文章目录
语言模型是用于预测文档中下一个单词或字符的模型。 您可以在下面找到不断更新的语言模型列表。
一、Transformer
Transformer 是一种模型架构,它避免重复,而是完全依赖注意力机制来绘制输入和输出之间的全局依赖关系。 在《变形金刚》出现之前,主要的序列转导模型基于复杂的循环或卷积神经网络,其中包括编码器和解码器。 Transformer 还采用了编码器和解码器,但为了支持注意力机制而消除了循环,与 RNN 和 CNN 等方法相比,可以实现显着更高的并行化。
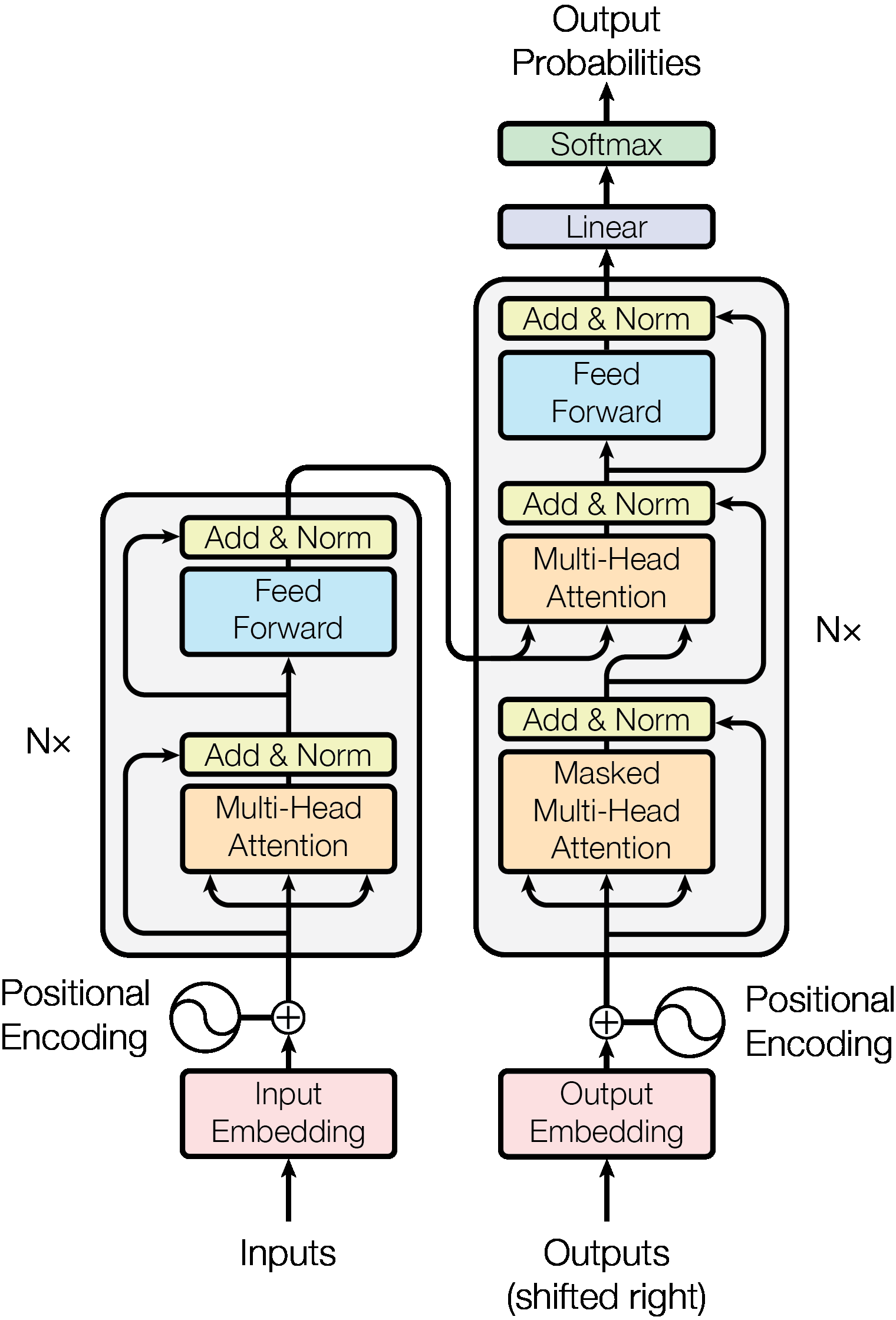
二、BERT
BERT(即 Transformer 的双向编码器表示)通过使用掩码语言模型 (MLM) 预训练目标消除单向性约束,对标准 Transformer 进行了改进。 屏蔽语言模型随机屏蔽输入中的一些标记,目标是仅根据上下文来预测屏蔽词的原始词汇 ID。 与从左到右的语言模型预训练不同,MLM 目标使表示能够融合左右上下文,这使我们能够预训练深度双向 Transformer。 除了掩码语言模型之外,BERT 还使用联合预训练文本对表示的下一句预测任务。
BERT有两个步骤:预训练和微调。 在预训练期间,模型在不同的预训练任务中使用未标记的数据进行训练。 为了进行微调,首先使用预训练的参数初始化 BERT 模型,然后使用来自下游任务的标记数据对所有参数进行微调。 每个下游任务都有单独的微调模型,即使它们是使用相同的预训练参数进行初始化的。
三、GPT-3
GPT-3 是一个自回归 Transformer 模型,拥有 1750 亿个参数。 它使用与 GPT-2 相同的架构/模型,包括修改后的初始化、预归一化和可逆标记化,但 GPT-3 在变压器层中使用交替密集和局部带状稀疏注意力模式,类似于 稀疏变压器。
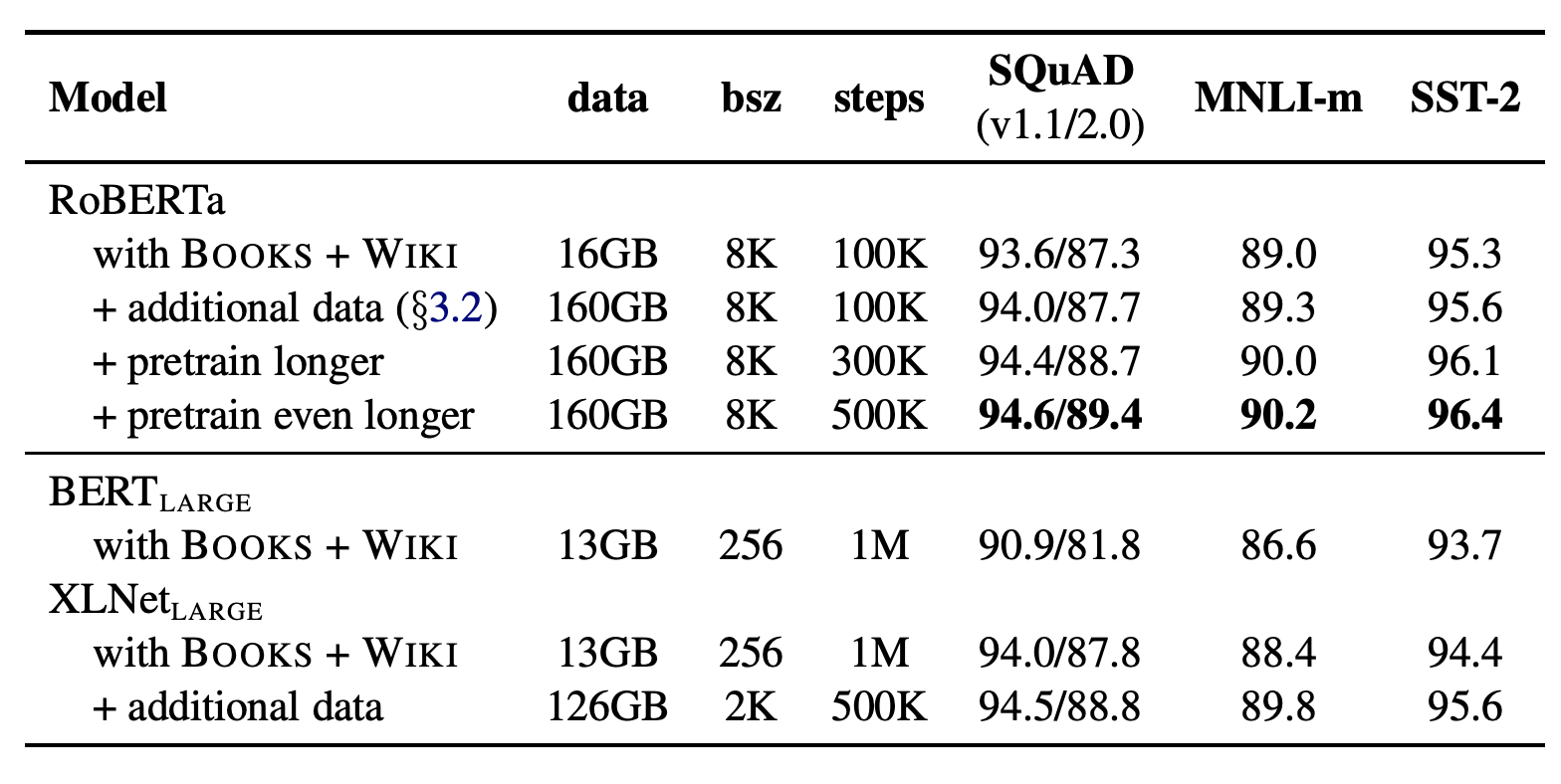
四、RoBERTa
RoBERTa 是 BERT 的扩展,对预训练过程进行了更改。 修改内容包括:
使用更多数据、更大批次、更长时间地训练模型
删除下一个句子的预测目标
较长序列的训练
动态改变应用于训练数据的掩蔽模式。 作者还收集了一个大型的新数据集与其他私人使用的数据集大小相当,以更好地控制训练集大小的影响
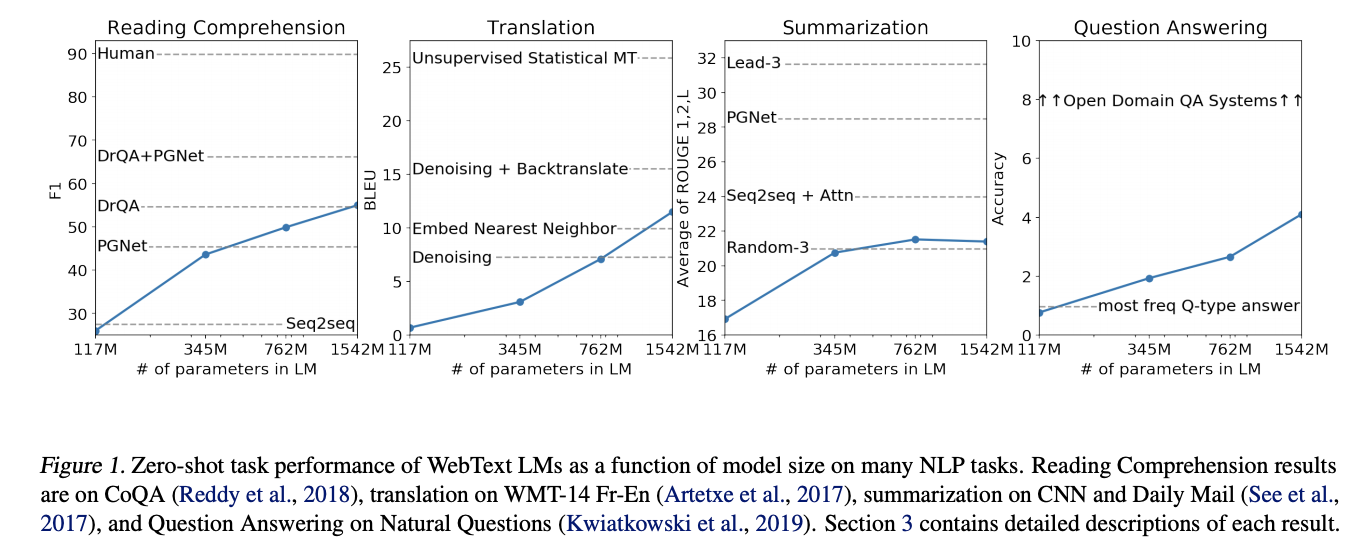
五、GPT-2
GPT-2 是一种 Transformer 架构,在发布时以其规模(15 亿个参数)而闻名。 该模型在 WebText 数据集(来自 4500 万个网站链接的文本)上进行了预训练。 它很大程度上沿袭了之前的 GPT 架构,但做了一些修改:
层归一化被移至每个子块的输入,类似于预激活残差网络,并且在最终自注意力块之后添加了额外的层归一化。
使用了修改后的初始化,该初始化考虑了残差路径上随模型深度的累积。 残差层的权重在初始化时按以下因子缩放在哪里是剩余层的数量。
词汇量扩大到50,257个。 上下文大小从 512 个令牌扩展到 1024 个令牌,并且使用了更大的批量大小 512。
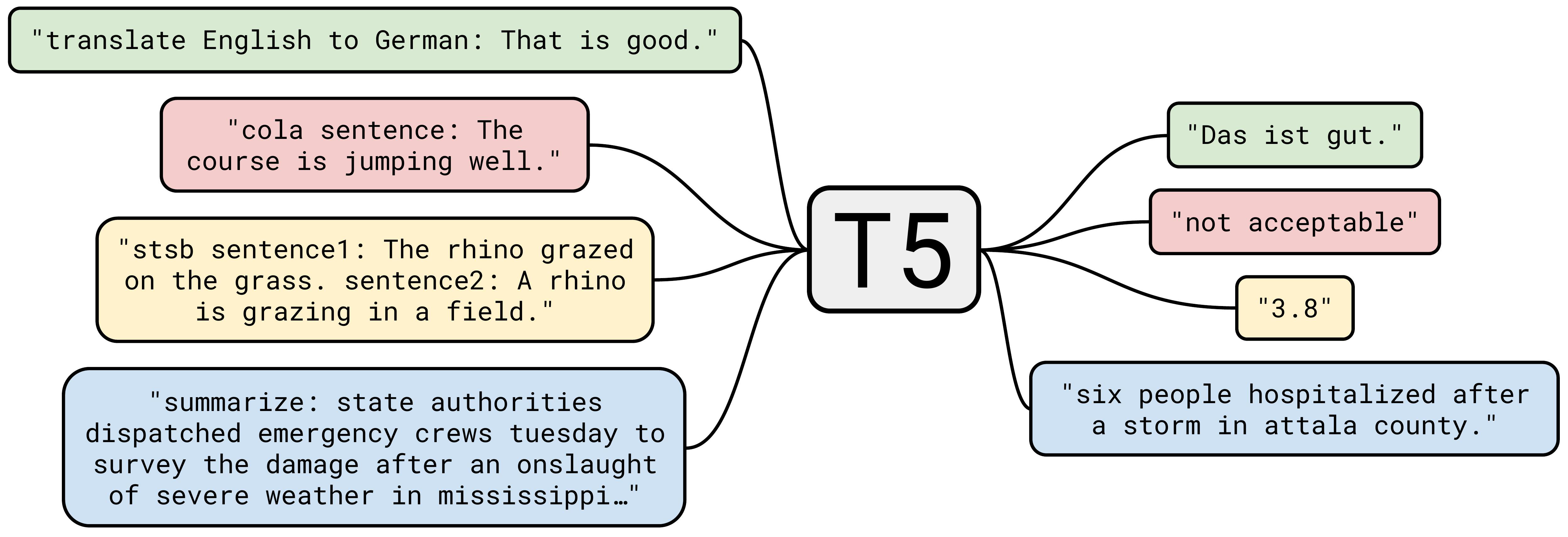
六、T5
T5(即文本到文本传输转换器)是一种基于转换器的架构,使用文本到文本的方法。 每项任务(包括翻译、问答和分类)都被视为将模型文本作为输入并训练它生成一些目标文本。 这允许在我们不同的任务集中使用相同的模型、损失函数、超参数等。 与 BERT 相比的变化包括:
在双向架构中添加因果解码器。
用替代预训练任务的组合取代填空完形填空任务。
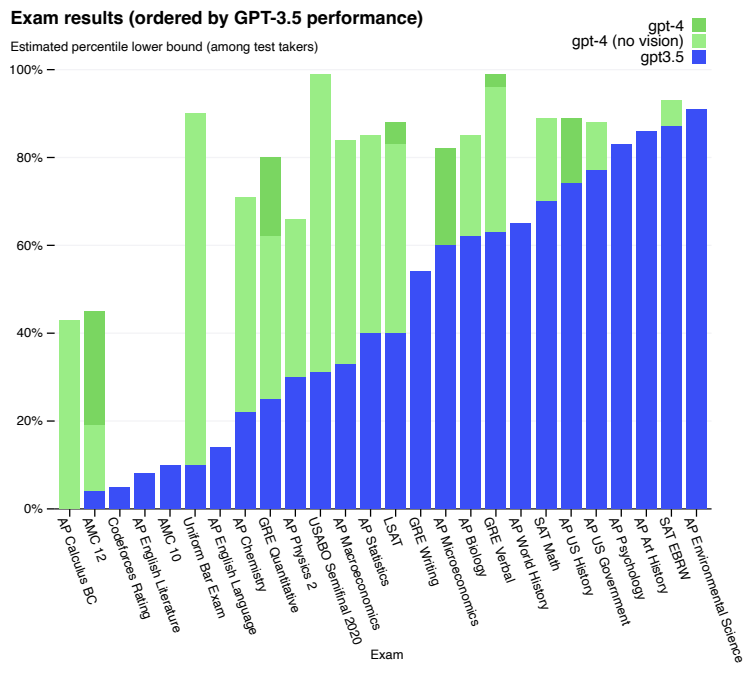
七、GPT-4
GPT-4 是一种基于 Transformer 的模型,经过预先训练,可以预测文档中的下一个标记。
八、GPT
GPT 是一种基于 Transformer 的架构和训练程序,用于自然语言处理任务。 培训遵循两个阶段的程序。 首先,在未标记的数据上使用语言建模目标来学习神经网络模型的初始参数。 随后,使用相应的监督目标使这些参数适应目标任务。
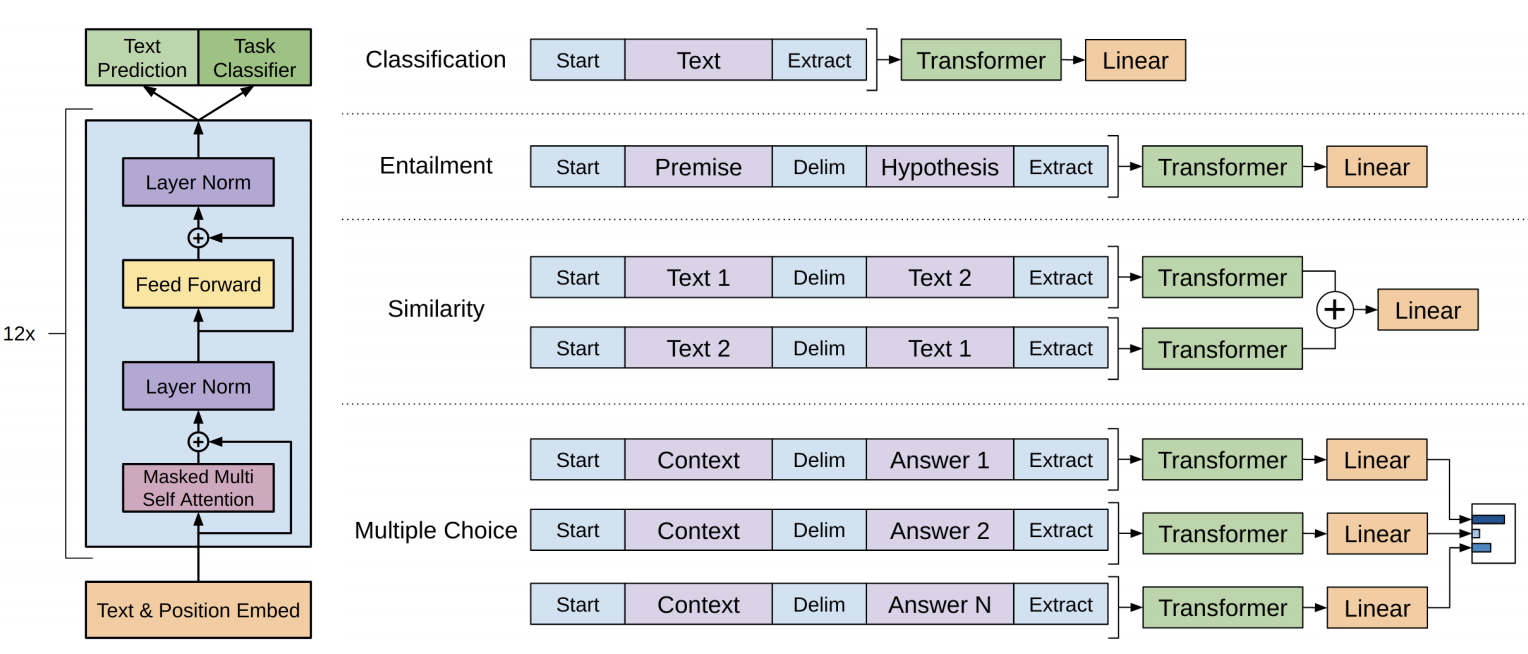
九、BART
BART 是一种用于预训练序列到序列模型的去噪自动编码器。 它的训练方式是:(1) 使用任意噪声函数破坏文本,以及 (2) 学习模型来重建原始文本。 它使用标准的基于 Transformer 的神经机器翻译架构。 它使用标准的 seq2seq/NMT 架构,带有双向编码器(如 BERT)和从左到右的解码器(如 GPT)。 这意味着编码器的注意力掩模是完全可见的,如 BERT,而解码器的注意力掩模是因果的,如 GPT2。
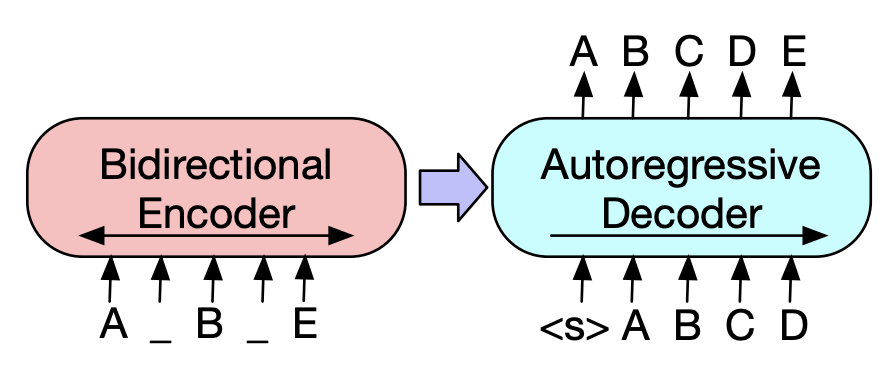
十、ELMo
语言模型嵌入(ELMo)是一种深度语境化的单词表示,它可以模拟(1)单词使用的复杂特征(例如语法和语义),以及(2)这些使用在语言环境中如何变化(即, 模型一词多义)。 词向量是深度双向语言模型 (biLM) 内部状态的学习函数,该模型是在大型文本语料库上进行预训练的。

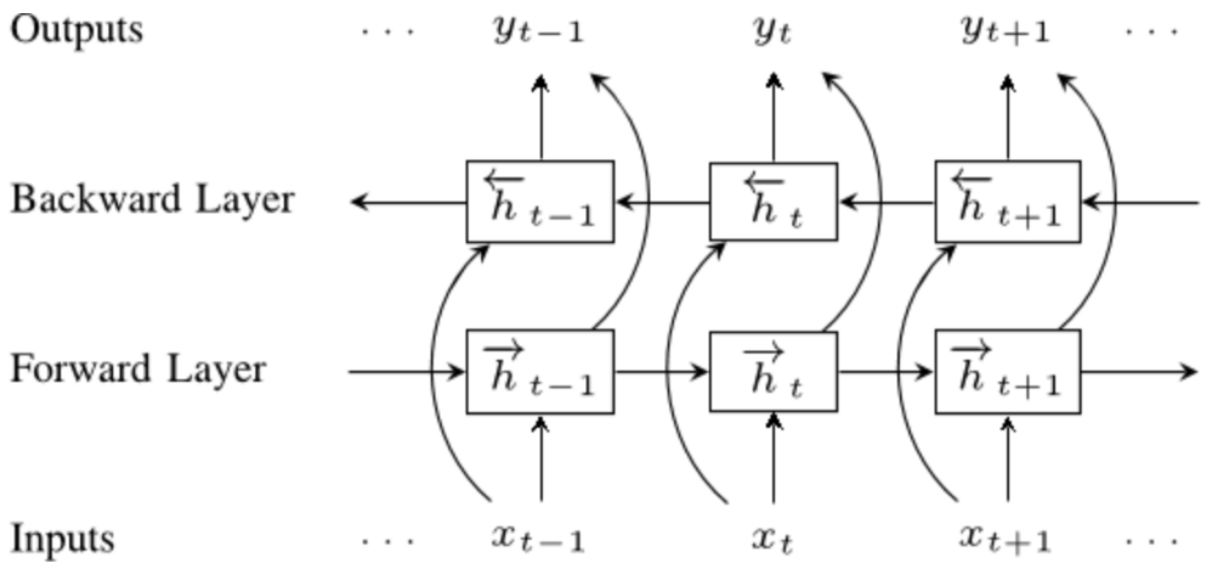
十一、Class-activation map
类激活图可用于解释卷积神经网络 (CNN) 做出的预测决策。
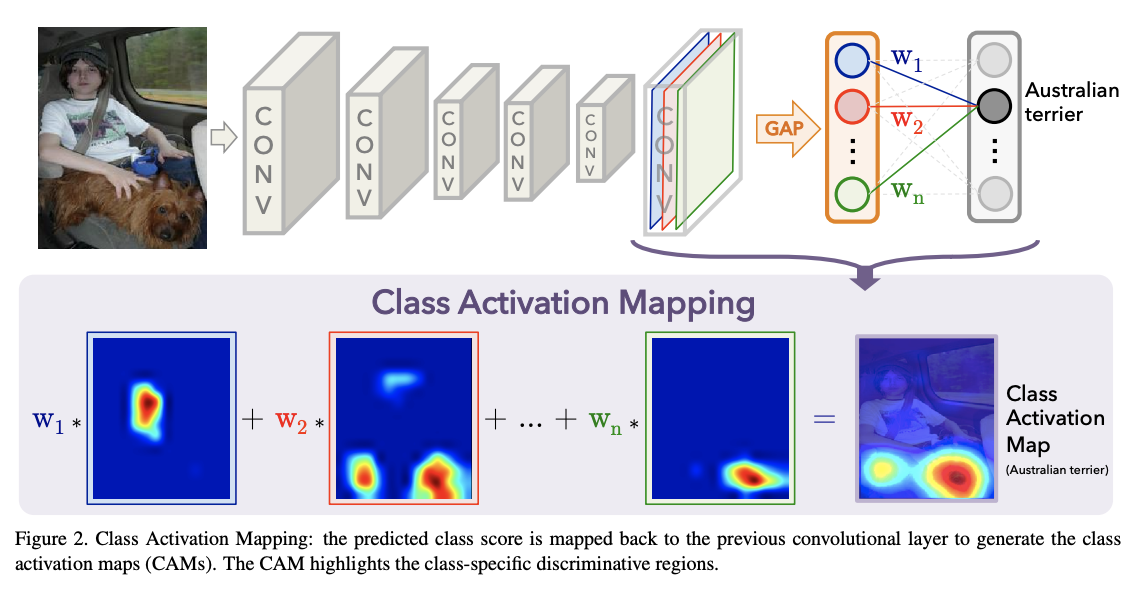
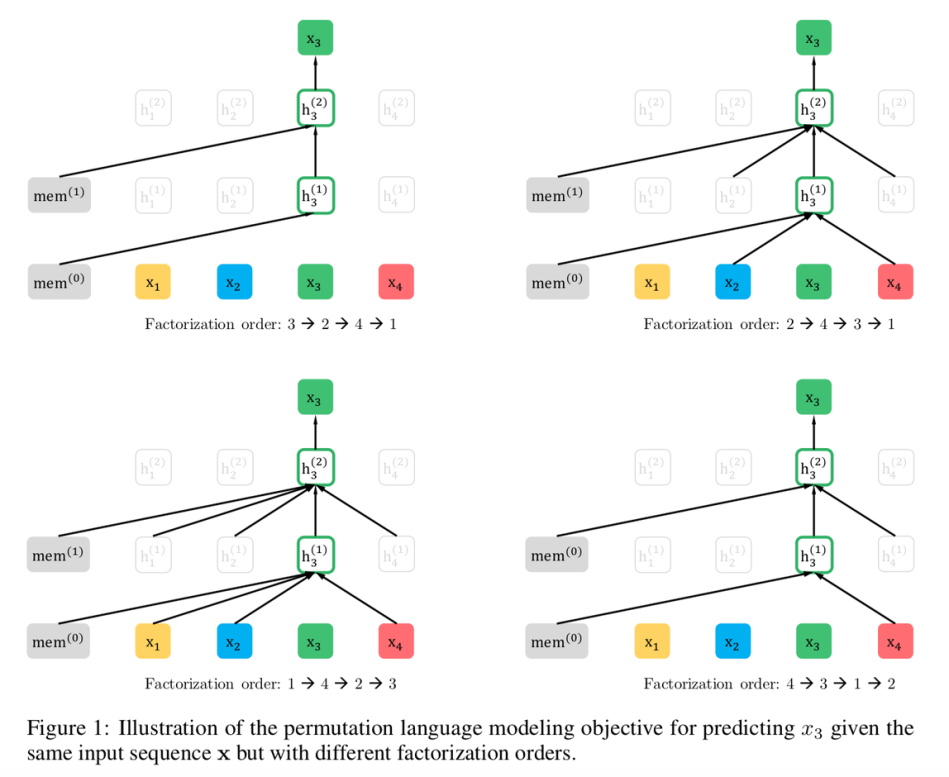
十二、XLNet
XLNet 是一种自回归 Transformer,它充分利用了自回归语言建模和自动编码的优点,同时试图避免它们的局限性。 XLNet 不像传统自回归模型那样使用固定的前向或后向分解顺序,而是最大化序列的预期对数似然。 因式分解顺序的所有可能排列。 由于排列操作,每个位置的上下文可以由来自左侧和右侧的标记组成。 在预期中,每个位置都会学习利用来自所有位置的上下文信息,即捕获双向上下文。
此外,受自回归语言建模最新进展的启发,XLNet将Transformer-XL的分段递归机制和相对编码方案集成到预训练中,从经验上提高了性能,特别是对于涉及较长文本序列的任务。