参考代码:None
在自监督深度估计中特征构建、运动预测对性能影响比较大。特征构建就是高效从图像数据中抽取有效特征,从而使得深度估计结果更准确。而运动估计除了需要估计出自身系统相机系统位姿变化之外,还应该估计出场景中的运动目标这样就可以减少对应区域像素对自监督深度估计的影响。
深度估计网络:
对于图像特征抽取上文章引入了transformer模块,首先利用帧间关联(运动网络估计出的pose信息)使用deformable attention算子优化当前帧的表达,这里可以看作当前帧特征(query)与相邻帧特征(key,val)做cross-attention。在得到帧间信息交互结果之后会经过也有deformable attention构建的self-attention模块,用于增强特征内部信息表达。最后就是接上一个解码器用于预测深度图了,它的结构如下:
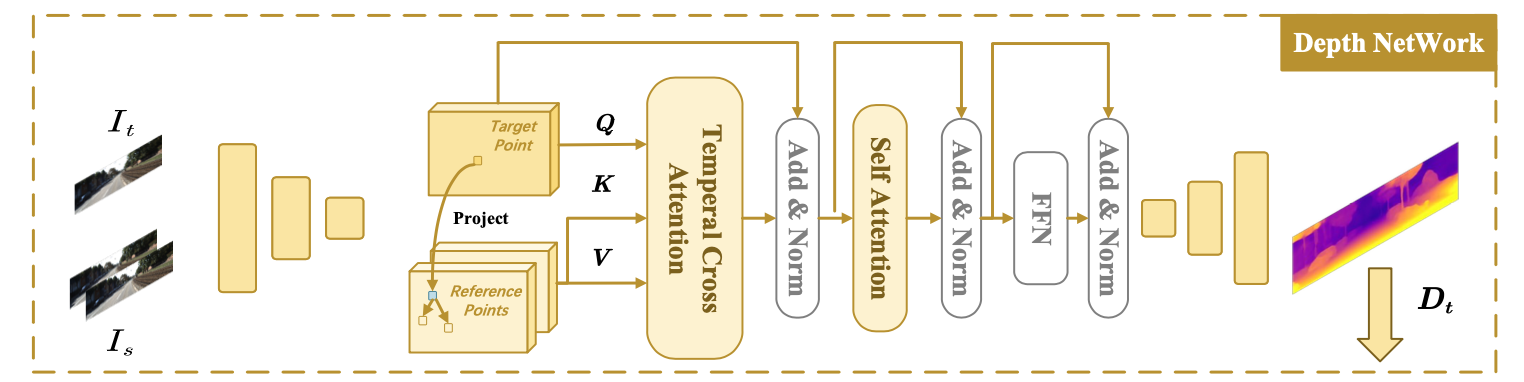
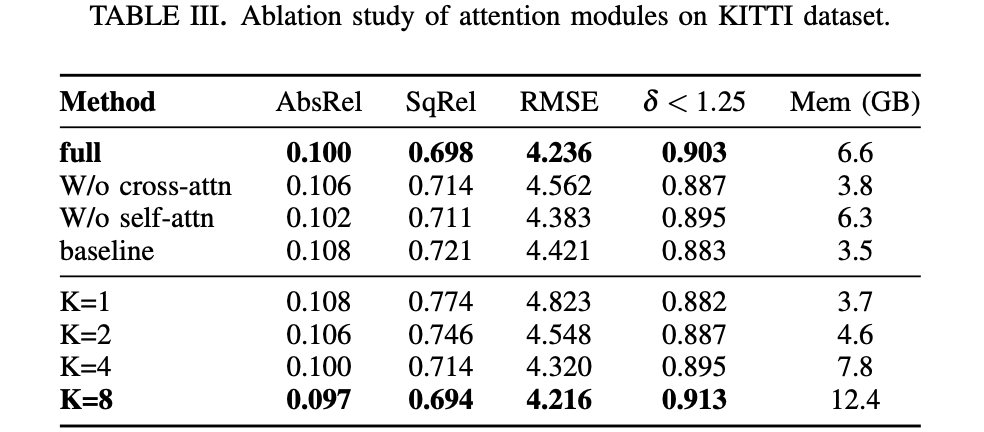
特征的优化模块还是有用的,只不过不是那么立竿见影:
运动估计网络:
在MonoDepth系列的经典网络中运动估计网络主要负责估计帧间的pose信息,这就导致对场景中的运动目标就没办法处理了,也就导致该种类型网络在运动目标深度的时候会出现“黑洞”的情况。在这篇文章中使用迭代的方式去估计场景中目标的运动变化 T r e s ∈ R 3 ∗ H ∗ W T_{res}\in R^{3*H*W} Tres∈R3∗H∗W,这里只估计目标的平移分量,对于旋转分量文章将其看作接近0的小值,不在网络的预测范围中。那么整体上运动信息估计部分的结构如下
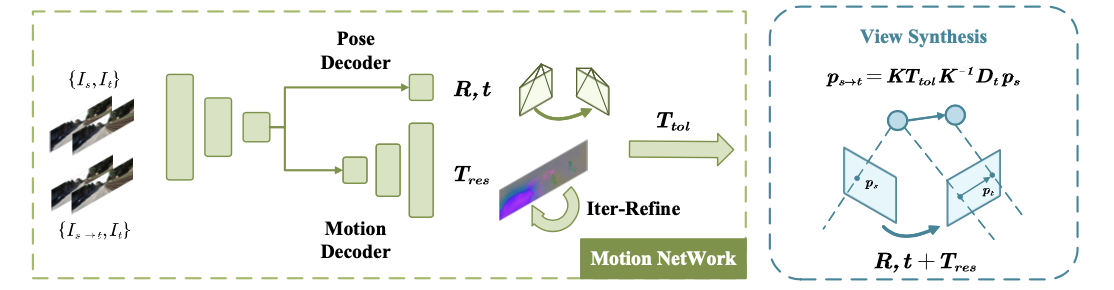
其实在上图中还没绘制出 T r e s T_{res} Tres迭代优化部分的网络 M ψ M_{\psi} Mψ,这个网络的输入是target图像和target图像到source图像的变换,首先对于帧间使用运动信息和深度信息构成的图像warp过程描述为:
I s → t = I s ⟨ p r o j ( D t , { R t → s , t t → s + T r e s } , K ) ⟩ I_{s\rightarrow t}=I_s\langle proj(D_t,\{R_{t\rightarrow s},t_{t\rightarrow s}+T_{res}\},K)\rangle Is→t=Is⟨proj(Dt,{
Rt→s,tt→s+Tres},K)⟩
而运动目标的运动信息描述为迭代的形式:
Δ T = M ψ ( I t , I t → s ) , T r e s = T r e s + Δ T \Delta T=M_{\psi}(I_t,I_{t\rightarrow s}),T_{res}=T_{res}+\Delta T ΔT=Mψ(It,It→s),Tres=Tres+ΔT
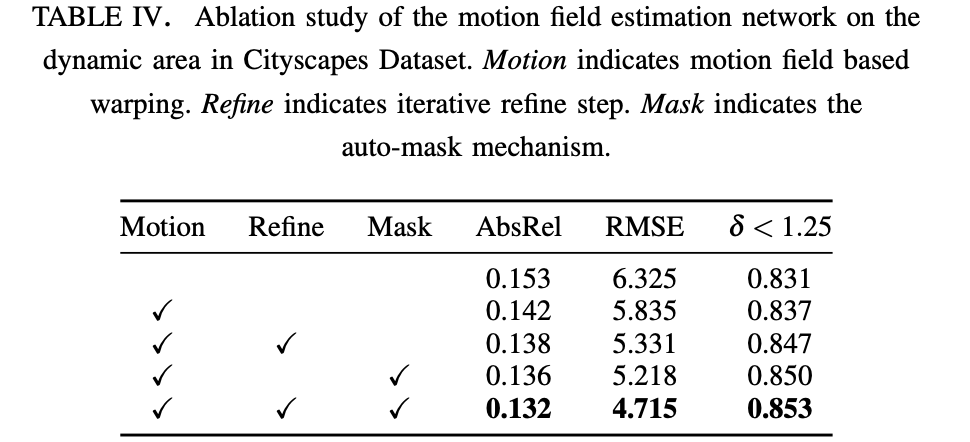
首先验证运动目标运动信息估计的有效性:
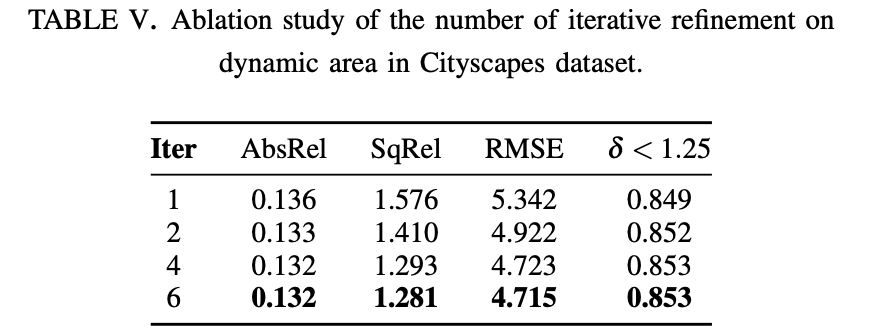
再看迭代次数对性能的影响:
损失函数:
首先对深度估计部分的约束就是经典自监督深度估计那套SSIM+L1+smooth:
L p = α 1 − S S I M ( I t , I s → t ) 2 + ( 1 − α ) ∣ ∣ I t − I s → t ∣ ∣ 1 + ∑ p ( ∇ D t ( p ) ⋅ e ∇ I t ( p ) ) 2 L_p=\alpha\frac{1-SSIM(I_t, I_{s\rightarrow t})}{2}+(1-\alpha)||I_t-I_{s\rightarrow t}||_1+\sum_p(\nabla D_t(p)\cdot e^{\nabla I_t(p)})^2 Lp=α21−SSIM(It,Is→t)+(1−α)∣∣It−Is→t∣∣1+p∑(∇Dt(p)⋅e∇It(p))2
而对于运动场景估计部分的越是是smooth+L1-norm(用于生成sparse的结果,毕竟大部分像素代表静态元素)的形式:
L m = ∑ p L g 1 ( T r e s ) + ∑ p ( ∇ T r e s ( p ) ⋅ e ∇ D t ( p ) ) 2 L_m=\sum_pL_{g1}(T_{res})+\sum_p(\nabla T_{res}(p)\cdot e^{\nabla D_t(p)})^2 Lm=p∑Lg1(Tres)+p∑(∇Tres(p)⋅e∇Dt(p))2
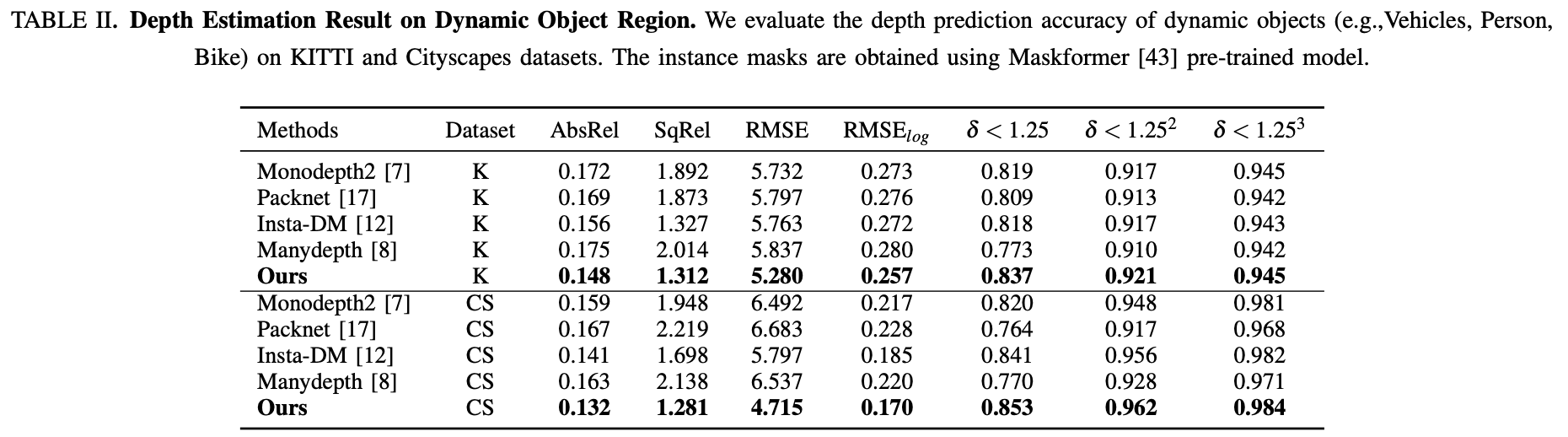
实验结果:
运动目标上的性能表现: