论文信息
题目:MaskVO: Self-Supervised Visual Odometry with a Learnable Dynamic Mask
作者:Weihao Xuan, Ruijie Ren, Siyuan Wu, Changhao Chen
时间:2022
来源: IEEE/SICE International Symposium on System Integration (SII)
Abstract
深度学习的最新进展使移动机器人能够以自我监督的方式联合学习自我运动和深度图。
然而,现有的方法受到尺度模糊问题和环境问题的困扰,阻碍了实际应用。
我们的工作旨在通过提出一种自监督视觉里程计模型来解决这两个问题,该模型利用图像序列的时间依赖性并从单目相机产生尺度一致的运动变换。
我们提出的框架与新颖的掩模网络集成,以提供可学习的动态掩模,减少场景动态和照明变化的影响。
Introduction
本工作旨在通过提出MaskVO来解决上述两个问题。这种自我监督的 VO 模型学会从图像序列中生成准确且尺度一致的自我运动估计。请注意,我们的模型仅使用单目图像进行训练和测试。
该框架将之前的自监督 VO 模型 [6] 重新表述为顺序学习问题,通过循环神经网络从图像序列中提供视觉特征,以利用它们的时间依赖性。这样做,它为手头的任务提供了更合适的功能。
为了减少环境动态和场景照明变化的影响,我们提出了一种基于动态场景/观察条件的去噪自动编码器(DAE)的新型动态掩模网络。掩模网络是端到端可训练的,提供动态掩模来解决场景问题,以进一步提高性能。
总之,我们的贡献如下:
1)我们为自监督 VO 系统提出了一种新颖的可学习掩模网络,该网络提供动态掩模以消除环境问题的影响;
2)我们引入了一个时间感知的VO框架,该框架利用图像序列中视觉运动的时间依赖性,并提取适合姿势估计的特征,这进一步提高了模型性能;
3)我们在现有尺度一致的 VO 系统的共同基准上进行了实验,我们的模型优于它们。
Methodology
Architecture
这项工作的目的是提出一种自监督学习系统,从未标记的图像序列中重建尺度一致的自我运动。
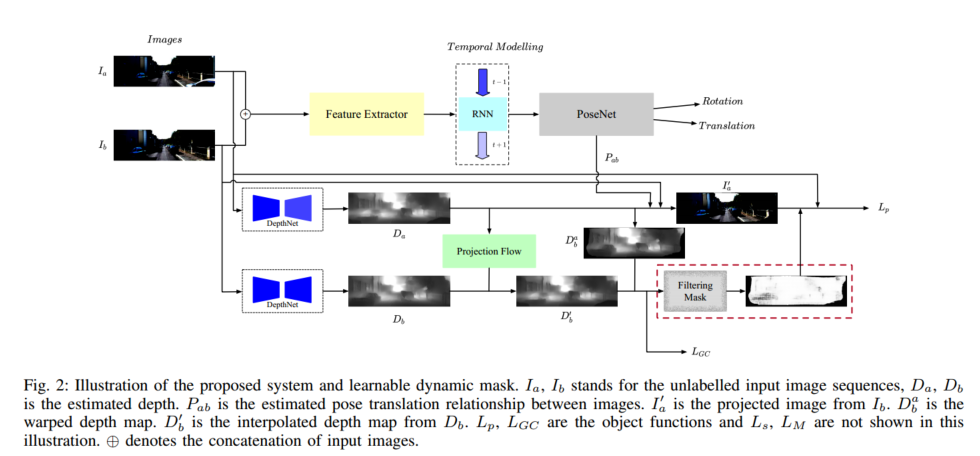
如图 2 所示,两个未标记的 RGB 图像 I a I_a Ia 和 I b I_b Ib 堆叠在一起并输入到特征提取器中。
I a I_a Ia 和 I b I_b Ib 是源图像和目标图像。与[6]、[12]不同,我们使用图像序列来利用视觉运动的时间依赖性。
特征时间建模模块提取图像序列的时间信息,由循环神经网络组成。
然后,6-DoF 位姿 P a b P_{ab} Pab 由位姿网络生成。同时,输入图像的深度图由深度网络生成。
投影图像 I a ′ I_{a}^{\prime} Ia′ 使用 D a 、 I b D_a、I_b Da、Ib和6-DoF位姿 P a b P_{ab} Pab通过等式5生成。
引入掩模网络将学习到的空间信息合并到框架中,减少场景动态的影响。真实图像 I a I_{a} Ia和合成 I a ′ I_{a}^{\prime} Ia′ 之间的差异可以用作自监督信号来构造光度损失。它可以约束并强制系统根据不同的输入图像序列估计姿态和深度。
Temporal-aware Feature Encoder
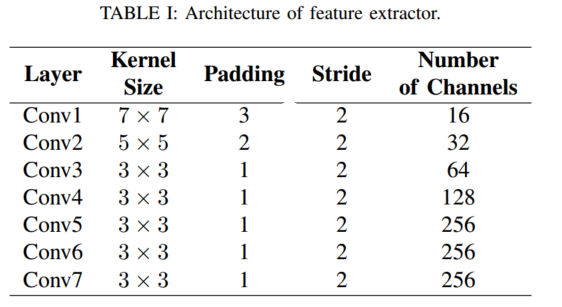
基于卷积神经网络 (CNN) 的特征提取器从两个串联图像中提取视觉特征,然后使用时间建模组件来利用这些特征的时间连接来实现更好的姿势估计。
与之前的工作[6]、[12]直接从两对图像中提取时间特征不同,我们将这些图像表示为一个序列,然后从该序列中提取特征。由于循环神经网络(RNN)能够捕获序列之间的依赖关系,因此它非常适合将 RNN 结构应用于 VO 问题 [16]。 RNN 维护其隐藏状态并使用以下序列更新它们:

为了处理长期图像序列的任务,利用了长短期记忆(LSTM)。在训练和测试过程中,我们在序列开头初始化隐藏状态。随着时间信息的引入,自我运动网络中提供了更合适的特征。它有助于解决长期位姿轨迹预测中的漂移问题。
Pose Network and Depth Network
Pose Network.如图 2 所示,PoseNet 结构被设计用于预测图像之间的相机旋转和平移。由于此步骤中获得的特征是由特征提取器仔细选择的,并且重点关注时间信息,因此利用两个全连接层(FCN)来根据高维特征预测 6-DoF 姿势。
Depth Network 这项工作中使用的深度网络架构基于 DispNetS [19],我们用深度残差块 [14] 替换卷积块。在我们的 DispResNet 中,除了预测 6 个不同尺度深度的 6 个层之外,所有卷积层和上卷积层均由 ReLU 激活。为了迫使预测的深度值处于正且合理的范围内,我们通过 1=(α·sigmoid(x) + β) 在不同尺度上添加非线性,其中 α = 10; β = 0:01。
Learn Dynamic Mask Network
我们的主要贡献是可学习的动态掩模网络。
通常,掩模用于解决场景动态和光照变化的问题,但现有的掩模仍然不足以处理这些问题。
例如,[12]和[8]是基于计算的方法,其中掩模是通过一对图像的深度图像的差异来计算的。因此,姿态估计精度与深度估计密切相关,这进一步阻止了这些掩模彻底去除动态对象。
[6]利用简单的编码器-解码器结构来生成掩码。它强制将 mask 训练得接近 1,以避免出现琐碎的结果。然而,这种基于学习的方法只是简单地生成不琐碎的掩模以及姿势估计过程。
在我们的工作中,我们发现深度差是掩模生成的有用信息源。在此背景下,我们提出了一种新型的基于去噪自动编码器(DAE)的可学习掩模网络,以减少场景动态和照明变化的影响。
受 Vincent 等人[20]的启发,我们设计了一种基于条件去噪自动编码器的动态掩模网络


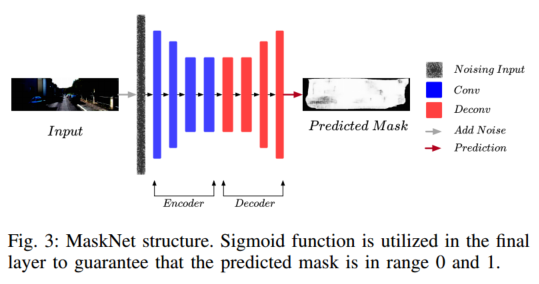
因此,掩码网络生成的掩码M在[0; 1]。我们的实验表明,学习到的掩模可以为静态/一致像素分配高权重,为动态/不一致像素分配低权重。我们提出的 MaskNet 结构可以生成更强大的掩模,其性能甚至比点积注意力的工作更好。
Image Synthesis Module
理想情况下,使用光度一致性损失作为约束假设:1)图像场景仅包括静态物体; 2)图像序列之间无遮挡; 3)表面是朗伯表面[6]。然而,在实践中,这些假设无法得到保证,因此我们利用几何一致性损失 LGC 和可学习的动态掩模 M 来解决这些限制。

Loss Function
方程中4的基本目标函数,主要涉及两个问题:
1)场景动态、遮挡和照明打破了静态场景的假设并影响模型性能;
2)深度和位姿的尺度不一致[6]。
为了解决这两个问题,我们提出了可学习的动态掩模 M 来处理动态场景、遮挡和照明。受[12]的启发,我们引入了几何一致性损失LGC,使框架能够产生比例一致的姿态估计。整体损失函数定义如下
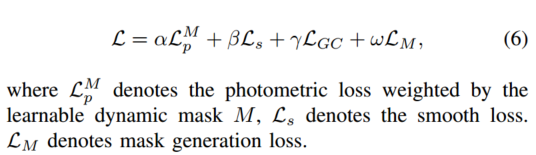
等式4的光度loss就变为

为了将掩模引入到整个系统中,我们将 M 添加到光度损失函数中:

由于缺乏信息,光度损失无法处理低纹理区域和均匀区域。方法[23]和[12]在生成深度图正则化之前利用平滑度损失。
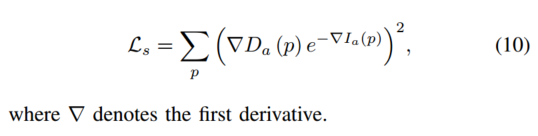
那么几何一致性损失定义为
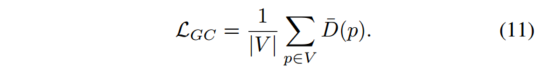
借助几何一致性约束,包括位姿估计模块和深度估计模块在内的整个框架将以尺度一致性进行训练