python之马尔科夫生成任意长度的句子
背景介绍
何为马尔科夫?
https://blog.csdn.net/pipisorry/article/details/46618991
说明
一个文件夹下包含有两个文件,分别是:wenben.txt,markovGenerator.py
01 代码
markovGenerator.py
# coding=utf-8
"""
@author: jiajiknag
程序功能: 文本分析与写作
a: 生成任意长度的(链长自定义:)
b: 马尔可夫链组成的句子
"""
import sys
from urllib.request import urlopen
from random import randint
# 1
def wordListSum(wordList):
"""创建一个单词列表总数"""
# 定义一个变量sum并初始化
sum = 0
# 定义word,value 两个变量进行有序遍历
# items()函数以列表返回可遍历的(键, 值) 元组数组,换言之:字典中所有的项以列表的形式返回,列表中的每一项都是以键值对的形式表现的
# 进行遍历键-值
for word, value in wordList.items():
# 这里开始自加
sum += value
# 返回值的总数
return sum
# 2
def retrieveRandomWord(wordList):
"""返回随机单词"""
# wordList代表的是出现在上一个词语后的词语列表及其频率组成的字典,然后根据统计的概率随机生成一个词。
# randint()用于生成一个指定范围内的整数
# 遍历wordListSun()函数(遍历范围:从1-sum)
randIndex = randint(1,wordListSum(wordList))
# 遍历retrieveRandomWord(wordList)
# 其实就是遍历字典
for word, value in wordList.items():
# 使用遍历wordListSum()函数的结果进行递减
randIndex -= value
if randIndex <=0:
return word
# 3
def buildWordDict(text):
"""buildWordDict(text)函数接收文本内容"""
# 剔除换行符和引号
# 这里也可以用re.sub(pattern, repl, string, count=0, flags=0)
# text = text.sub('(\n|\r|\t)+', " ", text)
# text = text.sub('\"', "", text)
text = text.replace("\n", " ")
text = text.replace("\"", "")
# 保证每个标点符号都和前面的单词在一起 作用:这样不会被剔除,保留在马尔可夫链中
punctuation = [',', '.', ';', ':']
for symbol in punctuation:
# 定义一个表示符号的symbol变量来遍历列表punctuation
text = text.replace(symbol, " " + symbol + " ")
# split()函数指的是通过指定分隔符对字符串进行切片
# 这里指定的是通过" "来进行切分
words = text.split(" ")
# 过滤空单词列表
words = [word for word in words if word!=""]
print("测试words:",words)
# 创建一个空字典
wordDict = {}
for i in range(1, len(words)):
# 创建一个变量i,作用:遍历过滤的单词(从1-len(words))
# 如果wordDict字典中不存在words[i-1]
if words[i-1] not in wordDict:
# 为不存在的单词(words[i - 1])新建(添加)一个字典
wordDict[words[i - 1]] = {}
print("\n测试1 wordDict[words[i - 1]] = {} : ",wordDict)
# print(wordDict)
# 如果words[i](第i个单词)不存在wordDict[words[i - 1]](为不存在单词新建的字典-将不存在的单词添加到新建的字典中)
if words[i] not in wordDict[words[i - 1]]:
# 给 wordDict[words[i - 1]] = {} 的值(值是一个字典)添加数据
wordDict[words[i - 1]][words[i]] = 0
print("\n测试2 wordDict",wordDict)
# wordDict[a][b] += 1 --------->把这个二维矩阵第a行第b列数字+1
# 位置+1
# print(words)
wordDict[words[i - 1]][words[i]] = wordDict[words[i - 1]][words[i]] + 1
print("测试3 wordDict:", wordDict)
# 返回字典的值
return wordDict
f = open(r"wenben.txt","r")
# 按行读取
text = f.readline()
# f.close()
# text = open("wen.txt",encoding='utf-8')
# text = str(urlopen("http://pythonscraping.com/files/inaugurationSpeech.txt").read(), 'utf-8')
# 创建实例--buildWordDict(text)函数接收文本内容
wordDict = buildWordDict(text)
# 生成链长为()的马尔可夫链
length = 10
chain = ""
currentWord = "B"
# 遍历马尔科夫链
for i in range(0,length):
chain += currentWord + " "
# 根据currentWord-->生成wordDict[currentWord]-->使用retrieveRandomWord()函数生成currentWord
currentWord = retrieveRandomWord(wordDict[currentWord])
print(chain)02 wenben.txt
这里的文本内容是博主随意输入进行测试的,根据个人需要可随意输奥!
03 程序流程图
1 程序总体代码流程图

2:函数buildWordDict(text)流程图

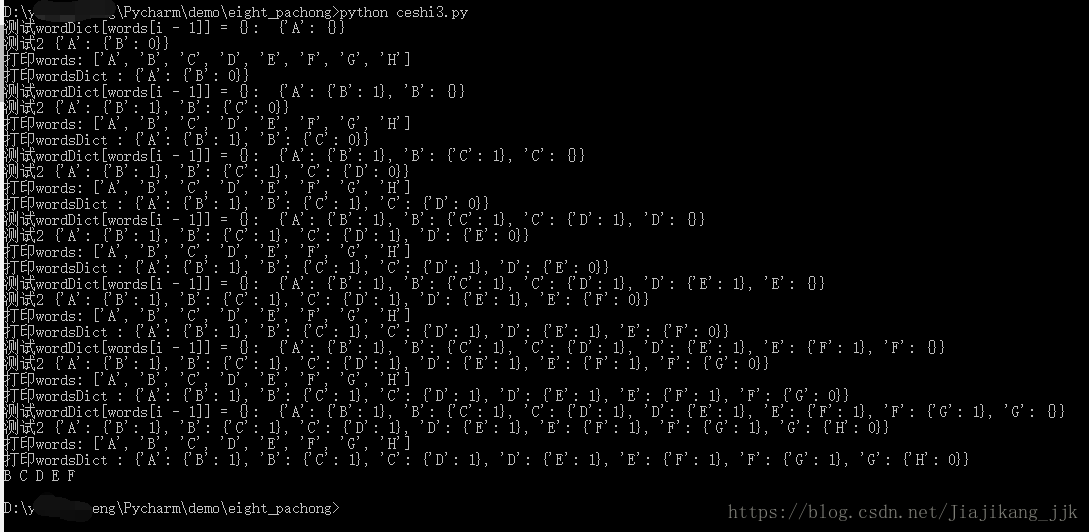
04 程序执行结果
好嘛,,,这个关于马尔科夫生成任意长度的句子的话题到这就简单了解啦,but! 还未结束,至于怎么个未结束敬请期待奥,嘿嘿。