文章目录
一、Inverted Bottleneck BERT
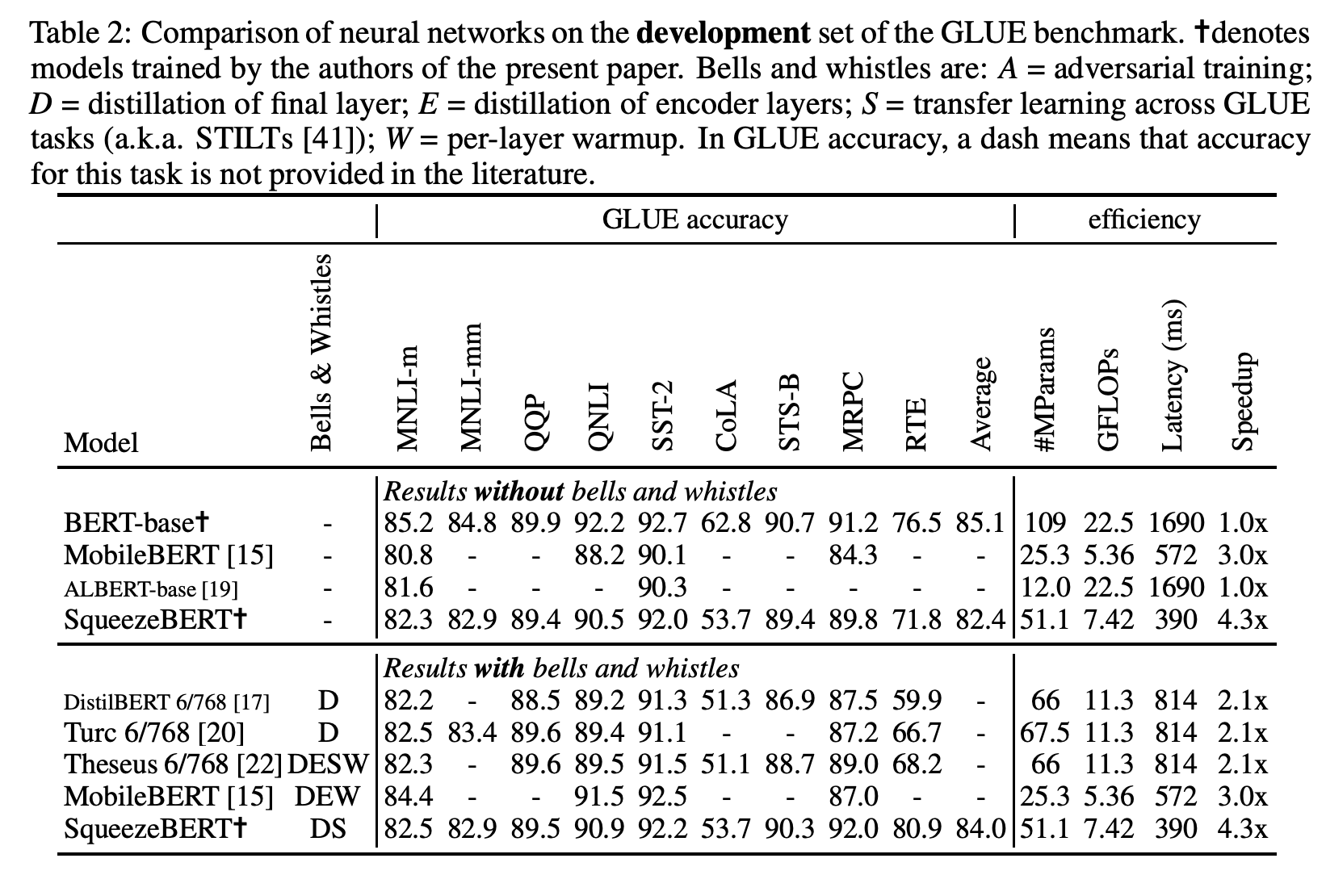
IB-BERT,即 Inverted Bottleneck BERT,是使用倒瓶颈结构的 BERT 变体。 它用作教师网络来训练 MobileBERT 模型。
二、MacBERT
MacBERT 是一个基于 Transformer 的中文 NLP 模型,它以多种方式改变了 RoBERTa,包括修改后的掩蔽策略。 MacBERT 没有使用在微调阶段从未出现的 [MASK] 标记进行屏蔽,而是使用其相似的单词来屏蔽该单词。 具体来说,MacBERT 与 BERT 共享相同的预训练任务,但有一些修改。 对于MLM任务,进行以下修改:
使用全字掩码以及 Ngram 掩码策略来选择掩码候选标记,字级一元到 4 元的比例为 40%、30%、20%、10%。
与使用[MASK]标记进行掩码不同,该标记在微调阶段中从未出现过,而是使用类似的单词来达到掩码目的。 使用基于word2vec相似度计算的Synonyms工具包获得相似词。 如果选择一个 N-gram 来屏蔽,我们将单独找到相似的单词。 在极少数情况下,当没有相似的单词时,我们会降级使用随机单词替换。
15%的输入单词用于掩码,其中80%将替换为相似单词,10%替换为随机单词,其余10%保留原始单词。

三、CPM-2
CPM-2是一个基于标准Transformer架构的110亿参数预训练语言模型,由双向编码器和单向解码器组成。 该模型在 WuDaoCorpus 上进行预训练,其中包含 2.3TB 清理后的中文数据以及 300GB 清理后的英文数据。 CPM-2的预训练过程可分为三个阶段:中文预训练、双语预训练、MoE预训练。 具有知识继承的多阶段训练可以显着降低计算成本。
四、mBARTHez
BARThez 是基于 BART 的法语自监督迁移学习模型。 与现有的基于 BERT 的法语模型(例如 CamemBERT 和 FlauBERT)相比,BARThez 非常适合生成任务,因为它的编码器和解码器都经过了预训练。

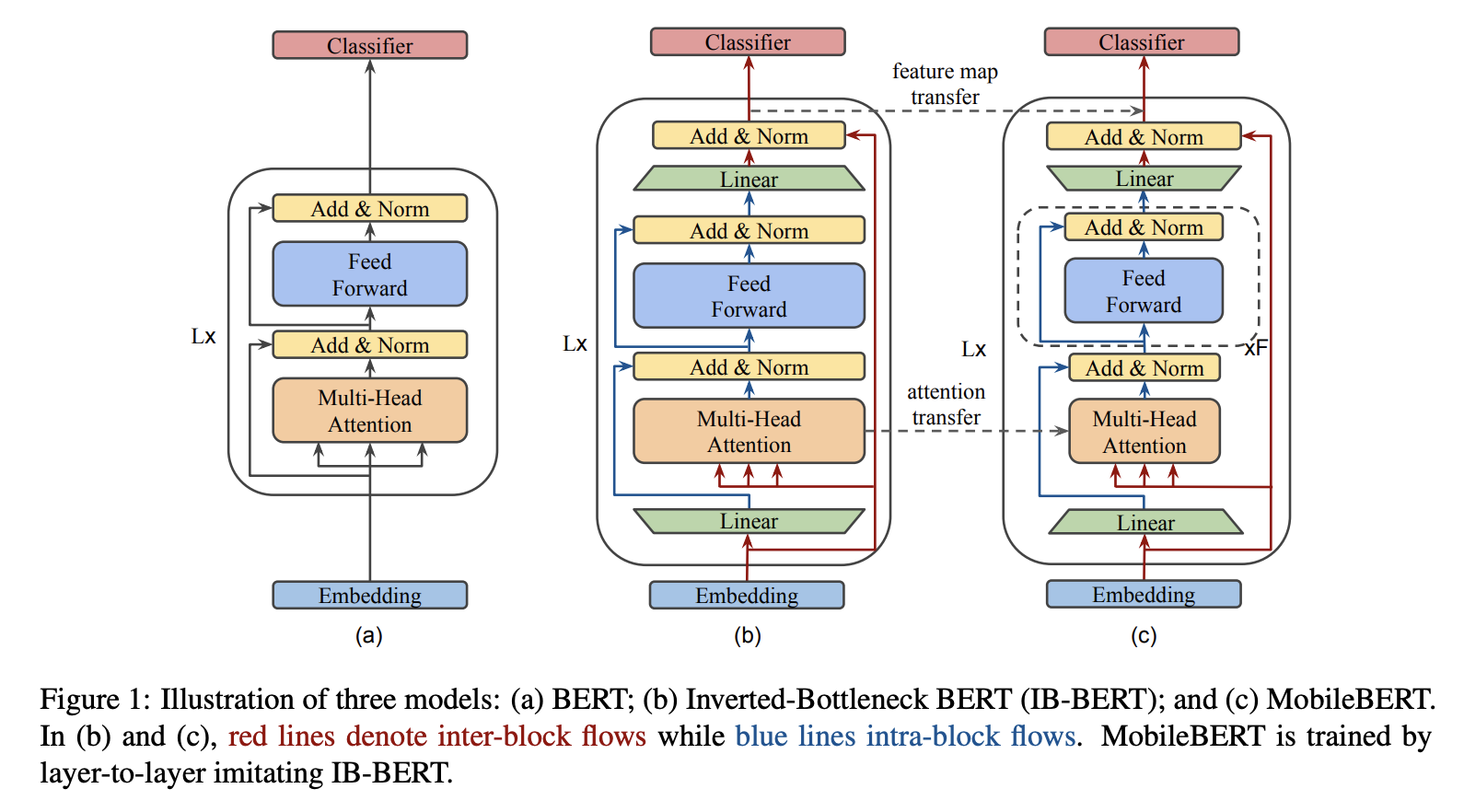
五、PanGu— α \alpha α
一个自回归语言模型 (ALM),在大型文本语料库(主要是中文)上预训练了多达 2000 亿个参数。 PanGu-α的架构基于 Transformer,Transformer 已被广泛用作多种预训练语言模型(例如 BERT 和 GPT)的骨干。 与它们不同的是,在 Transformer 层之上开发了一个额外的查询层,旨在显式地诱导预期输出。
六、OPT-IML
OPT-IML 是 OPT 的一个版本,针对 1500 多个 NLP 任务(分为不同的任务类别)进行了微调。
七、Siamese Multi-depth Transformer-based Hierarchical Encoder(SMITH)
SMITH(即 Siamese Multi-depth Transformer-based Hierarchical Encoder)是一种基于 Transformer 的文档表示学习和匹配模型。 它包含多种设计选择,以使自注意力模型适应长文本输入。 对于模型预训练,除了 BERT 中使用的原始掩码词语言模型任务之外,还使用了掩码句子块语言建模任务,以捕获文档内的句子块关系。 给定一系列句子块表示,文档级 Transformer 学习每个句子块的上下文表示和最终文档表示。

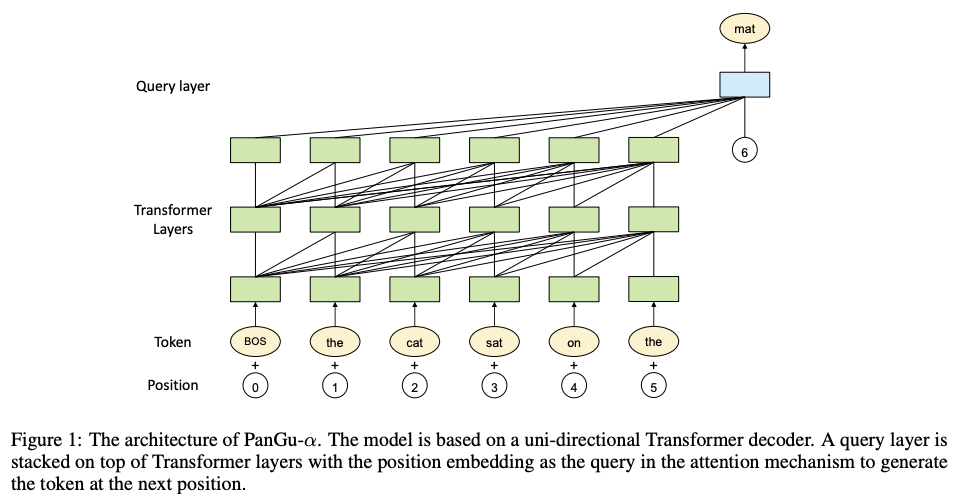
八、ClipBERT
ClipBERT 是一个用于视频和语言任务的端到端学习的框架,它采用稀疏采样,其中每个训练步骤仅使用视频中的一个或几个稀疏采样的短片。 ClipBERT 与之前的工作有两个不同之处。
首先,与密集提取视频特征(大多数现有方法采用的)相比,CLIPBERT 在每个训练步骤中仅从完整视频中稀疏地采样一个或几个短剪辑。 假设是稀疏剪辑的视觉特征已经捕获了视频中的关键视觉和语义信息,因为连续剪辑通常包含来自连续场景的相似语义。 因此,几个剪辑就足以进行训练,而不是使用完整的视频。 然后,聚合来自多个密集采样片段的预测,以在推理过程中获得最终的视频级预测,这对计算量要求较低。
第二个区别方面涉及模型权重的初始化(即通过预训练进行转移)。 作者使用 2D 架构(例如 ResNet-50)而不是 3D 特征作为视频编码的视觉主干,使他们能够利用图像文本预训练的强大功能来理解视频文本,以及低内存成本和运行时间的优势 效率。
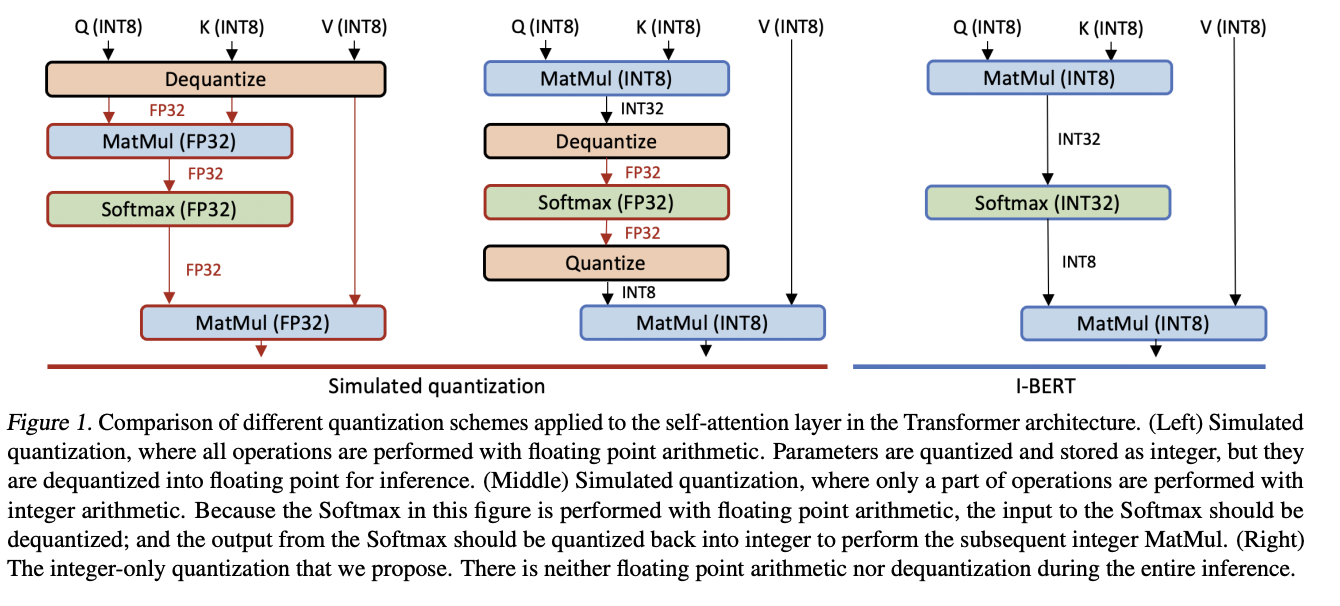
九、I-BERT
I-BERT 是 BERT 的量化版本,它使用纯整数算术来量化整个推理。 基于用于非线性运算的轻量级纯整数近似方法,例如 GELU、Softmax 和 Layer Normalization,它执行端到端纯整数 BERT 推理,无需任何浮点计算。
特别是,GELU 和 Softmax 使用轻量级二阶多项式进行近似,可以使用纯整数算术进行评估。 对于 LayerNorm,通过利用已知的平方根整数计算算法来执行仅整数计算。
十、SqueezeBERT
SqueezeBERT 是 BERT 的一种高效架构变体,用于使用分组卷积的自然语言处理。 它很像 BERT-base,但具有以卷积形式实现的位置前馈连接层,以及许多层的分组卷积。