文章目录
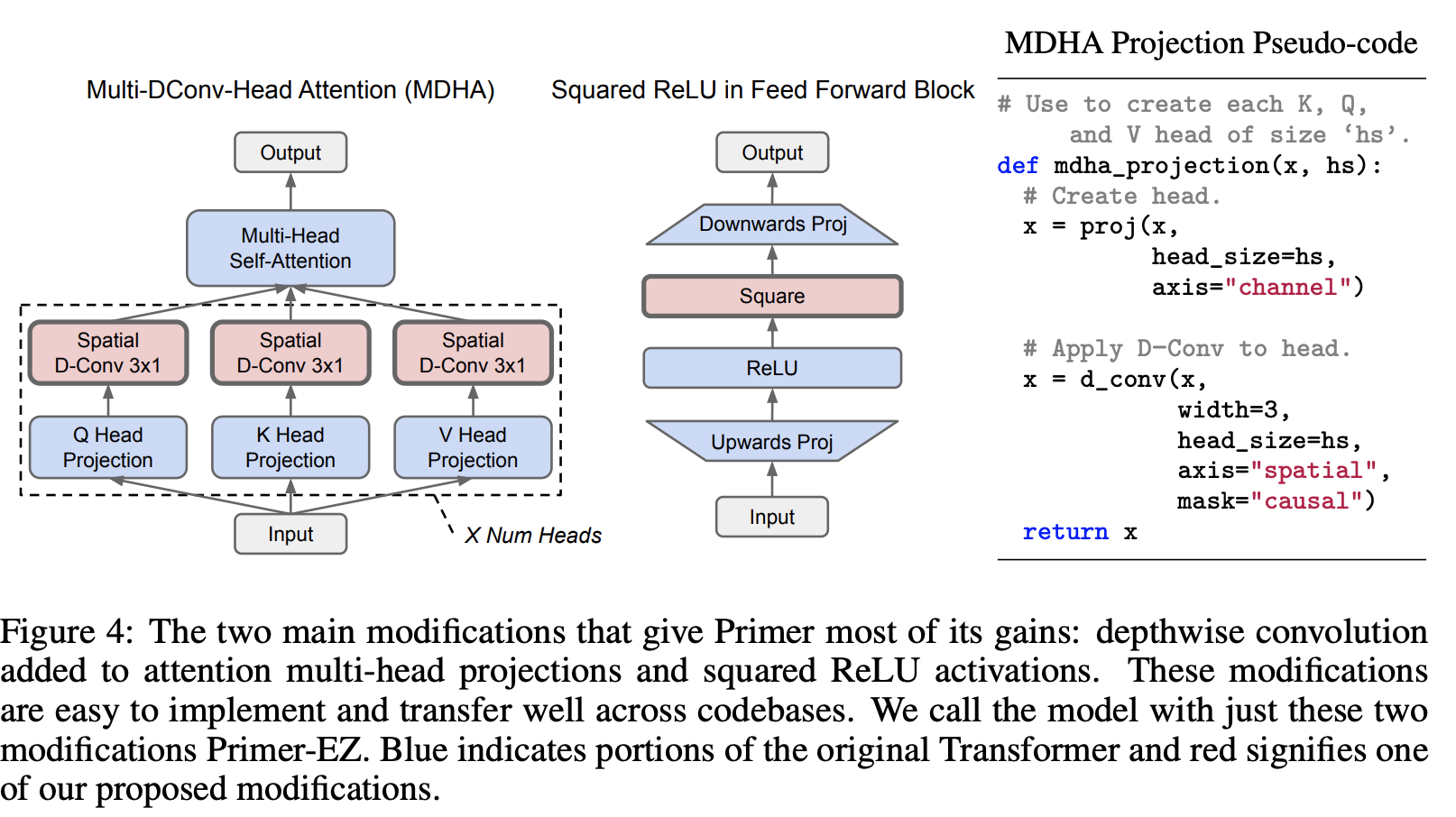
一、Primer
Primer 是一种基于 Transformer 的架构,它在 Transformer 架构的基础上进行了改进,通过神经架构搜索发现了两项改进:前馈块中的平方 RELU 激活,以及添加到注意力多头投影中的深度卷积:产生了一个名为 Multi- DConv-头部注意力。
二、Pythia
Pythia 是一套仅解码器的自回归语言模型,所有模型均以完全相同的顺序、大小从 70M 到 12B 参数不等的公共数据进行训练。 模型架构和超参数很大程度上遵循 GPT-3,但根据大规模语言建模最佳实践的最新进展,存在一些明显的偏差。
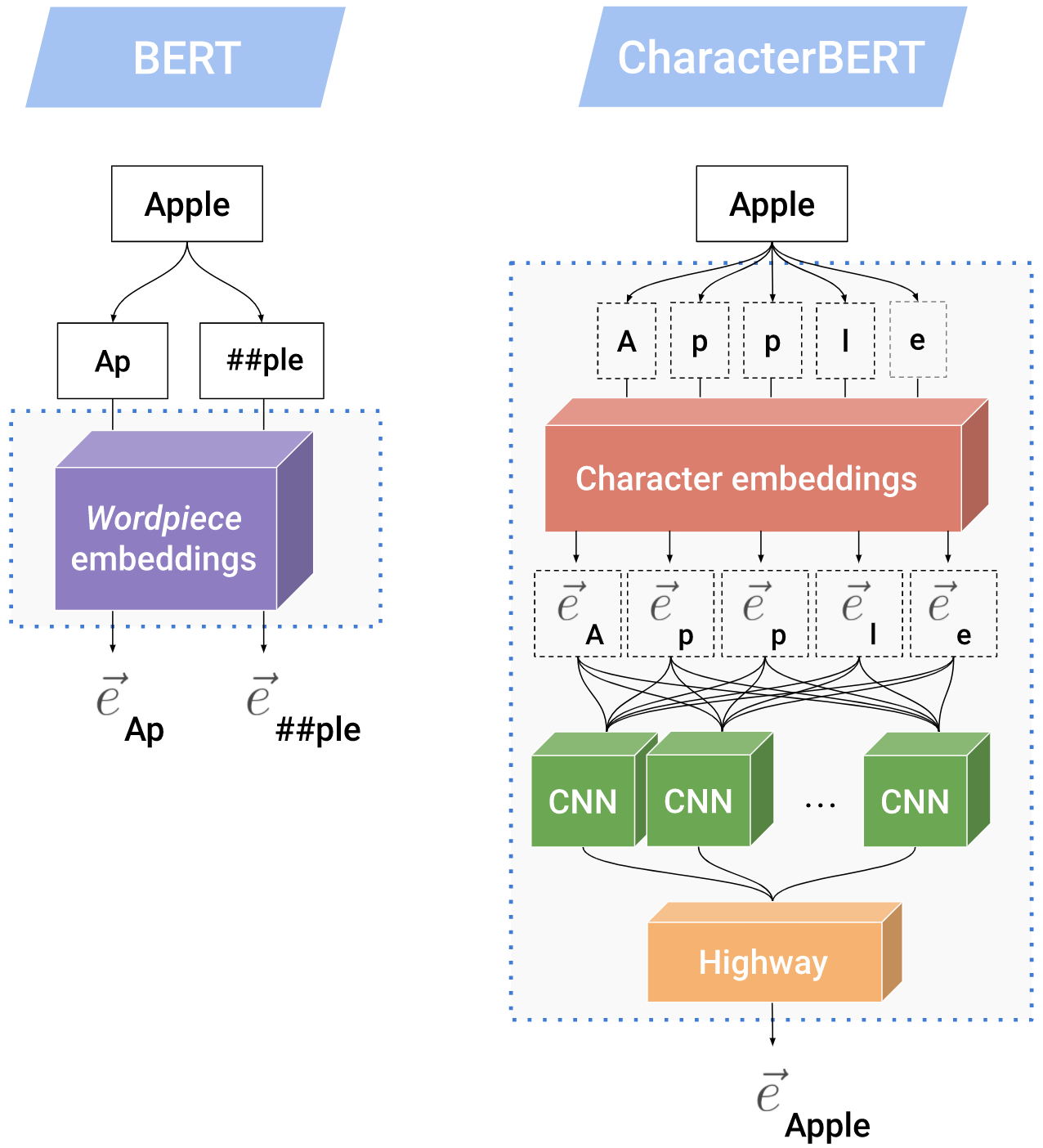
三、CharacterBERT
CharacterBERT 是 BERT 的一种变体,它放弃了 wordpiece 系统,并用 CharacterCNN 模块取代它,就像 ELMo 用于生成第一层表示的模块一样。 这使得CharacterBERT能够表示任何输入标记,而无需将其拆分为单词片段。 此外,这使 BERT 摆脱了特定领域词汇词汇的负担,这些词汇可能不适合您感兴趣的领域(例如医学领域)。 最后,它使模型对噪声输入更加鲁棒。
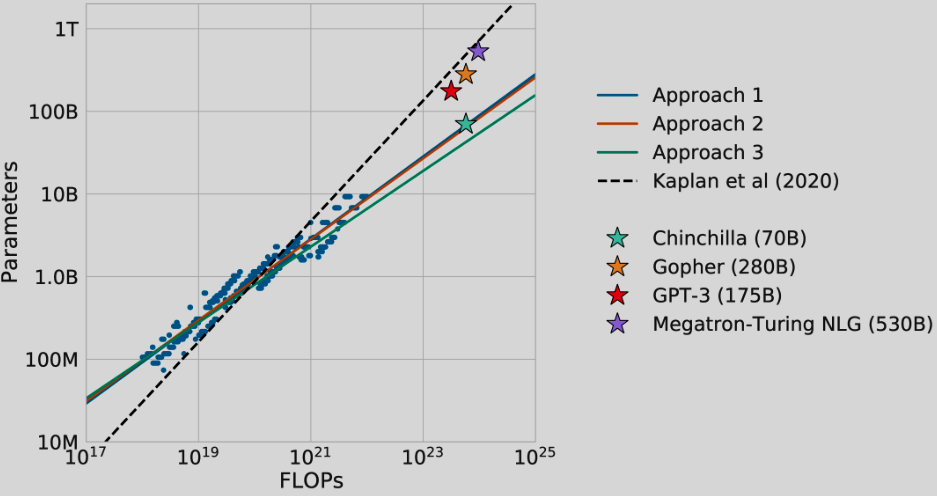
四、Chinchilla
Chinchilla 是一个 70B 参数模型,经过 1.4 万亿个代币训练为计算最优模型。 研究结果表明,通过同等缩放模型大小和训练标记,可以对这些类型的模型进行最佳训练。 它使用与 Gopher 相同的计算预算,但训练数据多出 4 倍。 Chinchilla 和 Gopher 接受相同次数的 FLOP 训练。 它是使用 MassiveText 使用稍微修改过的 SentencePiece 标记器进行训练的。 论文中有更多架构细节。
五、Galactica
Gactica 是一种语言模型,它在仅解码器设置中使用 Transformer 架构,并进行了以下修改:
它在所有模型尺寸上使用 GeLU 激活
它对所有模型尺寸使用 2048 长度的上下文窗口
它不使用任何密集内核或层规范中的偏差
它为模型使用学习的位置嵌入
使用 BPE 构建了 50k 个标记的词汇表。 词汇表是从随机选择的 2% 训练数据子集生成的

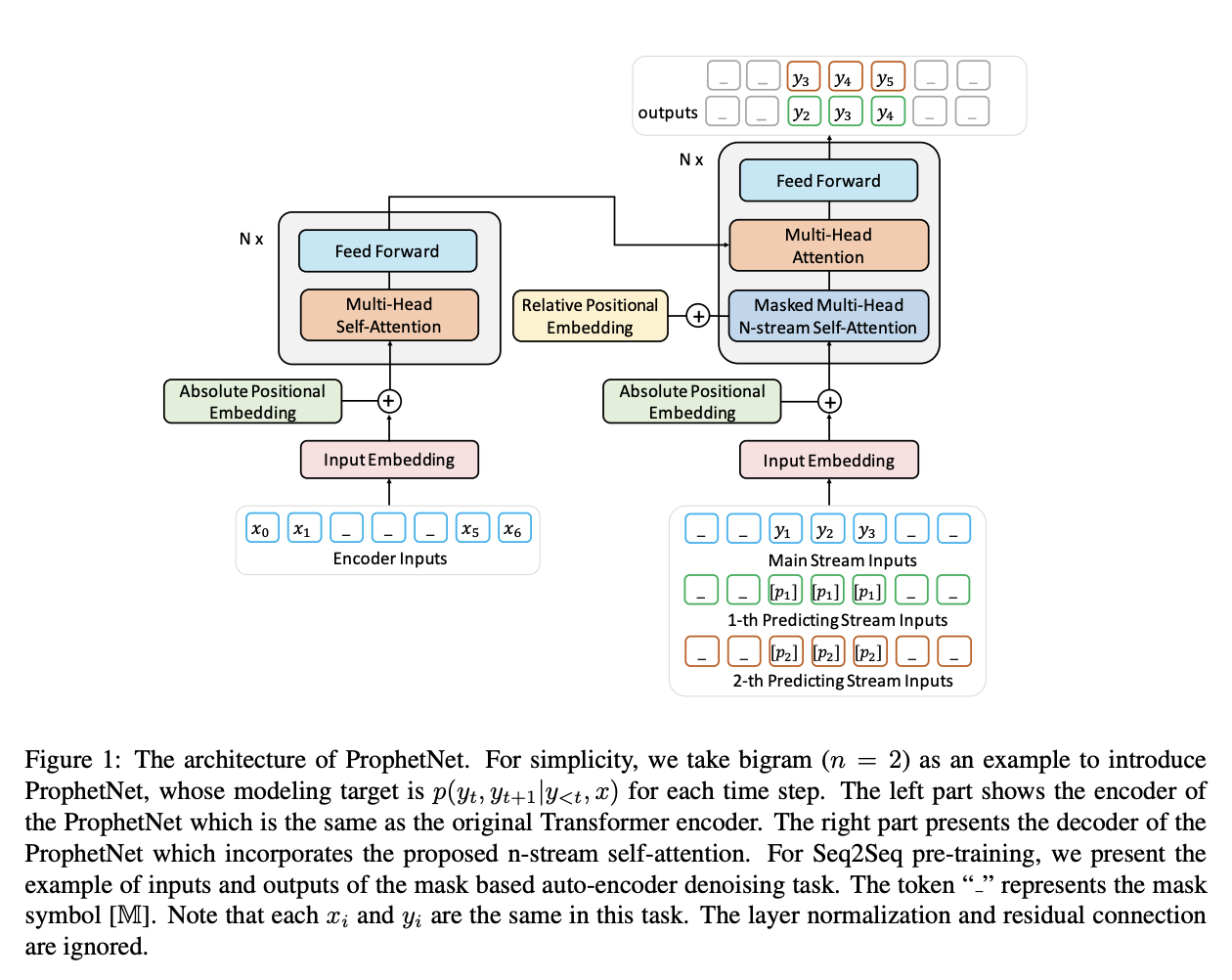
六、ProphetNet
ProphetNet 是一种序列到序列的预训练模型,引入了一种称为未来 n 元语法预测的新型自监督目标和所提出的 n 流自注意力机制。 ProphetNet 没有优化传统序列到序列模型中的一步预测,而是通过以下方式进行优化:
n- 预测下一步的超前预测在每个时间步基于先前的上下文标记同时标记。 未来的 n-gram 预测明确鼓励模型规划未来的 token,并进一步帮助预测多个未来的 token。
七、GPT-NeoX
GPT-NeoX 是一种自回归 Transformer 解码器模型,其架构很大程度上遵循 GPT-3 的架构,但有一些明显的偏差。 该模型有 200 亿个参数,44 层,隐藏维度大小为 6144,64 个头。 与 GPT-3 的主要区别是标记器的变化、旋转位置嵌入的添加、注意力层和前馈层的并行计算,以及不同的初始化方案和超参数。
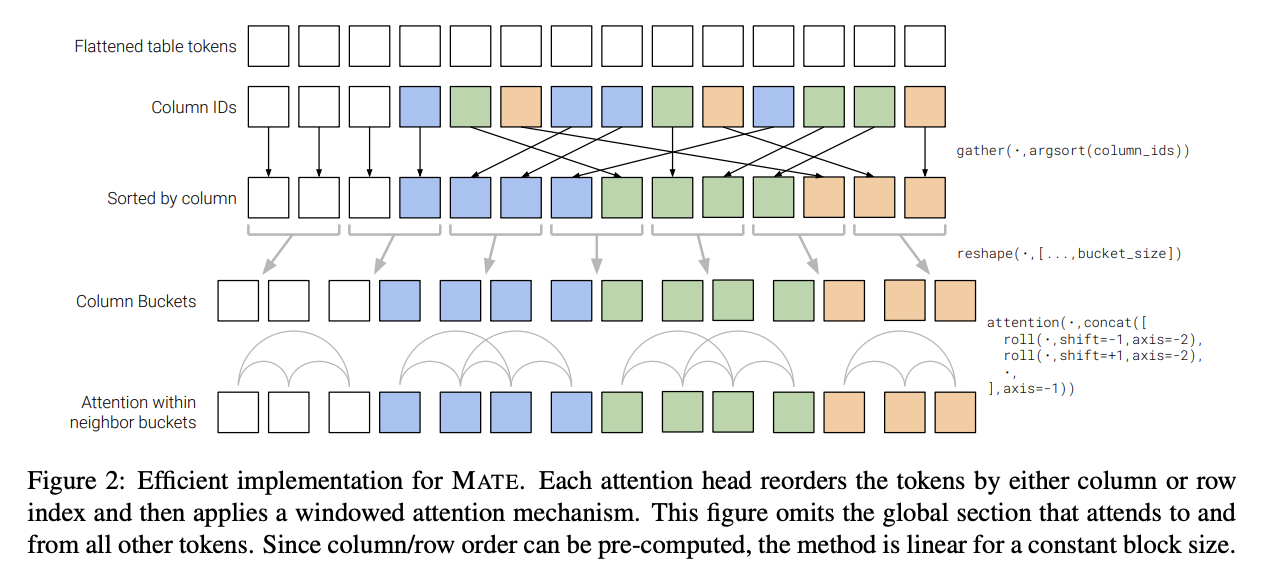
八、MATE
MATE 是一种 Transformer 架构,旨在对 Web 表的结构进行建模。 它使用稀疏注意力的方式允许头有效地关注表中的行或列。 每个注意力头按列或行索引对标记重新排序,然后应用窗口注意力机制。 与传统的自注意力机制不同,Mate 在序列长度上线性缩放。
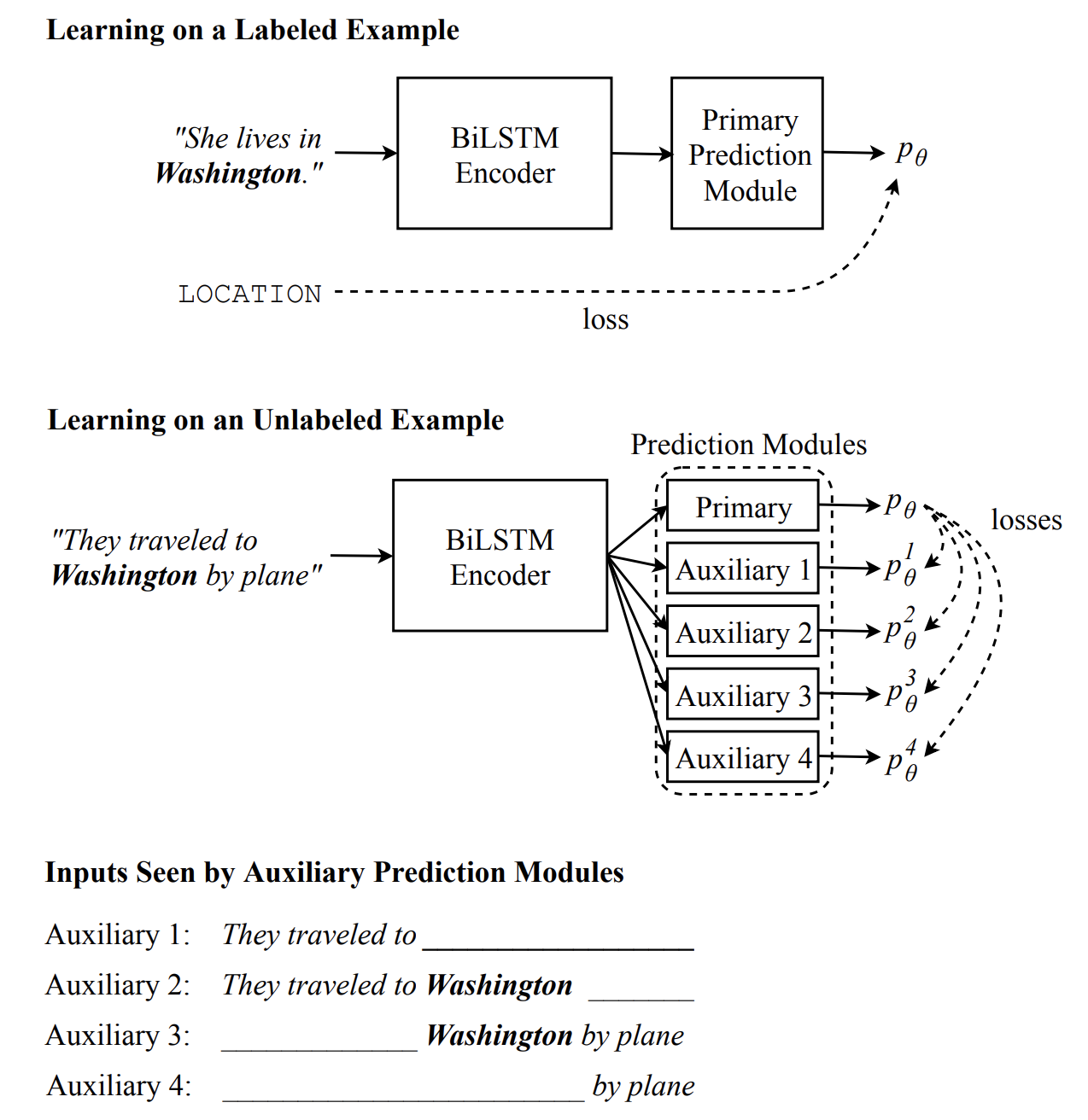
九、Cross-View Training
交叉视图训练(CVT)是一种半监督算法,用于训练分布式单词表示,它利用未标记和标记的示例。

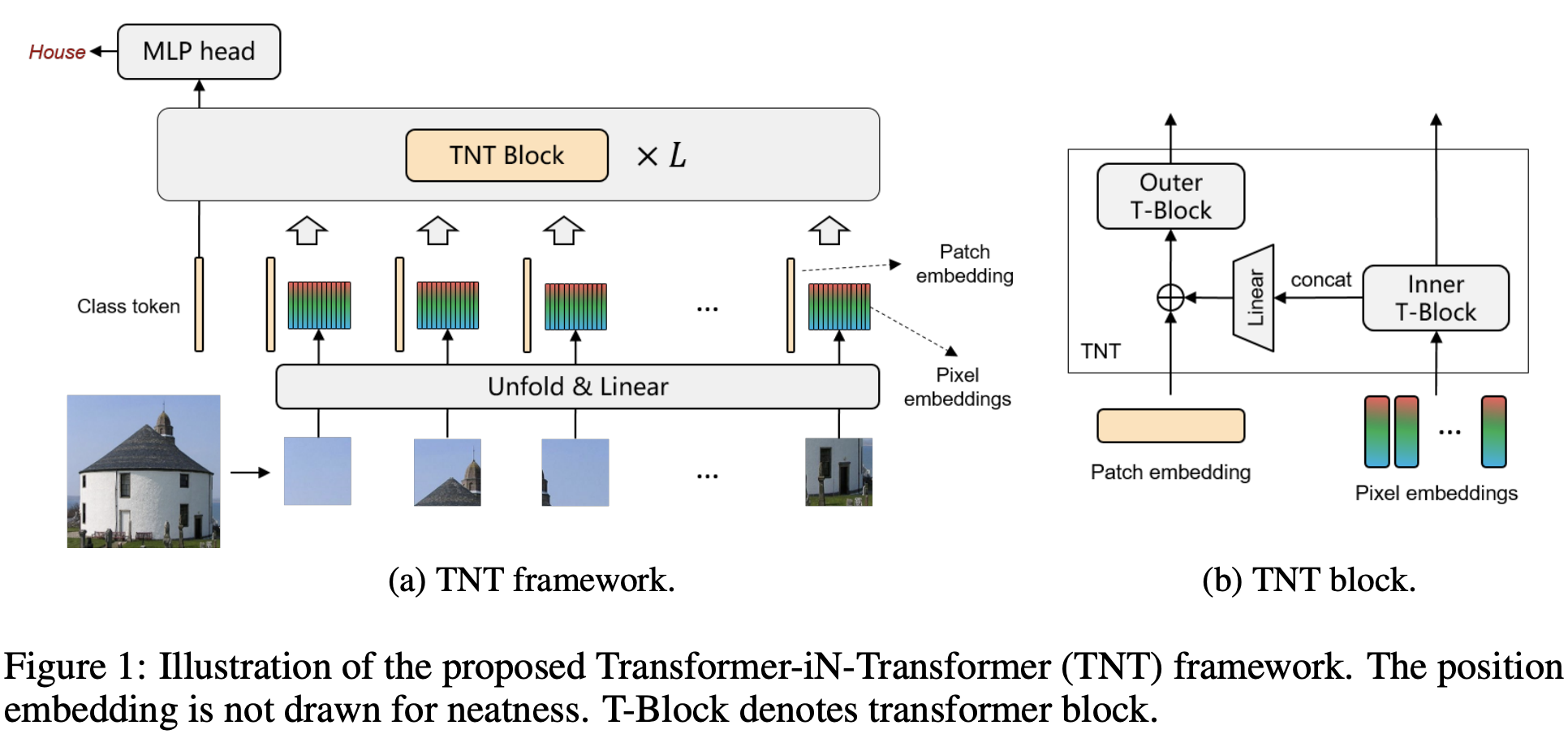
十、Transformer in Transformer
Transformer 是一种最初应用于 NLP 任务的基于自注意力的神经网络。 最近,提出了纯基于变压器的模型来解决计算机视觉问题。 这些视觉转换器通常将图像视为一系列补丁,而忽略每个补丁内部的内在结构信息。 在本文中,我们提出了一种新颖的 Transformer-iN-Transformer (TNT) 模型,用于对块级和像素级表示进行建模。 在每个 TNT 块中,外部变压器块用于处理补丁嵌入,内部变压器块从像素嵌入中提取局部特征。 像素级特征通过线性变换层投影到补丁嵌入的空间,然后添加到补丁中。 通过堆叠 TNT 块,我们构建了用于图像识别的 TNT 模型。
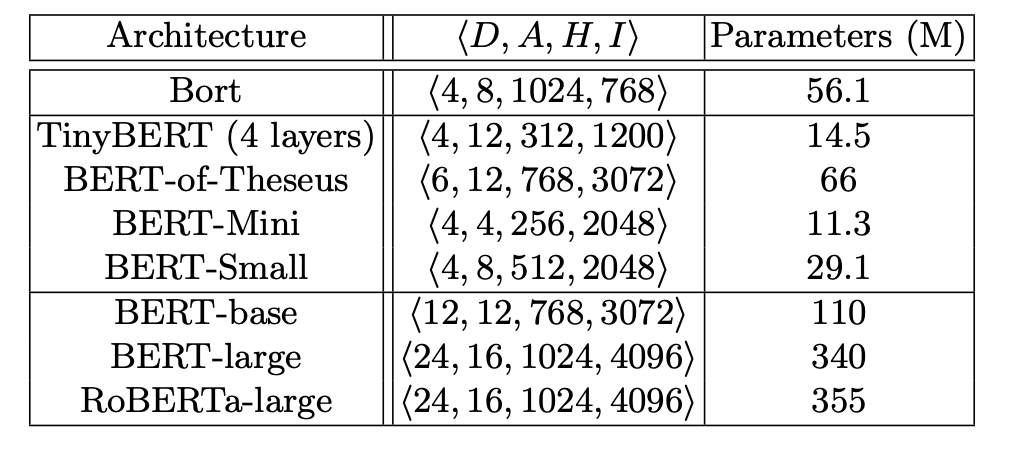
十一、Bort
Bort 是 BERT 架构的参数化架构变体。 它通过神经架构搜索方法提取 BERT 架构的架构参数的最佳子集; 特别是完全多项式时间近似方案(FPTAS)。 这个最佳子集 - “Bort” - 显然更小,Bort 还可以进行预训练GPU 小时数,即少于预训练性能最高的 BERT 参数化架构变体 RoBERTa-large (RoBERTa) 所需的时间,大约 33 美元%
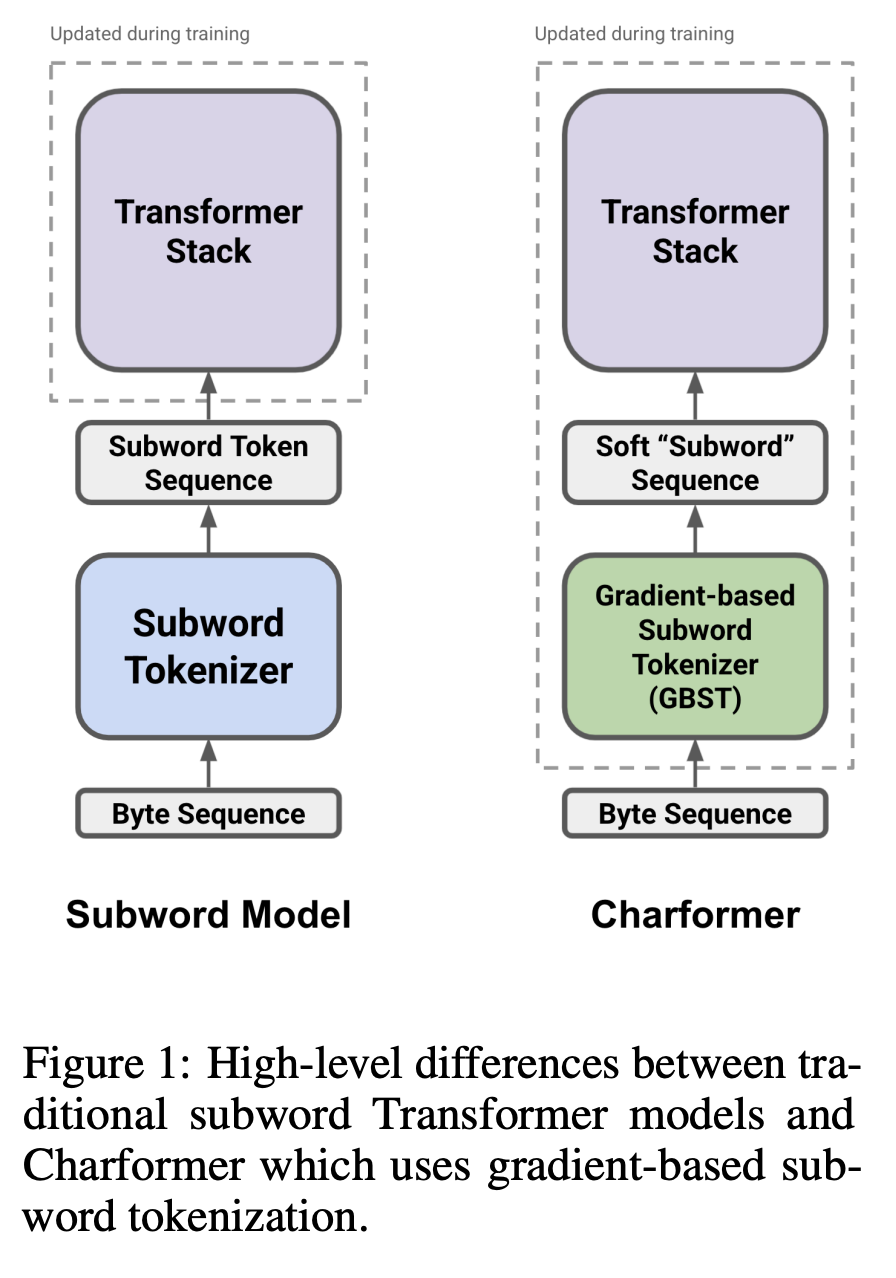
十二、Charformer
Charformer 是 Transformer 模型的一种,它作为模型的一部分端到端地学习子词标记化。 具体来说,它使用 GBST 以数据驱动的方式自动从字符中学习潜在的子词表示。 GBST 之后,软子字序列通过 Transformer 层。