文章目录
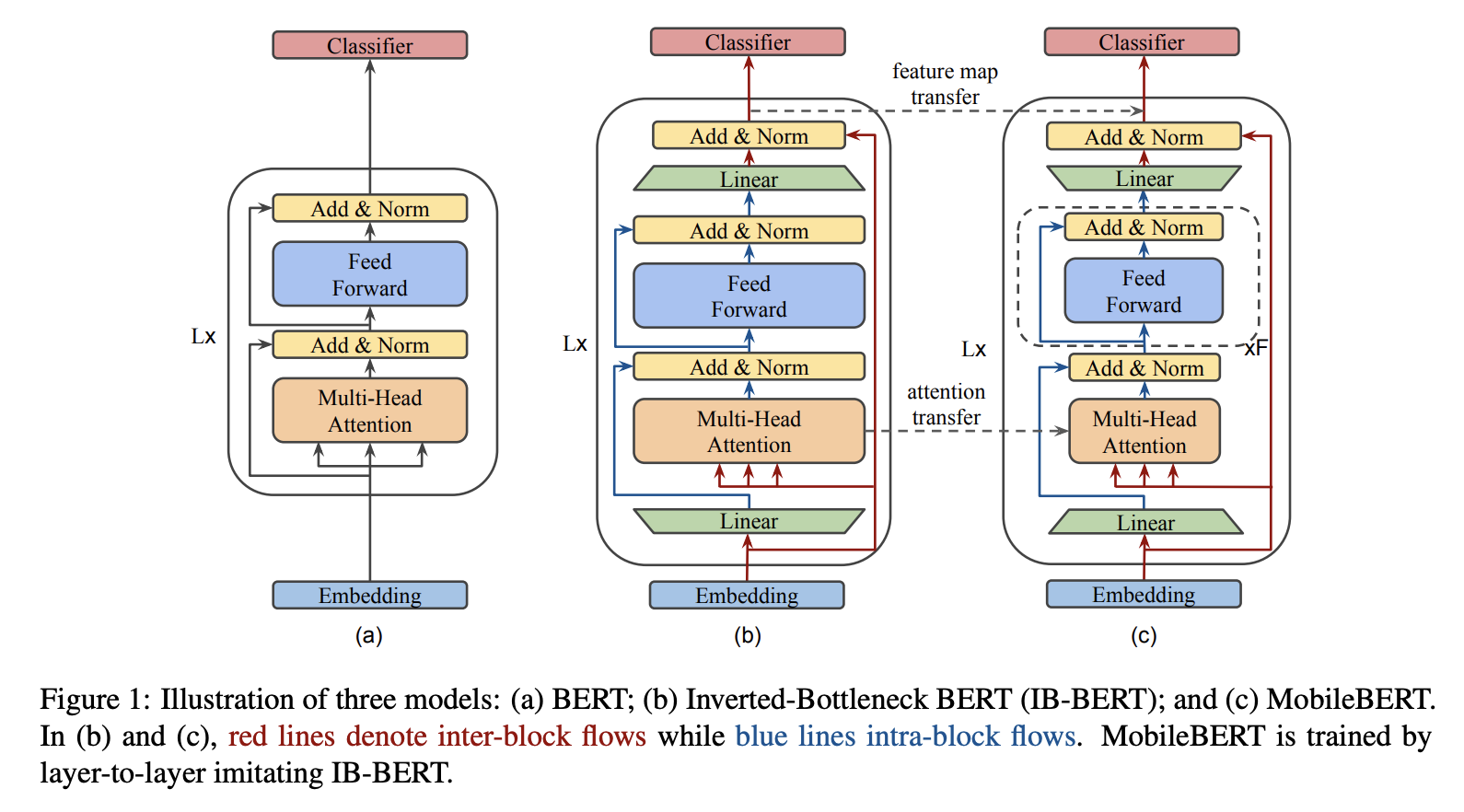
一、MobileBERT
MobileBERT 是一种反向瓶颈 BERT,它压缩并加速了流行的 BERT 模型。 MobileBERT 是 BERT_LARGE 的瘦身版本,同时配备了瓶颈结构以及精心设计的自注意力和前馈网络之间的平衡。 为了训练 MobileBERT,我们首先训练一个专门设计的教师模型,一个包含 BERT_LARGE 的倒瓶颈模型。 然后,我们将这位老师的知识迁移到 MobileBERT。 与原始 BERT 一样,MobileBERT 是与任务无关的,也就是说,它可以通过简单的微调普遍应用于各种下游 NLP 任务。 它是通过模仿反向瓶颈 BERT 进行逐层训练的。
二、UL2
UL2 是预训练模型的统一框架,在数据集和设置中普遍有效。 UL2 使用混合降噪器 (MoD),这是一种将不同预训练范例结合在一起的预训练目标。 UL2 引入了模式切换的概念,其中下游微调与特定的预训练方案相关联。
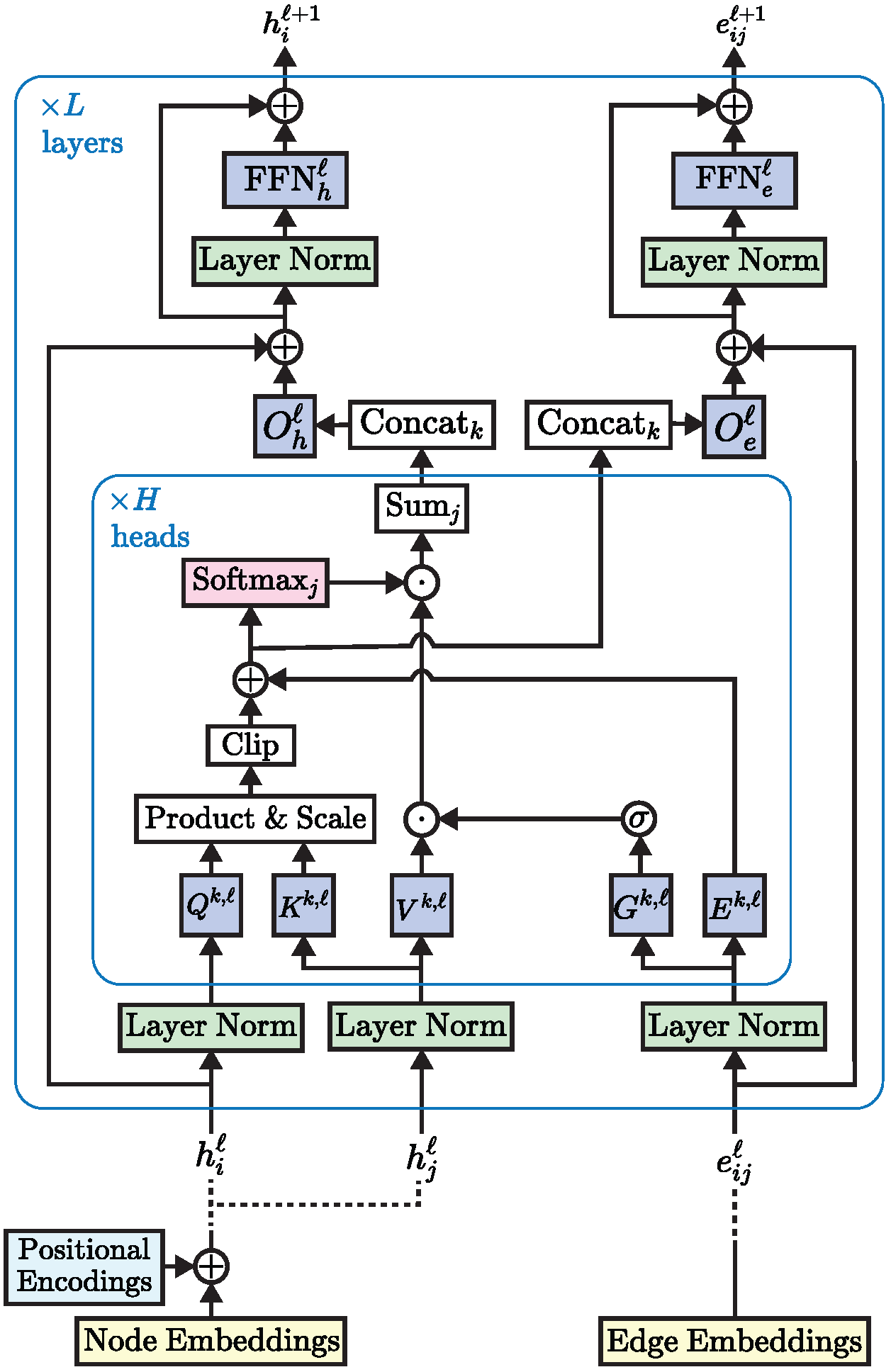
三、Edge-augmented Graph Transformer
Transformer 神经网络已经在文本和图像等非结构化数据上取得了最先进的结果,但它们在图结构化数据上的采用受到了限制。 这部分是由于将复杂的结构信息纳入基本变压器框架中的困难。 我们提出了一个简单但强大的变压器扩展 - 剩余边缘通道。 由此产生的框架,我们称之为边缘增强图变换器(EGT),可以直接接受、处理和输出结构信息以及节点信息。 它允许我们直接将全局自注意力(变压器的关键元素)用于图,并具有节点之间远程交互的好处。 此外,边缘通道允许结构信息从一层演变到另一层,并且边缘/链接上的预测任务可以直接从这些通道的输出嵌入执行。 此外,我们引入了一种基于奇异值分解的广义位置编码方案,可以提高 EGT 的性能。 与依赖邻域内的局部特征聚合的卷积/消息传递图神经网络相比,我们的框架依赖于全局节点特征聚合,实现了更好的性能。 我们在基准数据集上进行了广泛的实验,在监督学习环境中验证了 EGT 的性能。 我们的研究结果表明,卷积聚合并不是图的本质归纳偏差,全局自注意力可以作为灵活且自适应的替代方案。
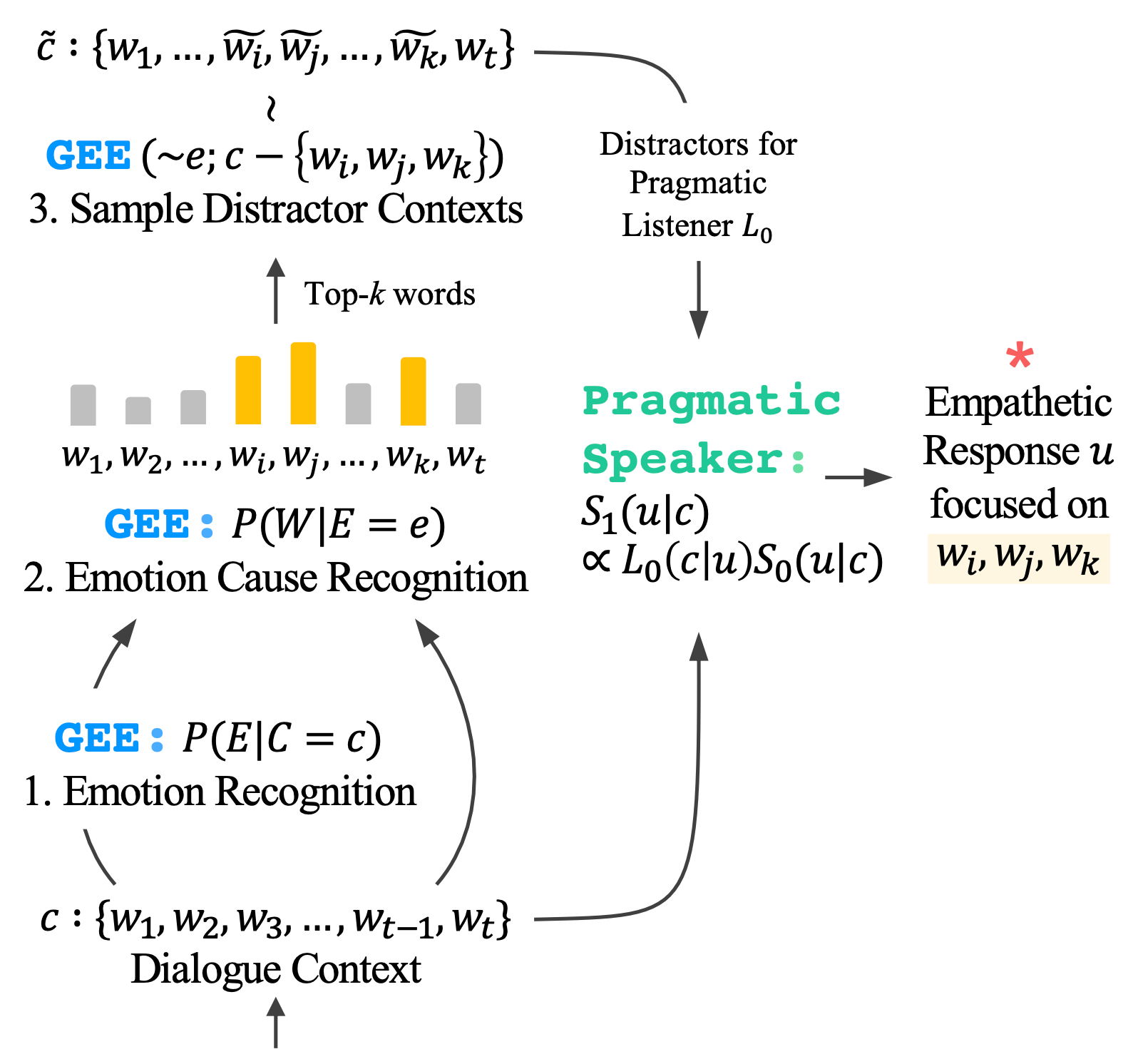
四、Generative Emotion Estimator
五、Neural Probabilistic Language Model
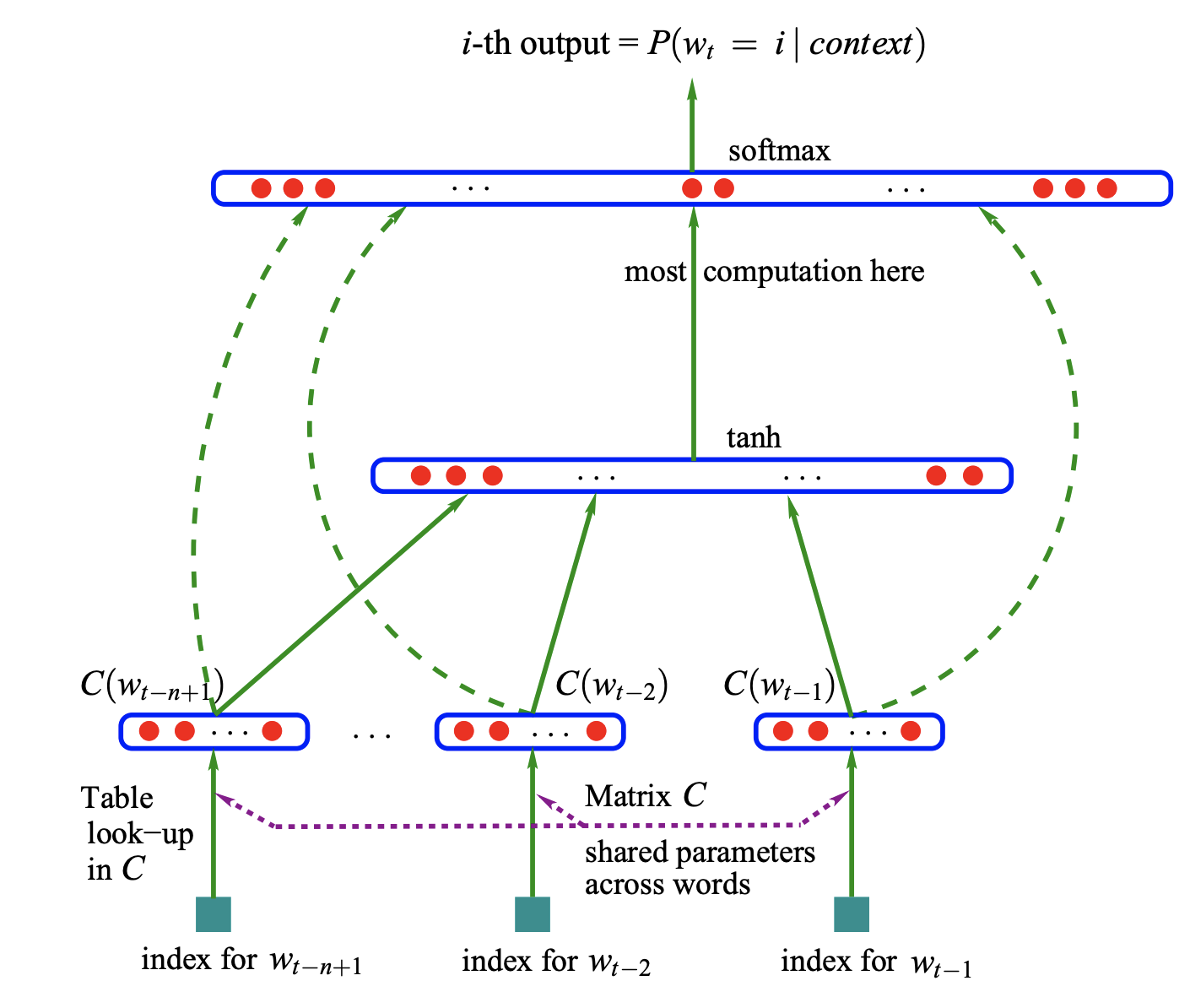
神经概率语言模型是一种早期的语言建模架构。 它涉及一个前馈架构,该架构接受前一个的输入向量表示(即词嵌入)n在表格中查找的单词C。
六、E-Branchformer
E-BRANCHFORMER:增强语音识别合并功能的 BRANCHFORMER

七、Routing Transformer
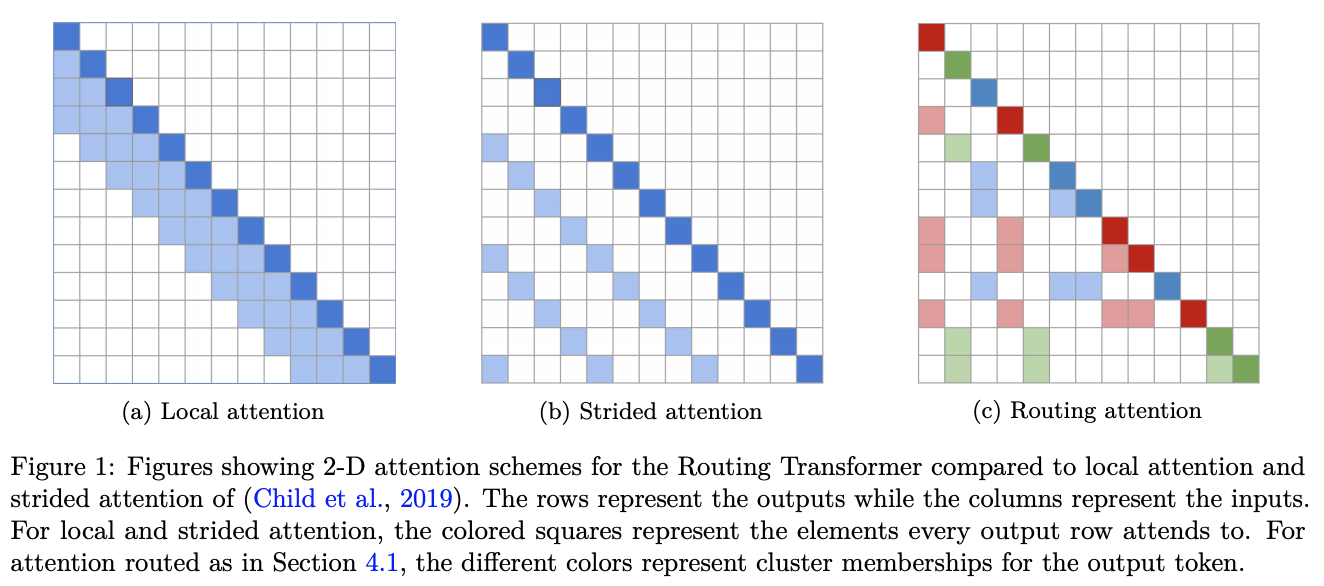
Routing Transformer是一个赋予self-attention基于在线k-means的稀疏路由模块的Transformer。 每个注意力模块都考虑空间的聚类:当前时间步仅关注属于同一聚类的上下文。 换句话说,当前时间步查询通过其集群分配路由到有限数量的上下文。
八、Compressive Transformer
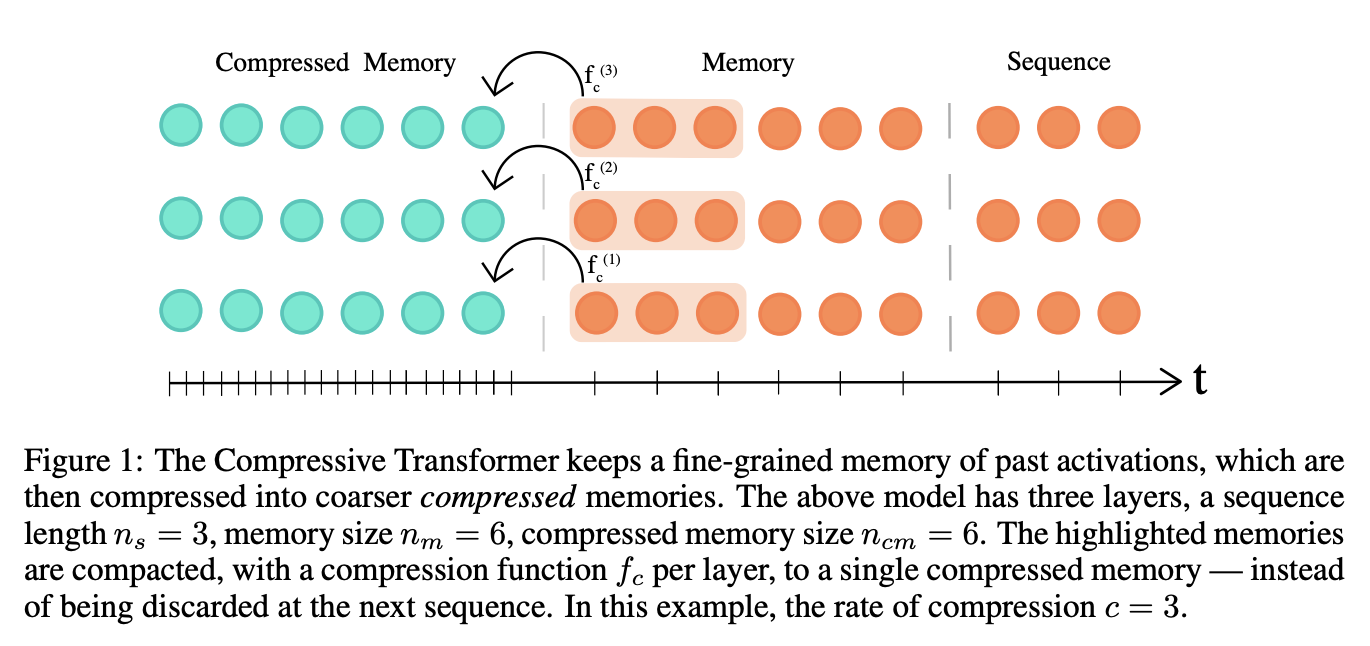
压缩变压器是变压器的扩展,它将过去的隐藏激活(记忆)映射到较小的压缩表示(压缩记忆)集。 压缩变压器对其记忆集和压缩记忆使用相同的注意力机制,学习查询其短期粒度记忆和长期粗略记忆。 它建立在 Transformer-XL 的思想之上,Transformer-XL 保留了每一层过去激活的记忆,以保留更长时间的上下文历史。 当过去的激活变得足够旧时(由内存大小控制),Transformer-XL 会丢弃它们。 压缩变压器的关键原理是压缩这些旧内存,而不是丢弃它们,并将它们存储在额外的压缩内存中。
在每个时间步,我们丢弃最旧的压缩存储器(FIFO),然后丢弃最旧的普通内存中的状态被压缩并转移到压缩内存中的新槽。 在训练期间,压缩记忆组件与主语言模型(单独的训练循环)分开进行优化。
九、CANINE
CANINE 是一种用于语言理解的预训练编码器,直接对字符序列进行操作(无需显式标记化或词汇),并且是一种用软归纳偏差代替硬标记边界的预训练策略。 为了有效且高效地使用其更细粒度的输入,Canine 将减少输入序列长度的下采样与对上下文进行编码的深度转换器堆栈相结合。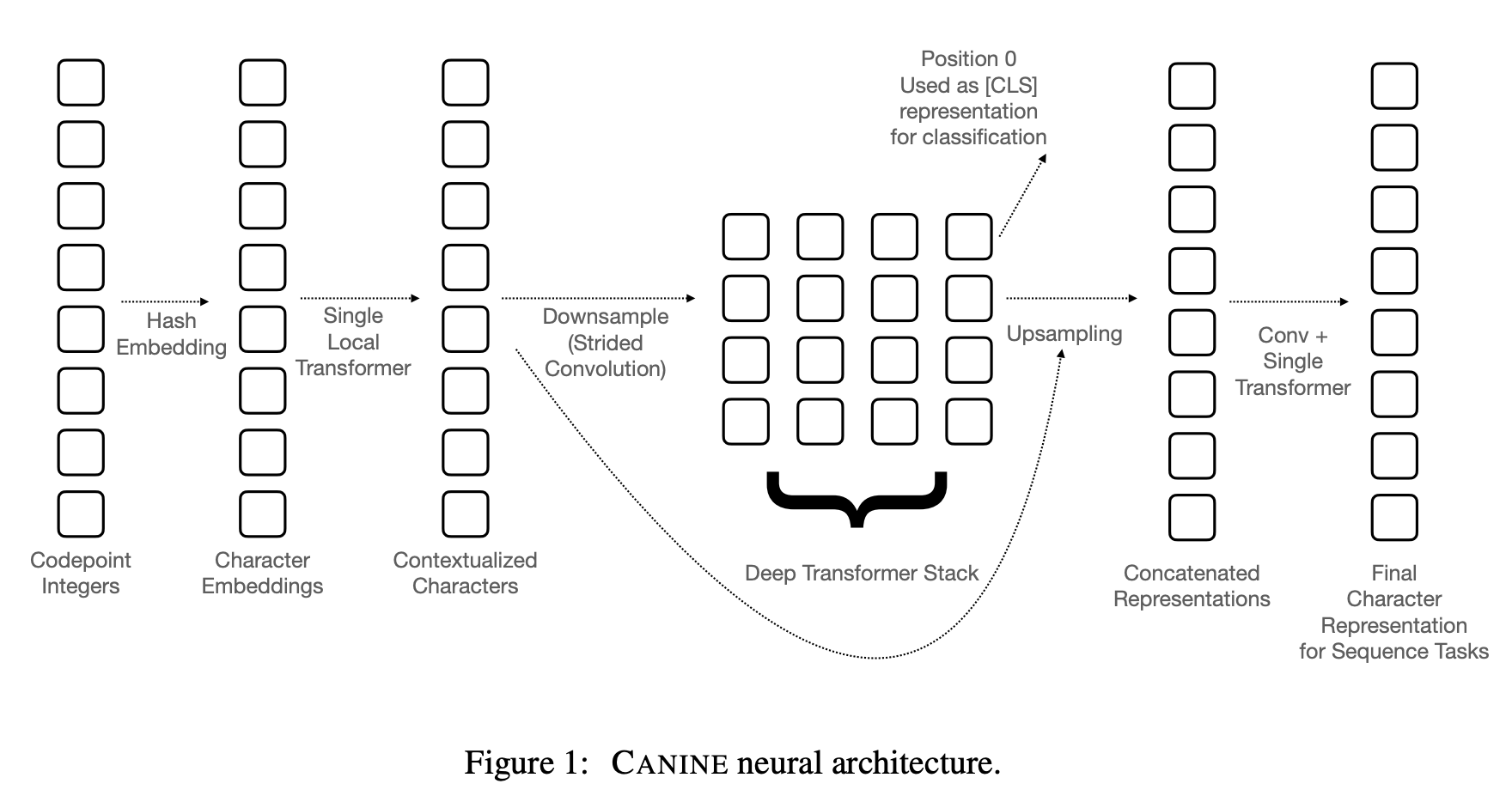
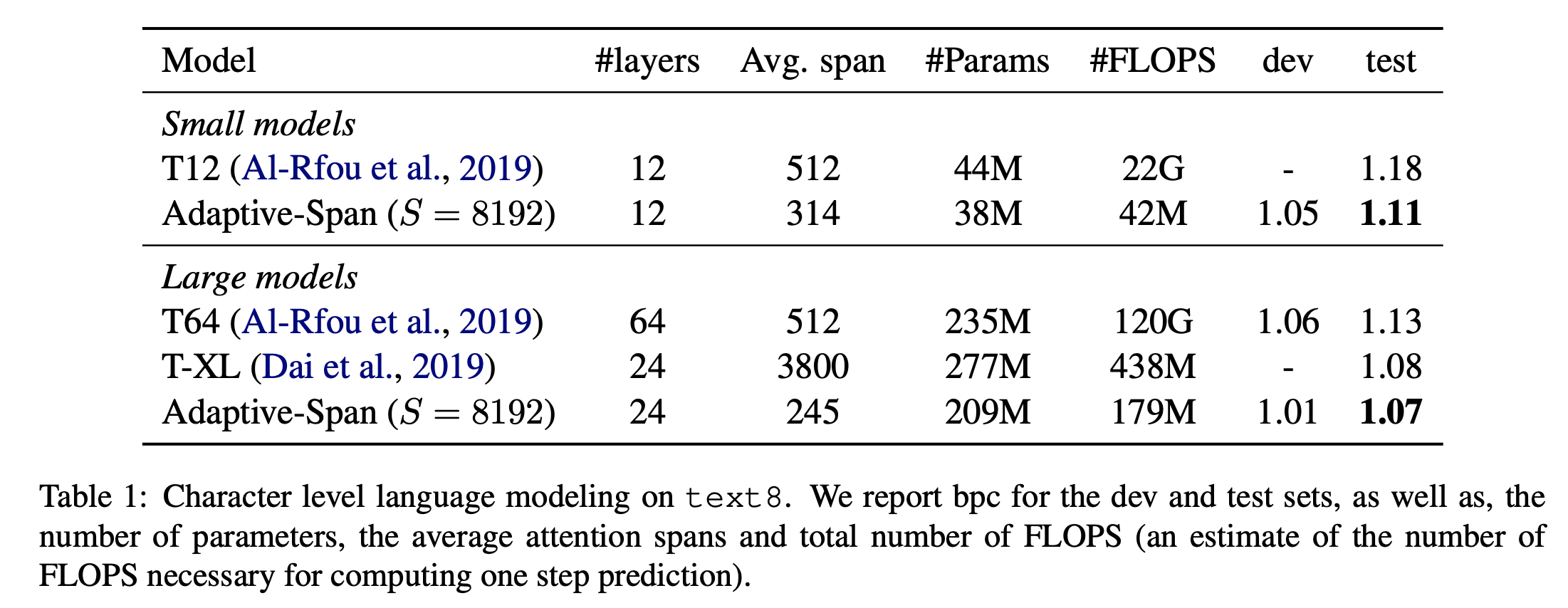
十、Adaptive Span Transformer
自适应注意力跨度变压器是一种利用称为自适应屏蔽的自注意力层改进的变压器,允许模型选择自己的上下文大小。 这会形成一个网络,其中每个注意力层都会收集有关其自身上下文的信息。 这允许扩展到超过 8k 个标记的输入序列。
他们的建议基于这样的观察:在传统 Transformer 的密集注意力下,每个注意力头共享相同的注意力跨度S(参与完整的上下文)。 但许多注意力头可以专注于更局部的上下文(其他注意力头则关注更长的序列)。 这激发了对自注意力变体的需求,该变体允许模型选择自己的上下文大小(自适应屏蔽 - 请参阅组件)。
十一、Generative Adversarial Transformer
GANformer 是一种新颖且高效的变压器,可用于视觉生成建模。 该网络采用二分结构,可以在图像上进行远程交互,同时保持线性效率的计算,可以轻松扩展到高分辨率合成。 它迭代地将信息从一组潜在变量传播到不断变化的视觉特征,反之亦然,以支持彼此的细化,并鼓励对象和场景的组合表示的出现。

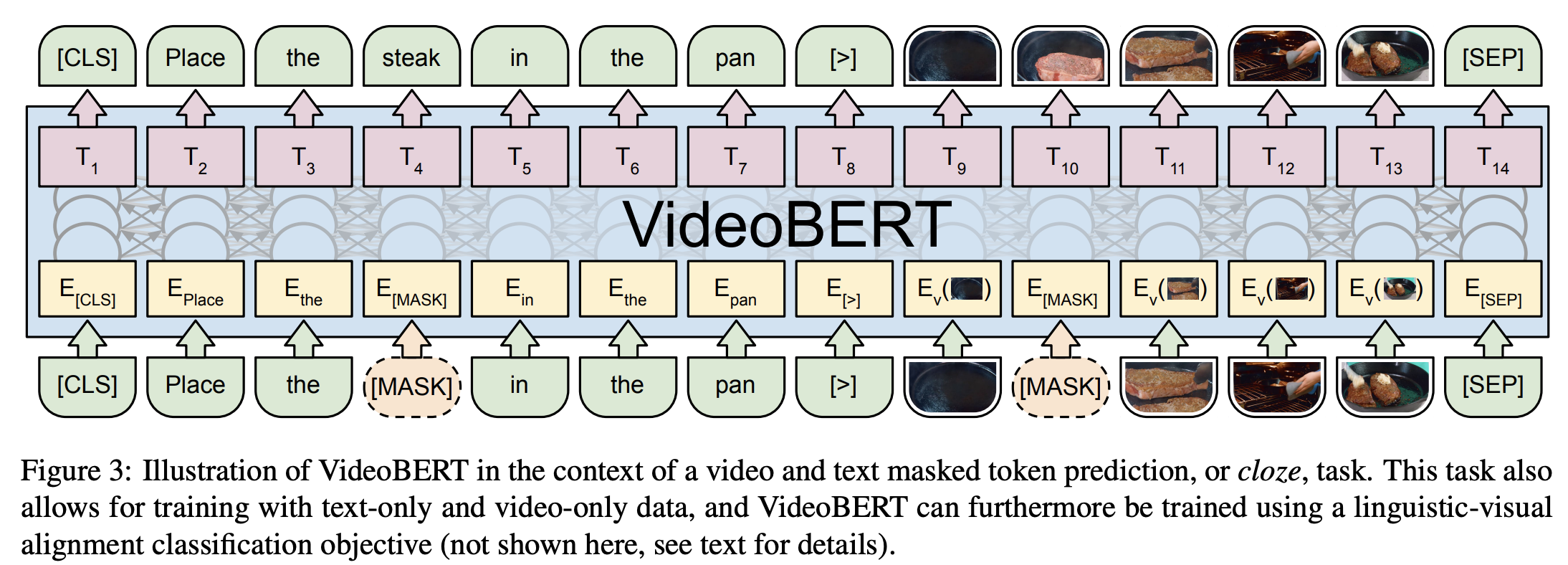
十二、VideoBERT
VideoBERT 采用强大的 BERT 模型来学习视频的联合视觉语言表示。 它用于许多任务,包括动作分类和视频字幕。