(书接上文)
五、贝叶斯博弈与混合战略均衡:
纯化定理( purification theorem;Harsanyi,1973):完全信息静态博弈中的一个混合战略博弈几乎总是可以被解释成一个有少量不完全信息的近似博弈的一个纯战略贝叶斯纳什均衡。
进一步可理解成“一个混合战略纳什均衡的根本特征不是参与人以随机的方法选择战略(即行为),而是各参与人对其他参与人的选择不能确定,这种不确定性既可以是随机性引起,也可以是少量信息的不完全性引起。”
(大白话翻译就是:一个混合战略的纳什均衡可以简单的分成几个纯战略纳什均衡问题)
【例题】夫妻之争
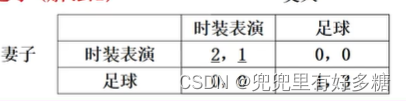
有两个纯战略纳什均衡(时装,时装)、(足球,足球),还有一个混合战略纳什均衡,即妻子以3/4的概率选时装,以1/ 4的概率选足球,丈夫以1/3的概率选时装,以2 / 3的概率选足球。
以上是前两章解决问题的方法。
还可以用一中概率的方法解决该问题:

【解法一】
丈夫对妻子看时装表演的得益不完全清楚,妻子对丈夫看足球的得益也不完全清楚。此时我们就把一个完全信息的静态博弈转换成了一个不完全信息的静态博弈。
这个不完全信息表现在丈夫对妻子看时装表演的得益不完全清楚,妻子对丈夫看足球的得益也不完全清楚。但我们要对其概率分布有一个了解,此处假设这个分布是一个 [ 0 , x ] [0,x] [0,x]的均匀分布,那么密度函数就是 1 / x 1/x 1/x。我们用参与人1表示妻子,参与人2表示丈夫。
用下面这式子来计算妻子如何达到最佳收益(就是给定丈夫的选择的情况下妻子如何选择,从而能使得妻子自己的期望效用最大化)
max t 1 ∈ T 1 ∫ 0 x ( s 1 , s 2 ∗ ) 1 x d t 2 = max t 1 ∈ T 1 { [ ∫ 0 t 2 ∗ ( s 1 = a 1 , s 2 ∗ = a 1 ) 1 x d t 2 + ∫ t 2 ∗ x ( s 1 = a 1 , s 2 ∗ = a 2 ) 1 x d t 2 ] i f t 1 ≥ t 1 ∗ (当妻子的想看服装秀的程度很高的时候,不论丈夫选择什么,妻子都会选择服装秀) [ ∫ 0 t 2 ∗ ( s 1 = a 2 , s 2 ∗ = a 1 ) 1 x d t 2 + ∫ t 2 ∗ x ( s 2 = a 2 , s 2 ∗ = a 2 ) 1 x d t 2 ] i f t 1 < t 1 ∗ (当妻子的没有那么想看服装秀的时候,不论丈夫选择什么,妻子都会选择足球) = max t 1 ∈ T 1 { [ ∫ 0 t 2 ∗ ( 2 + t 1 ) 1 x d t 2 + ∫ t 2 ∗ x 0 × 1 x d t 2 ] = ( 2 + t 1 ) t 2 ∗ x [ ∫ 0 t 2 ∗ 0 × 1 x d t 2 + ∫ t 2 ∗ x 1 × 1 x d t 2 ] = x − t 2 ∗ x ⇒ ( 2 + t 1 ∗ ) t 2 ∗ x = x − t 2 ∗ x i f t 1 = t 1 ∗ ( 让妻子选择时装秀或者选择足球的期望收益相等,这时就是妻子最佳的得益所对应的参数分布 ) \begin{aligned} & \max _{t_1 \in T_1} \int_0^x\left(s_1, s_2^*\right) \frac{1}{x} d t_2 \\ & =\max _{t_1 \in T_1}\left\{\begin{array}{l} {\left[\int_0^{t_2^*}\left(s_1=a_1, s_2^*=a_1\right) \frac{1}{x} d t_2+\int_{t_2^*}^x\left(s_1=a_1, s_2^*=a_2\right) \frac{1}{x} d t_2\right] i f t_1 \geq t_1^*} \\ (当妻子的想看服装秀的程度很高的时候,不论丈夫选择什么,妻子都会选择服装秀) \\ {\left[\int_0^{t_2^*}\left(s_1=a_2, s_2^*=a_1\right) \frac{1}{x} d t_2+\int_{t_2^*}^x\left(s_2=a_2, s_2^*=a_2\right) \frac{1}{x} d t_2\right] i f t_1<t_1^*} \\ (当妻子的没有那么想看服装秀的时候,不论丈夫选择什么,妻子都会选择足球) \\ \end{array}\right. \\ & =\max _{t_1 \in T_1}\left\{\begin{array}{l} {\left[\int_0^{t_2^*}\left(2+t_1\right) \frac{1}{x} d t_2+\int_{t_2^*}^x 0 \times \frac{1}{x} d t_2\right]=\frac{\left(2+t_1\right) t_2^*}{x}} \\ {\left[\int_0^{t_2^*} 0 \times \frac{1}{x} d t_2+\int_{t_2^*}^x 1 \times \frac{1}{x} d t_2\right]=\frac{x-t_2^*}{x}} \\ \Rightarrow \frac{\left(2+t_1^*\right) t_2^*}{x}=\frac{x-t_2^*}{x} i f t_1=t_1^*\\ (让妻子选择时装秀或者选择足球的期望收益相等,这时就是妻子最佳的得益所对应的参数分布) \end{array}\right. \end{aligned} t1∈T1max∫0x(s1,s2∗)x1dt2=t1∈T1max⎩
⎨
⎧[∫0t2∗(s1=a1,s2∗=a1)x1dt2+∫t2∗x(s1=a1,s2∗=a2)x1dt2]ift1≥t1∗(当妻子的想看服装秀的程度很高的时候,不论丈夫选择什么,妻子都会选择服装秀)[∫0t2∗(s1=a2,s2∗=a1)x1dt2+∫t2∗x(s2=a2,s2∗=a2)x1dt2]ift1<t1∗(当妻子的没有那么想看服装秀的时候,不论丈夫选择什么,妻子都会选择足球)=t1∈T1max⎩
⎨
⎧[∫0t2∗(2+t1)x1dt2+∫t2∗x0×x1dt2]=x(2+t1)t2∗[∫0t2∗0×x1dt2+∫t2∗x1×x1dt2]=xx−t2∗⇒x(2+t1∗)t2∗=xx−t2∗ift1=t1∗(让妻子选择时装秀或者选择足球的期望收益相等,这时就是妻子最佳的得益所对应的参数分布)
max t 2 ∈ T 2 ∫ 0 x ( s 1 ∗ , s 2 ) 1 x d t 1 = max t 2 ∈ T 2 { [ ∫ 0 t 1 ∗ ( s 1 ∗ = a 2 , s 2 = a 1 ) 1 x d t 1 + ∫ t 1 ∗ x ( s 1 ∗ = a 1 , s 2 = a 1 ) 1 x d t 1 ] i f t 2 < t 2 ∗ [ ∫ 0 t 1 ∗ ( s 1 ∗ = a 2 , s 2 = a 2 ) 1 x d t 1 + ∫ t 1 ∗ x ( s 1 ∗ = a 1 , s 2 = a 2 ) 1 x d t 1 ] i f t 2 ≥ t 2 ∗ = max t 2 ∈ T 2 { [ ∫ 0 t 1 ∗ 0 × 1 x d t 1 + ∫ t 1 ∗ x 1 × 1 x d t 1 ] = x − t 1 ∗ x [ ∫ 0 t 1 ∗ ( 3 + t 2 ) × 1 x d t 1 + ∫ t 2 ∗ x 0 × 1 x d t 1 ] = ( 3 + t 2 ) t 1 ∗ x ⇒ x − t 1 ∗ x = ( 3 + t 2 ∗ ) t 1 ∗ x i f t 2 = t 2 ∗ \begin{aligned} & \max _{t_2 \in T_2} \int_0^x\left(s_1^*, s_2\right) \frac{1}{x} d t_1 \\ & =\max _{t_2 \in T_2}\left\{\begin{array}{l} {\left[\int_0^{t_1^*}\left(s_1^*=a_2, s_2=a_1\right) \frac{1}{x} d t_1+\int_{t_1^*}^x\left(s_1^*=a_1, s_2=a_1\right) \frac{1}{x} d t_1\right] i f t_2<t_2^*} \\ {\left[\int_0^{t_1^*}\left(s_1^*=a_2, s_2=a_2\right) \frac{1}{x} d t_1+\int_{t_1^*}^x\left(s_1^*=a_1, s_2=a_2\right) \frac{1}{x} d t_1\right] i f t_2 \geq t_2^*} \end{array}\right. \\ & =\max _{t_2 \in T_2}\left\{\begin{array}{l} {\left[\int_0^{t_1^*} 0 \times \frac{1}{x} d t_1+\int_{t_1^*}^x 1 \times \frac{1}{x} d t_1\right]=\frac{x-t_1^*}{x}} \\ {\left[\int_0^{t_1^*}\left(3+t_2\right) \times \frac{1}{x} d t_1+\int_{t_2^*}^x 0 \times \frac{1}{x} d t_1\right]=\frac{\left(3+t_2\right) t_1^*}{x}} \\ \Rightarrow \frac{x-t_1^*}{x}=\frac{\left(3+t_2^*\right) t_1^*}{x} i f t_2=t_2^* \end{array}\right. \end{aligned} t2∈T2max∫0x(s1∗,s2)x1dt1=t2∈T2max⎩
⎨
⎧[∫0t1∗(s1∗=a2,s2=a1)x1dt1+∫t1∗x(s1∗=a1,s2=a1)x1dt1]ift2<t2∗[∫0t1∗(s1∗=a2,s2=a2)x1dt1+∫t1∗x(s1∗=a1,s2=a2)x1dt1]ift2≥t2∗=t2∈T2max⎩
⎨
⎧[∫0t1∗0×x1dt1+∫t1∗x1×x1dt1]=xx−t1∗[∫0t1∗(3+t2)×x1dt1+∫t2∗x0×x1dt1]=x(3+t2)t1∗⇒xx−t1∗=x(3+t2∗)t1∗ift2=t2∗
( 2 + t 1 ∗ ) t 2 ∗ x = x − t 2 ∗ x x − t 1 ∗ x = ( 3 + t 2 ∗ ) t 1 ∗ x } ⇒ { t 1 ∗ = − 3 + 9 + 3 x 2 t 2 ∗ = − 6 + 2 9 + 3 x 3 a ∗ = { s 1 ∗ ( T 11 ) = a 1 , s 1 ∗ ( T 12 ) = a 2 ; s 2 ∗ ( T 21 ) = a 1 , s 2 ∗ ( T 22 ) = a 2 } T 11 = [ t 1 ∗ , x ] , T 12 = [ 0 , t 1 ∗ ] T 21 = [ 0 , t 2 ∗ ] , T 22 = [ t 2 ∗ , x ] \begin{aligned} &\left.\begin{array}{l} \frac{\left(2+t_1^*\right) t_2^*}{x}=\frac{x-t_2^*}{x} \\ \frac{x-t_1^*}{x}=\frac{\left(3+t_2^*\right) t_1^*}{x} \end{array}\right\} \Rightarrow\left\{\begin{array}{l} t_1^*=\frac{-3+\sqrt{9+3 x}}{2} \\ t_2^*=\frac{-6+2 \sqrt{9+3 x}}{3} \end{array}\right.\\ &\begin{aligned} & a^*=\left\{s_1^*\left(T_{11}\right)=a_1, s_1^*\left(T_{12}\right)=a_2 ; s_2^*\left(T_{21}\right)=a_1, s_2^*\left(T_{22}\right)=a_2\right\} \\ & T_{11}=\left[t_1^*, x\right], T_{12}=\left[0, t_1^*\right] T_{21}=\left[0, t_2^*\right], T_{22}=\left[t_2^*, x\right] \end{aligned} \end{aligned} x(2+t1∗)t2∗=xx−t2∗xx−t1∗=x(3+t2∗)t1∗}⇒{
t1∗=2−3+9+3xt2∗=3−6+29+3xa∗={
s1∗(T11)=a1,s1∗(T12)=a2;s2∗(T21)=a1,s2∗(T22)=a2}T11=[t1∗,x],T12=[0,t1∗]T21=[0,t2∗],T22=[t2∗,x]
我们从上面这个结论也可以证明混合概率模型的求解结果:
P ( 0 ≤ t 1 ∗ < − 3 + 9 + 3 x 2 ) = − 3 + 9 + 3 x 2 x = 3 2 ( 3 + 9 + 3 x ) ∣ x → 0 = 1 4 P ( 0 ≤ t 2 ∗ < − 6 + 2 9 + 3 x 3 ) = − 6 + 2 9 + 3 x 3 x = 4 6 + 2 9 + 3 x ∣ x → 0 = 1 3 \begin{aligned} & P\left(0 \leq t_1^*<\frac{-3+\sqrt{9+3 x}}{2}\right)=\frac{-3+\sqrt{9+3 x}}{2 x} \\ & =\frac{3}{2(3+\sqrt{9+3 x})}\Bigg|_{x\rightarrow0} = \frac{1}{4} \\ & P\left(0 \leq t_2^*<\frac{-6+2 \sqrt{9+3 x}}{3}\right)=\frac{-6+2 \sqrt{9+3 x}}{3 x} \\ & =\frac{4}{6+2 \sqrt{9+3 x}}\Bigg|_{x\rightarrow0} = \frac{1}{3} \end{aligned} P(0≤t1∗<2−3+9+3x)=2x−3+9+3x=2(3+9+3x)3
x→0=41P(0≤t2∗<3−6+29+3x)=3x−6+29+3x=6+29+3x4
x→0=31
【解法二】
设妻子的战略:当 t w > W t_w>W tw>W时,选择时装表演,否则选择足球赛;丈夫的战略与妻子相似:当 t h > h t_h>h th>h时,选择足球赛,否则选时装表演。在上述双方的战略下,因为都是 [ 0 , x ] [0,x] [0,x]上的标准分布,所以妻子选时装的概率为 ( x − w ) / x (x-w)/ x (x−w)/x,选足球赛的概率为 w / x w / x w/x;丈夫选时装表演的概率为 h / x h / x h/x,选足球赛的概率为 ( x — h ) / x (x—h)/x (x—h)/x。为了使双方上述战略组合成为贝叶斯纳什均衡,参数 W W W和 h h h必须取恰当的数值。
从妻子的角度,假设已知丈夫已经采用了上述战略,则她选时装表演和足球赛的期望得益分别为:
h x ( 2 + t w ) + x − h x × 0 = h x ( 2 + t w ) h x × 0 + x − h x × 1 = x − h x w = x h − 3 \begin{gathered} \frac{h}{x}\left(2+t_w\right)+\frac{x-h}{x} \times 0=\frac{h}{x}\left(2+t_w\right) \quad \frac{h}{x} \times 0+\frac{x-h}{x} \times 1=\frac{x-h}{x} \\ w=\frac{x}{h}-3 \end{gathered} xh(2+tw)+xx−h×0=xh(2+tw)xh×0+xx−h×1=xx−hw=hx−3
同样的,假设妻子已采用了前述临界值战略,则丈夫选择足球赛和时装表演的期望得益分别为:
w x ( 3 + t h ) + x − w x × 0 = w x ( 3 + t h ) w x × 0 + x − w x × 1 = x − w x \begin{aligned} &\frac{w}{x}\left(3+t_h\right)+\frac{x-w}{x} \times 0=\frac{w}{x}\left(3+t_h\right)\\ &\frac{w}{x} \times 0+\frac{x-w}{x} \times 1=\frac{x-w}{x} \end{aligned} xw(3+th)+xx−w×0=xw(3+th)xw×0+xx−w×1=xx−w
当选足球的期望得益不小于选时装表演的期望得益时,丈夫选择足球赛,即:
t h > = x w − 4 t_h>=\frac{x}{w}-4 th>=wx−4,由此可得: h = x w − 4 h=\frac{x}{w}-4 h=wx−4.
{ w = x h − 3 h = x w − 4 \left\{\begin{array}{l}w=\frac{x}{h}-3 \\ h=\frac{x}{w}-4\end{array}\right. {
w=hx−3h=wx−4
{ w = − 3 ± 9 + 3 x 2 = − 3 + 9 + 3 x 2 h = − 6 ± 2 9 + 3 x 3 = − 6 + 2 9 + 3 x 3 \left\{\begin{array}{l} w=\frac{-3 \pm \sqrt{9+3 x}}{2}=\frac{-3+\sqrt{9+3 x}}{2} \\ h=\frac{-6 \pm 2 \sqrt{9+3 x}}{3}=\frac{-6+2 \sqrt{9+3 x}}{3} \end{array}\right. {
w=2−3±9+3x=2−3+9+3xh=3−6±29+3x=3−6+29+3x
当参数W和h由上述两式决定时,容易证明双方的前述林觉战略构成贝叶斯纳什均衡。根据上述W和h的值,妻子选择时装表演的概率是:
x − w x = 1 − w x = 1 − − 3 + 9 + 3 x 2 x \frac{x-w}{x}=1-\frac{w}{x}=1-\frac{-3+\sqrt{9+3 x}}{2 x} xx−w=1−xw=1−2x−3+9+3x
丈夫选择足球赛的概率是:
x − h x = 1 − h x = 1 − − 6 + 2 9 + 3 x 3 x \frac{x-h}{x}=1-\frac{h}{x}=1-\frac{-6+2 \sqrt{9+3 x}}{3 x} xx−h=1−xh=1−3x−6+29+3x
当x趋近于0时,即不完全信息接近消失或微不足道时,上述两概率分别趋向于3/4和2/3,而这也正是完全信息夫妻之争博弈的混合战略均衡的随机选择的概率。因此混合战略均衡可以看作是有极少量不完全信息的静态贝叶斯博弈的贝叶斯纳什均衡,这样就证明了海萨尼的结论是成立的。
【例题】非线性定价
假定有一个垄断厂商,以不变的边际成本 c c c生产某种产品。当厂商出售 q ≥ 0 q≥0 q≥0数量的商品给消费者时,从消费者处获取数量 T T T的货币;而消费者消费 q q q数量的商品并支付 T T T的费用时获得的效用为 u ( q , T , θ ) = θ v ( q ) − T u(q,T,\theta)= \theta v(q)-T u(q,T,θ)=θv(q)−T。这里 θ V ( q ) \theta V(q) θV(q)是消费者总剩余, V ( . ) V(.) V(.)是一个确定的关于 q q q的函数,它满足 V ( 0 ) = 0 , V ′ > 0 , V ′ ′ < 0 V(0)=0,V' > 0,V''<0 V(0)=0,V′>0,V′′<0; θ \theta θ是消费者的类型信息,它的取值可能是 θ 1 \theta_1 θ1或 θ 2 \theta_2 θ2, θ 2 > θ 1 > 0 \theta_2>\theta_1>0 θ2>θ1>0。假定总人口中 θ 1 \theta_1 θ1类型消费者的比例为 p 1 p_1 p1, θ 2 \theta_2 θ2类型消费者的比例为 p 2 p_2 p2,且 p 1 + p 2 = 1 p_1+p_2=1 p1+p2=1。证明:企业的利润最大化行为(战略最优)意味着如下条件成立:
(1) θ 2 V ′ ( q 2 ) = c \theta_2 V^{\prime}\left(q_2\right)=c θ2V′(q2)=c;
(2) θ 1 V ′ ( q 1 ) = c 1 − p 2 ( θ 2 − θ 1 ) p 1 θ 1 \theta_1 V^{\prime}\left(q_1\right)=\frac{c}{1-\frac{p_2\left(\theta_2-\theta_1\right)}{p_1 \theta_1}} θ1V′(q1)=1−p1θ1p2(θ2−θ1)c
【解】
首先理解题意: V ( q ) V(q) V(q)是一个关于购买商品数量 q q q的函数,其一阶微分大于零,二阶微分小于零,意思是随着消费者购买的商品数量逐渐递增,他认为该商品能给他带来的边际效用逐渐递减,这是一个变化率类似于对数函数的函数。
其次, V ( q ) V(q) V(q)是一个商品本身有的效用属性,但是由于消费者的类型不一样,所以给消费者带来的效用也不一样,比如辣椒本身有其固有的价值,但是对于喜欢吃辣的人带来的效用就会比给不喜欢吃辣的人带来的效用更高,这就是由消费者类型影响的。
下面让我们证明:两个参与人类型对应的商品效用:对于 θ 1 \theta_1 θ1,当其消费数量为 q 2 q_2 q2时,其边际效用等于边际成本。对于 θ 2 \theta_2 θ2,当其消费数量为 q 1 q_1 q1时,其边际效用大于边际成本,对于特别想要这个商品的,效用等于边际成本,对于不太想要这个商品的,其边际效用大于边际成本。
证明:
该博弈过程为厂商开出一个价 T ( q ) T(q) T(q),消费者要么接受要么拒绝。因此,公司将有两套方案:
( q 1 , T 1 ) (q_1,T_1) (q1,T1)卖给 θ 1 \theta_1 θ1类型的消费者, ( q 2 , T 2 ) (q_2,T_2) (q2,T2)卖给 θ 2 \theta_2 θ2类型的消费者。
公司的期望收益为: E u 0 = p 1 ( T 1 − c q 1 ) + p 2 ( T 2 − c q 2 ) Eu_0= p_1(T_1 - cq_1)+p_2(T_2 - cq_2) Eu0=p1(T1−cq1)+p2(T2−cq2)
上面这些都是卖方开出的条件,至于买方是否会接受这样的条件,还有一个参与约束,就是买方衡量这个条件是否符合自己的利益:
参与约束(IR, individual - rationality):
( I R 1 ) θ 1 V ( q 1 ) − T 1 ≥ 0 ( I R 2 ) θ 2 V ( q 2 ) − T 2 ≥ 0 (IR_1)\theta_1V(q_1)-T_1 ≥0\\(IR_2)\theta_2V(q_2)-T_2≥0 (IR1)θ1V(q1)−T1≥0(IR2)θ2V(q2)−T2≥0
还有一个问题就是,公司是针对不同人群制定的不同方案,对于 θ 1 \theta_1 θ1这类人群,制定的是 ( q 1 , T 1 ) (q_1,T_1) (q1,T1),针对 θ 2 \theta_2 θ2这类人群,制定的是
( q 2 , T 2 ) (q_2,T_2) (q2,T2)。所以需要保证 θ 1 \theta_1 θ1在 ( q 1 , T 1 ) (q_1,T_1) (q1,T1)准则下消费会得到最大的利益,而不是最后他们发现在 ( q 2 , T 2 ) (q_2,T_2) (q2,T2)准则下消费会得到更好的利益,如果这样的话就说明公司消费计划制定错误,所以就有以下激励相容:
激励相容(C, incentive - compatibility)约束:
( I C 1 ) θ 1 V ( q 1 ) − T 1 ≥ θ 1 V ( q 2 ) − T 2 ( I C 2 ) θ 2 V ( q 2 ) − T 2 ≥ θ 2 V ( q 1 ) − T 1 (IC_1) \theta_1V(q_1)-T_1≥\theta_1V(q_2)-T_2\\ (IC_2) \theta_2 V(q_2)-T_2≥\theta_2V(q_1)-T_1 (IC1)θ1V(q1)−T1≥θ1V(q2)−T2(IC2)θ2V(q2)−T2≥θ2V(q1)−T1
所以博弈论在求解的时候其实也是一个多约束条件下的优化问题,所以他也有相应的优化算法来求解这种问题。
若 I R 1 IR_1 IR1和 I C 2 IC_2 IC2满足,由 ( I R 1 ) θ 1 V ( q 1 ) − T 1 ≥ 0 → θ 1 V ( q 1 ) ≥ T 1 (IR_1)\theta_1V(q_1)-T_1 ≥0 \rightarrow \theta_1V(q_1)≥T_1 (IR1)θ1V(q1)−T1≥0→θ1V(q1)≥T1
θ 2 V ( q 2 ) − T 2 ≥ θ 2 V ( q 1 ) − T 1 ⇒ θ 2 V ( q 2 ) − T 2 ≥ θ 2 V ( q 1 ) − θ 1 V ( q 1 ) = ( θ 2 − θ 1 ) V ( q 1 ) ≥ 0 V ( q 1 ≠ 0 ) > 0 , θ 2 − θ 1 > 0 ⇒ θ 2 V ( q 2 ) − T 2 > 0 \begin{aligned} \theta_2 V\left(q_2\right)-T_2 \geq \theta_2 V\left(q_1\right)-T_1 & \Rightarrow \theta_2 V\left(q_2\right)-T_2 \geq \theta_2 V\left(q_1\right)-\theta_1 V\left(q_1\right) \\ & =\left(\theta_2-\theta_1\right) V\left(q_1\right) \geq 0 \\ V\left(q_1 \neq 0\right)>0, \theta_2-\theta_1>0 \Rightarrow & \theta_2 V\left(q_2\right)-T_2>0 \end{aligned} θ2V(q2)−T2≥θ2V(q1)−T1V(q1=0)>0,θ2−θ1>0⇒⇒θ2V(q2)−T2≥θ2V(q1)−θ1V(q1)=(θ2−θ1)V(q1)≥0θ2V(q2)−T2>0
因此,厂商战略最优时, I R 1 IR_1 IR1必成立于等号,否则对于任意小的 ε \varepsilon ε有:
( I C 1 ) θ 1 V ( q 1 ) − ( T 1 + ε ) ≥ θ 1 V ( q 2 ) − ( T 2 + ε ) \left(I C_1\right) \theta_1 V\left(q_1\right)-\left(T_1+\varepsilon\right) \geq \theta_1 V\left(q_2\right)-\left(T_2+\varepsilon\right) (IC1)θ1V(q1)−(T1+ε)≥θ1V(q2)−(T2+ε)
( I 2 ) θ 2 V ( q 2 ) − ( T 2 + ε ) ≥ θ 2 V ( q 1 ) − ( T 1 + ε ) \left(I_2\right) \quad \theta_2 V\left(q_2\right)-\left(T_2+\varepsilon\right) \geq \theta_2 V\left(q_1\right)-\left(T_1+\varepsilon\right) (I2)θ2V(q2)−(T2+ε)≥θ2V(q1)−(T1+ε)
这不符合厂商最优化策略,所以 θ 1 V ( q 1 ) = T 1 \theta_1V(q_1)=T_1 θ1V(q1)=T1
于是有:
θ 2 V ( q 2 ) − T 2 = θ 2 V ( q 1 ) − T 1 = θ 2 V ( q 1 ) − θ 1 V ( q 1 ) ⇒ T 2 = θ 2 V ( q 2 ) − θ 2 V ( q 1 ) + θ 1 V ( q 1 ) E u 0 = p 1 ( T 1 − c q 1 ) + p 2 ( T 2 − c q 2 ) E u 0 = p 1 ( θ 1 V ( q 1 ) − c q 1 ) + p 2 [ θ 2 V ( q 2 ) − θ 2 V ( q 1 ) + θ 1 V ( q 1 ) − c q 2 ) ] = [ p 1 θ 1 − p 2 ( θ 2 − θ 1 ) ] V ( q 1 ) − p 1 c q 1 + p 2 [ θ 2 V ( q 2 ) − c q 2 ] \begin{aligned} &\theta_2 V\left(q_2\right)-T_2=\theta_2 V\left(q_1\right)-T_1=\theta_2 V\left(q_1\right)-\theta_1 V\left(q_1\right) \\ & \Rightarrow T_2=\theta_2 V\left(q_2\right)-\theta_2 V\left(q_1\right)+\theta_1 V\left(q_1\right) \\ & E u_0=p_1\left(T_1-c q_1\right)+p_2\left(T_2-c q_2\right) \\ & \left.E u_0=p_1\left(\theta_1 V\left(q_1\right)-c q_1\right)+p_2\left[\theta_2 V\left(q_2\right)-\theta_2 V\left(q_1\right)+\theta_1 V\left(q_1\right)-c q_2\right)\right] \\ & =\left[p_1 \theta_1-p_2\left(\theta_2-\theta_1\right)\right] V\left(q_1\right)-p_1 c q_1+p_2\left[\theta_2 V\left(q_2\right)-c q_2\right] \end{aligned} θ2V(q2)−T2=θ2V(q1)−T1=θ2V(q1)−θ1V(q1)⇒T2=θ2V(q2)−θ2V(q1)+θ1V(q1)Eu0=p1(T1−cq1)+p2(T2−cq2)Eu0=p1(θ1V(q1)−cq1)+p2[θ2V(q2)−θ2V(q1)+θ1V(q1)−cq2)]=[p1θ1−p2(θ2−θ1)]V(q1)−p1cq1+p2[θ2V(q2)−cq2]
分别求一节条件得:
θ 2 V ′ ( q 2 ) = c \theta_2V'(q_2)=c θ2V′(q2)=c
θ 1 V ′ ( q 1 ) = c 1 − p 2 ( θ 2 − θ 1 ) p 1 θ 1 \theta_1V'(q_1)=\frac{c}{1-\frac{p_2(\theta_2-\theta_1)}{p_1\theta_1}} θ1V′(q1)=1−p1θ1p2(θ2−θ1)c