文章目录
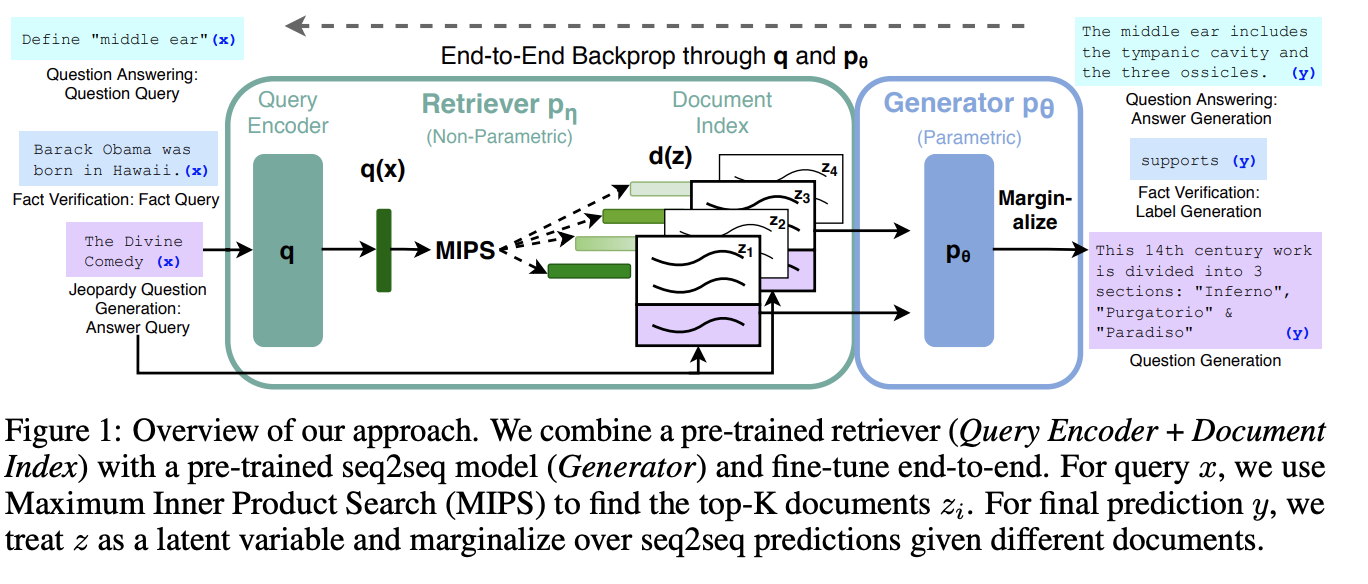
一、RAG
检索器增强生成(RAG)是一种语言生成模型,它结合了预先训练的参数和非参数记忆来生成语言。 具体来说,参数存储器是预训练的 seq2seq 模型,非参数存储器是维基百科的密集向量索引,可通过预训练的神经检索器访问。 供查询,最大内积搜索(MIPS)用于查找top-K文档。 用于最终预测,我们对待作为潜在变量,并在给定不同文档的情况下边缘化 seq2seq 预测。
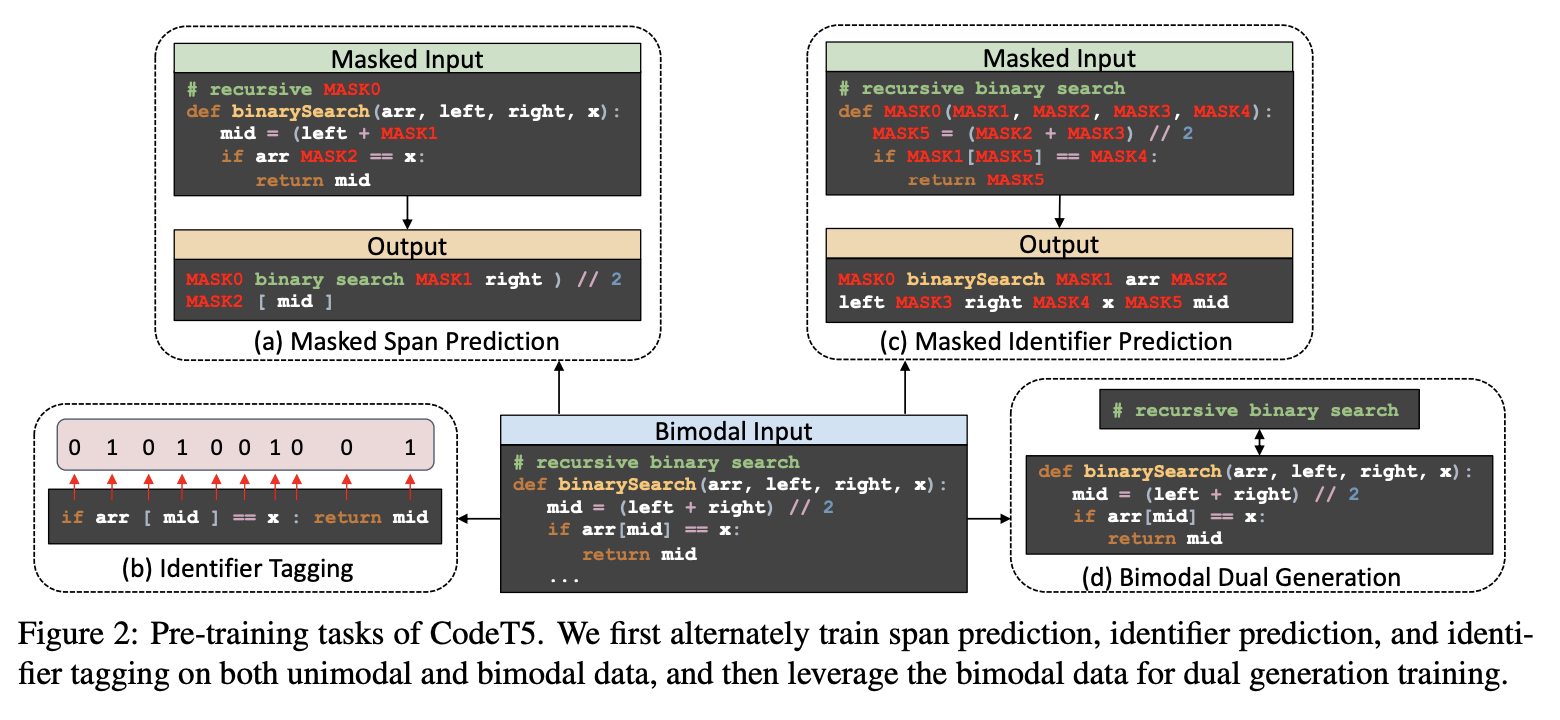
二、CodeT5
CodeT5是一个基于Transformer的模型,用于基于T5架构的代码理解和生成。 它利用标识符感知的预训练目标,考虑代码中的关键令牌类型信息(标识符)。 具体来说,T5 的去噪 Seq2Seq 目标通过两个标识符标记和预测任务进行了扩展,以使模型能够更好地利用编程语言中的标记类型信息,即开发人员分配的标识符。 为了提高自然语言与编程语言的一致性,使用双模态双重学习目标来实现自然语言和编程语言之间的双向转换。
三、CTRL
CTRL 是条件转换器语言模型,经过训练以控制样式、内容和特定于任务的行为的控制代码为条件。 控制代码源自与原始文本自然共存的结构,保留了无监督学习的优势,同时提供对文本生成的更明确的控制。 这些代码还允许 CTRL 预测训练数据的哪些部分最有可能是给定的序列。

四、CodeGen
CodeGen 是一种自回归转换器,以下一个标记预测语言模型为学习目标,在自然语言语料库和 GitHub 上整理的编程语言数据上进行训练。
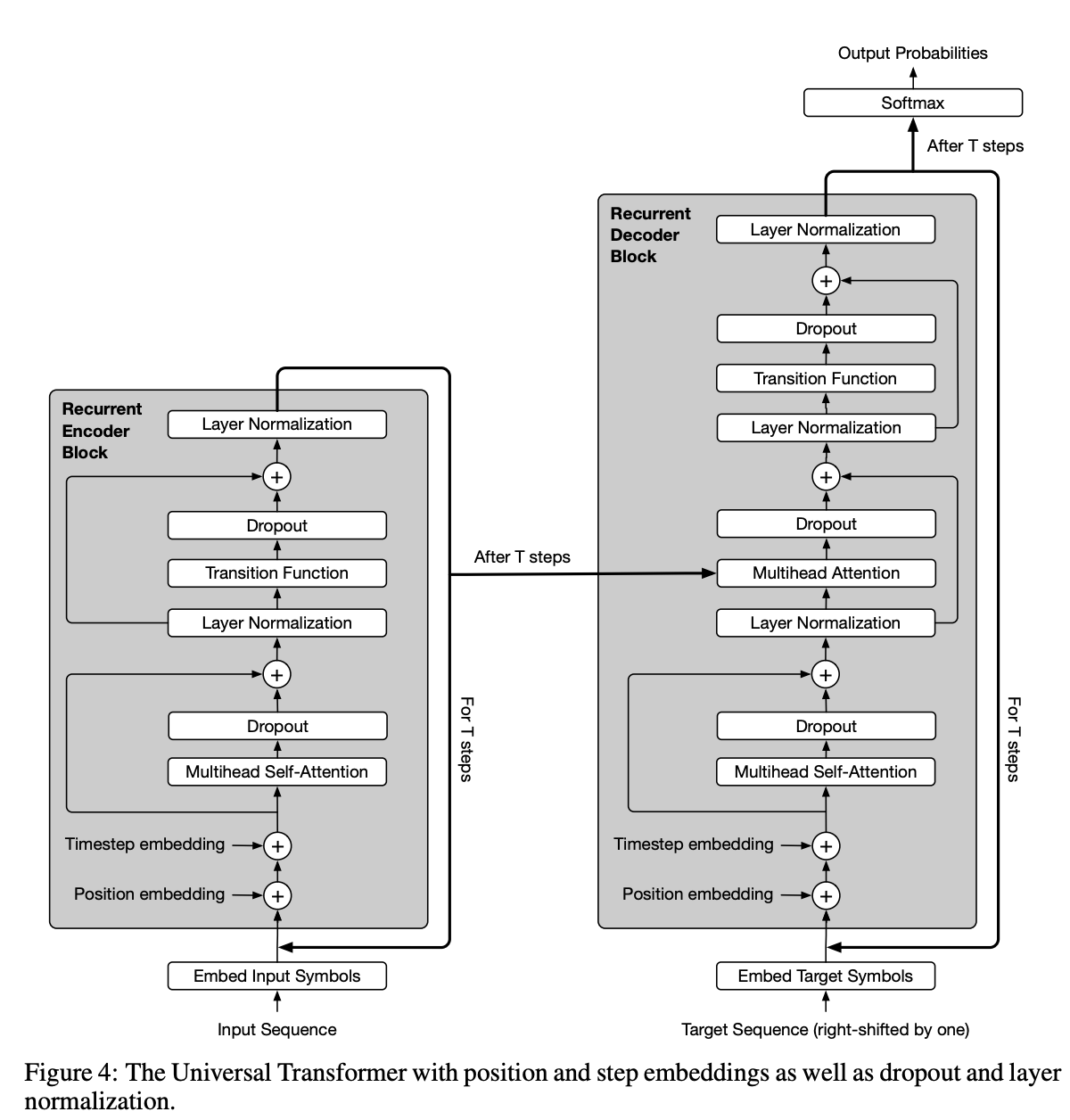
五、Universal Transformer
通用 Transformer 是 Transformer 架构的泛化。 Universal Transformers 将 Transformer 等前馈序列模型的并行性和全局感受野与 RNN 的循环归纳偏置相结合。 他们还利用动态的每个位置停止机制。
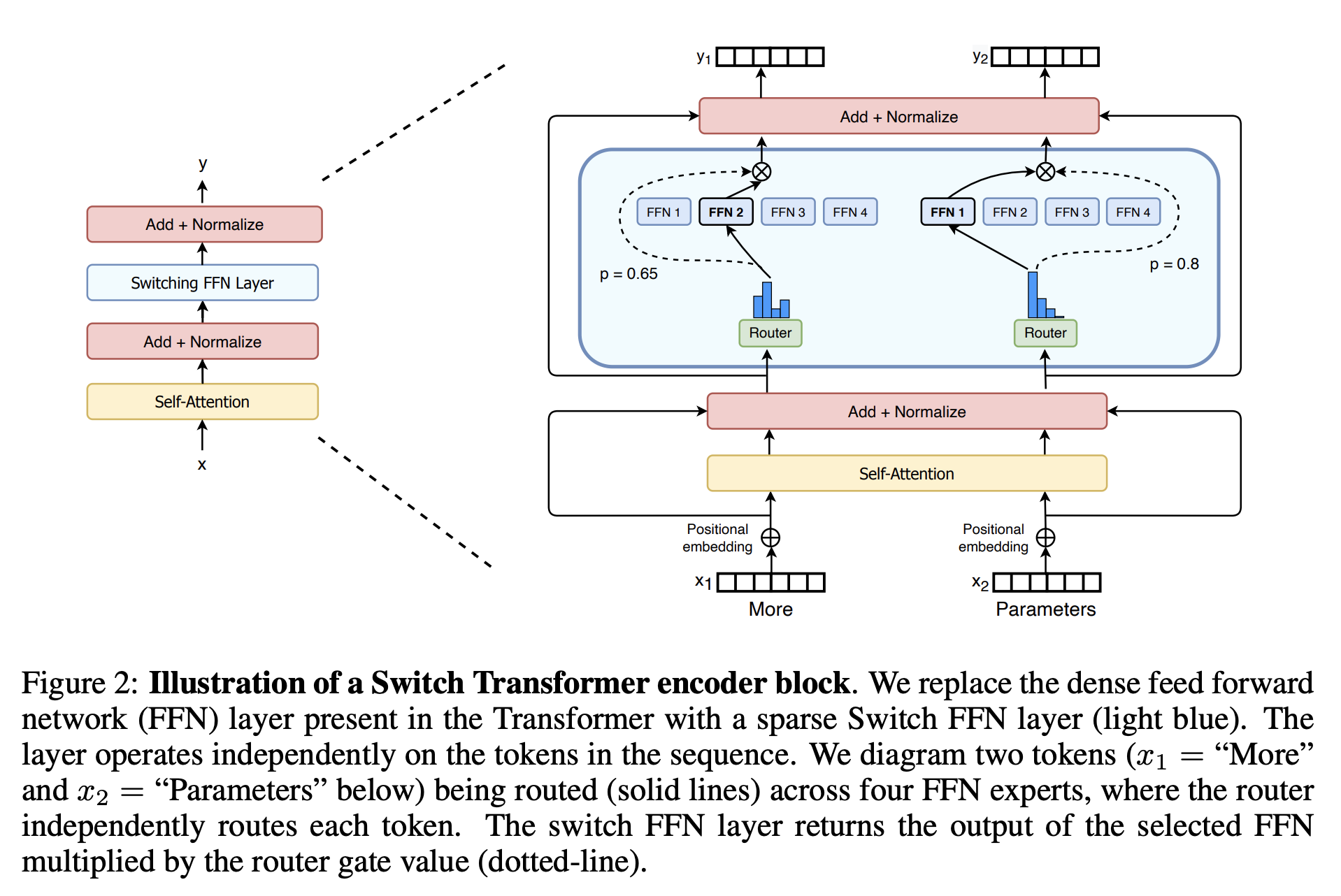
六、Switch Transformer
Switch Transformer 是一种稀疏激活的专家 Transformer 模型,旨在简化和改进 Mixture of Experts。 通过将稀疏的预训练和专门的微调模型蒸馏为小型密集模型,它可以将模型大小减少高达 99%,同时保留大型稀疏教师 30% 的质量增益。 它还使用选择性精度训练,以较低的 bfloat16 精度进行训练,以及允许扩展到更多专家的初始化方案,并增加正则化,以改进稀疏模型微调和多任务训练。
七、BLOOMZ
BLOOMZ 是 BLOOM 的多任务提示微调 (MTF) 变体。
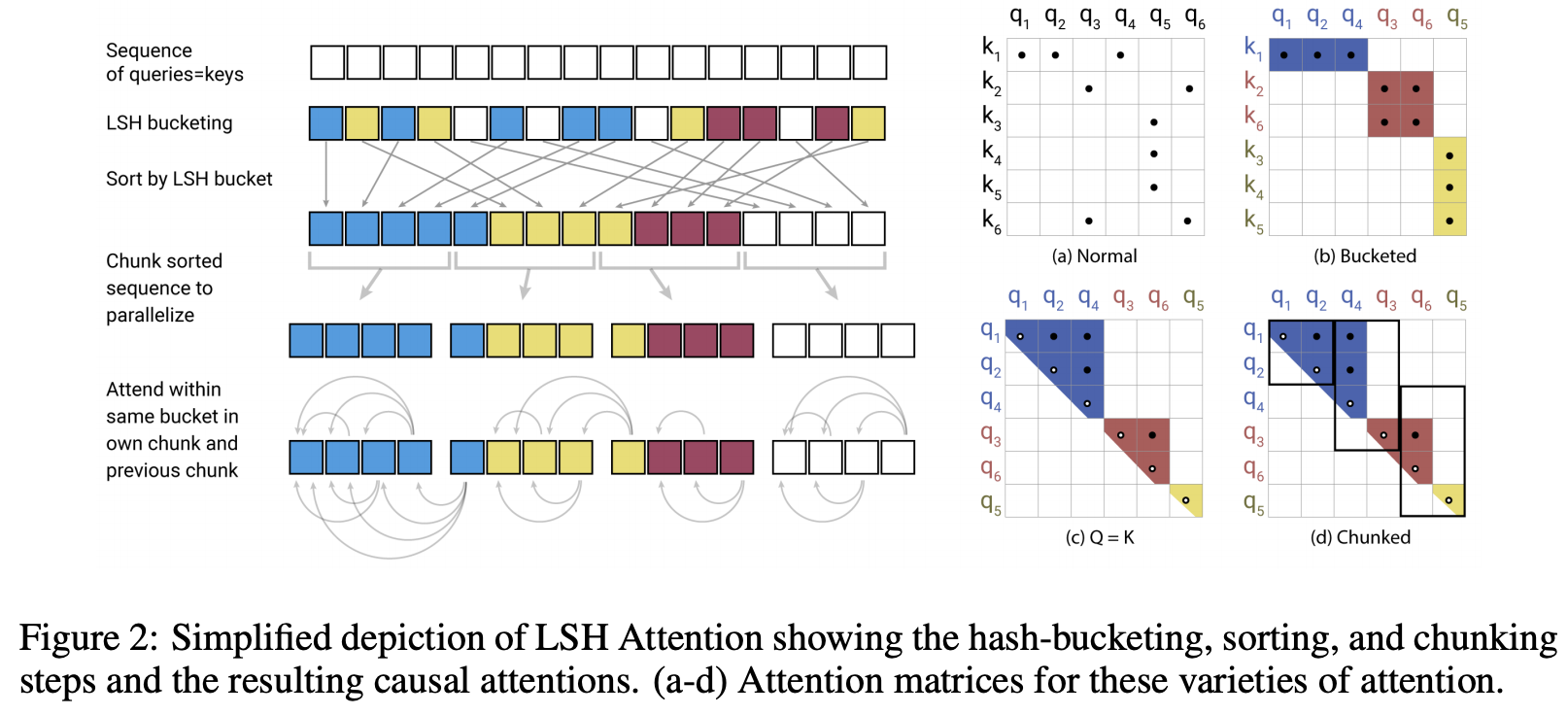
八、Reformer

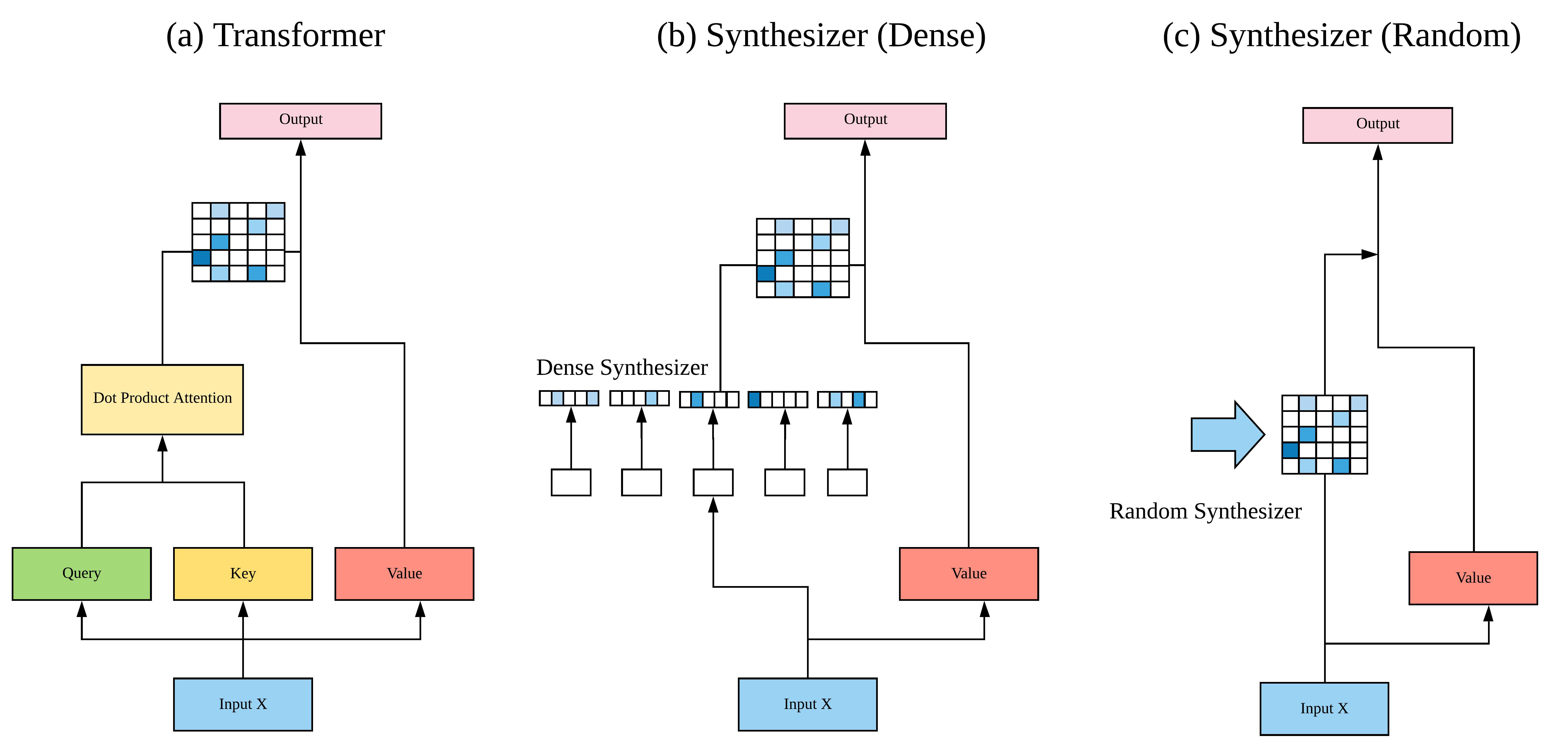
九、Synthesizer
Synthesizer 是一个无需 token-token 交互即可学习合成注意力权重的模型。 与变形金刚不同,该模型避开了点产品自注意力,也完全避开了基于内容的自注意力。 合成器学习合成自对齐矩阵,而不是手动计算成对点积。 它是基于转换的,仅依赖于简单的前馈层,并且完全不需要点积和显式的令牌-令牌交互。
合成器采用的这个新模块称为“综合注意力”:一种无需明确参与(即没有点积注意力或基于内容的注意力)即可学习参与的新方法。 相反,合成器生成独立于令牌-令牌依赖性的对齐矩阵。
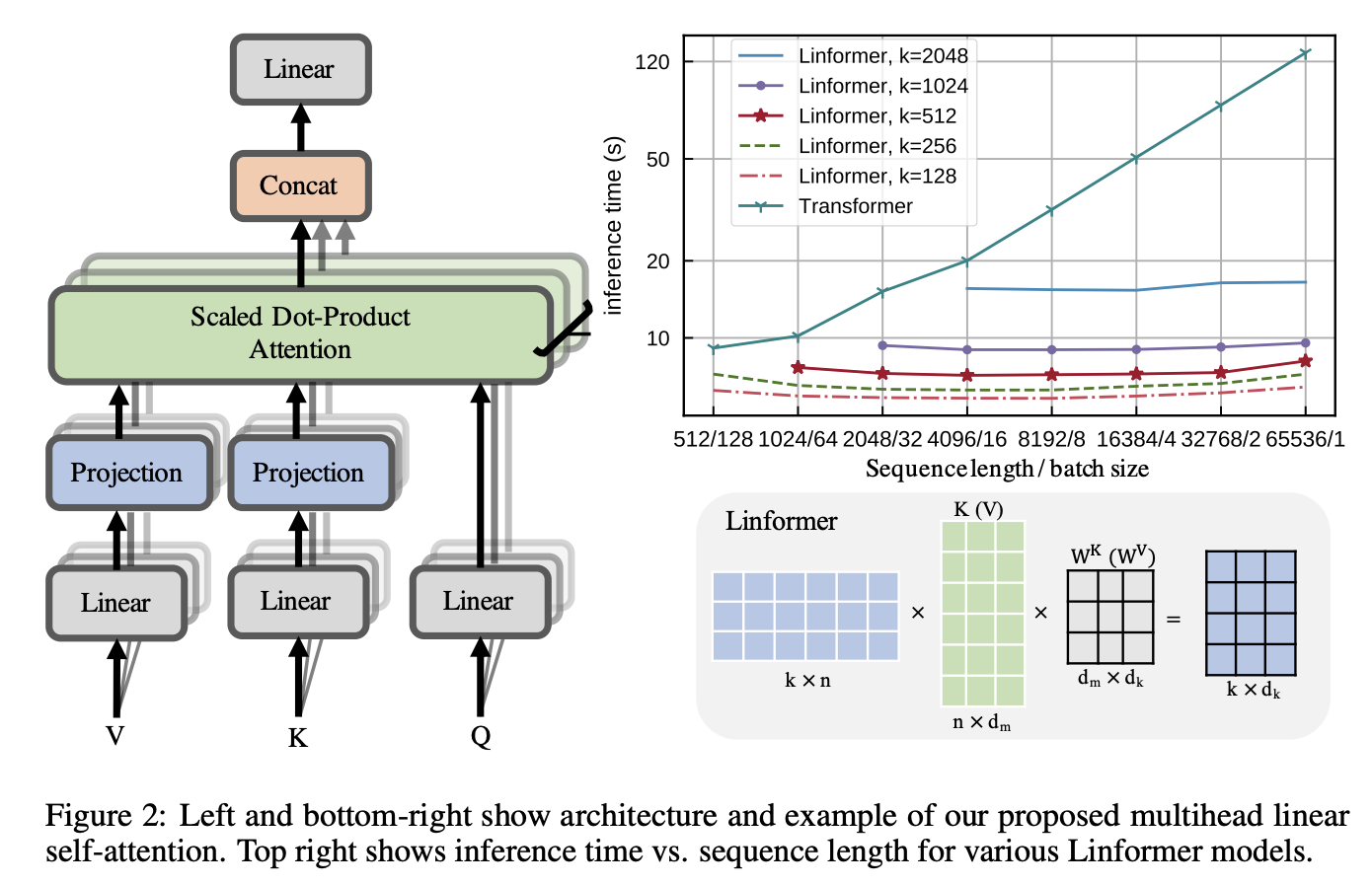
十、Linformer
Linformer 是一个线性 Transformer,它利用线性自注意力机制来解决 Transformer 模型的自注意力瓶颈。 原始缩放的点积注意力通过线性投影分解为多个较小的注意力,使得这些操作的组合形成原始注意力的低阶分解。
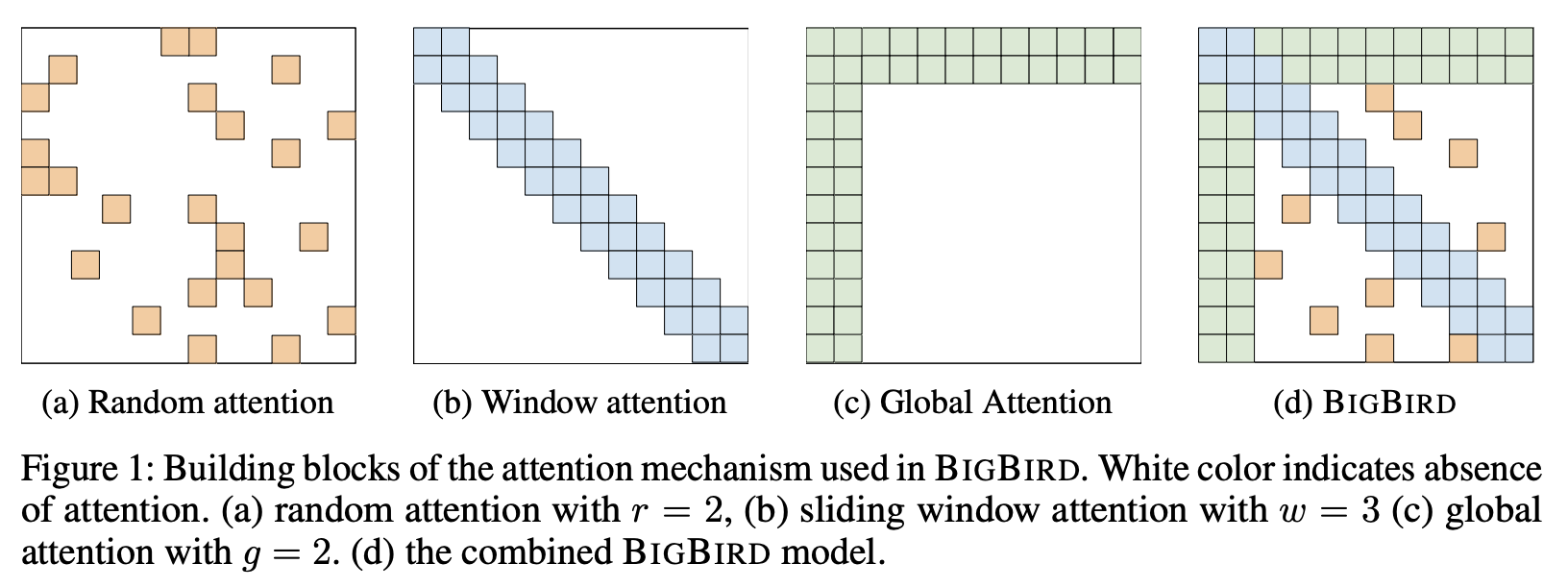
十一、BigBird
BigBird 是一个具有稀疏注意力机制的 Transformer,可以将自注意力的二次依赖性减少到令牌数量的线性。 BigBird 是序列函数的通用逼近器,并且是图灵完备的,从而保留了二次全注意力模型的这些属性。 具体来说,BigBird 由三个主要部分组成:

这导致高性能的注意力机制扩展到更长的序列长度(8x)。
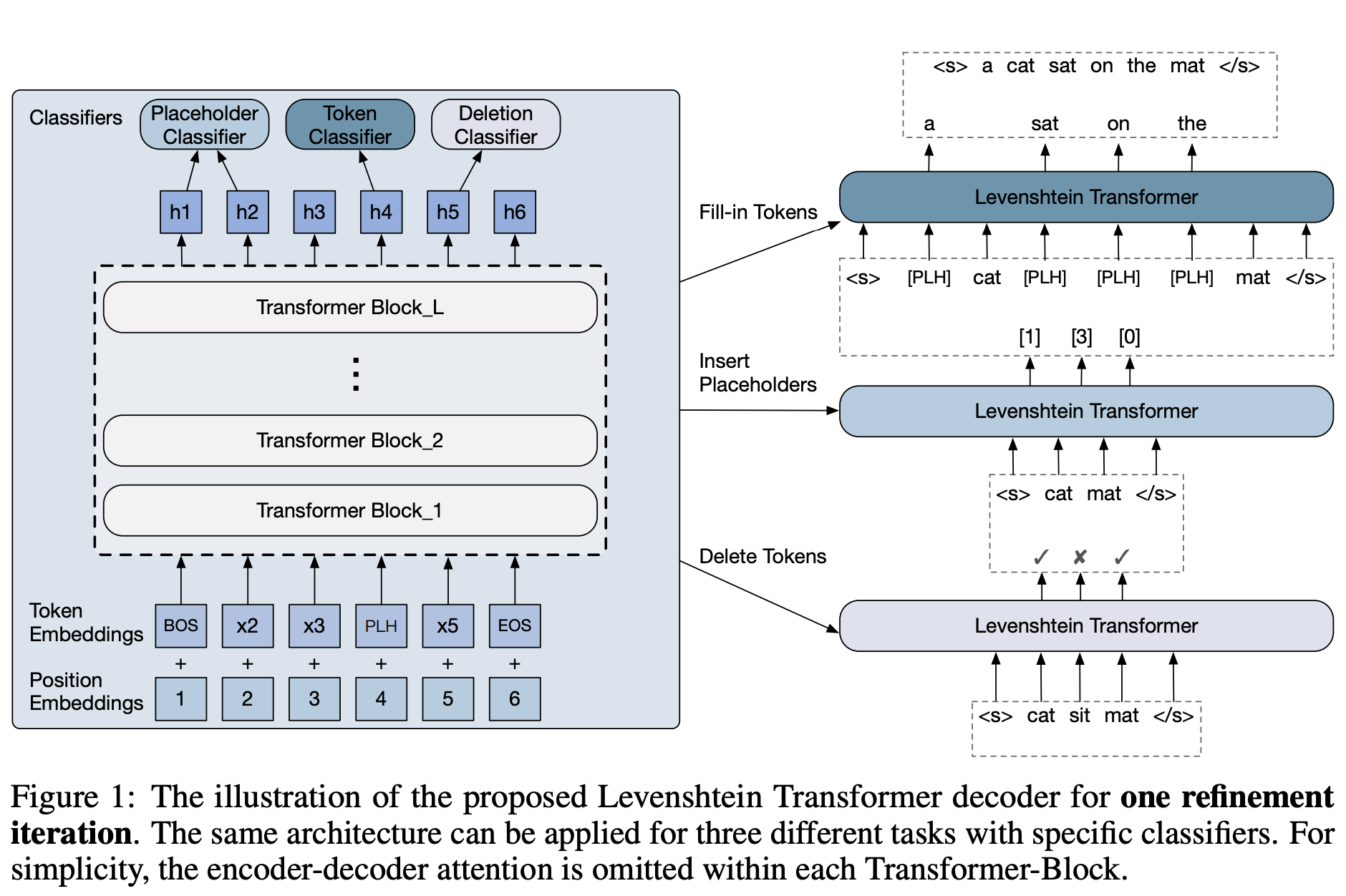
十二、Levenshtein Transformer
Levenshtein Transformer (LevT) 是一种变压器,旨在解决以前解码模型缺乏灵活性的问题。 值得注意的是,在以前的框架中,生成的序列的长度要么是固定的,要么随着解码的进行而单调增加。 作者认为这与人类水平的智能不相容,人类可以修改、替换、撤销或删除其生成文本的任何部分。 因此,LevT 被提出通过打破目前标准化的解码机制并用插入和删除这两个基本操作来代替它来弥补这一差距。
LevT 使用模仿学习进行训练。 结果模型包含两个策略,并且它们以交替方式执行。 作者认为,通过这种模型,解码变得更加灵活。 例如,当给解码器一个空令牌时,它会退回到正常的序列生成模型。 另一方面,当初始状态是低质量的生成序列时,解码器充当细化模型。
LevT 框架的关键组成部分之一是学习算法。 作者利用了插入和删除的特征——它们是互补的,但也是对抗的。 他们提出的算法称为“双策略学习”。 这个想法是,当训练一个策略(插入或删除)时,我们使用其对手在前一次迭代中的输出作为输入。 另一方面,专家政策则被用来提供修正信号。