来源:
Georgescu, Mariana-Iuliana, et al. “Anomaly Detection in Video via Self-Supervised and Multi-Task Learning.” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021. Crossref, https://doi.org/10.1109/cvpr46437.2021.01255.
Official URL: CVPR 2021 Open Access Repository
Code:GitHub - lilygeorgescu/AED-SSMTL

目的:在对象级别通过自监督和多任务学习来实现视频中的异常事件检测
步骤:
- 首先使用预训练的检测器来检测对象
- 然后,我们训练一个三维卷积神经网络,通过联合学习多个代理任务来产生区分异常的特定信息:三个自监督任务和一个基于知识蒸馏的任务。
- 自监督任务包括:
- (i)识别向前/向后移动的对象(时间箭头 指的是跟随时间箭头方向 对象是向前还是向后移动)
- (ii)识别连续/间歇帧中的对象(判断对象运动的不规则性)
- (iii)重建特定于对象的外观信息。(重建的是中间帧)
- 知识蒸馏任务同时考虑分类和检测信息,当异常发生时,在教师和学生模型之间产生较大的预测差异。
对于几个任务不理解是什么可以看后面方法部分,论文中有一一介绍
据我们所知,我们是第一个将视频中的异常事件检测作为多任务学习问题进行处理的人,将多个自监督和知识提取代理任务集成到一个架构中。
我们的轻量级架构在三个基准上超越了最先进的方法:Avenue、ShanghaiTech和UCSD Ped2。此外,我们进行了一项消融研究,证明了在多任务学习环境中集成自监督学习和归一化特定提取的重要性。
主要贡献:
- 引入学习时间箭头作为异常检测的代理任务
- 我们将运动不规则性预测作为异常检测的代理任务
- 我们将模型提取作为视频异常检测的代理任务
- 我们将视频中的异常检测作为一个多任务学习问题,将多个自监督和知识提取任务集成到一个模型中
- 我们进行的实验表明,与最先进的方法相比,我们的方法在三个基准上取得了更好的结果。
补充知识:
霍金在《时间简史》中提出了“时间箭头”这个概念,来论证时间一定是向前流动,而不能向后倒回。
什么是时间箭头
广义地说,时间箭头是为我们指明时间方向的一些规律。依据这些规律,我们可以明确指出事件发生的先后顺序。
具体方法
动机和概述
动机:
通过单个代理任务(例如未来帧预测)对异常事件检测进行建模是次优的,因为代理任务与实际(异常检测)任务之间缺乏完美的对齐。为了减少模型与异常检测任务的不一致性,我们建议通过在多个代理任务上联合优化来训练模型。
训练:
首先,我们使用预训练的YOLOv3检测每一帧中的对象,获得边界框列表。对于第i帧中检测到的每个对象,我们通过简单地从第i帧裁剪相应的边界框来创建以对象为中心的时间序列 {i−t, ..., i−1, i, i+1, ...., i+t}(不执行任何对象跟踪),将每个裁剪图像的大小调整为64×64像素。为了便于说明,我们在网络结构图中设置了t=2。由此产生的以对象为中心的序列是我们的3D CNN的输入。我们的架构由共享的3D CNN和四个分支(预测头)组成,每个分支对应一个代理任务。
测试:
在推理过程中,通过平均每个任务的预测分数来计算异常分数。对于时间流向和运动不规则性任务,我们采用时间序列向后移动的概率和时间序列间歇性的概率。对于中间帧预测任务,我们考虑了真实值和重建对象之间的平均绝对差。异常分数的最后一个分量是YOLOv3预测的类概率与我们的知识提取分支预测的相应类概率之间的差异。我们不包括推理时的ResNet-50预测,以保持我们框架的实时处理。
网络结构
网络架构由一个共享的CNN和四个独立的预测头组成,共享的CNN使用3D卷积(conv)来建模时间依赖关系,而单个分支仅使用2D卷积
当一次考虑一个代理任务时,我们使用由三个conv层组成的相对浅而窄的神经架构观察到了准确的结果。当我们转向在多个代理任务上联合优化我们的模型时,我们观察到需要增加神经网络的宽度和深度,以适应多任务学习问题的复杂性增加。因此,考虑到浅、深(网络的层数)、窄和宽(通道数)结构的所有可能组合,我们采用了一组四种神经结构。这些是:浅+窄、浅+宽、深+窄和深+宽。每个3D CNN架构的详细配置如表1所示。

对于每个网络配置,RGB输入的空间大小为64×64像素。3D conv层使用3×3×3的滤波器。每个转换层后面都有一个batch normalization layer和一个ReLU activation。
- 我们的浅+窄3D CNN由三个3D conv层和三个3D max-pooling层组成。其第一个3D conv层由16个滤波器组成,接下来的两个conv层分别由32个滤波器组成。padding 设置为“same”,stride 设置为1。我们只对前两个3D max-pooling layers 执行 spatial pooling 。pooling size 和 the stride 都设置为2。最后一个3D max-pooling layer 执行global temporal pooling,在空间级别上保持与前两个池层相同的配置。只使用temporal pooling一次(在最后一个池层中)使我们能够为每个代理任务使用不同的时间大小。
- 在浅+宽配置中,我们通过将每个conv层中的滤波器数量加倍来更改3D CNN。
- 对于深度+狭窄架构,我们将3D conv层的数量从三层增加到六层。
- 最后,在深+宽配置中,相对于浅+窄模型,我们将每个conv层中的层数和滤波器数加倍。
在中间对象预测头中,我们结合了一个由上采样层和基于3×3滤波器的2D conv层组成的解码器。上采样操作的数量始终等于3D CNN中最大池层的数量。类似地,解码器中2D conv层的数量与3D CNN中3D conv层的数量匹配。每个上采样操作都基于最近邻插值,将空间支持度增加了2倍。为了重建RGB输入,解码器中的最后一个conv层只有三个滤波器。
其他三个预测头共享相同的配置,具有一个具有32个滤波器的2D conv层和一个2×2的最大池层。最后一层是一个全连接层,有两个神经元来预测对象沿着时间箭头的移动方向和运动不规则性,或者1080个神经元(1000个ImageNe类和80个MS COCO类)预测的教师网络输出的分类分数
代理任务和联合学习
任务1:时间箭头
为了在对象级别预测时间箭头,我们从每个以对象为中心的序列中生成两个标记的训练样本。
- forward motion(class 1):第一个样本按时间顺序提取帧,即 (i−t, ..., i−1, i, i+1, ..., i+t)
- backward motion(class 2): 第二个样本按相反顺序获取帧,即 (i+t, ..., i+1, i, i−1, ..., i−t)
在推断过程中,我们预计对于具有异常运动的对象,时间箭头更难预测 (这里就表明为什么要采用时间箭头这个任务)
使用交叉熵损失来训练时间箭头部分:
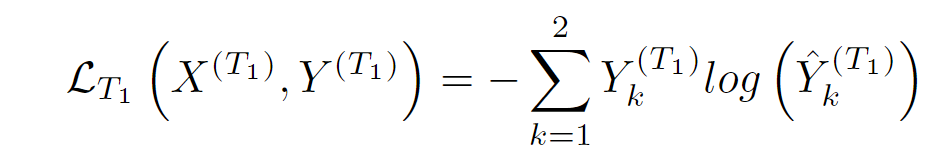
其中:
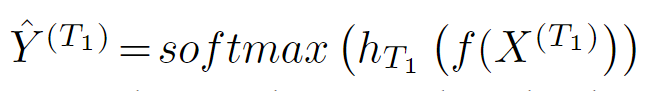
这里![]() 是共享的3D CNN,
是共享的3D CNN,![]() 是时间箭头头部网络。
是时间箭头头部网络。![]() 是大小为(2·t+1)×64×64×3的正向或反向以对象为中心的序列。
是大小为(2·t+1)×64×64×3的正向或反向以对象为中心的序列。![]() 是
是![]() 的真值标签的一个one-hot encoding。
的真值标签的一个one-hot encoding。
T1表明的就是针对第几个任务,下同。
任务2:运动不规则
假设可以通过不规则运动模式识别一些异常,我们训练我们的模型来预测以对象为中心的序列是否具有连续或间歇性帧(一些帧被跳过)。为了学习运动不规则性,我们从每个以对象为中心的序列中生成两个带标签的训练样本。
第一个示例在连续帧中捕获一个从 i-t 到 i+t 的对象,相应的类是regular motion (类别1)
通过保留帧 i,然后逐渐添加 随机选择 t 个的过去帧 和 t 个的后续帧 来创建间歇性的以对象为中心的序列。(间歇性序列的获取)。通过使用{1,2,3,4}范围内的随机间隙跳过帧来选择间歇帧。间歇性以对象为中心的序列被标记为 irregular motion (类别2)
利用交叉熵损失训练运动不规则头:

其中,
![]()
![]() 是不规则运动部分
是不规则运动部分
![]() 是大小为(2·t+1)×64×64×3的规则或不规则以对象为中心的序列
是大小为(2·t+1)×64×64×3的规则或不规则以对象为中心的序列
任务3:中间边界框预测
3D CNN模型还学习了重建在正常训练视频中检测到的对象。从每个以对象为中心的序列中,我们选择从帧 {i − t, ..., i − 1, i + 1, ..., i + t} 中裁剪的图像样本,形成大小为(2·t)×64×64×3的以输入对象为中心的序列![]() ,中间图像对应于第 i 帧中的边界框,表示大小为64×64×3的目标输出
,中间图像对应于第 i 帧中的边界框,表示大小为64×64×3的目标输出![]()
当我们遇到异常运动时,例如一个人跑步,该人以输入对象为中心的序列将不包含足够的信息,模型无法准确重建中间边界框,因此被标记为异常。
使用 L1损失学习中间边界框预测任务:
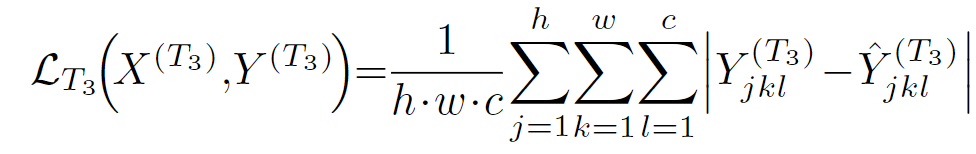
其中,
![]()
![]() 中间边界框预测头
中间边界框预测头
![]() 是输出的大小,(h=64、w=64和c=3)
是输出的大小,(h=64、w=64和c=3)
任务4:模型蒸馏
一方面,我们的3D CNN模型学习预测ResNet-50 (在ImageNet上预训练)最后一层(就在softmax之前)的特征。另一方面,3D CNN模型 通过 预训练的yolov3 (在 COCO上预训练好的)进行类别概率预测。
在蒸馏过程中,我们的模型学习了教师网络对正常数据的预测行为。在推理过程中,当我们遇到外观异常或属于训练过程中未看到的对象类别的对象时,我们期望我们的学生网络和YOLOv3老师网络之间存在较高的预测差异。
为了节省宝贵的计算时间,我们在推理过程中避免使用ResNet-50。我们注意到,YOLOv3仅在每个帧 i 上应用一次,每个检测到的对象的相应类概率在模型蒸馏期间已经可用。在训练期间,我们仍然需要将每个对象传递给ResNet-50,以提取pre-softmax features。
为了从YOLOv3和ResNet-50教师网络那里提取知识,我们的学生网络3D CNN模型接收到与ResNet-50相同的输入,并学习预测ResNet-50的 pre-softmax features![]() 和YOLOv3预测的类别概率
和YOLOv3预测的类别概率![]() 。
。
通过最小化L1损失函数来学习模型蒸馏任务:
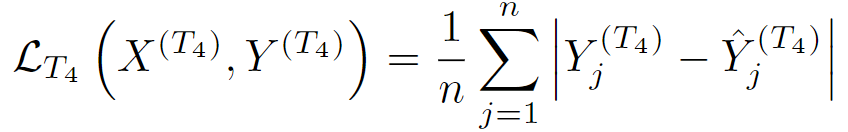
其中,
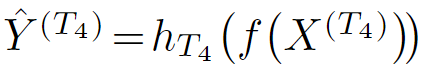
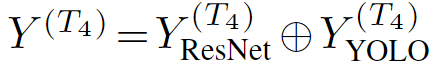
![]() 是包含检测对象的输入图像。
是包含检测对象的输入图像。![]() 是知识蒸馏头部。
是知识蒸馏头部。
联合损失
我们的3D CNN模型是通过在上述四个代理任务上联合优化来训练的。因此,该模型使用联合损失函数进行训练:
![]()
其中 λ∈(0,1] 是调节知识蒸馏任务重要性的权重。我们从经验上观察到,任务4(知识蒸馏)通常比其他损失函数更高,在没有正则化项的情况下主导着联合损失。在我们的实验中,我们在将我们的框架应用于异常检测任务之前,根据联合损失的验证值微调 λ 。
推理
在推理过程中,我们利用 YOLOv3来检测每个帧中的对象 i。对于每个对象,我们通过剪切帧 { i - t,... ,i - 1,i,i + 1,... ,i + t } 中的边界框来提取对应的以对象为中心的序列 X。
我们通过神经网络模型传递每个以对象为中心的序列,分别获得输出![]() 、
、![]() 、
、![]() 和
和![]() 。
。
对于时间箭头代理任务,将时间序列向后移动的概率作为异常分数。
对于运动不规则性任务,我们认为无间隙测试序列 X 间歇性的概率是一个良好的异常指标。
对于中间边界框预测任务,重建和真实中间对象之间的平均绝对误差 作为中间包围盒预测头提供的异常分数。
对于知识蒸馏任务,我们考虑了Yolov3预测的类概率与模型预测的类别概率之间的平均绝对差。
我们计算对象的最终异常分数,是每个预测头给出的异常分数的平均值:
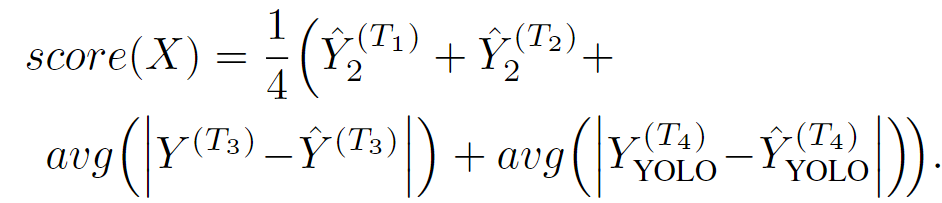
接下来,我们在每个帧的像素级异常图中重新组合检测到的对象。因此,我们可以很容易地在任何给定的帧中定位异常区域。为了创建平滑的像素级异常图,我们应用了三维平均滤波器。某一帧的异常分数由相应异常图中的最大分数给出。通过应用时间高斯滤波器获得最终帧级异常分数。
对象级别与帧级别检测
虽然在对象级别执行异常检测可以准确定位异常,但缺点是YOLOv3的检测失败(由于对象类别有限或性能较差)会转化为误报。为了解决这个限制,我们可以在框架级别应用我们的框架,从 pipeline 中删除YOLOv3,并将其他组件保留在适当的位置。通过在后期融合帧级和对象级异常分数,我们可以恢复以对象为中心的框架的一些误判。在我们的实验中,我们报告了基于后期融合的框架的结果,以及分别在对象级别和帧级别的结果。
实验部分
数据集
我们在三个基准数据集上进行了实验:Avenue、ShanghaiTech和UCSD Ped2。每个数据集都有预定义的训练集和测试集,异常事件仅在测试时包含。
Avenue:
Avenue数据集包含16个活动正常的训练视频和21个测试视频。大街上发生的异常事件与人们奔跑、投掷物体或朝错误方向行走有关。每个视频的分辨率为360×640像素。
ShanghaiTech:
ShanghaiTech是视频中用于异常检测的最大数据集之一。它由330个训练视频和107个测试视频组成。训练视频仅包含正常事件,而测试视频包含正常和异常序列。异常事件的例子有:在步行区抢劫、跳跃、打架和骑自行车。每个视频的分辨率为480×856像素。
UCSD Ped2:
UCSD Ped2包含16个正常活动的训练视频和12个测试视频。异常事件的例子是自行车手、滑冰者和行人区的汽车。每个视频的分辨率为240×360像素。
Avenue:Avenue Dataset
ShanghaiTech:Shanghaitech Vision and Intelligent Perception(SVIP) LAB
UCSD Ped2:UCSD Anomaly Detection Dataset
实施细节
评估措施
作为我们的主要评估指标,我们考虑了相对于真实帧级注释计算的曲线下面积(AUC)。帧级AUC度量是相关工作中最常用的度量。许多相关工作也报告了UCSD Ped2数据集的像素级AUC。正如Ramachandra等人[37]所解释的那样,像素级AUC是一个有缺陷的评估指标。因此,我们报告了我们在UCSD Ped2上基于区域的检测准则(RBDC)和基于轨迹的检测准则(TBDC)的性能。Ramachandra等人[37]最近引入了这些指标,以取代常用的像素级和帧级AUC指标。
[37] Bharathkumar Ramachandra and Michael Jones. Street Scene: A new dataset and evaluation protocol for video anomaly detection. In Proceedings of WACV, pages 2569-2578, 2020.
参数设置与调整
我们框架的第一步是基于YOLOv3的对象检测。对于Avenue和ShanghaiTech,我们保持检测的置信度高于0.8。由于UCSD Ped2的分辨率较低,我们将检测置信度设置为0.5。我们在训练和推理期间使用相同的置信阈值。
我们使用每个训练视频中前85%的帧在代理任务上训练我们的模型,保留最后15%在每个代理任务上验证模型。在过渡到异常检测之前,我们在验证集上微调参数 t 和 λ 。对于 t ,我们考虑了{1,2,3,4}中的值。当我们在 t=3 时获得最佳结果时,我们在所有异常检测实验中使用该值。因此,以对象为中心的时间序列是7×64×64×3的张量。考虑{0.1、0.2、0.5、1.0}中的值,我们微调了联合损失中![]() 重要性的参数 λ 。最终在UCSD Ped2上获得了λ=0.5的最佳结果,在Avenue和ShanghaiTech上分别获得了 λ=0.2 的最佳结果。因此,我们报告了这些最佳设置下的异常检测结果。
重要性的参数 λ 。最终在UCSD Ped2上获得了λ=0.5的最佳结果,在Avenue和ShanghaiTech上分别获得了 λ=0.2 的最佳结果。因此,我们报告了这些最佳设置下的异常检测结果。
使用Adam优化器对每个神经网络进行30个epoch的训练,学习率为0.001、保留Adam其他参数的默认值。由于计算资源的限制,我们使用小批量的256个样本(浅+窄体系结构)、128个样本(深+窄和浅+宽体系结构)和64个样本(深+宽体系结构)训练模型。对于每个模型,我们选择代理任务上验证错误最低的 checkpoint 来执行异常检测。
异常检测结果
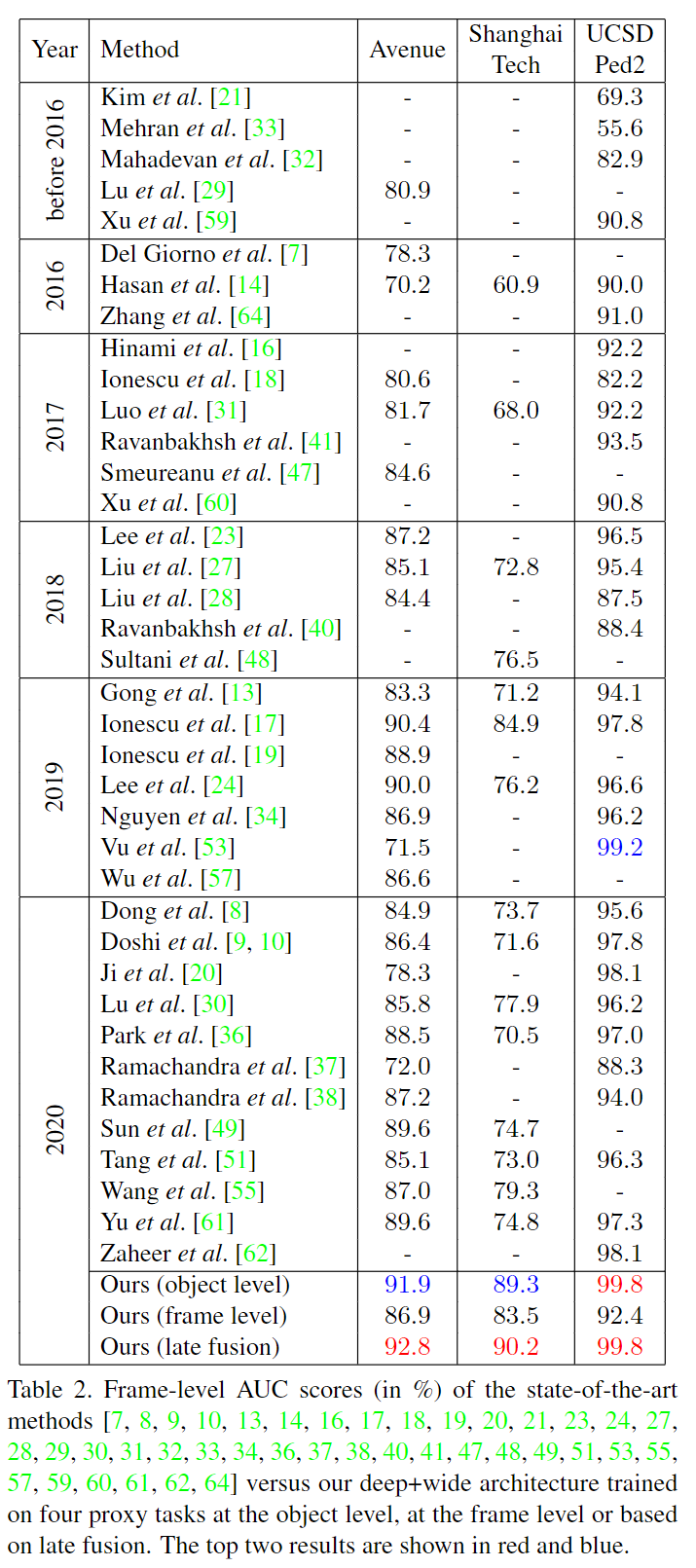
在表2中,我们展示了我们的对象级、帧级和后期融合框架与最先进方法的比较结果,报告了以下三个平台上的帧级AUC分数
Results on Avenue.
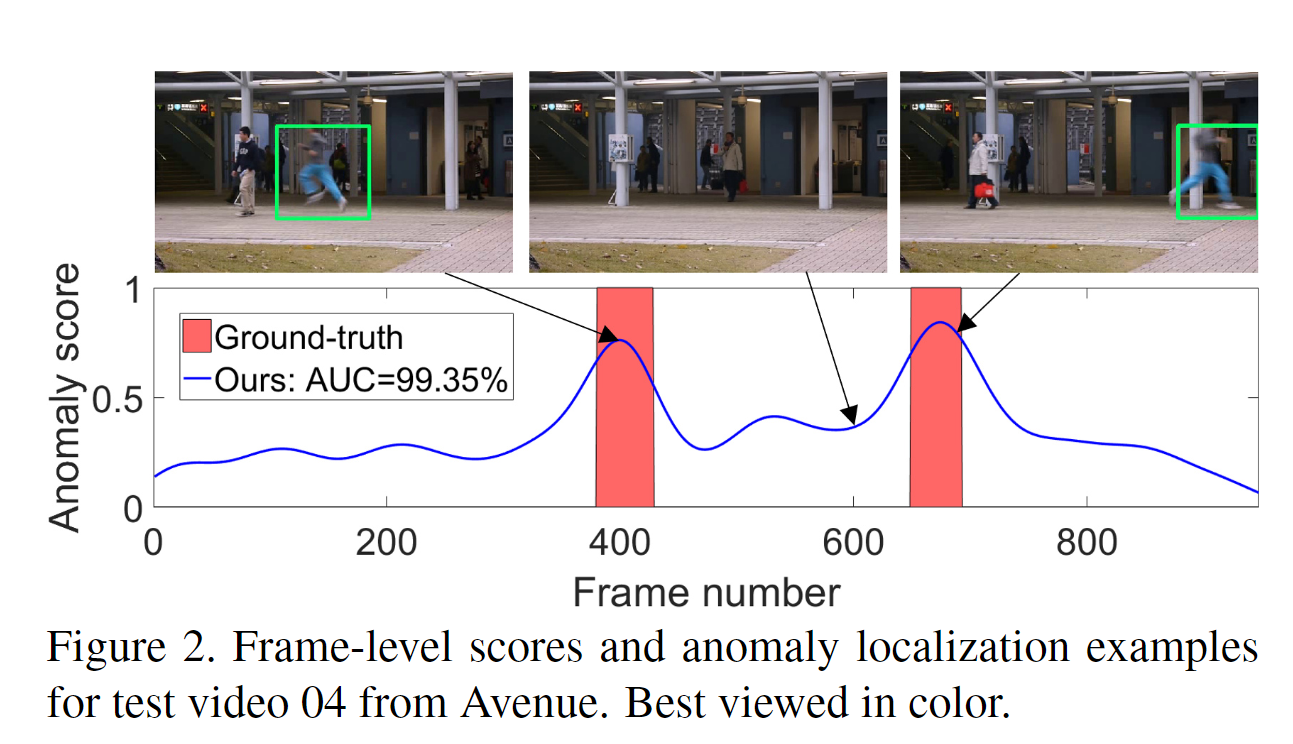
只有两种方法[17,24]在Avenue上超过90%的阈值。我们在对象级应用的框架获得了91.9%的帧级AUC,比最先进的方法[17]高出1.5%。当我们在帧级应用我们的框架时,我们的性能显著下降,但该方法仍然能够优于一些最近的工作[8、9、20、30、37、51]。当我们将对象级异常分数与帧级异常分数融合时,我们的性能得到了提高,达到了92.8%的最先进的帧级AUC。在图2中,我们展示了一组异常定位示例以及测试视频04的帧级异常分数。我们观察到,我们的方法与真值帧级注释有很好的相关性。
Results on ShanghaiTech.
在ShanghaiTech上,我们的后期融合方法优于所有以前的作品,达到了90.2%的最先进性能,比以前的最先进方法[17]高出了5.3%。值得注意的是,我们是第一个在ShanghaiTech上达到超过90%的帧级AUC分数。除[17]外,我们的方法比所有其他最先进的方法至少高出10.9%。在图3中,我们展示了异常定位示例以及测试视频03_0035的帧级异常分数。我们的方法与真值注释相关性良好。

Results on UCSD Ped2.
UCSD Ped2是最流行的视频异常检测基准之一,有23个作品报告的帧级AUC分数超过90%。目前最先进的方法[53]报告的帧级AUC为99.2%。尽管如此,我们的方法仍然超越了所有以前的作品,在UCSD Ped2上达到了99.8%的最先进的帧级AUC。
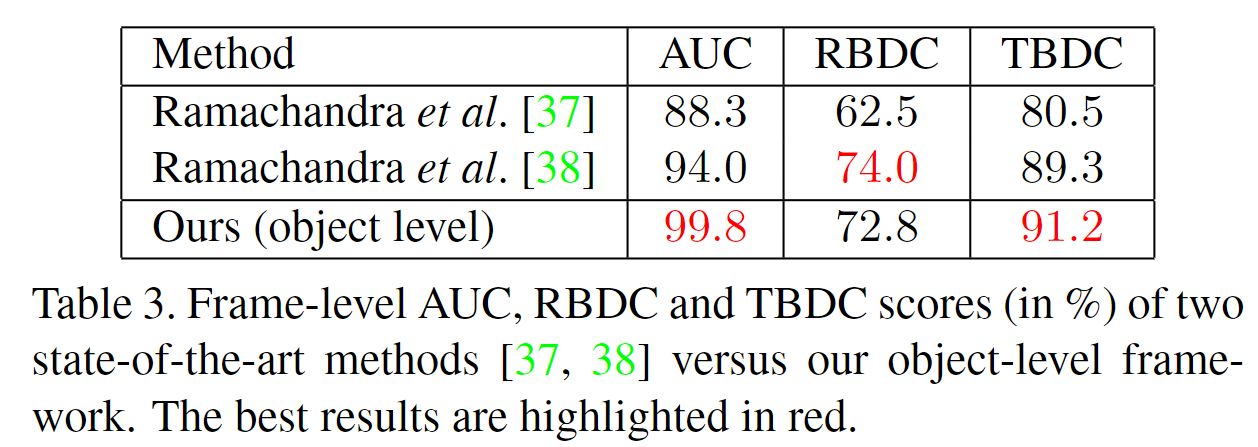
由于RBDC和TBDC是最近的评估协议的一部分,因此只有两种方法[37,38]可以与表3中的方法进行比较。我们在所有指标方面都优于第一种方法[37]。我们在TBDC方面也比第二种方法高1.9%,在帧级AUC方面比第二种方法高5.8%,我们的RBDC得分略低。这些结果表明,我们的方法可以准确定位异常。
Ablation Study
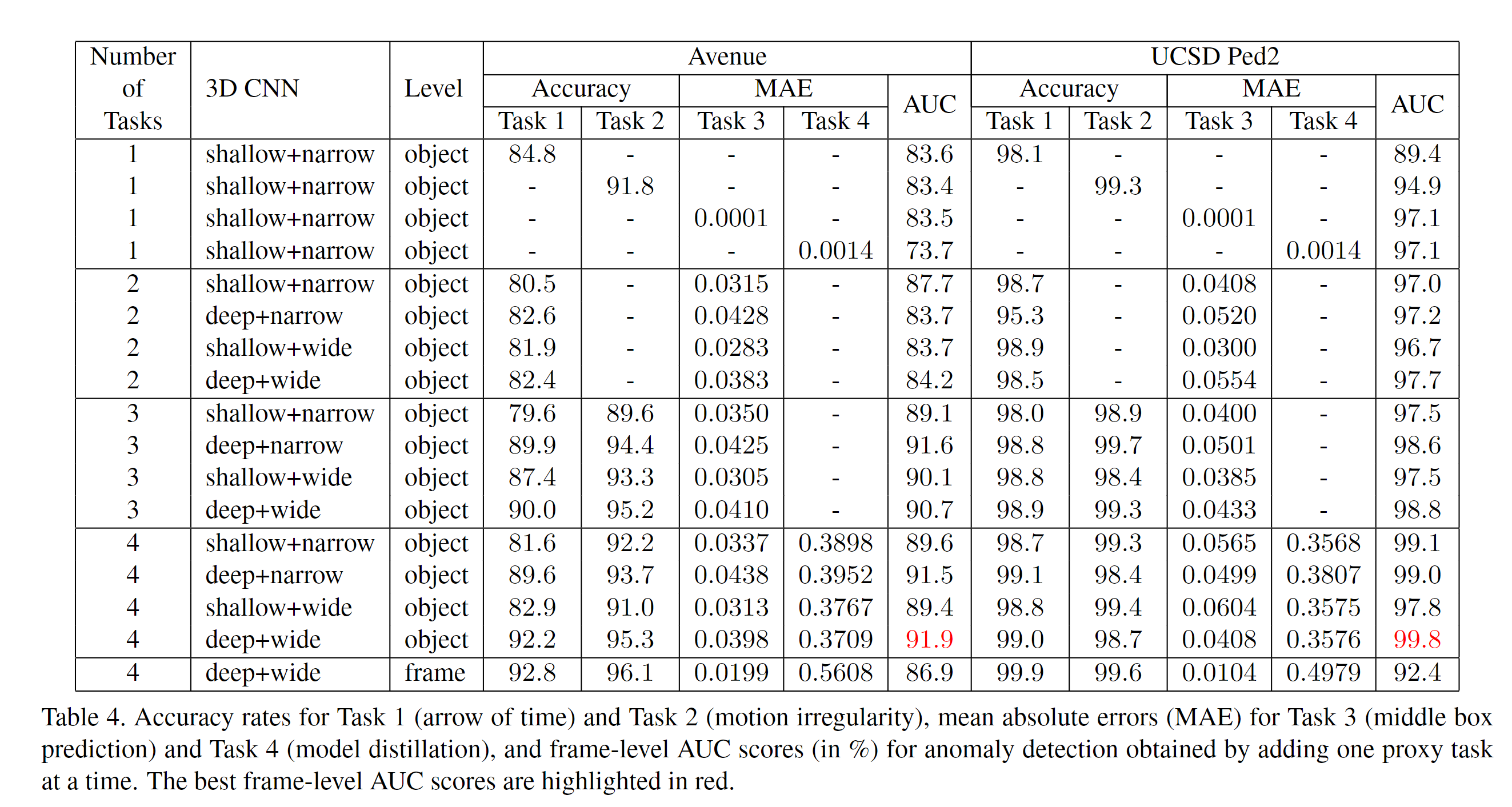
我们在Avenue和UCSD Ped2上进行了消融研究,以评估在我们的联合多任务框架中包含每个代理任务的益处。表4给出了相应的结果。
Conclusion
在这项工作中,我们提出了一种新的基于自监督和多任务学习的异常检测方法,在Avenue、ShanghaiTech和UCSD Ped2三个基准上给出了全面的结果。据我们所知,我们的方法是第一个也是唯一一个在所有三个基准上都超过90%阈值的方法。此外,我们进行了一项消融研究,展示了联合学习多个代理任务用于视频异常检测的好处。在未来的工作中,我们将考虑探索额外的代理任务,以进一步提高我们的多任务框架的性能。