文章目录
一、Criss-Cross Network
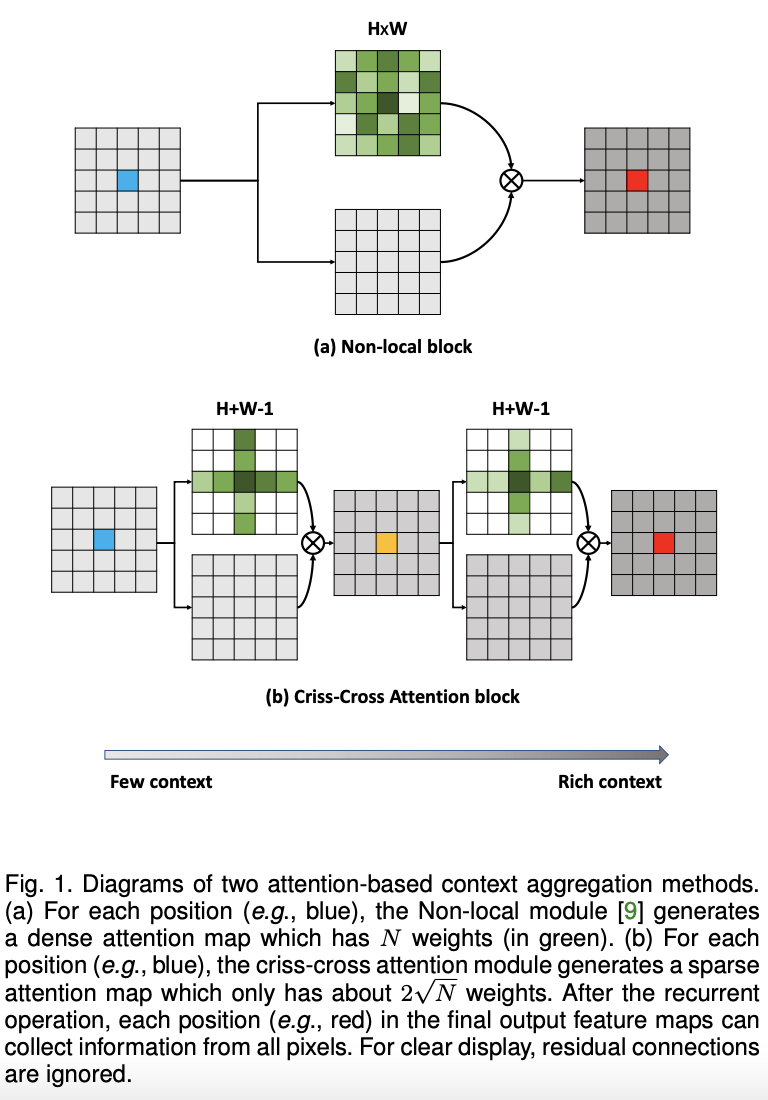
Criss-Cross Network(CCNet)旨在以有效且高效的方式获取全图像上下文信息。 具体来说,对于每个像素,一个新颖的十字交叉注意力模块会收集其十字交叉路径上所有像素的上下文信息。 通过进一步的循环操作,每个像素最终可以捕获全图像的依赖关系。 CCNet 具有以下优点: 1)GPU 内存友好。 与非局部块相比,所提出的循环交叉注意模块需要的 GPU 内存使用量减少了 11 倍。 2)计算效率高。 循环交叉注意力显着减少了非局部块约 85% 的 FLOP。 3)最先进的性能。
二、LiteSeg
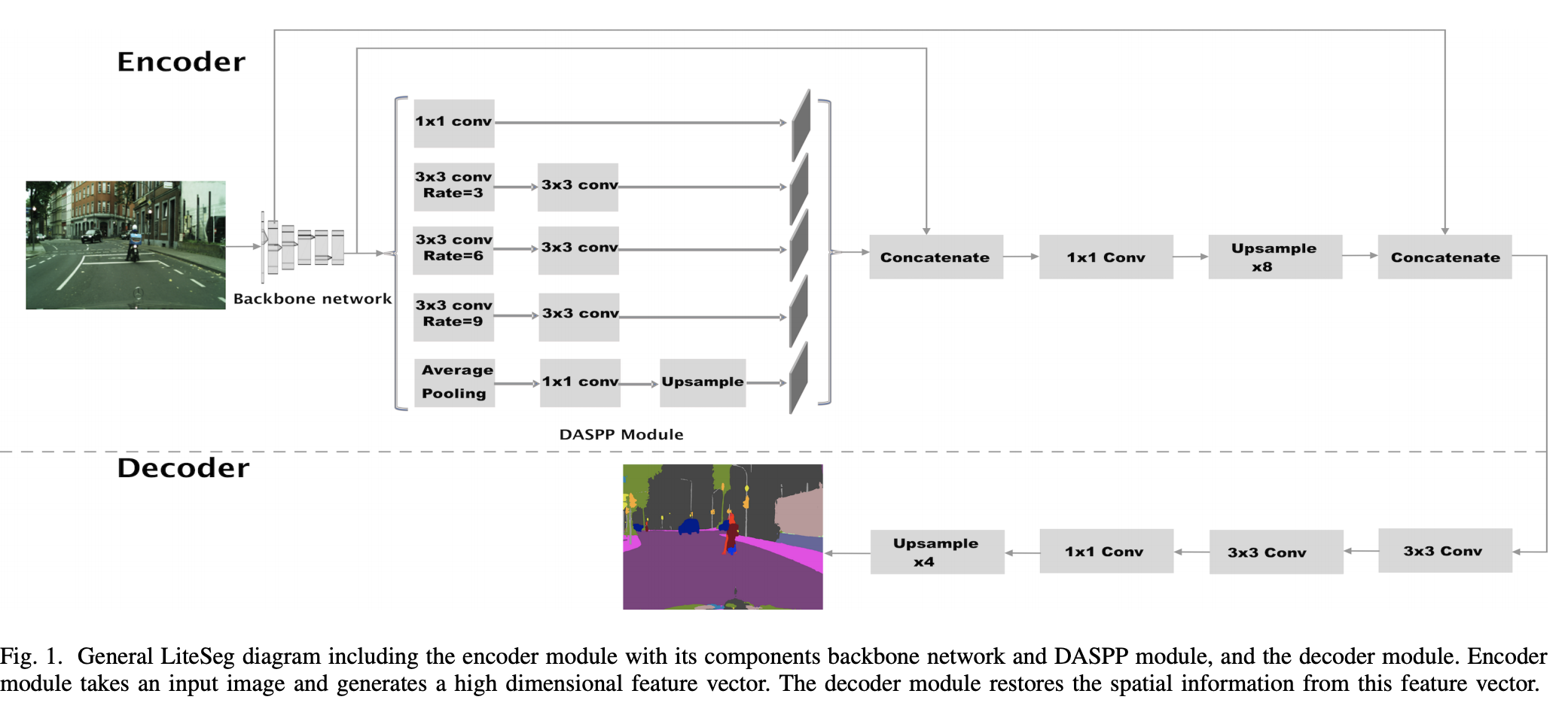
LiteSeg 是一种用于语义分割的轻量级架构,它使用更深版本的 Atrous Spatial Pyramid Pooling 模块 (ASPP),并应用短残差连接和长残差连接以及深度可分离卷积,从而产生更快、更高效的模型。
三、EdgeFlow
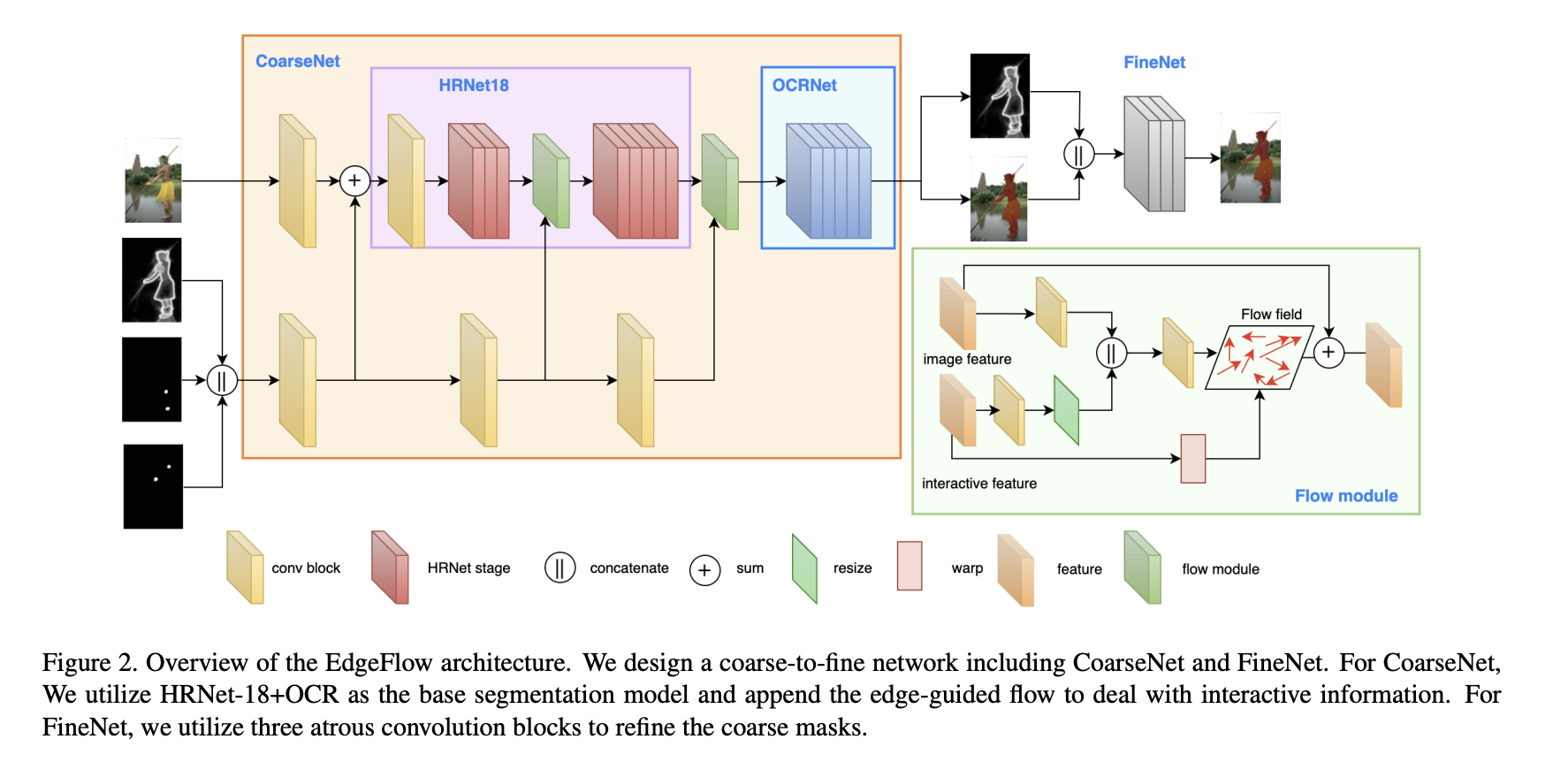
EdgeFlow是一种交互式分段架构,通过边缘引导流充分利用用户点击的交互信息。 边缘引导是交互式分割通过用户点击逐步改进分割掩模的想法。 基于用户点击,使用边缘掩模方案,该方案将先前迭代估计的对象边缘作为先验信息,而不是直接掩模估计(如果使用先前掩模作为输入,可能会导致较差的分割结果)。
该架构由粗到细的网络组成,包括 CoarseNet 和 FineNet。 对于CoarseNet,利用HRNet-18+OCR作为基础分割模型,并附加边缘引导流来处理交互信息。 对于 FineNet,利用三个有孔卷积块来细化粗略掩模。
四、BiSeNet V2
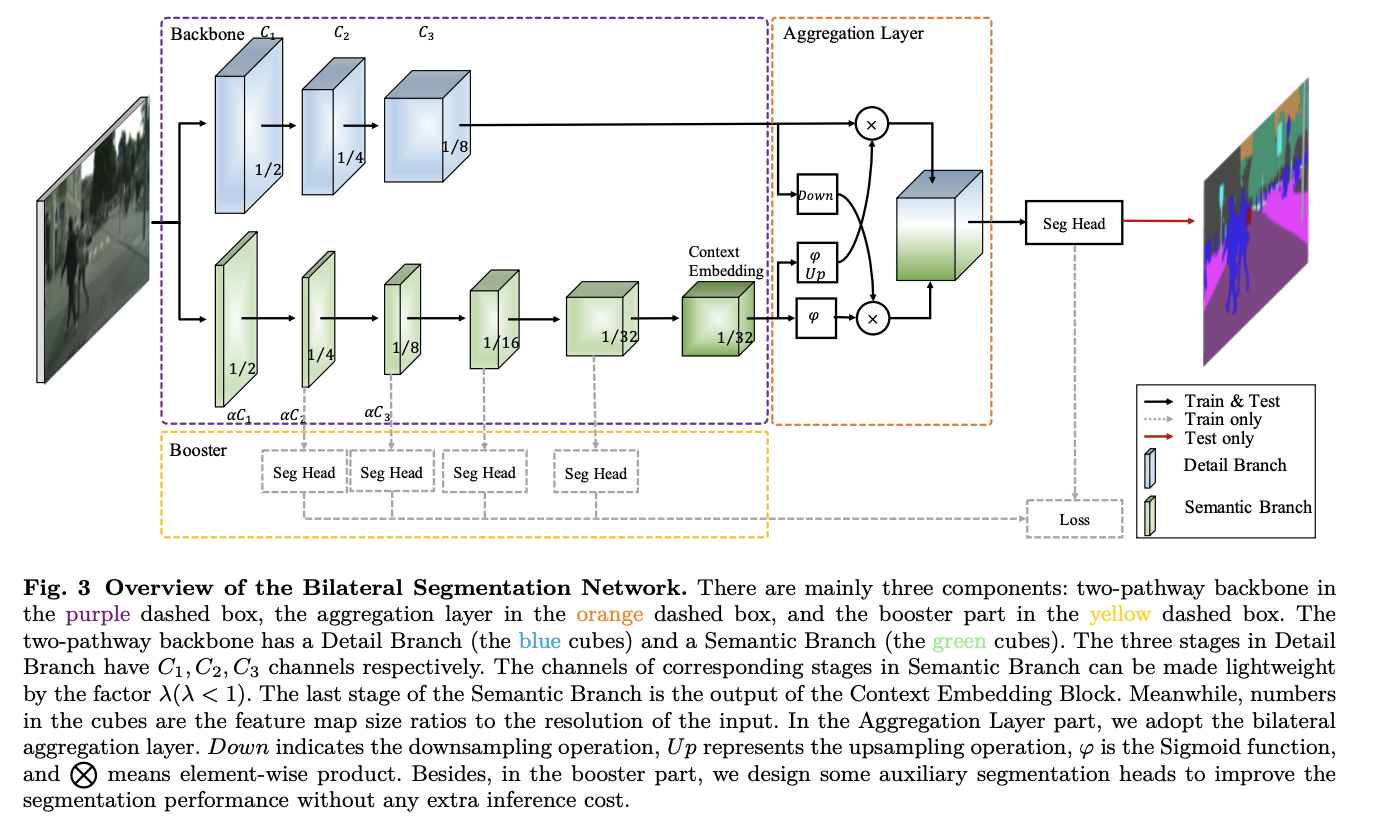
BiSeNet V2 是一种用于实时语义分割的双路径架构。 一种路径旨在捕获具有宽通道和浅层的空间细节,称为细节分支。 相比之下,引入了另一种途径来提取具有狭窄通道和深层的分类语义,称为语义分支。 语义分支只需要一个大的感受野来捕获语义上下文,而详细信息可以由细节分支提供。 因此,语义分支可以变得非常轻量级,具有更少的通道和快速下采样策略。 两种类型的特征表示被合并以构建更强、更全面的特征表示。
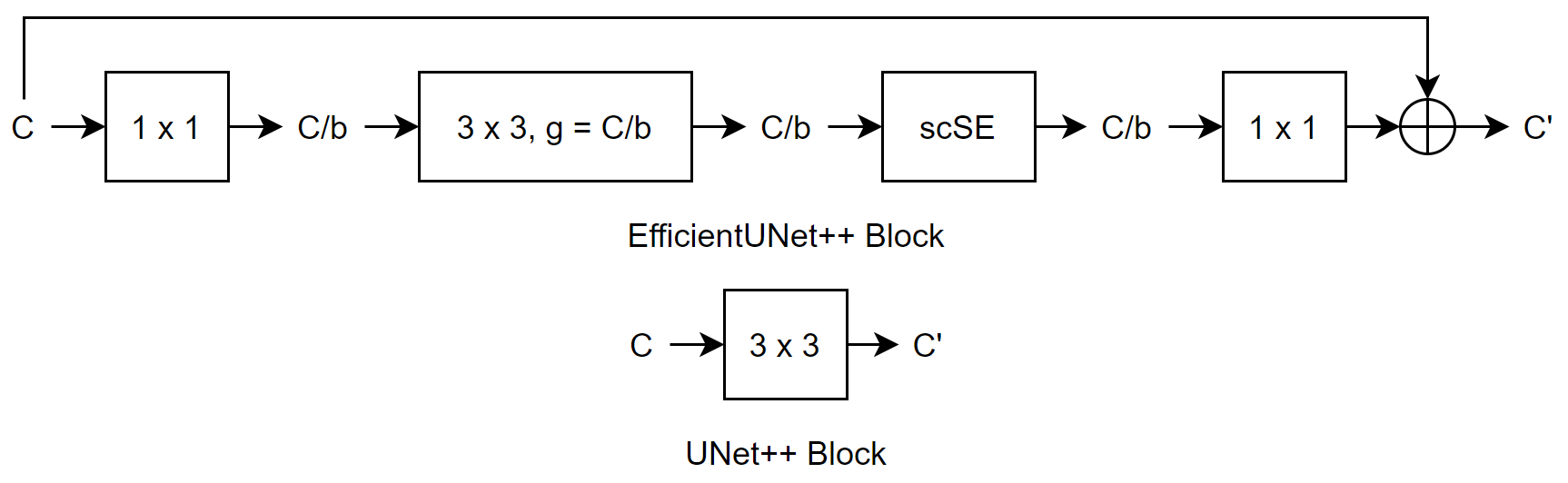
五、EfficientUNet++
解码器架构受到 UNet++ 结构和 EfficientNet 构建块的启发。 EfficientUNet++在保留UNet++结构的基础上,通过两个简单的修改实现了更高的性能并显着降低了计算复杂度:
将 UNet++ 的 3x3 卷积替换为带有深度卷积的残余瓶颈块
使用并发空间和通道挤压和激励 (scSE) 块将通道和空间注意力应用于瓶颈特征图
六、PSANet
PSANet 是一种语义分割架构,它利用逐点空间注意力(PSA)模块以灵活、自适应的方式聚合远程上下文信息。 特征图中的每个位置通过自适应预测的注意力图与所有其他位置连接,从而收获附近和远处的各种信息。 此外,作者还设计了双向信息传播路径,以全面理解复杂场景。 每个位置收集所有其他位置的信息来帮助自己的预测,反之亦然,每个位置的信息可以分布在全球范围内,辅助所有其他位置的预测。 最后,双向聚合的上下文信息与局部特征融合,形成复杂场景的最终表示。
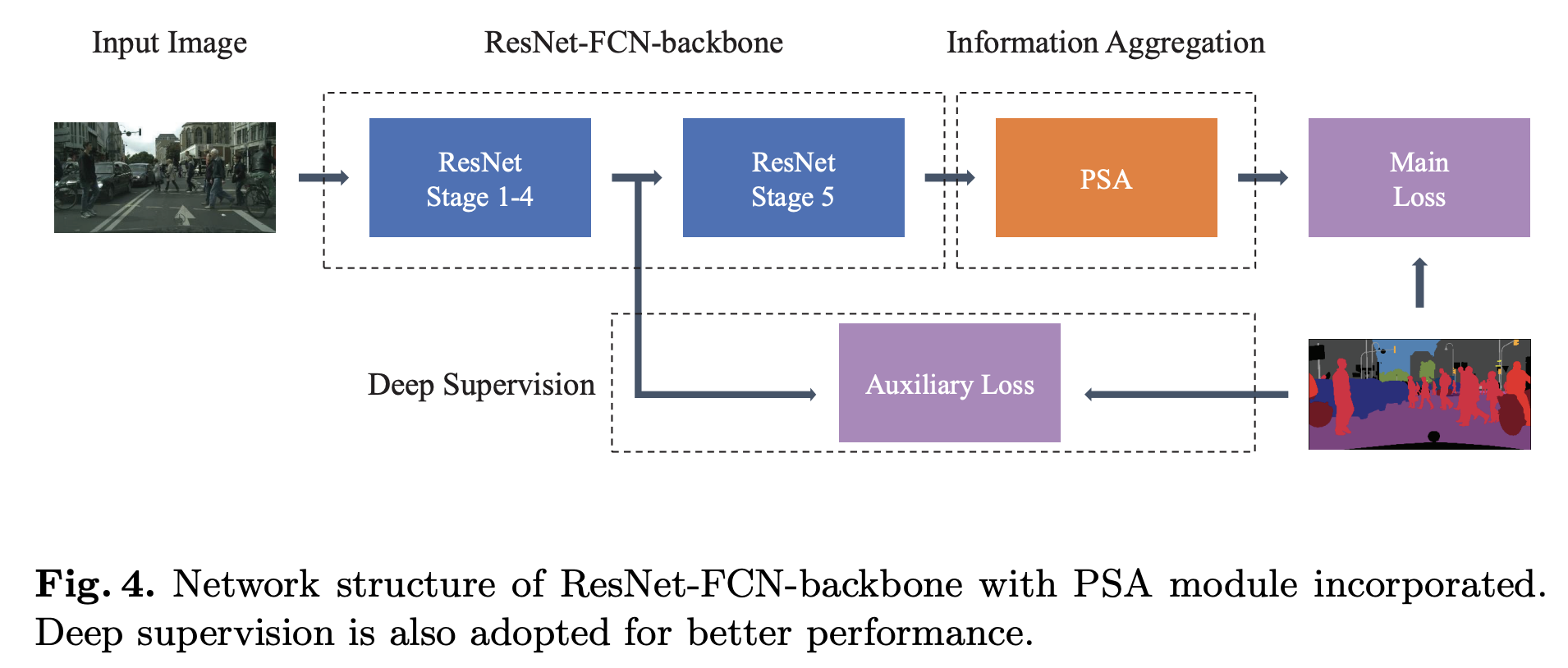
作者使用 ResNet 作为 PSANet 的 FCN 主干,如右图所示。 然后使用所提出的 PSA 模块从本地表示中聚合远程上下文信息。 它遵循 ResNet 中的第 5 阶段,这是 FCN 主干网的最后阶段。 第 5 阶段的特征在语义上更强。 将它们聚合在一起可以更全面地表示远程上下文。 此外,第5阶段特征图的空间尺寸更小,可以减少计算开销和内存消耗。 除了主损耗之外,还应用辅助损耗分支。
七、The Ikshana Hypothesis of Human Scene Understanding Mechanism
八、Adaptive Early-Learning Correction
Adaptive Early-Learning Correction for Segmentation from Noisy Annotations
九、O-Net
十、Difference of Gaussian Random Forest
十一、Context Aggregated Bi-lateral Network for Semantic Segmentation
随着自主系统的需求不断增加,用于视觉场景理解的像素语义分割不仅需要准确,而且对于潜在的实时应用程序来说也需要高效。 在本文中,我们提出了上下文聚合网络,这是一种双分支卷积神经网络,与最先进的技术相比,其计算成本显着降低,同时保持了有竞争力的预测精度。 基于现有的用于高速语义分割的双分支架构,我们设计了一个用于有效空间细节的高分辨率分支和一个具有轻量级版本的全局聚合和本地分布块的上下文分支,能够捕获远程和本地 准确的语义分割所需的上下文依赖性,且计算开销较低。 我们在两个语义分割数据集(即 Cityscapes 数据集和 UAVid 数据集)上评估我们的方法。 对于 Cityscapes 测试集,我们的模型取得了最先进的结果,mIOU 为 75.9%,在 NVIDIA RTX 2080Ti 上达到 76 FPS,在 Jetson Xavier NX 上达到 8 FPS。 对于 UAVid 数据集,我们提出的网络以高执行速度(15 FPS)实现了 63.5% 的 mIOU 分数。