经典目标检测识别方法概述@陈子逸
经典目标检测识别方法概述
由于水硕期间自学了一些目标探测的方法,这里做一个概述,肯定有不完美的地方,还请指正一起进步.
综述
1.分别简单描述一下RCNN系列:
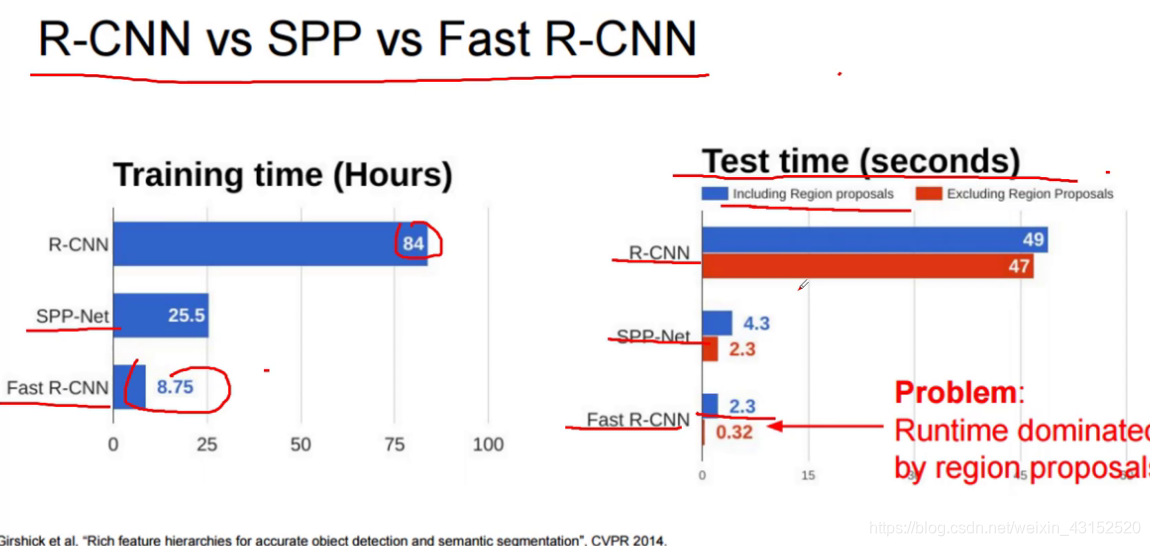
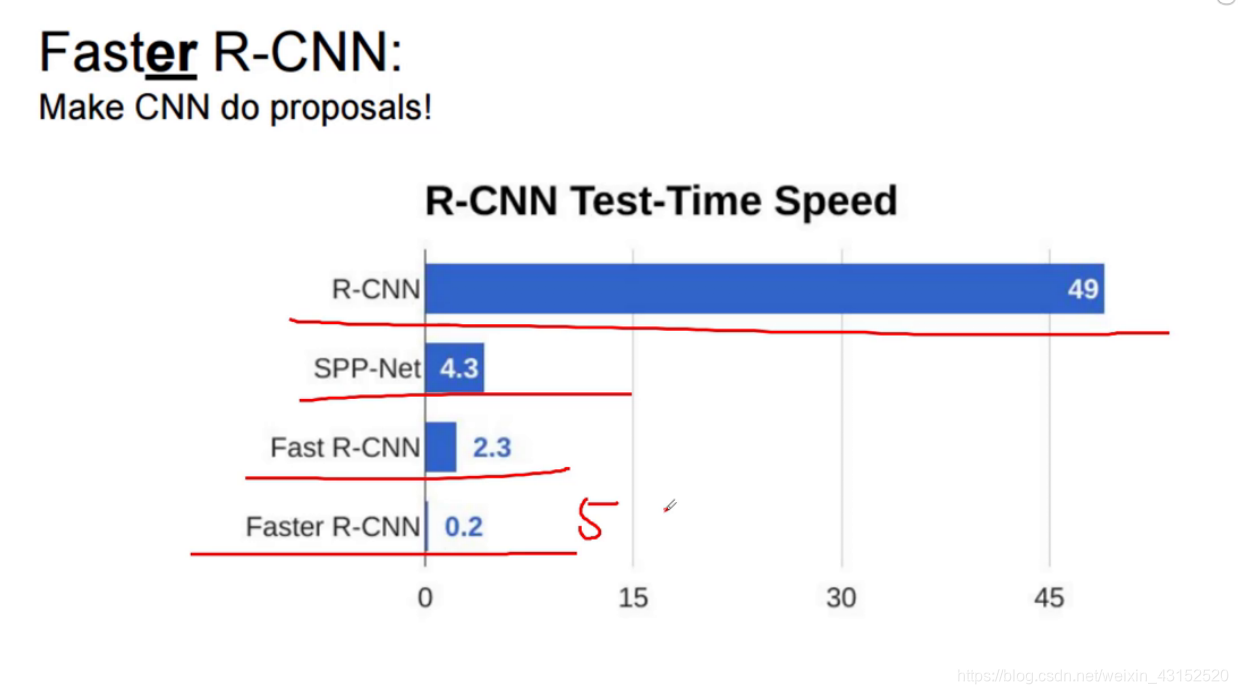
在我看来, RCNN 是一个benchmark,首先利用传统的图像检测方法基于纹理特征用selective search 如HOG,sift来产生一些候选框,然后将这些候选框加入到卷积神经网络中进行训练和分类.这很明显不是一个端到端的算法,我记得一幅图就需要47s以上的时间来识别.
在这个基础上何等人又提出了Fast rcnn. 这里就不用传统的SVM/reg(线性回归模型) 来分类而是同样采用神经网络(多任务网络)来分类, 他是结合SPPnet改进RCNN,在这里提出了ROI Pooling,利用这个ROI Pooling层得到FC层固定的输入. 但是在候选区域提取的过程仍然选择的是selective search的方法.
Linear+ softmax:分类
Bounding-box regressors:回归
但是Roi 还是需要一些传统的算法去原始图像上找,再把处理的结果汇入CNN
.这一步只能在CPU上面做!!!没办法用GPU,所以无法迭代到神经网络中来.
Faster就把候选区域提取这一部分的工作进行了优化,引入了RPN网络. RPN网络最直接的是anchor机制, 这个机制对特征图上的每个像素点进行三个尺度的反映射,利用感受野的比例在原图上产生一堆box. 然后对这些可能是目标的box进行筛选和精细化过滤,这里有一些小tricks. 比如把和图像边框重叠的去掉以及以IOU比例来去掉一部分,再加上非极大值抑制,最终一幅图大概还剩2000个框. 然后就是2层共四个分类回归器当中.第一层是判断前景背景,从传递函数可以看出来,如果不是前景,Pi*(anchor预测是物体的概率)是0,右边半部分是0,就不需要bbox regression的计算了同时左边很明显是二分类交叉熵损失.朗达值是用来分配分类回归权重的.

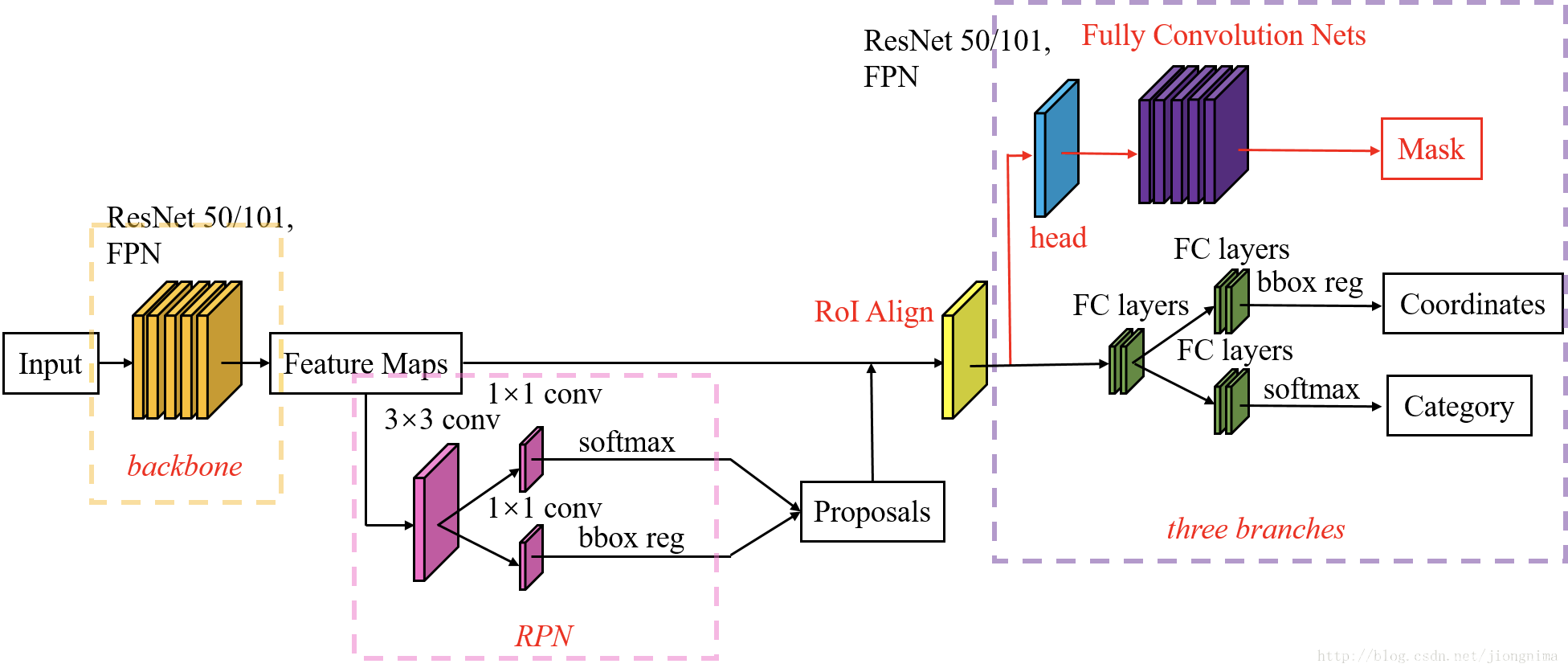
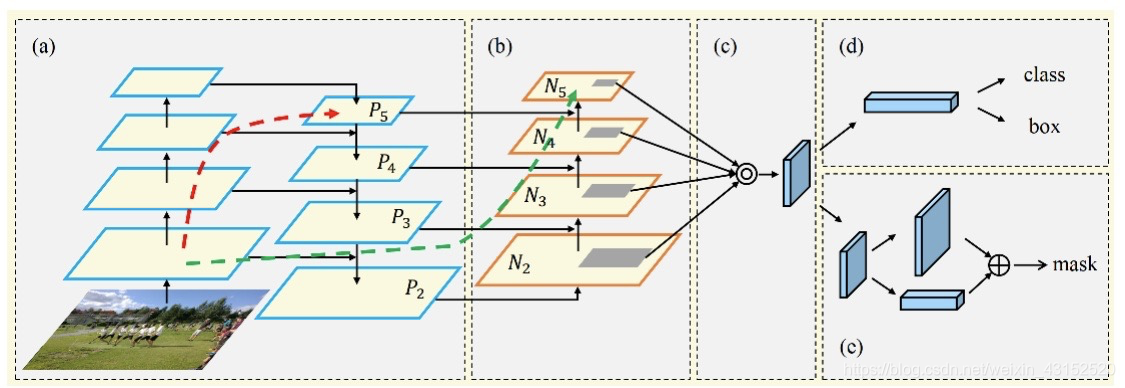
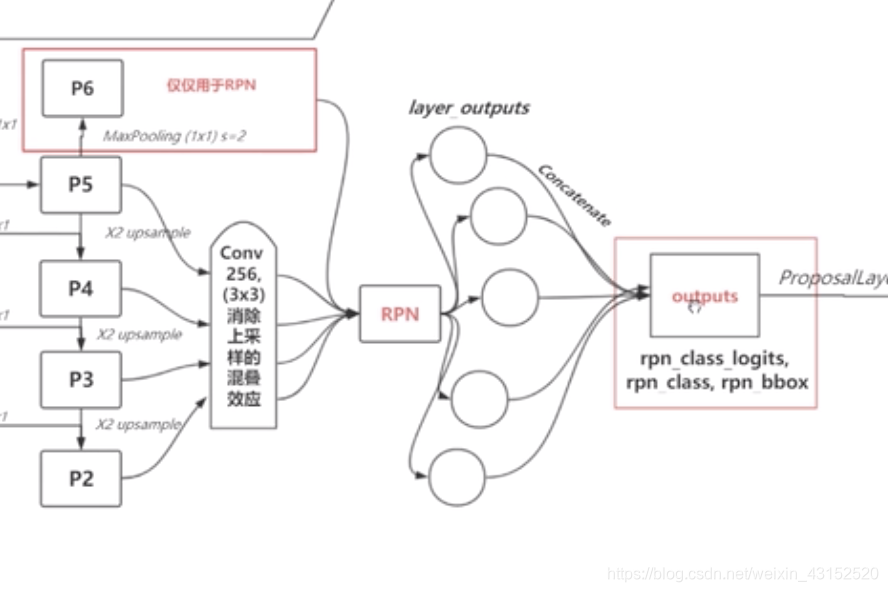
而mask-rCNN呢 比起之前有了2个最明显的提高. mask的backbone使用新的resnet+FPN.另外使用ROI align替换ROI Pooling.更具体一点就是ResNeXt+RPN+RoI Align+Fast R-CNN+FCN。 深度残差网络是一种神经网络中将输入输出跨层连接 的一种网络,函数是F(x)+x,x为之前层的输出.因为随着网络深度的增长,cnn的效果(performance)并不是越来越好,相反会下降,而深度残差网络因为将前几层的结果跨层输入到后面的层未经过激活函数的放缩可以极大的保存原始的特征.而RPN网络是左右2个模型,左边是bottom-up模型就是简单的卷积过程,这里作者是将深度残差网络中的几个过程分为几个stage.,feature map的大小在经过某些层后会改变(Pooling层),而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。将每个stage 的结果输出成为C1-C5的特征图,其分辨率从512到32,然后通过C5一个11卷积得到P5(达到通道数与高层相同),再P5高层与较低一层且通过11卷积后的C4相加得到P4,后面以此类推.生成P2–P5后,再通过一个33的卷积生成新的P2-P5(消除混叠效应),P5上采样生成P6只进行RPN网络使用.
每个层利用RPN三个比例就能生成15个anchor,那么如何决定该选择哪层特征图进行ROI Pooling呢? 有一个公式,其作用是大尺度的ROI就用高层特征.输出为三个: rpn-logits/rpn-class/rpn-bbox. Roialign呢就是针对之前roipooing的坐标转换的浮点型近似带来的特征图信息值缺失的改良,对该点周围四个像素点进行双线性插值,然后maxpooling得到的值比只进行近似要好很多.进行完roi pooling后, 用FCN对mask 分支机构对每个roi产生k个分辨率mm的二值掩膜,K为分类物体总类数.根据faster rcnn里面的预测判断使用哪一个掩膜,对于预测的二值掩膜的每一个像素点,我们都应用sigmod激活函数(127-0.77举个例子),整体使用二分类交叉熵损失函数.这样就允许每个类生成独立的掩膜,避免类间竞争(解耦).如果像只用FCN那样对每个像素点进行softmax,整体使用多任务交叉熵,会引起竞争,导致分割效果差.
FCN是全卷积,实现任何输入,而且因为pooling的分辨率降低,便使用上采样,同时有结合不同深度的跳级skip结构.
SSD?
SSD是利用多尺度特征图来进行检测的算法, 主干网络是vgg16,去掉了最后的FC层.因为vgg16后面的FC层是用来分类,在这些只利用前部分提取特征不用分类,一共有6个尺度的特征图,从3838到11. 这里也借鉴了faster rcnn中的rpn网络, 叫prior box其实差不多,scale也是自己定义.3838、1919、1010每个产生6个,其他三个每个产生4个box. 最终输出的向量纬度为(C类+4)kmn.同样是参照rpn,设定一个阈值,大于为正样本,小于一个阈值为负样本.中间的省略.这里要注意两个阈值不一样.同时负样本也会添加一些难例,正负样本比例基本是1:3.数据增强是通过随机采用多个path,分类用的softmax loss,回归用的smooth L1. 损失函数里面采用的jaccard函数算IOU其实就是RPN里面算IOU的方法.最终损失函数通过置信损失和分类损失按比例和的形式得到.
DSSD ?
将SSD中的vgg16模型前部分backbone替换成了ResNet. 然后在网络后面添加了反卷积网络层,原因是增加了大量上下文信息.后面还有些作者添加不同的预测结构这个有余力可以看看。
YOLO V1
将图像分为SS个格子, 每个框包含ground truth的拿去回归. 这里我们可以发现, 无论大小分辨率的图都是固定的SS个格子,这样对于小物体的检测没有特别突出的优化,容易检测失误. 但这是一个端到端的算法, 或者说one-stage. 它没有faster rcnn那种候选框提取的步骤,整个网络都在CNN网络中进行, 每个格子产生B个框,每个框有5个坐标,4个位置,1个置信度,置信度就是框和ground的IOU,所以总的输出向量为(5B+C)SS这一个tensor. C是预测的类别信息,置信度为box含物体的概率IOU两个乘积(测得有多准).从这里可以看出如果不是objct,第一项就是0,总的置信度0,也就不参与后面计算. 得到的box一样也是设定阈值再NMS. 有个特点是使用小卷积代替了inception moudule.但是这个inception module我不了解,回头学习一下. 为了更加精细化, 分辨率也是从224达到了448,同时设置一个dropout层,在第一个全连接层后面,ratio=0.5,为了防止过拟合.
但是在损失函数上面,作者将分类,回归,置信度三部分平方和,这样比较简单粗暴.如果是原论文的模型, B=2, C20类 5*B+C=30. 拿8维的回归坐标和20维的分类来同样权重平方和不太合理.而且由于大部分都不是物体,置信度为0可能会导致后面的网络发散或者崩溃.所以目标函数权重引入参数比较好.另外缺点还有只能输入固定尺寸,对小目标识别较差.
YOLO V2
最明显的是用卷积层代替了FC,同时引入了anchor机制. 同时对所有层都进行batch norm.batch norm 就是对每次的输入进行批规范化处理(归一化), 使其输入尽量高斯分布,使训练比较规范,不会扩散错误,加快训练速度. 输入尺寸从v1的448变成416,因为总的池化层pooling尺度为32,这样到最后一层就是13,对于图片来说一般的物体在中间的概率最大,13的话中心就是一个点,更好捕捉信息. 而且改造了darknet来代替以往的纯CNN结构,更加高效,这个网络特点就是每次下采样通道翻倍. 因为SSD和faster rcnn的box scale都是手动设置,而v2采取聚类K-means去分类box,但是没有采用欧式距离这样box越大error比较大,而是采用1-IOU进行聚类分析.
以下是分别详细的回忆
RCNN
Region proposal
给一些候选框,然后再找.
Selective search
先通过一些纹理特征 将图像分为潜在的可能是物体的候选框.
SVM 分类器、Bbox reg:回归
RCNN: 一张图像产生2k个候选框,再分别进行CNN处理.
慢!!!~ 47s一张图像
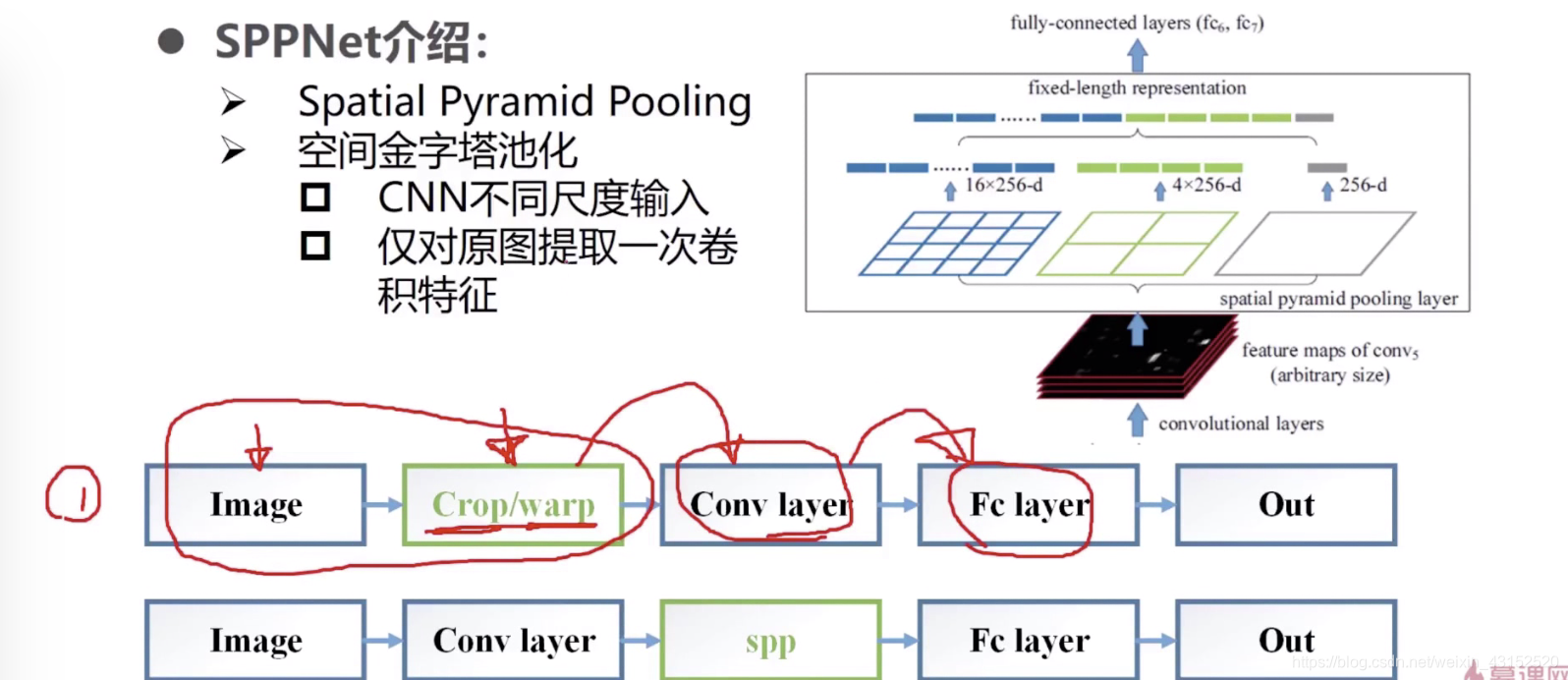
卷积不限制输入大小,全连接层有限制: 要保持输入一致.
ROI pooling
通过一个pooling 层把大小不同尺寸大小的特征图连成串(拼接在一起)的大小是一致的.
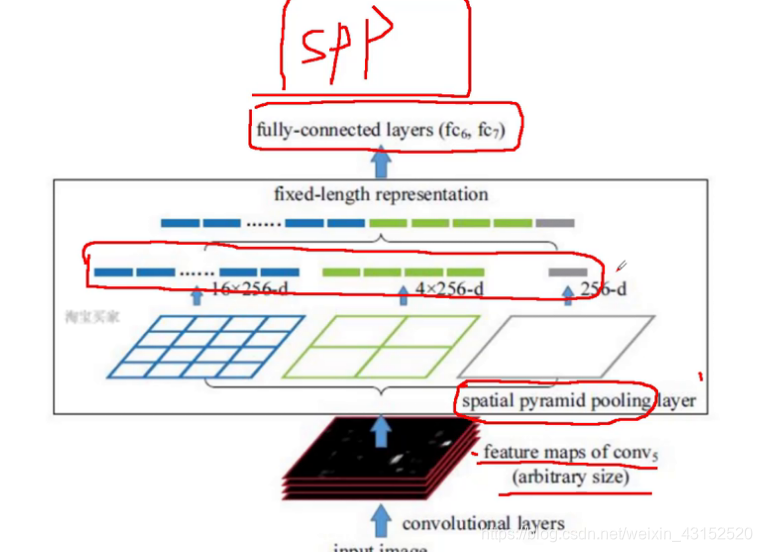
SPPnet的优化:
输入: feature map
原始的需要reseize
得到一个21维的特征每个通道. 21*通道(256)
就可以忽略feature map的大小,只对原图进行一次卷积.
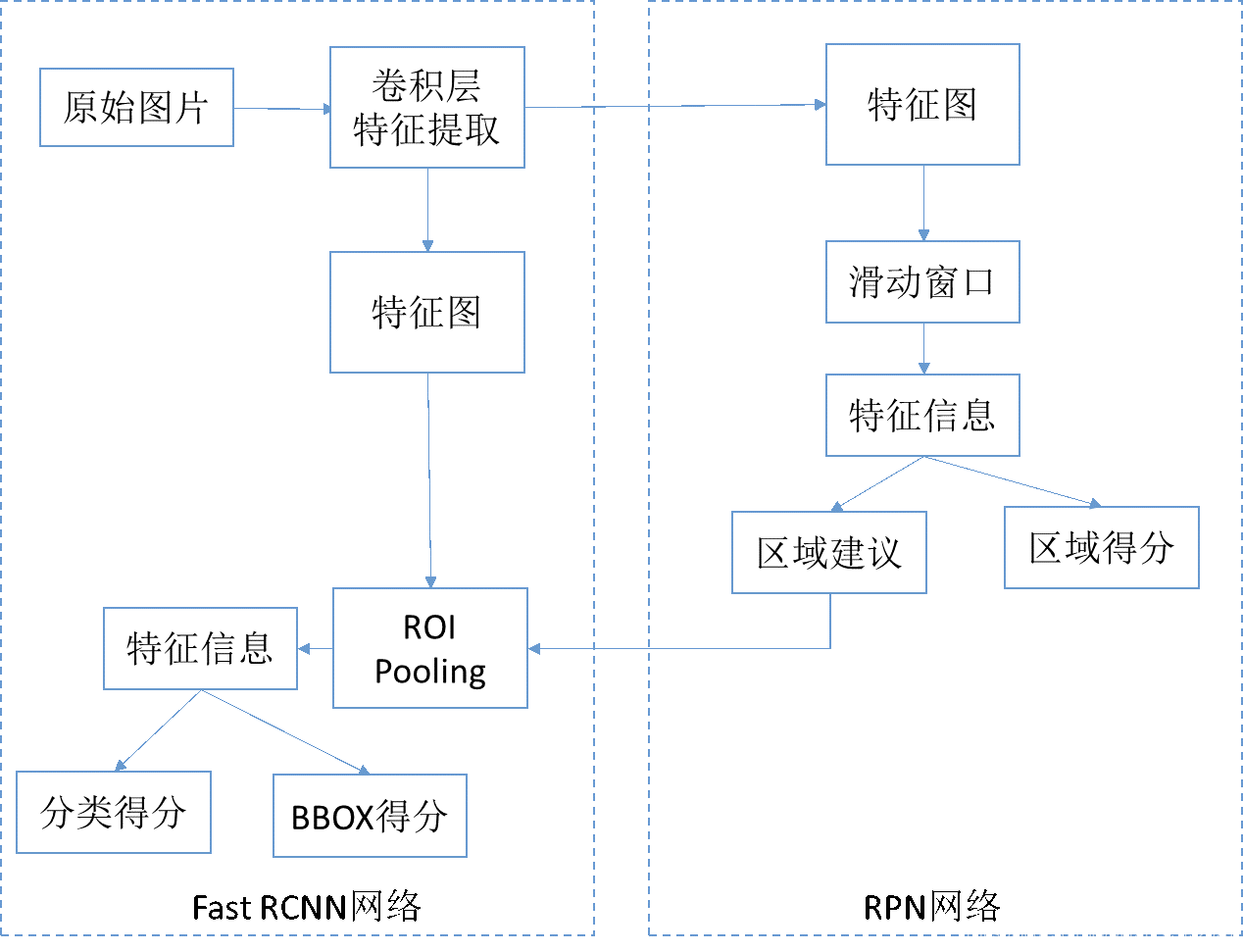
Fast RCNN

不用SVM/Reg来分类用CNN.
与SPPnet不同的是采用了ROI pooling层来得到FC层的固定输入.
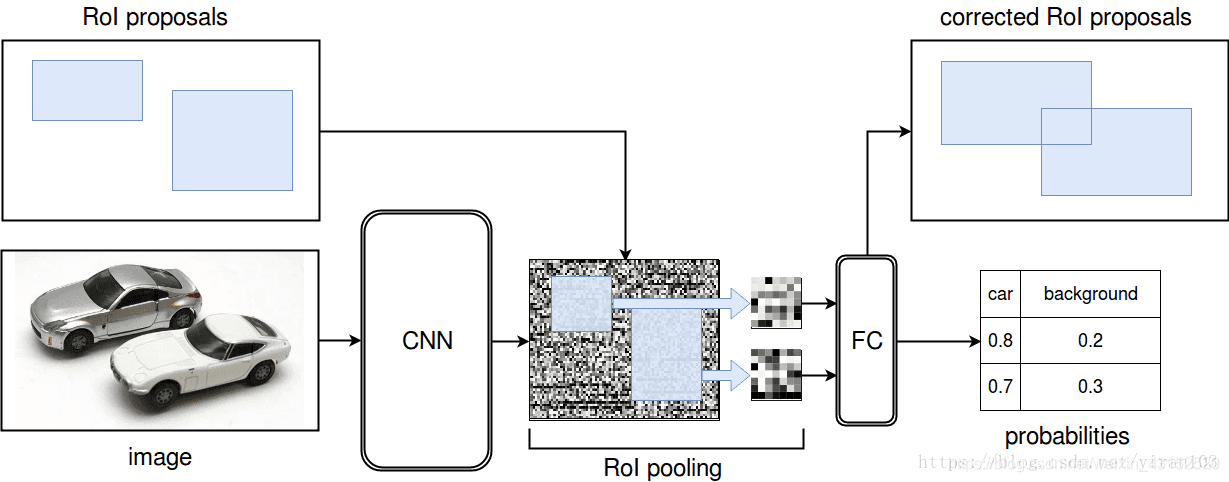
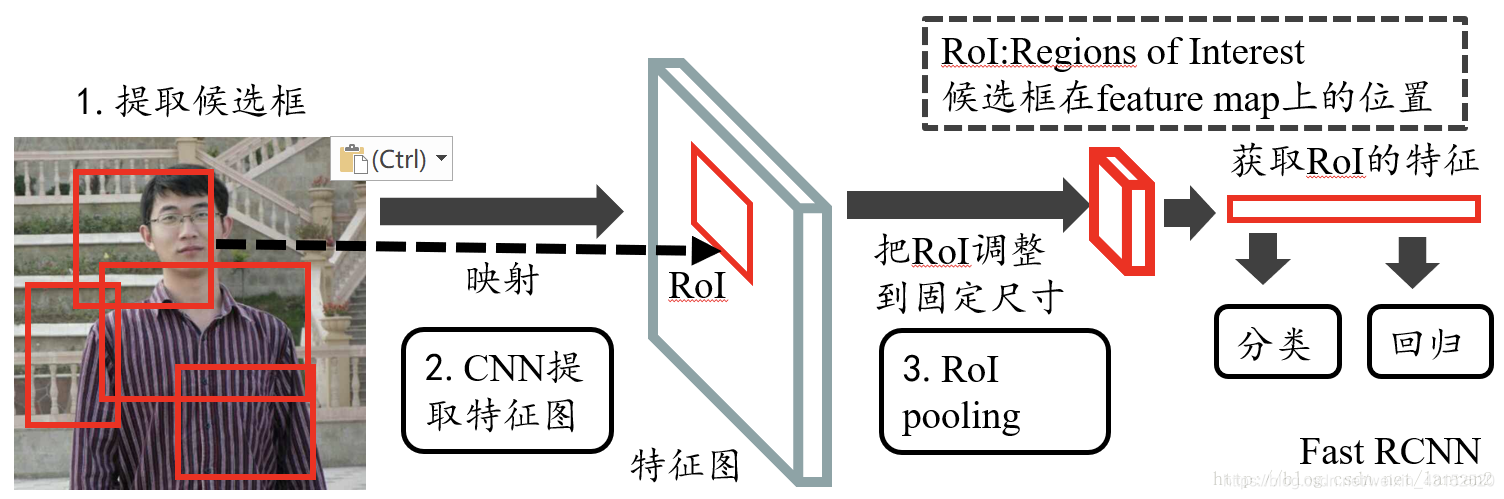
ROI Pooling: 

先卷积, 候选区域是selective research.
先总的卷积.
RoIs: 通过感受野找到原始图像该区域的大小.
基本上是端到端.
Linear+ softmax:分类
Bounding-box regressors:回归
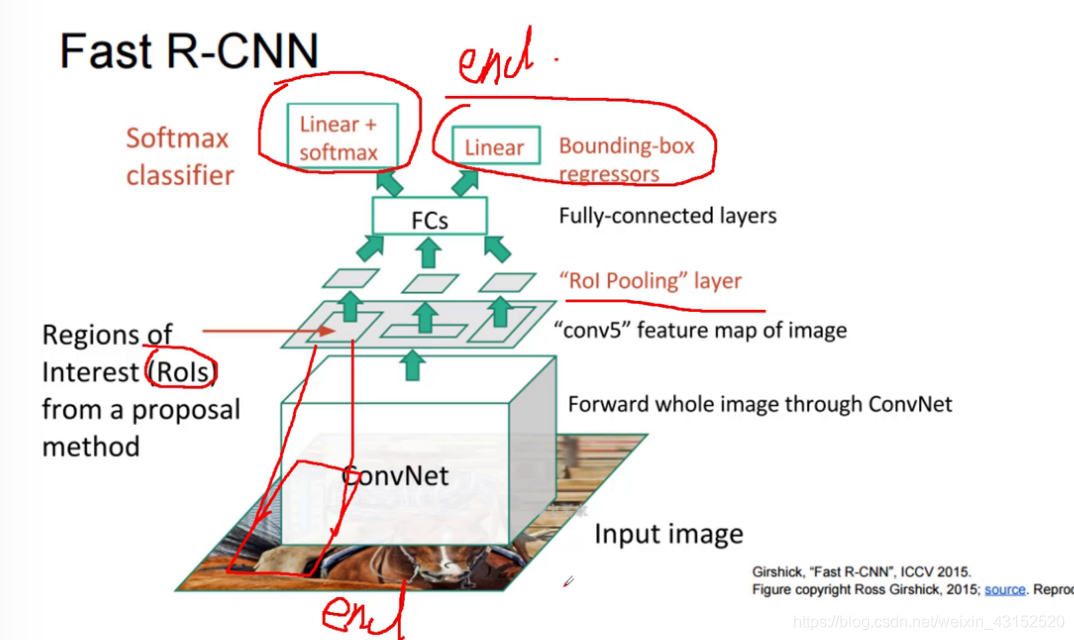
但是Roi 还是需要一些传统的算法去原始图像上找,再把处理的结果汇入CNN
.这一步只能在CPU上面做!!!没办法用GPU,所以无法迭代到神经网络中来.
RCNN Fast RCNN 对比:
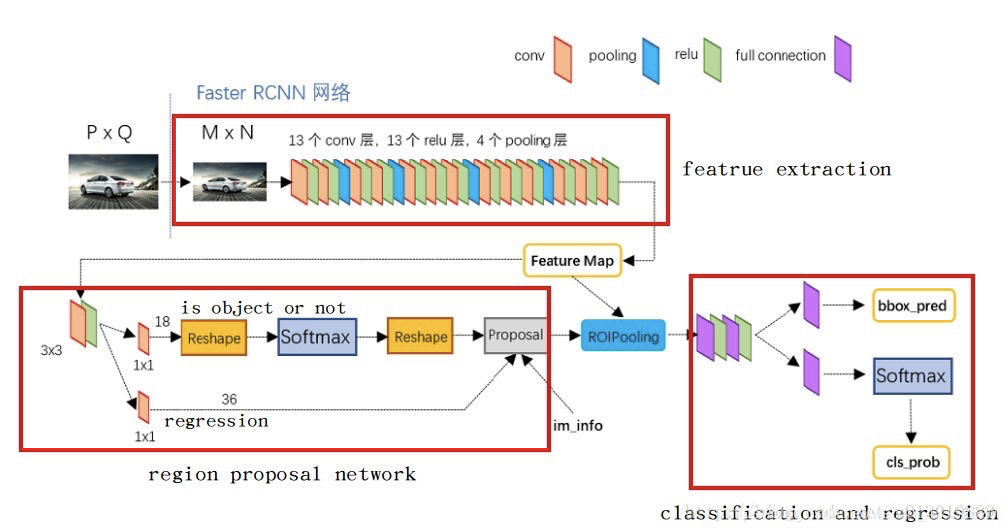
Faster RCNN
15年年末
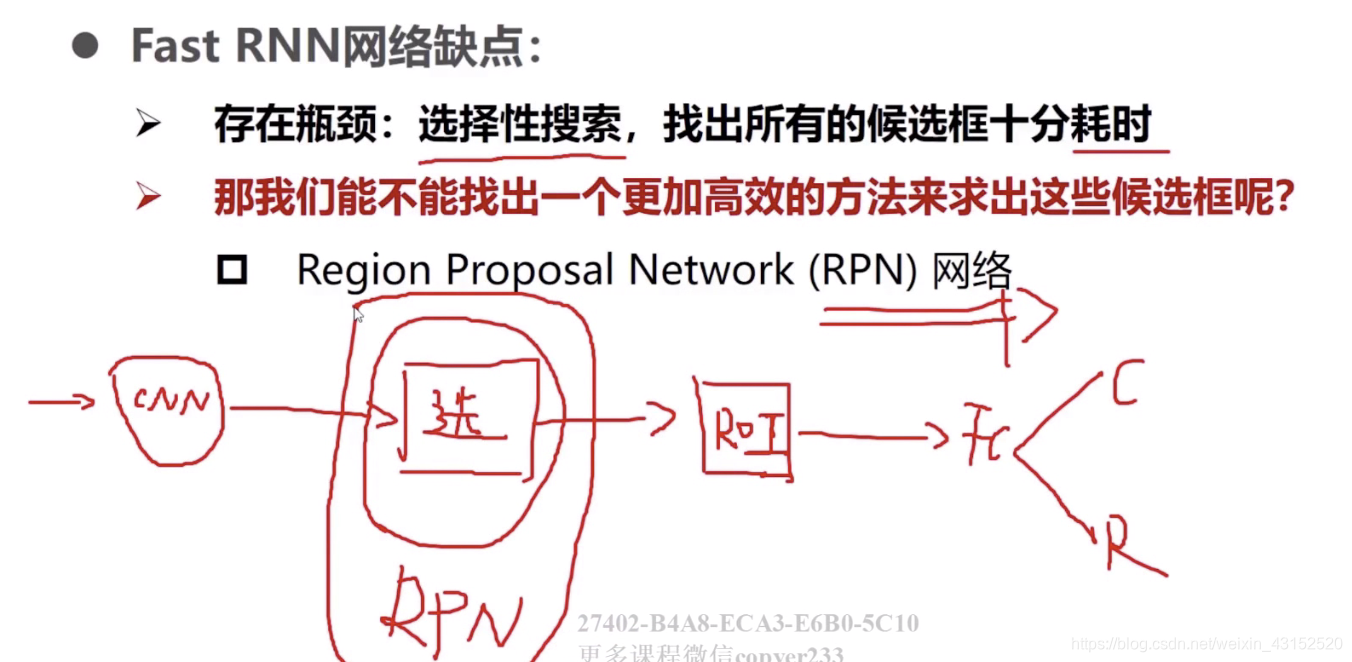
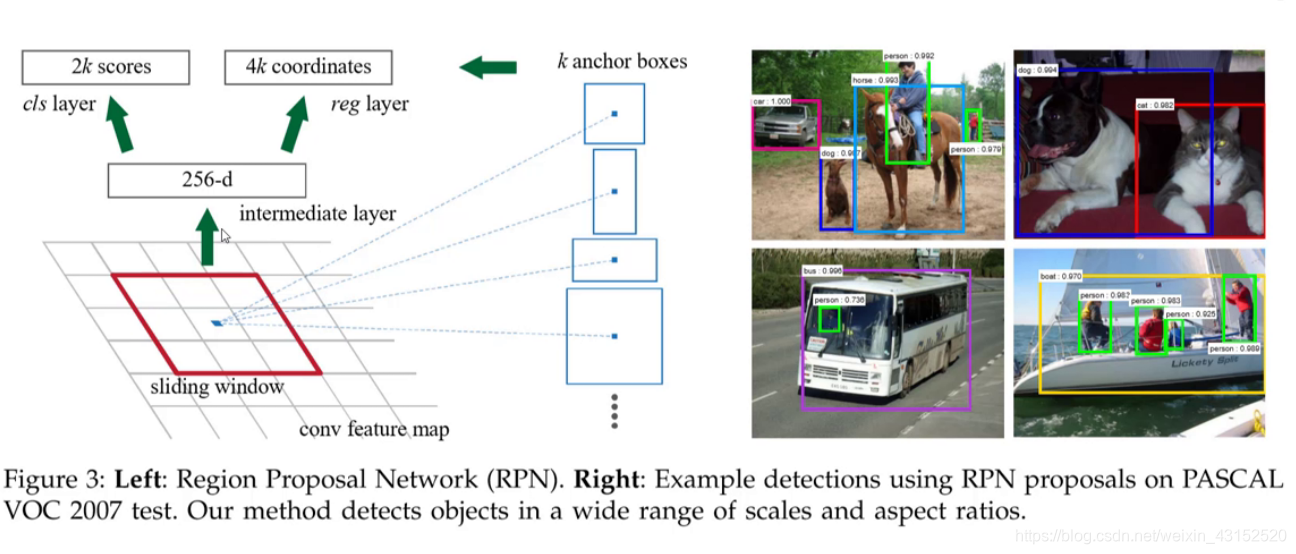
Region Proposal Network
之前是没有一个好的产生候选框的方法,也不是在神经网络中产生的
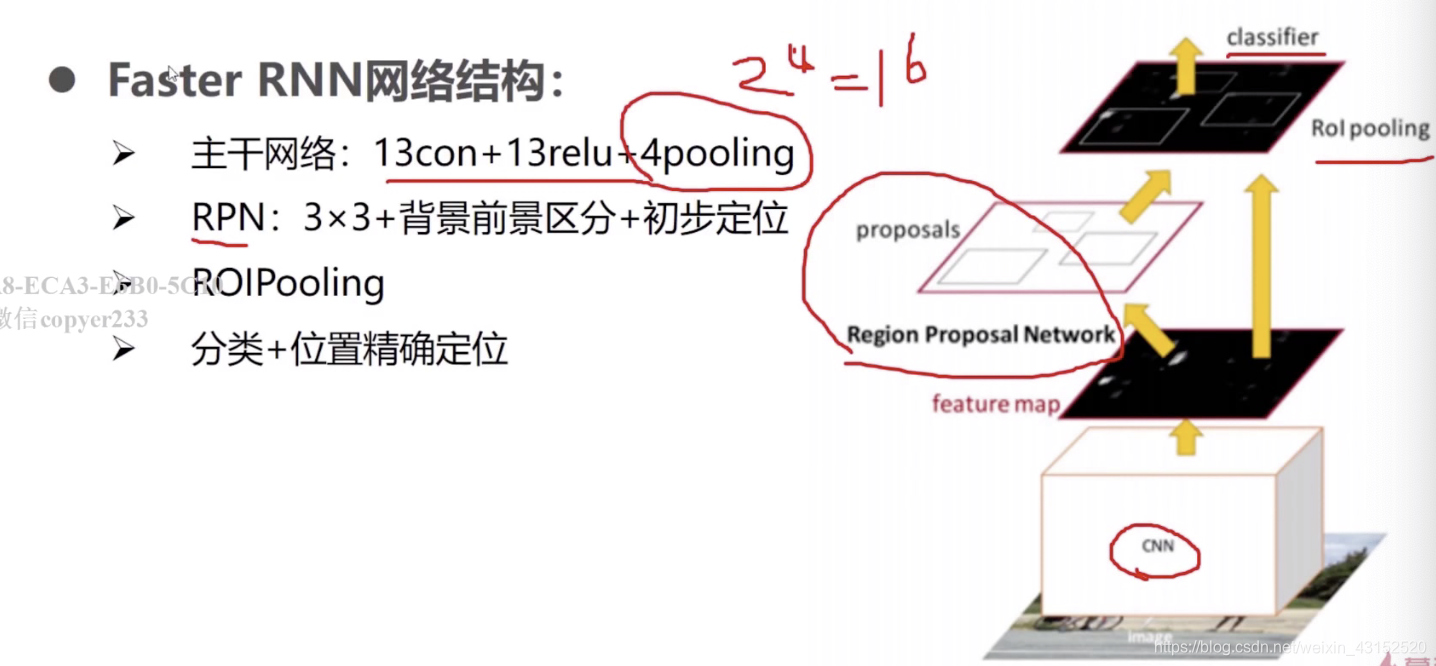
主要完成二分类,背景和前景.,RPN里面也有一个Roi Pooling层.
粗分类,粗定位.
3*3滑动窗口,中心点作为anchor.
三个面积为: 128/256/512.
从特征图产生候选框!!!.
有四个LOSS值:
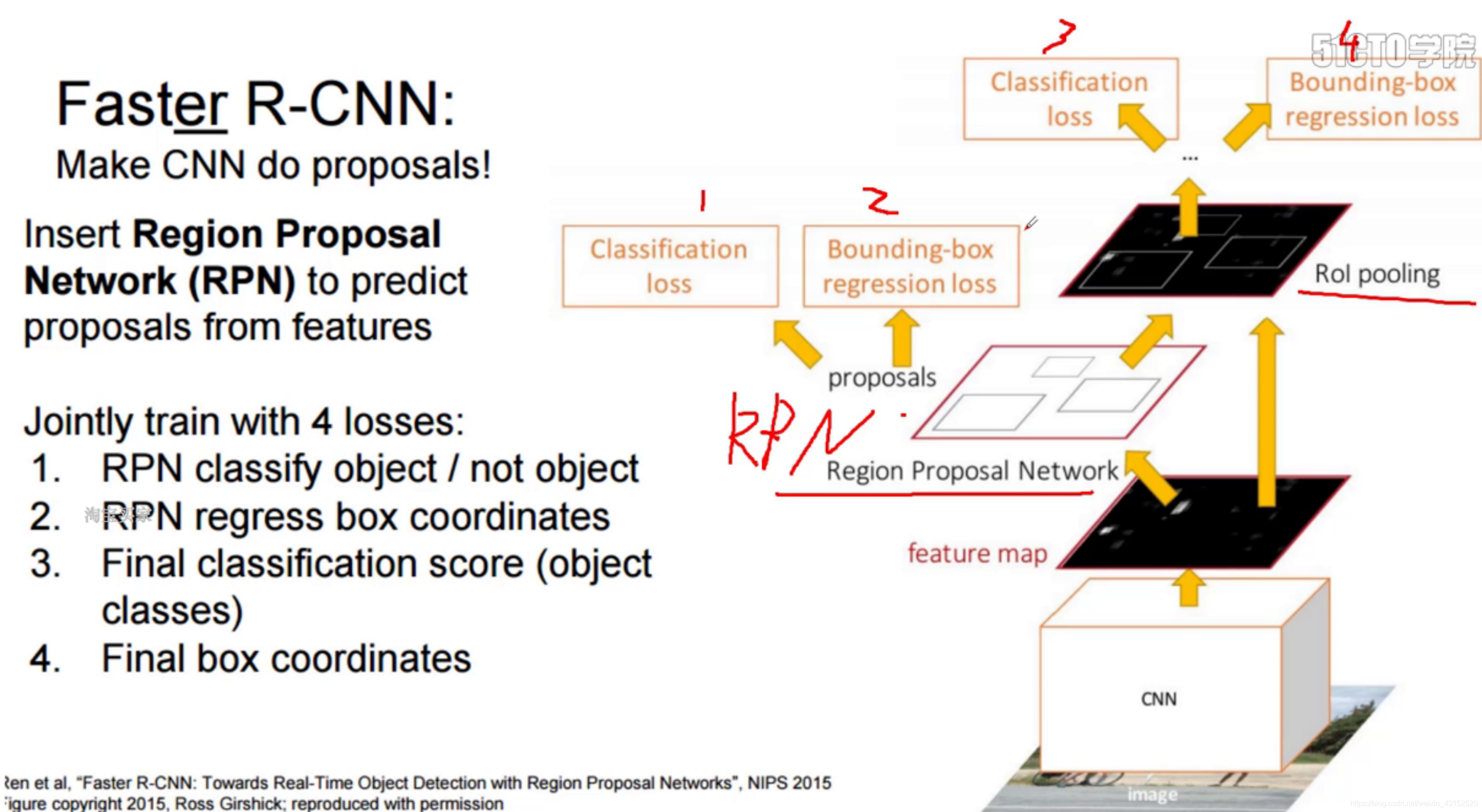
对产生的2w个候选框进行2分类,看看他是什么,是不是物体.
1: 判断是不是前景还是背景. 2分类
2: 做微调,用Bounding box regression 算与当前
3. 20分类
4. 找到最合适的边框回归的位置.
端到端!!!
以往的方法: 1图像金字塔 将图像按不同比例放大缩小 再卷积
2对feature map 按不同比例缩放.
RPN网络: 把任意图像都能当成输入.
输出: 当前框是不是物体,以及它是不是物体的得分.
对特征图再进行一次卷积:
对于特征图的每一个点,都有其原图的感受野,对特征图每一个点进行映射到原始的输入上,得到的区域就是感受野.
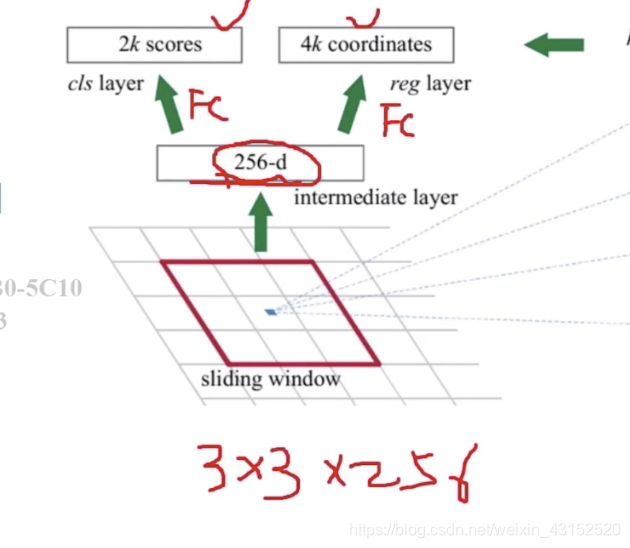
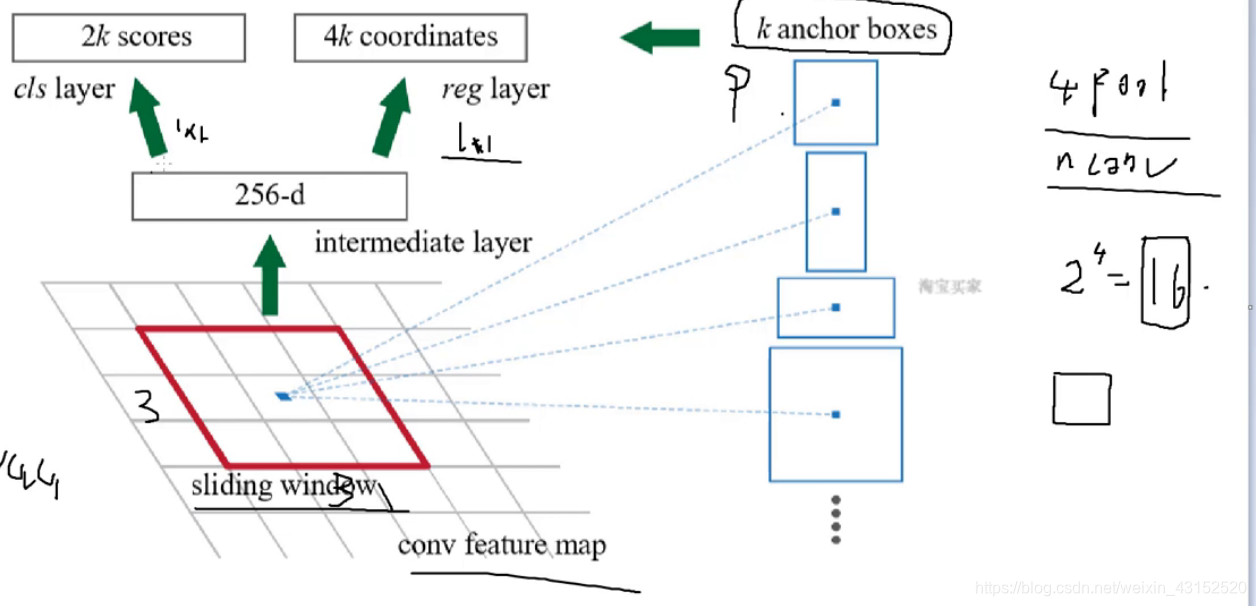
K anchor boxes
9个box 3个初始长宽比. 128/256/512
cls layer: 分类 看是不是物体 2k个 前景和背景的得分
reg layer: 回归 判断坐标 4k个
Sliding window: 不停滑动
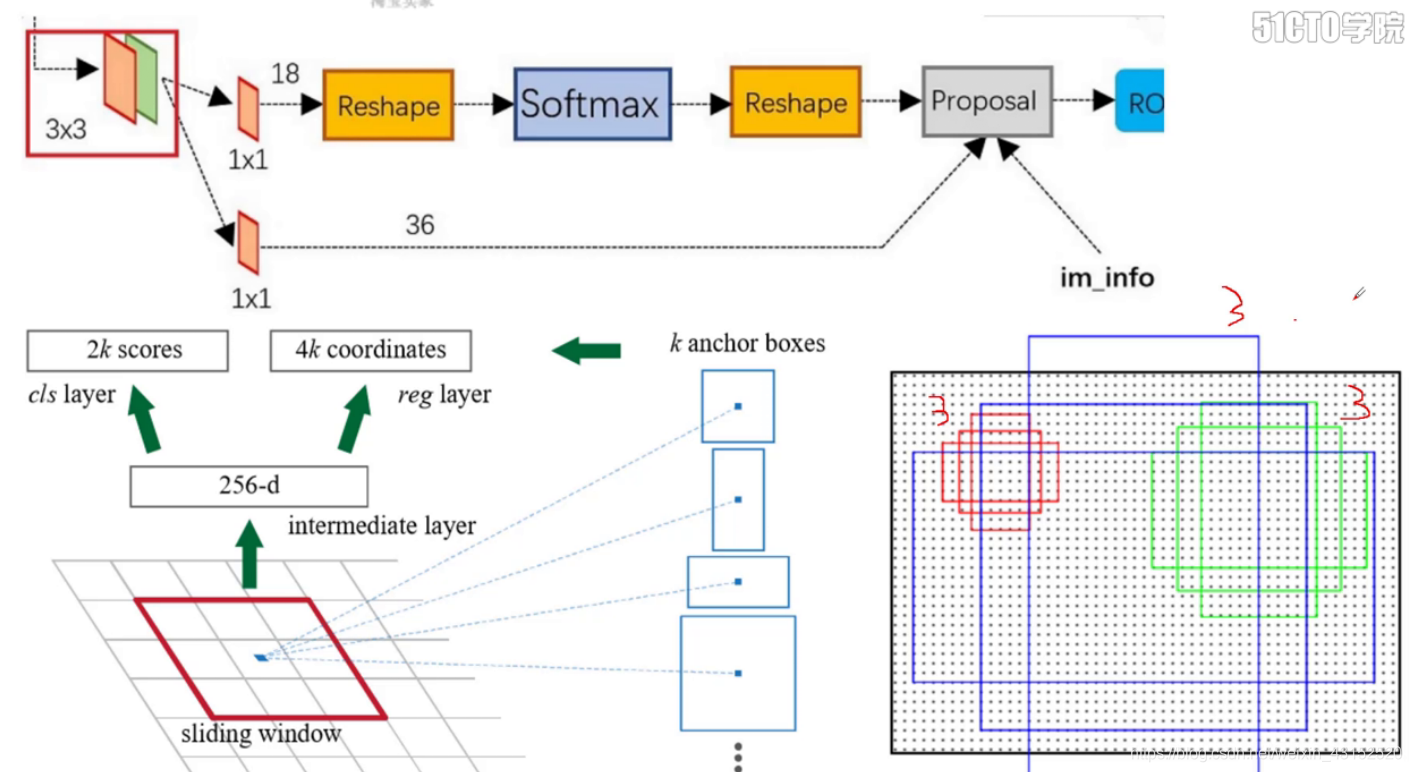
2个11的卷积代替全连接层.
原图400600 最后一层conv 40*60 2400个点 总共2w个候选框
Loss Function
1. 选择候选框中重叠比例最大的, 打为正标签.
2. IOU大于0.7的,打为正标签. 负例为小于0.3. 中间的全部去掉.
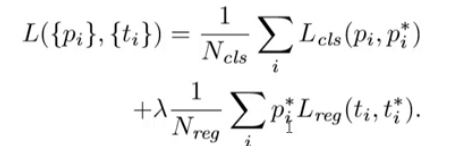
RPN网络训练
Mini batch=1.
任意选256个. 尽量使正负样本为1:1, 都是高斯初始化.
越界的框也不要了. 剩 6000个.
大多数框都重叠了: 引入非极大值抑制NMS
保留物体比例 Sa>Sb 大的. 剩2000个
再取个top N. 128个
RPN做的它到底是不是东西,最后还有一个分类做的是它到底是个什么东西. 20分类…
SPPnet的优化:
输入: feature map
原始的需要reseize
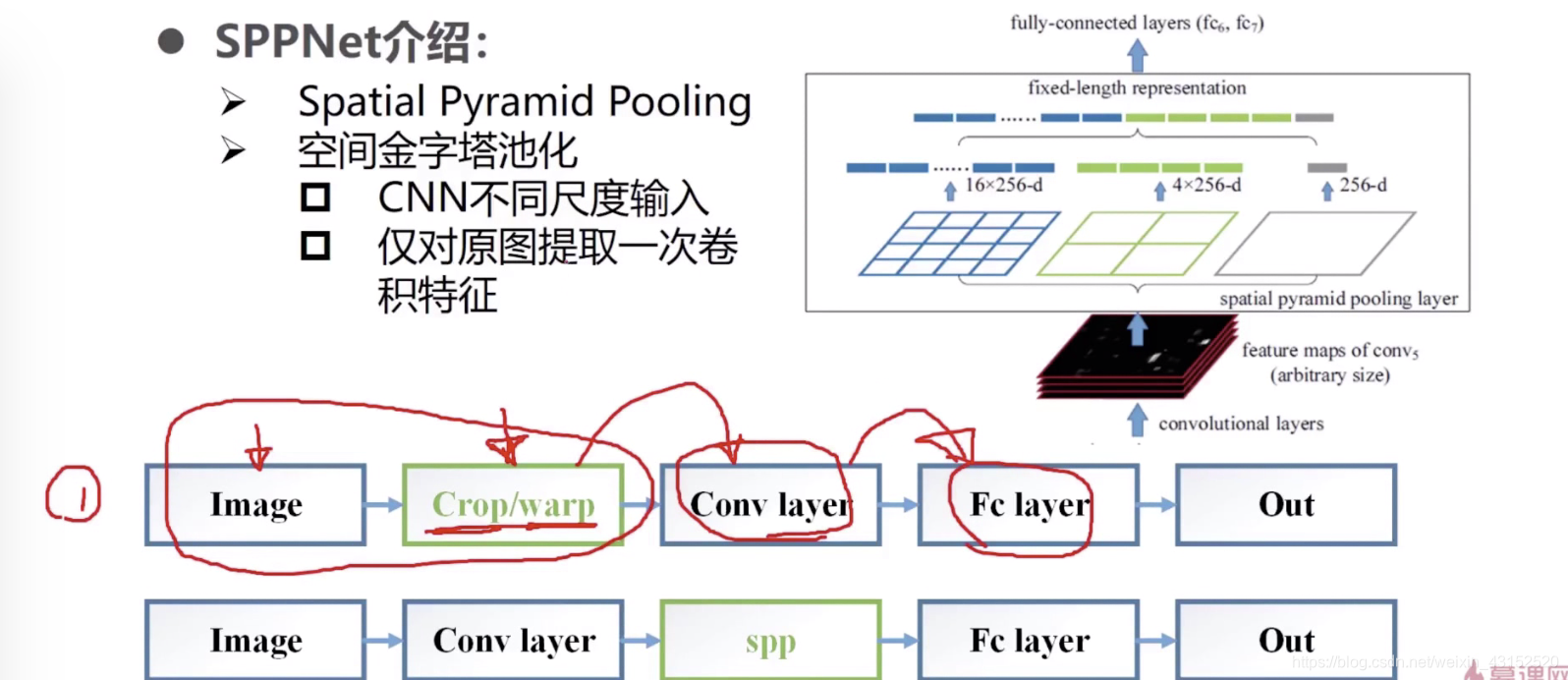
得到一个21维的特征每个通道. 21*通道(256)
就可以忽略feature map的大小,只对原图进行一次卷积.
Mask RCNN
遵循自下而上的原则,依次的从backbone,FPN,RPN,anchors,RoIAlign,classification,box regression,mask这几个方面讲解。
FPN: 特征金字塔.
除了class和box,加了mask分割的任务.
转置卷积 *2
RPN: 基于滑窗的无类别obejct检测器

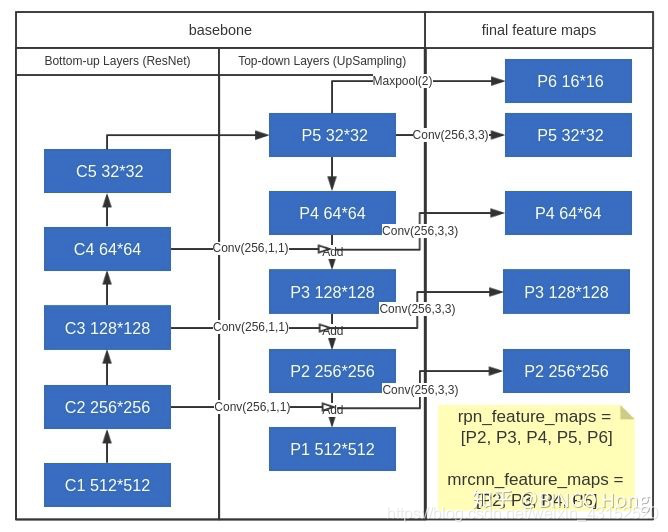
RPN在图像上创建大量的boxes(anchors),并在anchors上运行一个轻量级的二值分类器返回有目标/无目标的分数。具有高分数的anchors(positive anchors,正样本)会被传到下一阶段用于分类。
通常,positive anchors也不会完全覆盖目标,所以RPN在对anchor打分的同时会回归一个偏移量和放缩值,用于修正anchors位置和大小。
语义分割, 实例分割.


后来出现的SNIP、SNIPER也是基于Image Pyramid.
SSD: 在不同尺度的feature map上做检测
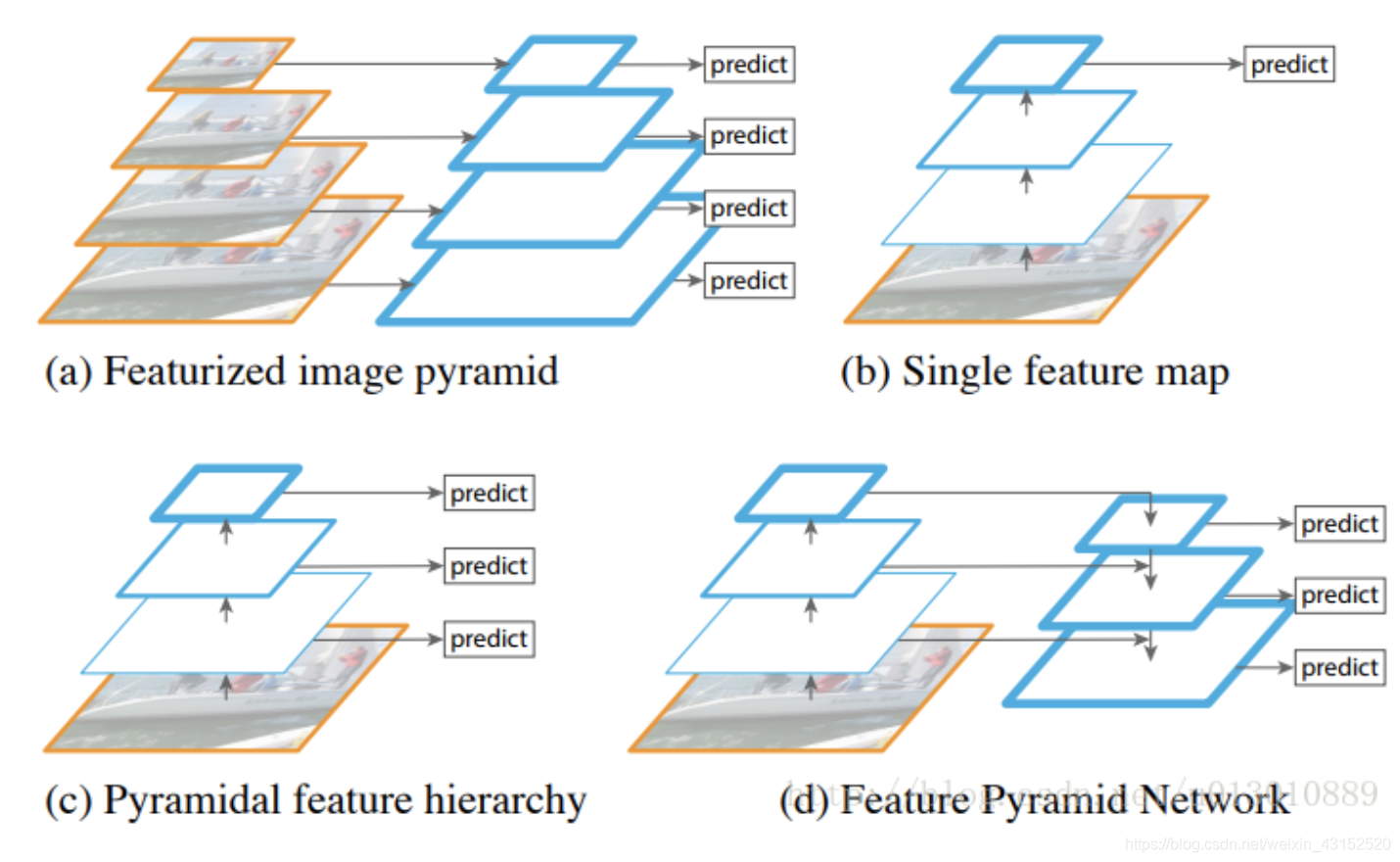
SSD就采用了图像特征金字塔, 但FPN作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
FPN:把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息。
VGG16/ROIalign
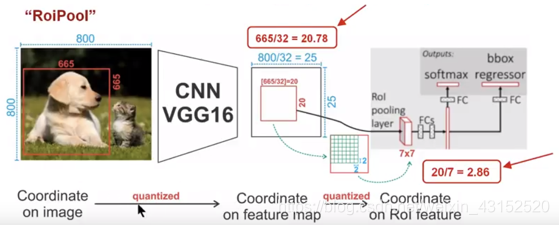
假定我们输入的是一张800x800的图像,在图像中有两个目标(猫和狗),狗的BB大小为665x665,经过VGG16网络后,获得的feature map 会比原图缩小一定的比例,这和Pooling层的个数和大小有关:
在该VGG16中,我们使用了5个池化操作,每个池化操作都是2Pooling,因此我们最终获得feature map的大小为800/32 x 800/32 = 25x25(是整数)
但是将狗的BB对应到feature map上面,我们得到的结果是665/32 x 665/32 = 20.78 x 20.78,结果是浮点数,含有小数,取整变为20 x 20,在这里引入了第一次的量化误差;
然后我们需要将20 x 20的ROI映射成7 x 7的ROI feature,其结果是 20 /7 x 20/7 = 2.86 x 2.86,同样是浮点数,含有小数点,同样的取整,在这里引入了第二次量化误差。
为了得到为了得到固定大小(7X7)的feature map,ROIAlign技术并没有使用量化操作,取而代之的使用了双线性插值,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。
蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature,最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。
然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。

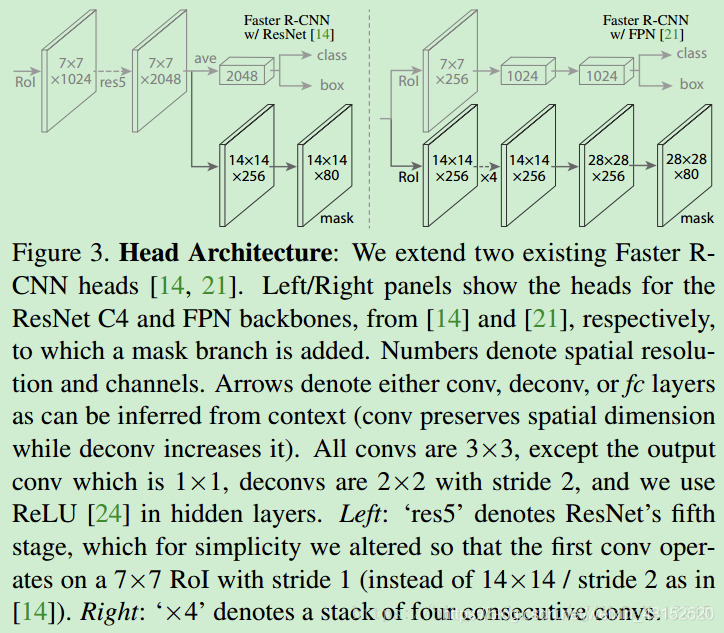
重点在于:作者把各种网络作为backbone进行对比,发现使用ResNet-FPN作为特征提取的backbone具有更高的精度和更快的运行速度,所以实际工作时大都采用右图的完全并行的mask/分类回归
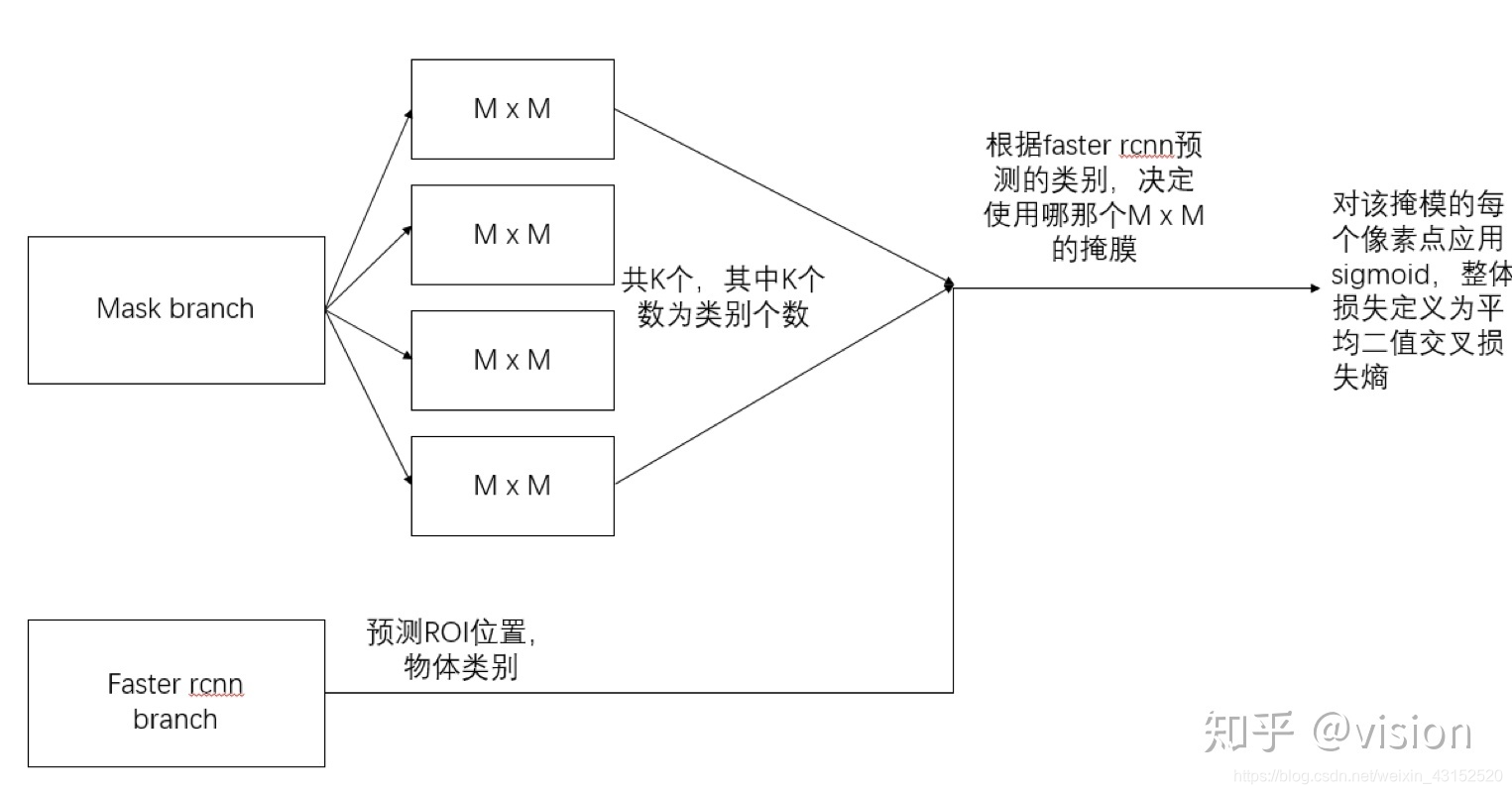
mask分支针对每个RoI产生一个Kmm的输出,即K个分辨率为m*m的二值的掩膜,K为分类物体的种类数目。依据预测类别分支预测的输出,我们仅将第i个类别的输出登记,用于计算
对于预测的二值掩膜输出,我们对每个像素点应用sigmoid函数,整体损失定义为平均二值交叉损失熵。引入预测K个输出的机制,允许每个类都生成独立的掩膜,避免类间竞争。这样做解耦了掩膜和种类预测。不像FCN的做法,在每个像素点上应用softmax函数,整体采用的多任务交叉熵,这样会导致类间竞争,最终导致分割效果差。
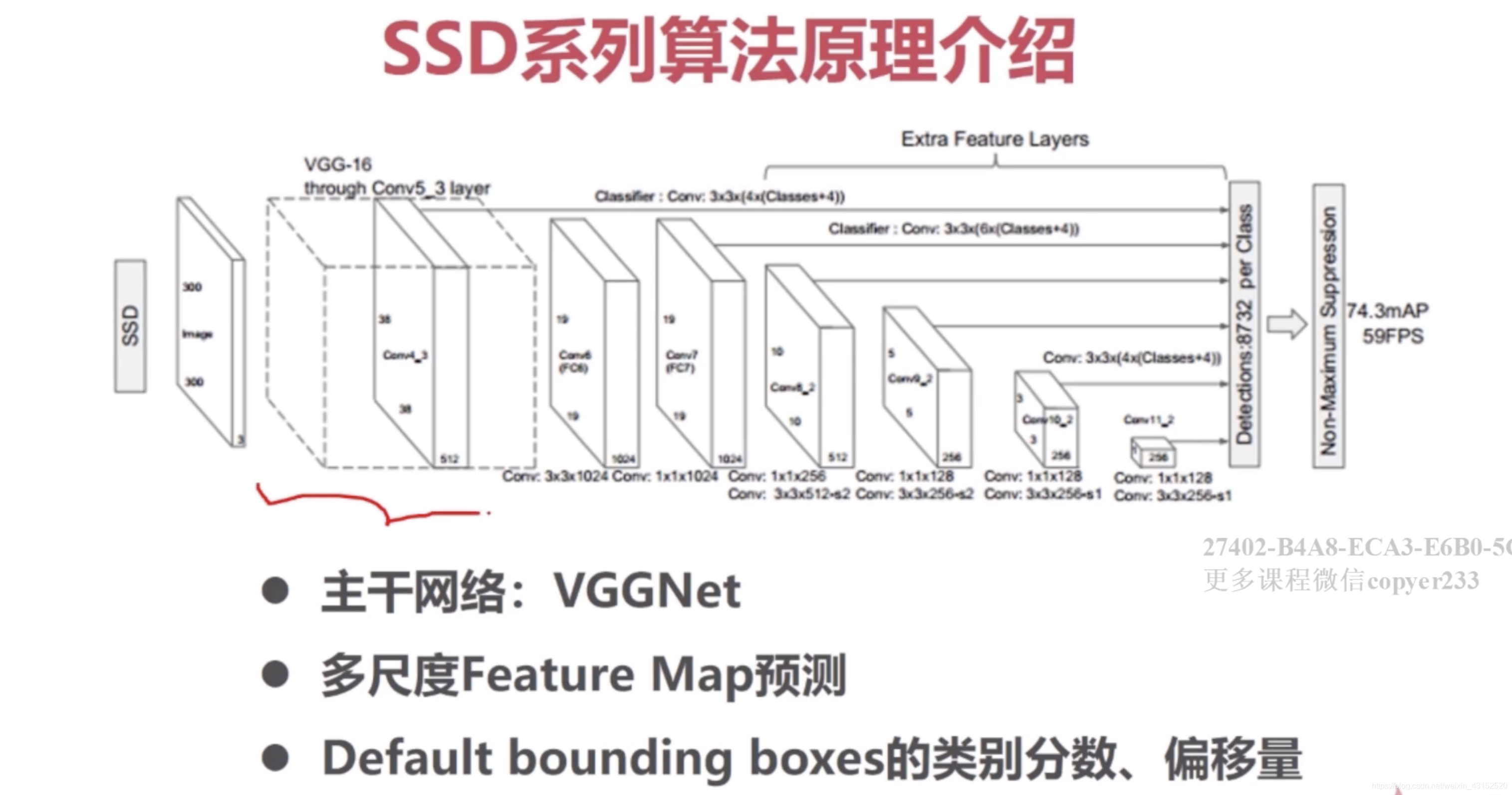
SSD
不同尺度的特征图上进行预测.
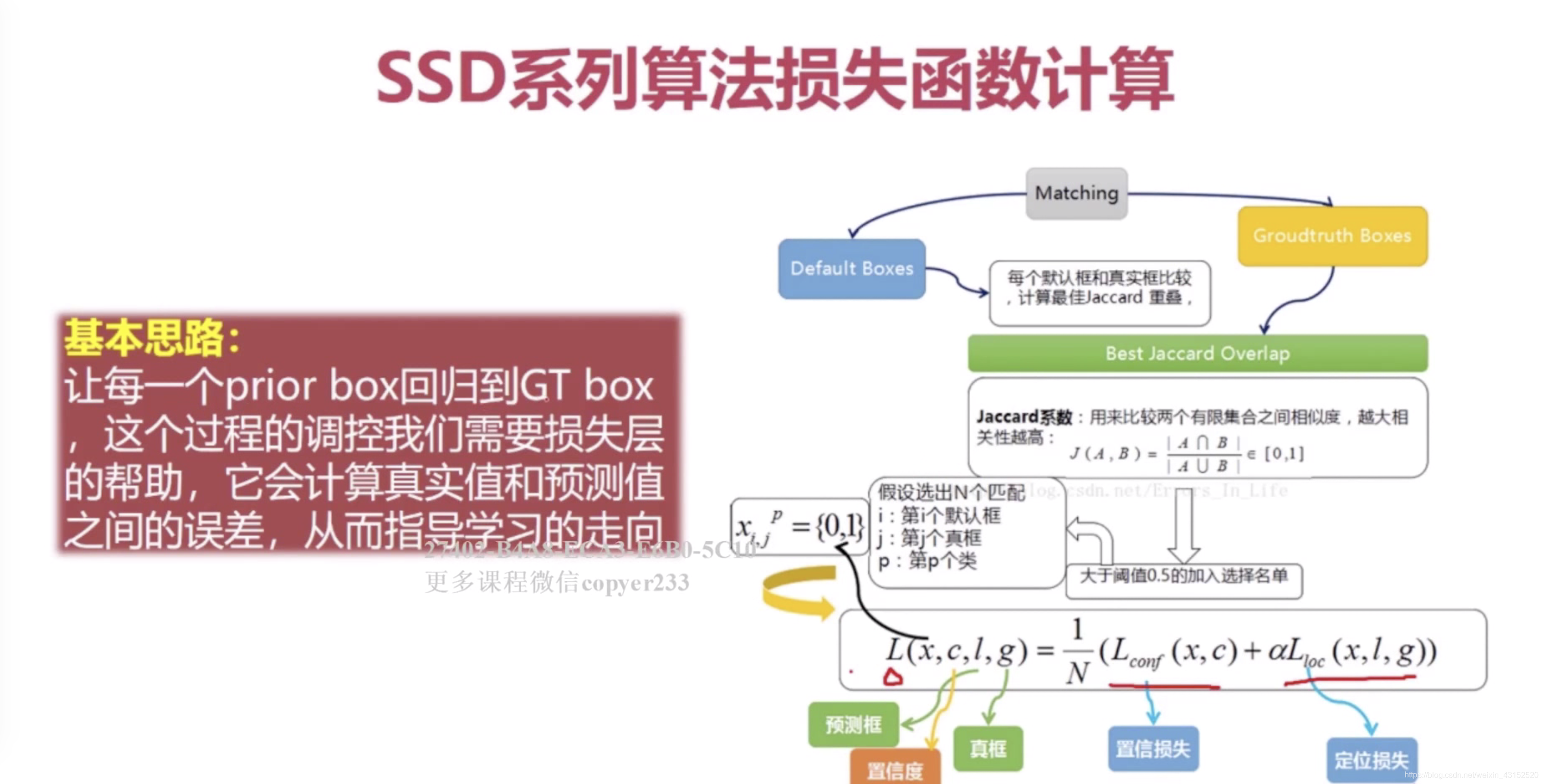
One-stage 直接回归.不需要proposal.
1.主干网络是Vgg16.去掉了原始的fc层,目标检测不需要分类任务,增加卷积层,提高模型性能.
2.对6个尺度的feature map.3838-11
3.Prior box
Anchor(cell),等比,找到原始图的box.跟rpn差不多.
Scale: 定义.1. Sk=(smin+smax-smin/m-1)(k-1) 2.长宽比
6个不同的box.

(C类别+4个坐标偏移值)K个anchorMN 特征图 这样纬度的输出.
大于阈值正样本,中间的省略.
负样本: 难例, 正负样本比达到1:3
数据增强: 随机采样多个path.
分类: softmax loss.
回归: smooth L1.
DSSD
DSSD有哪些创新点?
1. Backbone:将ResNet替换SSD中的VGG网络,增强了特征提取能力
2. 添加了Deconvolution层,增加了大量上下文信息
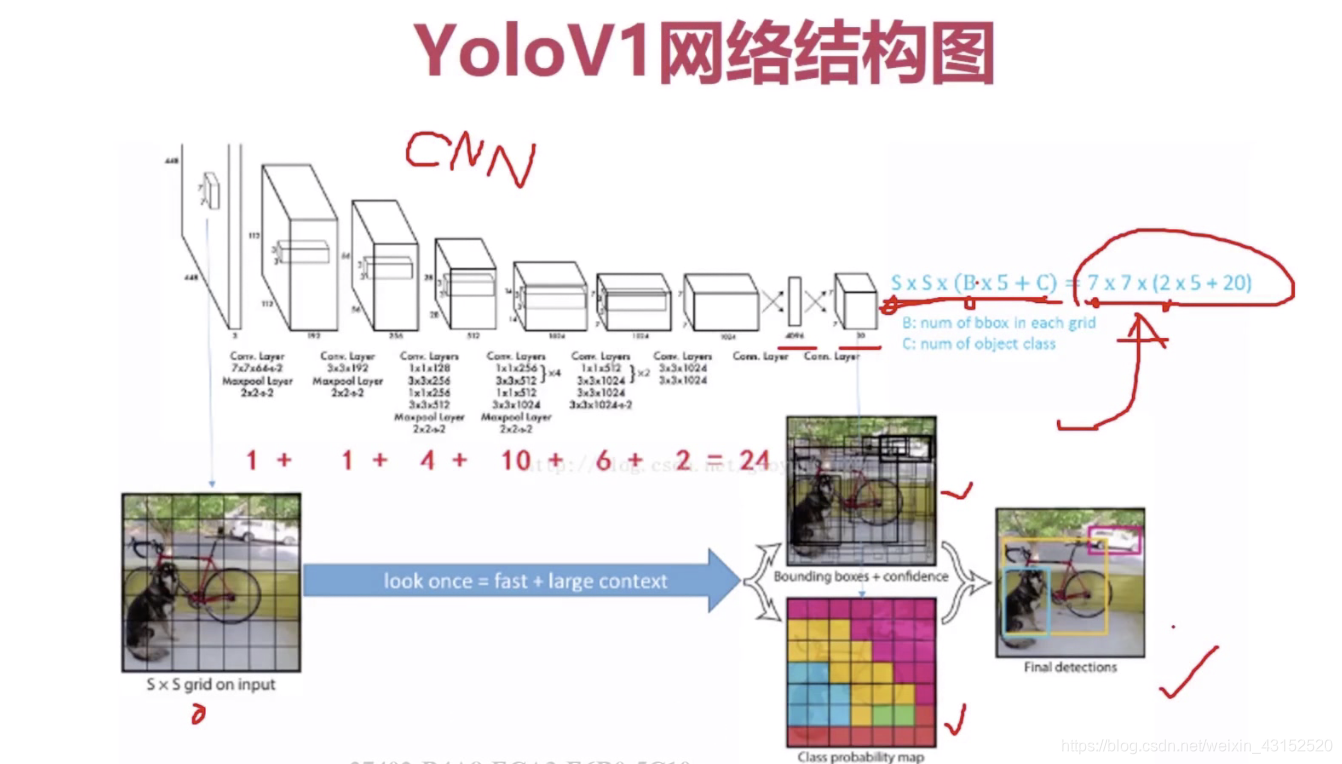
YOLO V1
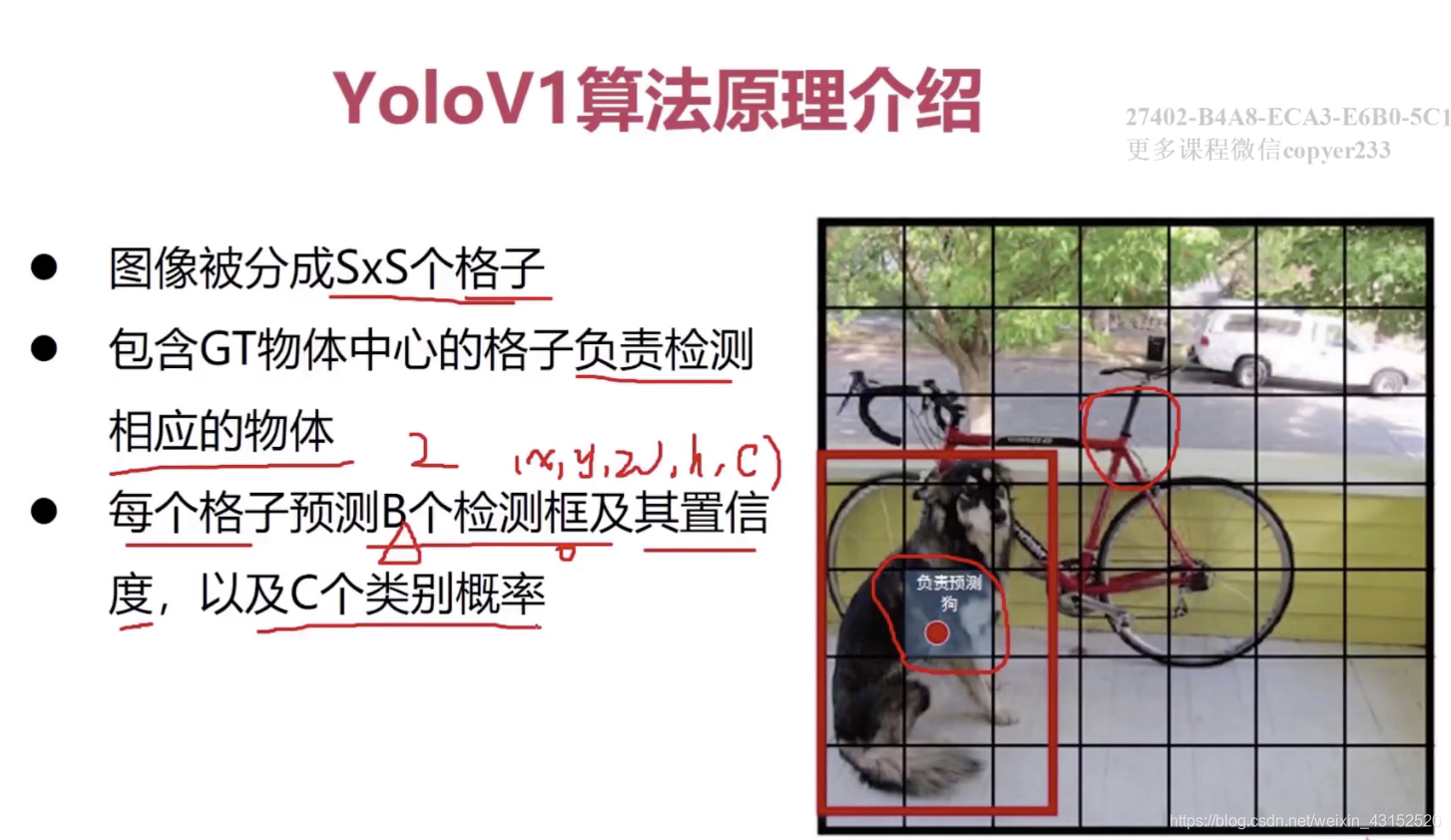
对于每个格子,预测出 5*B+C这样的向量长度.
总的: (5B+C)SS
YOLO对每个bounding box有5个predictions:x, y, w, h,
and confidence。
坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。
坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。
confidence就是预测的bounding box和ground truth box的IOU值。
每一个栅格还要预测C个 conditional class probability(条件类别概率):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。
我们只为每个栅格预测一组(C个)类概率,而不考虑框B的数量。
conditional class probability信息是针对每个网格的。 confidence信息是针对每个bounding box的。在测试阶段,将每个栅格的conditional class probabilities与每个 bounding box的 confidence相乘:
24个卷积层+2个全连接层.
Yolo1使用11+33小卷积代替inception module.
为了更精细化,224224分辨率提升到448*448.
为了防止过拟合,在第一个全连接层后面接一个ratio=0.5的dropout层.
损失函数
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。
简单的全部采用了sum-squared error loss来做这件事会有以下不足:
a) 8维的localization error和20维的classification error同等重要显然是不合理的。
b) 如果一些栅格中没有object(一幅图中这种栅格很多),那么就会将这些栅格中的bounding box的confidence 置为0,相比于较少的有object的栅格,这些不包含物体的栅格对梯度更新的贡献会远大于包含物体的栅格对梯度更新的贡献,这会导致网络不稳定甚至发散。
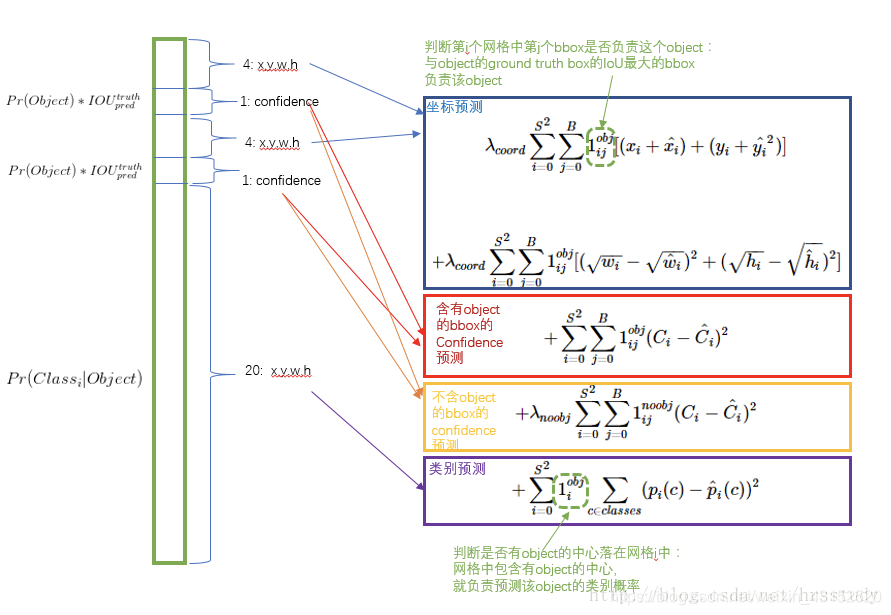

置信度: 两种概率的乘积.


正如损失函数写的,只有该bounding box负责该物体的时候,才会产生loss
缺点:

YOLO V2/YOLO9000


Batch norm:


13*13 反推32下采样=416.
Bounding box : 两个重叠/两个面积并 排出了框尺寸的影响

重新设计的网络:
每次max pooling(下采样),通道翻倍.
对于每一个box: 预测 (5+C)*B 更加关注类别,因为anchor.
YOLO-v2取消了全连接层,而是使用anchor box(应该是借鉴SSD)。去掉了一个池化层来得到更高的分辨率。为了最后得到奇数个位置,确定中心,所以分辨率改为416416。最后得到一个1313的feature map。
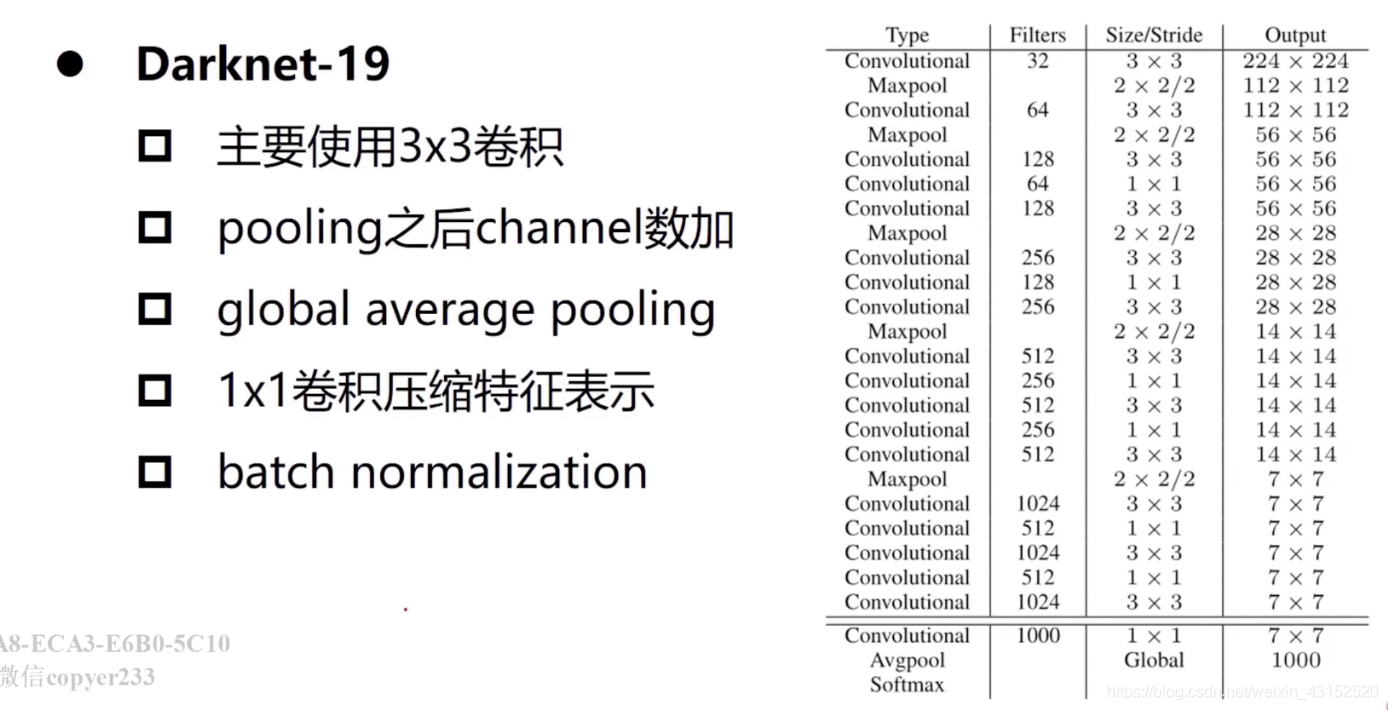
K-means对Bouding box进行聚类。传统的聚类方法是用欧式距离,这样大的box往往有更大的error,所以作者采用1-IOU作为聚类的距离。因为模型仅仅使用卷积和池化,所以可以随意修改尺寸。作者训练的多种尺寸的网络。包含{320,352,…608}。尺寸越大正确率越高,速度越慢。所以可以根据需求选择分辨率.之前大部分的检测框架基于VGG-16,一个强大,准确的网络。但是运算量太大。所以作者构建了新的框架darknet-19。
一些新型网络
HyperNet:
2016由清华提出.
RFCN:何凯明.
Light-Head RCNN 旷视和清华.
部分来源:1. https://blog.csdn.net/u011974639/article/details/78483779
2.https://www.cnblogs.com/hellcat/p/9749538.html
以上图片资料均来自公开论文及其开源网站,如有冒犯,请私我删除.