动机
基于轮廓的检测方法(预测多边形的点、贝塞尔曲线控制点),由于粗略的位置查询建模,可能会实现次优化的训练效率和性能。使用的点标签形式暗示了人类的阅读顺序,阻碍了我们观察到的检测稳健性。基于这两个问题,作者提出一种简洁的动态点文本检测转换器网络:DPText-DETR
方法概述
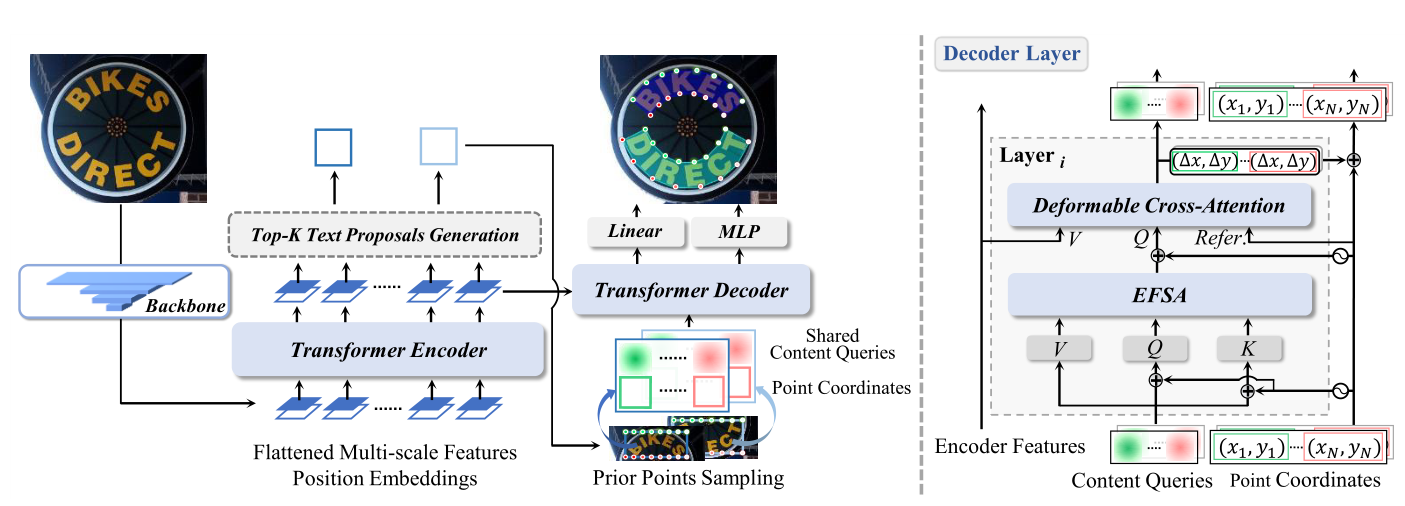
1. 图片输入到 CNN 主干 + Transformer 编码器进行特征提取,在最终的编码层生成K个轴对齐框(输入图像中有多少个文本实例,K就等于多少) ,利用这些轴对齐框的中心点和比例信息,在顶部和底部均匀地采样一定数量的初始控制点坐标,用作可变形交叉注意力模块的合适参考点。
2.在解码器中对采样的控制点点坐标进行编码,并将其添加到相应的控制点内容查询中,形成复合查询。复合查询首先被发送到 EFSA 以进一步挖掘它们的相对关系,再馈送到可变形交叉注意力模块,然后采用控制点坐标预测头逐层动态更新参考点 。预测头用于生成每个文本实例的类置信度分数和 N个控制点坐标。
Explicit Point Query Modeling(EPQM)
EPQM 包括:先验点采样和点更新。
a. 先验点采样。
TESTR模型:提出轴对齐框(矩形框)转换为多边形框的方案
在编码层的最后一层,由前 K 个提议生成器生成 K 个轴对齐框(一张图片中,有多少个文本实例,K 就等于多少),这些轴对齐框被 N 个控制点内容查询共享。
因此,TESTR 中的复合查询可表示为
其中,P表示复合查询的位置部分,C 表示复合查询的内容部分。 是正弦位置编码函数,后跟线性和归一化层。(x, y, w, h) 表示每个轴对齐框的中心坐标和大小。
是 N 个可学习的控制点内容查询,由 K 个复合查询共享。TESTR 这种方式中,不同的控制点内容查询共享相同的轴对齐框先验信息,在一定程度上与点目标不匹配。内容查询缺少了各自的显示位置,无法在框子区域中进行利用。
针对上述问题,本文作者做出改进。
在符合查询公式中,不使用(x, y, w, h)。而是在每个轴对齐框的顶部和底部均匀的采样 N/2 个坐标点(即初始控制点/先验点),采样公式如下:
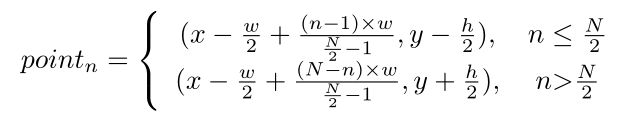
为位置先验,即显示位置。生成复合查询的完整显示点公式如下:
这样,N 个控制点内容查询享有各自的显示位置先验。
区别:
在 TESTR 的复合查询
中,每一个控制点内容查询
加的是 (x, y, w, h);而本文中,
加的是
TESTR 通过轴对齐框(中心和大小)生成位置查询(显式位置),这种方式比较难细化,因为只有一个中心点。
DPText 利用 显式点坐标(上下边界采样的N个点)生成位置查询(显式位置),这种方式容易细化,因为有 N个显式点,可以通过预测头给它们预测坐标偏移。
b. 点更新。
本文作者在解码器层,逐层细化显式点坐标,并将更新后的显式点作为新的参考点送入可变形交叉注意力模块。
Enhanced Factorized Self-Attention(EFSA)
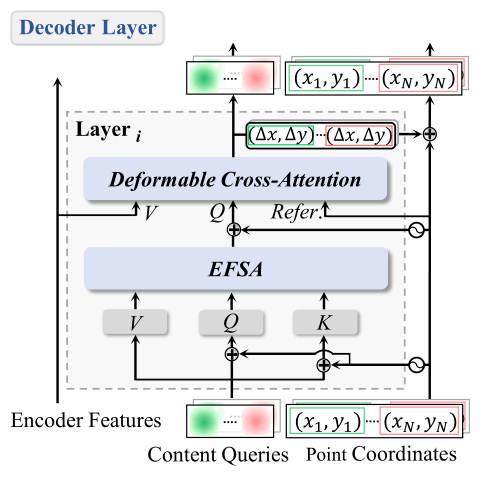
在解码器中,有了 query 输入后,通常还需要考虑如何挖掘 query 之间的关系。在之前的工作中,首先对同一实例内的不同点使用自注意机制挖掘实例内关系,其次在代表不同实例的维度上构建实例间关系。这种关系建模(称为 Factorized Self-Attention, FSA)虽然涵盖了实例内与实例间的关系,却缺少了对实例内不同控制点空间归纳偏置的显式建模。针对多边形的文本表示形式,可以观察到文本的多边形控制点呈现明显的闭合环形,因为作者引入了环形卷积与实例内自注意力并行以提供显示的环形引导,引入更多的先验以充分挖掘实例内不同控制点 query 的关系。增强的实例内关系建模与实例间关系建模共同构成了 EFSA 模块。
1. 利用每个复合查询 的 N 个子查询
的组内自注意力(
) 来捕获同一个文本实例中的不同点之间的关系。
2. 采用 K 个复合查询的组间自注意()来捕捉不同文本实例之间的关系。
本文作者推测,非局部 在捕捉多边形控制点的圆形先验方面存在不足。因此,利用局部循环卷积补充 FSA,形成 EFSA。
执行,获得查询
本地增强查询
融合查询 ,其中 FC 是全连接层;BN 表示 BatchNorm;LN 为 LayerNorm;C 为查询内容。
执行,挖掘不同实例之间的关系: