faster Rcnn是何凯明,RG大神等人2015年发表的,在目前来看,也是比较经典的通用检测算法之一,随着时间
的推移虽然又出现了更快的目标检测算法,例如YOLO算法系列,SSD, R-FCN等,但是经典的faster rcnn算法还
比较适合初学者入门拿来深入研究和作为自己第一个AI领域的项目。
一:faster Rcnn的历史:
faster Rcnn之前已经经过了好几代算法了,分别为Rcnn, fast Rcnn, 相比之下,每一代都会在上一代上做
进一步改良和升级。先从Rcnn算法开始讲起。(注,前2代算法这里不会详细描述,重点讨论第三代faster Rcnn)
二:R-CNN算法原理:

(注:图片为论文作者的图)
以上为第一代R-CNN算法,工作原理如下:
1. 一张图片的输入,通过selective search算法来提取是否为物体的候选框(大概2000个框),提取时间2秒左右
2. 对于每一个候选框都输入到卷积神经网络中进行特征提取,得到2000个特征图,那么就需要2000个卷积神经网络来一起干活,训练和检测速度太慢,并且占用了大量的内长
3. 2000个特征图分别进行BBox reg回归算法来微调候选框与真实的物体框最为接近
4.2000个特征图进行SVM支持向量机来做20分类任务,由于SVM是做2分类任务,需要由20个支持向量机来共同
完成20分类。
Rcnn算法优缺点:
1.该算法在当时的准确率来看还是比较高的
2.训练速度太慢了需要3天,还消耗了大量内长,由于需要2000个卷积神经网络来训练,预测时间为47秒,根本谈不上实时性可言,对于实时性要求比较高的领域无法部署。
3.该算法通过卷积神经网络来做特征提取,通过传统的BBox回归和SVM支持向量机算法来完成候选框回归和分类任务,是非end to end的网络结构。
三:fast Rcnn算法原理:
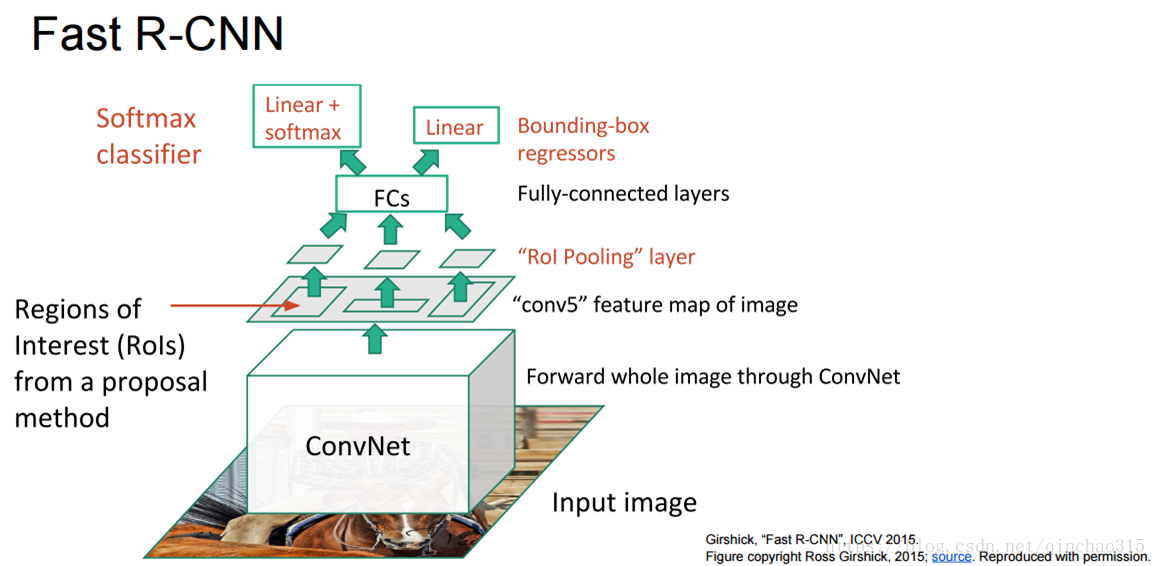
(注:图片为论文作者所使用的图)
第二代fast Rcnn算法在第一代上做了很大的改进,意义极大,工作原理如下:
1. 直接对一整张图片进行卷积(而不是像第一代里对每一个候选框进行卷积),经过卷积提取的特征图假设大小
为40*60,那么共有2400个特征点,每一个特征点对应到原图上的大小是16*16(对于VGG16卷积网络是这样的,VGG16的网络都是3*3的卷积,padding=1, 卷积后特征图和原图大小不变,但是VGG16中经过了4次2X2的Pooling层,相当于特征图相比原图浓缩了16(2的4次方)倍,所以每个特征点对应于原图大小是16*16)。
2.由于经过VGG16卷积的特征图都会对应原图一个16*16的视野,那么可以直接将之前经过selective search算法产生的候选框映射到经过VGG16的特征图上来,从而避免了对每一个候选框进行一次卷积网络,达到了所有候选框共享一个卷积网络。
3.由于特征图上的候选框大小并不相同,无法输入到全连接层中去,作者使用ROI Pooling层方式,将每个特征图上的候选框通过Pooling为同一个尺寸大小,然后一起输入到全连接层中去,使用softmax来做20分类,并做候选框微调的回归任务。
fast Rcnn优缺点:
相比第一代,有了所有候选框共享同一个VGG卷积网络,并且使用了ROI Pooling层来统一尺寸,通过全连接层统一做分类和回归任务,去掉了传统的SVM分类器和BBox回归方法。
大大缩减了训练和预测时间,训练时间为8.75个小时,预测时间为2.3秒(其中光selective search就占用了2秒)
,所以其实该网络预测只需花0.3秒的时间,并且准确率也得到了提高。
感觉上实现了end to end网络结构(整个过程使用一个网络结构,统一训练),但是其实并不是真正意义上的end to end,因为对于候选框的题取还是使用了传统的selective search算法,并且该算法提取候选框需要2秒时间,无法实现实时性。
有了前面对R-CNN和fast Rcnn的了解,我们再来讨论正题了,faster Rcnn原理
faster Rcnn原理请看第二篇: