代码:GitHub - HKUDS/MMSSL: [WWW'2023] "Multi-Modal Self-Supervised Learning for Recommendation"
 背景
背景
一、现有模型局限性:现有的多模态推荐模型虽然引入多模态信息来增强item embedding。但模型的表示能力受限于用户行为稀疏性(可从两个方面考虑:1、例如文本特征是从视频评论中提取的,如果评论量太少则无法很好表示视频信息。2、用户兴趣通过交互过的物品进行表征,若与用户交互过的物品数量过少,则无法很好表示用户兴趣)。而真实环境下用户的交互行为是非常有限的,所以很难建模出用户准确偏好。
二、现有自监督学习中数据增强的局限性:数据增强时忽略了用于增强的多模态特征,可能会阻碍SSL任务提取信息的有效性。
The overlook of multi-modal characteristics for augmentation may hinder the effectiveness of their introduced auxiliary SSL tasks to distill modality-aware signals
METHODOLOGY
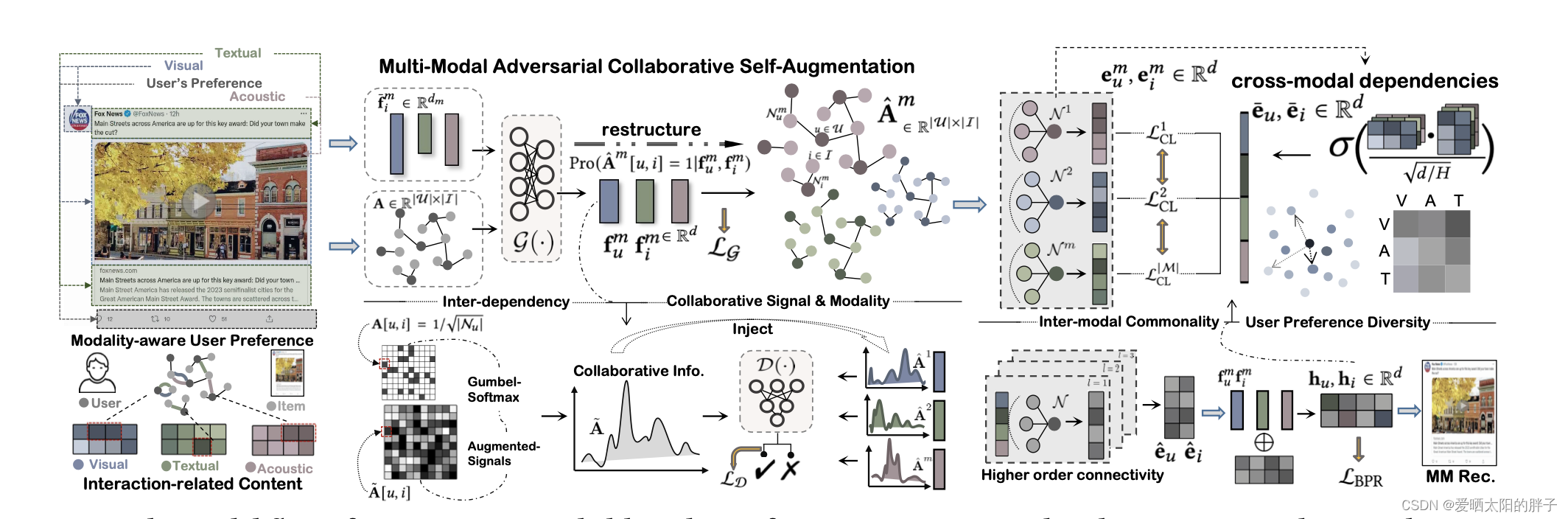
多模态中即包含每种模态独有的信息,又包含模态间相互作用的信息。本文采用两种方式对这两部分信息分别进行提取。
一、多模态视图
本文采用对抗学习的方式来捕捉更健壮的模态感知的用户行为偏好(即捕捉用户在模态m上的偏好)。
生成器( )
)
输入:用户和物品在模态m上的特征表示(,
);
输出:u和i发生交互的概率(实数),
作用:将生成器生成的fake数据,与真实交互数据放在一起,让判别起去判别真伪。
公式描述:
1、生成用户u和物品i在模态m上的特征表示:
,
,
:用户和物品的邻居节点
从公式中可以看到,为了充分利用协作信号,每一个节点的特征都是通过对邻居的节点的特征做归一化求和得到的。因为物品拥有原始特征,所以可以使用物品的原始特征生成用户的特征表示,在用用户的特征表示生成物品的。
2、通过全连接神经网络对特征进行降维。,
3、由和
生成用户-物品交互概率:
:生成的生成的fake交互矩阵(矩阵的每一项都是实数)。
为矩阵
中的一项,表示用户u-i在模态m上交互概率。
将和真实交互矩阵A(
,由0/1组成代表用户和物品是否发生过交互)纵向拼接在一起,交给判别器去判别真伪。
判别器
判别公式:
为数据矩阵中的一行,代表用户u的所有交互行为。
作用:生成器生成数据来迷惑判别器,判别器尽力识别虚假信息,两者相互优化,达到平衡时,生成器生成的数据和真实交互数据接近,判别器无法区别出fake数据。通过将判别器生成的猜测向真实的交互情况对其,使得用户/物品特征(,
)更能反映出真实交互信息。
补充:
交互矩阵A中元素为离散值(由0/1组成),生成器生成的猜测交互矩阵中元素为连续值(交互概率),两种数据形式不一样,可能会导致模型崩塌或者难以收敛所以论文对A进行了转化得到等价矩阵
。转化公式如下:
![]()
其中
优化方程minmax:
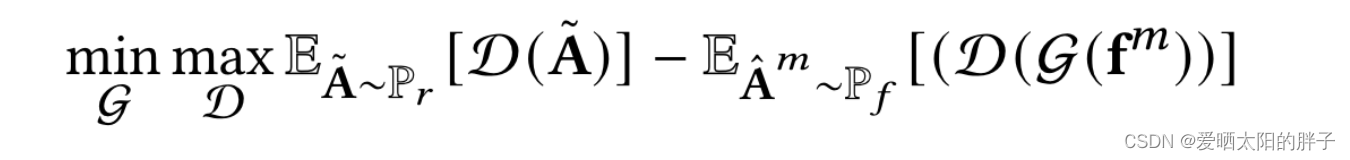
可以看到上面的公式有两部分组成min及max。内层的max通过最大化判别器区分真实数据之间的距离来训练判别器。固定判别器来看min,生成器的任务是生成猜测数据来迷惑判别器使其分辨不出真伪,通过最小化判别器判别真实数据和假数据之间的距离来优化生成器。
二、协同视图(跨模态对比学习)
捕捉模态间相互作用关系。
1、生成用户/物品的多模态潜在特征
,
其中为Xavier初始化id相关的embedding
2、提取u /i模态间关系
本文通过多头自注意力机制来提取u/i两两模态之间的关系来更新特征向量,公式如下:
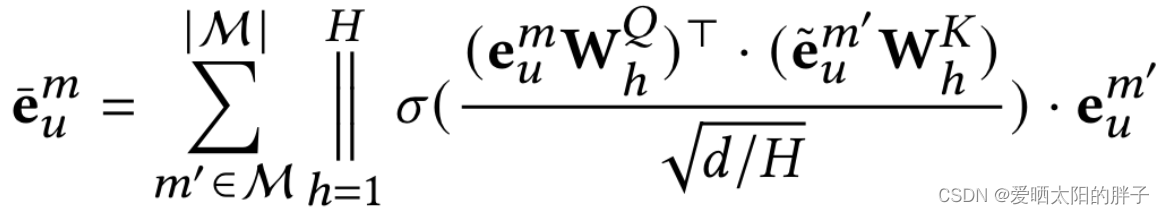
3、u/i多模态特征融合
本文采用平均池化的方式来进行融合,生成多模态用户/物品表示,下方为用户多模态特征融合的方式(物品):
![]()
4、注入协同信号
通过GNN向特征中注入协同信号
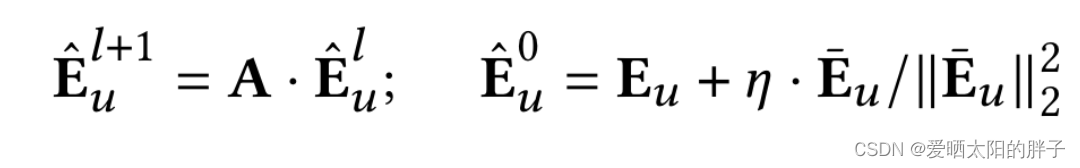
其中代表汇聚了l层邻居信息后的结果,
,
为邻居数,
id 相关embedding向量,
为用户的多模态表示。
并通过池化来生成协同特征表示
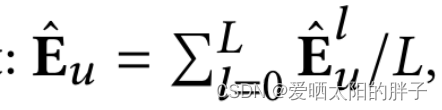
5、损失函数
本文采用的InforNCE,来最大化协同特征表示和最终表示之间的相互信息。
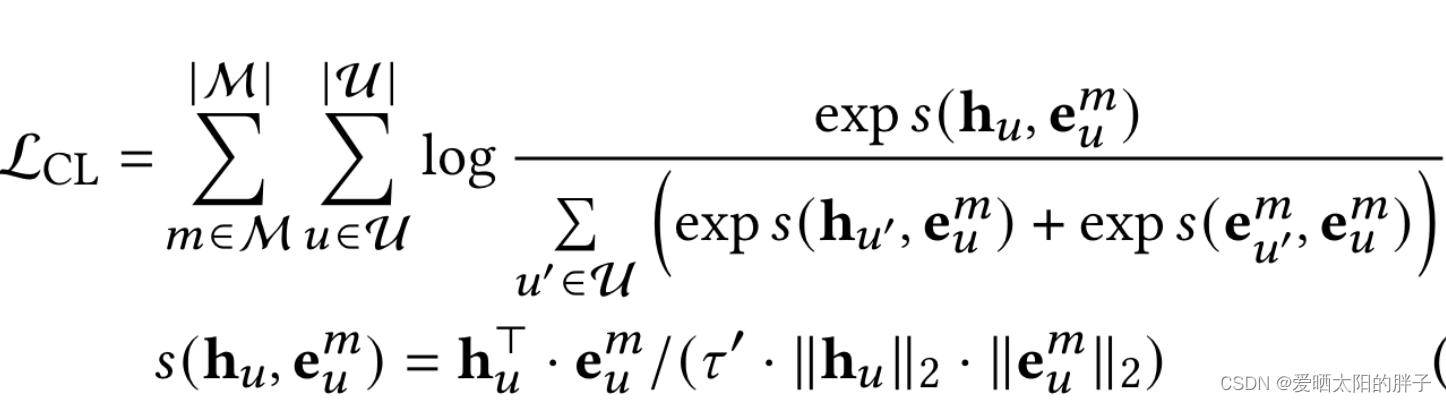
其中
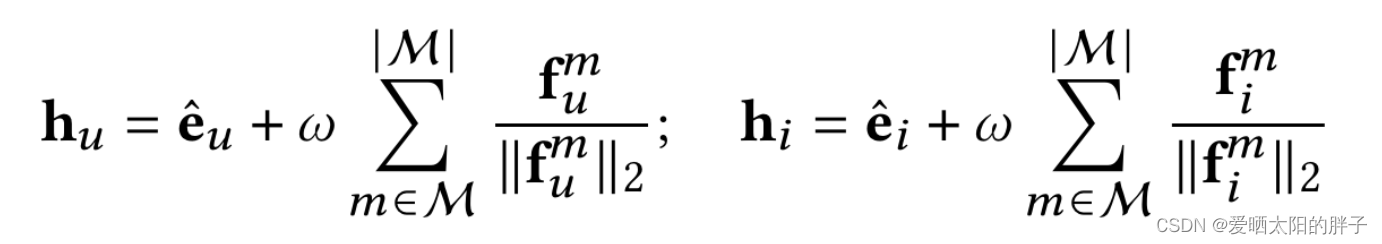
代表用户/物品的最终表示。
三、模型优化
损失函数如下:
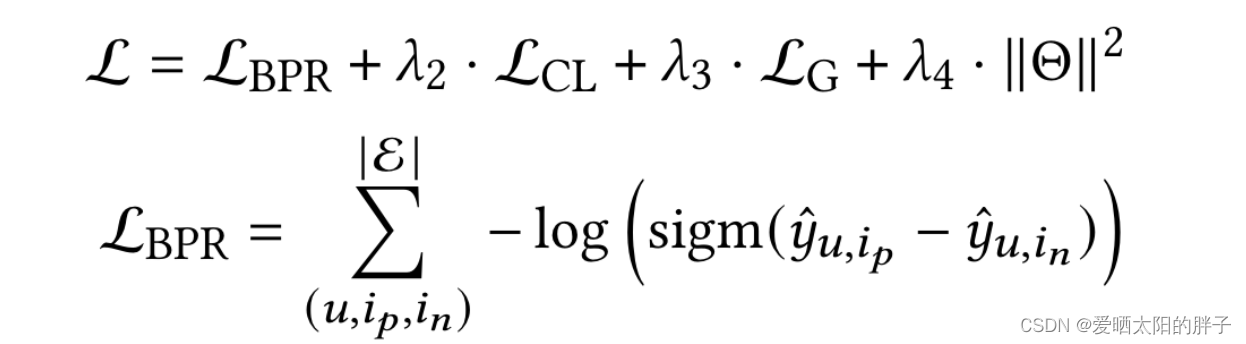
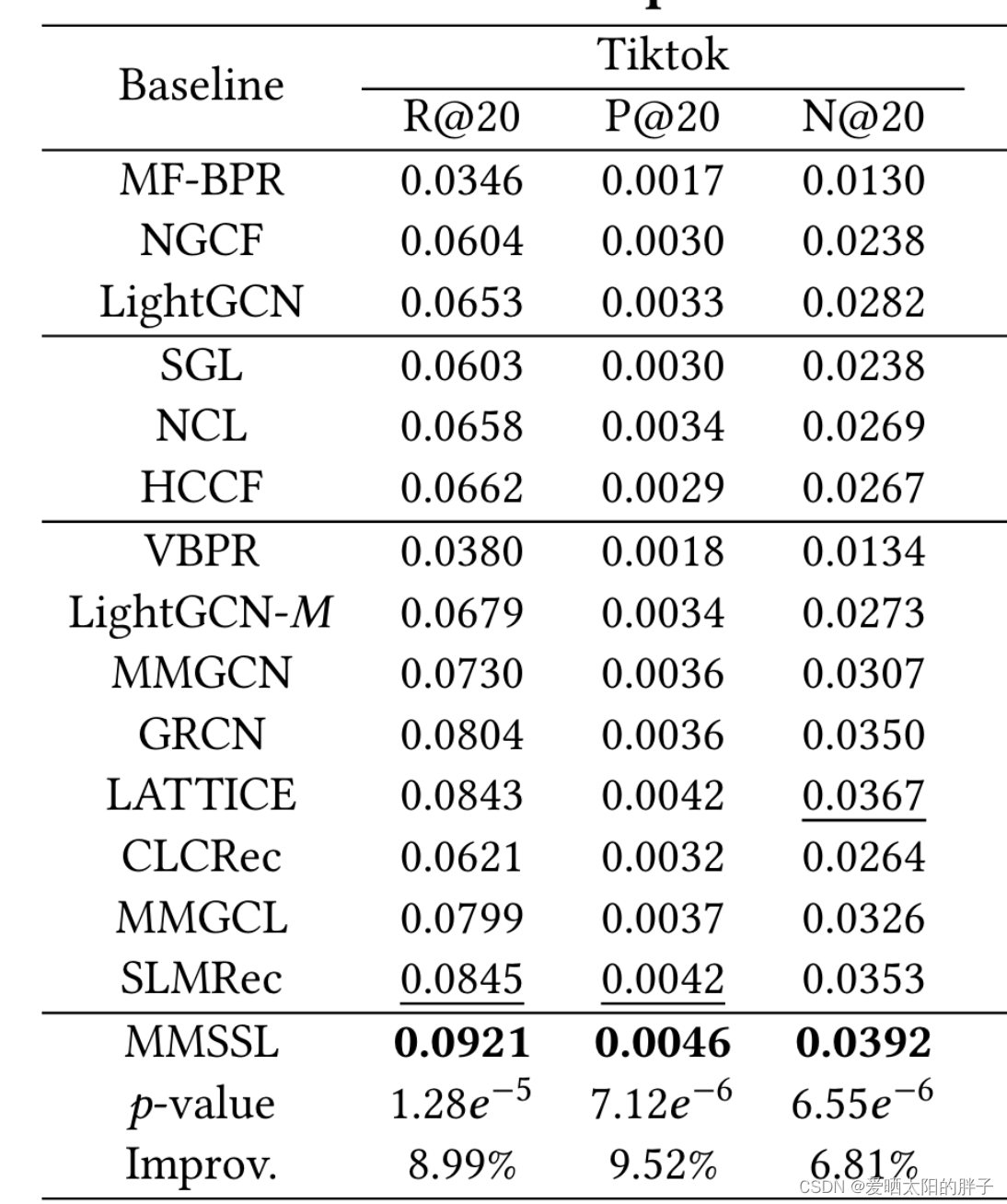
四、实验结果