目标检测——SSD
编者:杨柳依依
日期:2018年9月27日
今天给大家介绍一篇目标检测领域中经典的一篇论文,15年发表在ECCV。

1.背景知识
在介绍论文之前,我们先简单了解下本文的思路和做法。
作者提出了一种单个深度神经网络来解决图像中的目标检测的问题。这种方法,叫做SSD,将边框的输出空间在特征映射图离散化到不同比例或者不同尺度的先验边框集中。在预测阶段,网络产生每一个感兴趣的目标的置信度并且对先验框调整使其更加匹配目标形状。另外,网络利用了不同分辨率的大量的特征映射的预测来处理不同大小的目标。SSD比R-CNN和multibox相对简单之处在于它完全忽略了目标框的生成阶段,将这一步整合进了整个网络中。这种端到端的结构使得SSD方便训练并且可以整合进检测的模块中。
1.1 深度学习的目标检测的框架的对比
深度卷积网络在图像分类上取得了显著的效果。但是在目标检测这个任务中,除了目标的分类之外还包括在一张图片中定位所有的目标。基于区域的卷积网络以及更快的相关变种将检测视为一种在候选框上的分类问题,之后再加入一层对框的坐标位置修正的回归网络。
而Yolo则是在网格上使用最高特征映射直接预测了候选框和各类别的分数。Overfeat在知道目标的类别后回归出边框。但是这些方法并不能达到R-CNN的效果。难道只有RCNN的框架能成为高质量目标检测的唯一方法了吗?作者发出了这样的疑问。
那回到本篇文章的思路上来,作者提出的依然是single shot的方法,但是较之前的增加了多边框的检测器。给定一系列不同比例和尺寸的先验框,训练一个网络来挑选包含目标的先验框并且去调整先验框的坐标来更好匹配目标。这与faster-rcnn的先验框类似,但是SSD不需要像fast rcnn共享卷积层一样儿检测多个目标类别。更重要的是,SSD框架组合了网络中不同分辨率的特征映射的预测,这可以检测不同大小的目标,从而提升检测质量。
1.2 作者的贡献点
1.SSD去除了提取目标候选框的过程。这部分非常耗时并且依赖于低级的区域特征。
2.SSD整合了卷积先验框预测去多类别目标。
3.SSD先验框是不同比例和大小的。在特征映射图上稠密的提取,期望能覆盖不同大小的物体。
4.SSD将网络中不同分辨率的先验框使用起来。
5.快速高效,100-1000的提速。
2.SSD
2.1训练方法
假设我们有n个先验框,记为,每个先验框关联了一个边框以及目标类别分数的集合,
是第i个先验框的类别p的分数,
是第i个先验框的坐标,
是类别p的真实边框坐标。这些坐标都是根据图像的大小归一化的,这样不同大小的图像可以比较。
2.1.1匹配策略
训练阶段,我们需要建立先验框和真实框对应问题,先验框与真实框一致的为正例,否则为负例。
作者提出了两种可能的匹配方法。一种是完全匹配。另一种是从网络中得到最好置信度的匹配。
2.1.2训练目标
SSD的目标训练方法是从多框的目标检测方法延伸出来的,但是可处理多类别的目标。定义是第i个框与类别p的第j个真实框是一致的,反之就是=0。为了保证双向匹配,有
。如果是
,意味着可以有多个源框与真实框j匹配。整体的目标检测的损失函数是带权值的定位损失函数和分类损失函数的和。
损失函数定义如下:
定位损失函数是预测框与真实框的L2损失:

分类的损失函数可以是多类的logisitic或者softmax损失,如果是多类的Logistic 损失函数如下:

权值经过交叉验证后选择的常数是0.06。
2.2 全卷积先验框
多框方法的主要创新是使用了训练集边框的k-means聚类的中心点作为先验。在原来的方法中,分数最大的特征图用来为所有的先验框预测偏移,更好的策略是使用全卷积的先验框,比如图1中,在某个位置提出多个先验框。不光是计算高效,而且减少参数数量以及过拟合的风险。
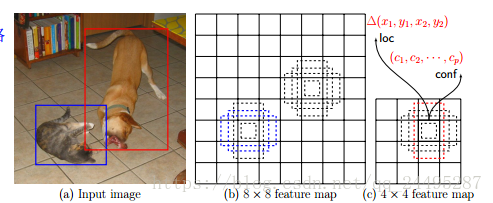
全卷积先验框跟RPN中anchor框很相似。为了进一步简化模型,把3*3的卷积核替换成1*1的卷积核来预测偏移和分类分数,而且并不需要中间层。更重要的是,RPN仍然是学习目标和产生提案,这在fast-rcnn是综合完成的。然而,SSD可以在他们中共享的目标框中检测多个类别。特别地,比如我们有m*m的特征映射图,特征图上每个位置k个先验框,一共c个类别。对于k个先验框,我们将有4k个偏移输出,对于c个类别,我们将有ck个分数输出。也就是(4+c)*k个输出。考虑特征图上每个位置的预测的总和,一共是有(4+c)*km2,但是只有(4+c)*k个参数需要学习。如果不共享,参数数量将是5ck,输出有5ckm2。
2.3 多个特征图综合预测输出
大多数的卷积网络在更深的层中减少特征图的数量,不仅仅是因为可以减少计算和内存空间,而且也是提供了一定程度的翻转和尺寸大小不变性。
为了处理不同的目标大小,一些方法提出将图像转变成不同的尺度,每个尺度单独处理,并将结果最后组合。但是,在一个单独网络中从一些不同的层的特征映射的输出上,我们也可以模拟这种效果。有些论文中研究指出从低层中使用特征映射可以提高语义分割的质量因为低层捕捉了输入目标的细节信息。类似的,有篇文章指出从最高的特征映射图中加上全局池化有助于平滑分割结果。受这些方法的启发,作者使用了低层和高层的特征映射来检测预测。图1中就有两个例子,一个是8*8,另一个是4*4。同时也多了不可忽略的计算量。
在网络中的不同级别的映射中对应着不同的感受野。幸运的是,在SSD的框架里,卷积框并不需要与每一层的感受野一致。假设想要使用m的特征映射。简单点说,定义fk其中,k按照降序排列。每个特征映射的先验框的尺寸因子如下:
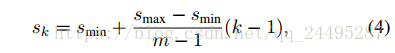
是0.1,
是0.7,
是1,意味着最低层是0.1,最高层是0.7,其他层在之间均匀分布。我们利用不同的比例,定义如下,
,计算宽和高的公式为:
和
,对于比例为1的,增加尺度为
。因此每个位置有6个先验框。定义先验框的中心为
,先验框的坐标控制在[0,1]。
2.4 难的负例挖掘
在匹配之后,大部分的框都是负例的,尤其是先验框的数量是大量的时候。这带来正负例的不均衡问题。不适用所有的负例,我们排序后,选取分数高的为训练数据,比例为3:1。这样可以优化以及加速训练过程。
2.5 图像处理
为了使得模型对不同的输入尺寸和形状鲁邦性高,每个训练图像通过以下方法随机采样:
1.使用原图
2.采样区域使得与目标重合最小jaccard overlap是0.1,0.3,0.5,0.7
3.采样区域使得与目标重合最大jaccard overlap时0.5
只有每张图都水平翻转0.5,另外增加光学的畸变。
3.实验结果
作者采用了ILSVRC DET和PASCAL VOC两个数据集,在Inception的一个早期变种上做的实验,使用微调,加了bn和adagrad学习率为0.4.
3.1ILSVRC 2014 DET结果
3.1.1 两个阶段的基准检测器
multibox 图像输入是299*299,提案重新尺寸到299*299,在测试集上,单模型map是38.0,6个集成模型的map是43.9.在val2上最新的单模型的map是44.7.提高的原因是后分类的Inception的网络结构的提高。网络输入从224增加到299。
3.1.2 SSDvs基准检测器
SSDperson比baseline高。

3.1.3 特征映射多效果好
3.1.4 输入尺寸大效果好
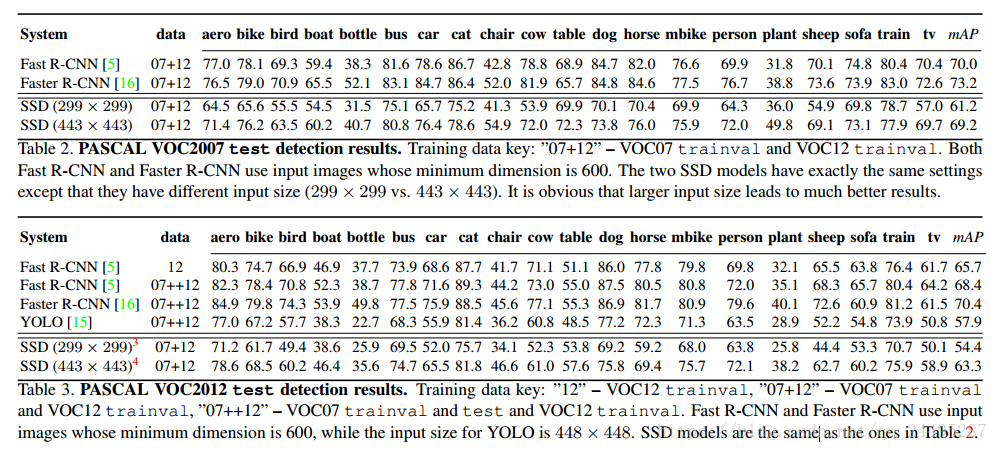
3.2 VOC 2007结果
容易训练,fast 和faster r-cnn都比SSD效果好。可能是输入图像尺寸大。但是SSD比yolo效果好。
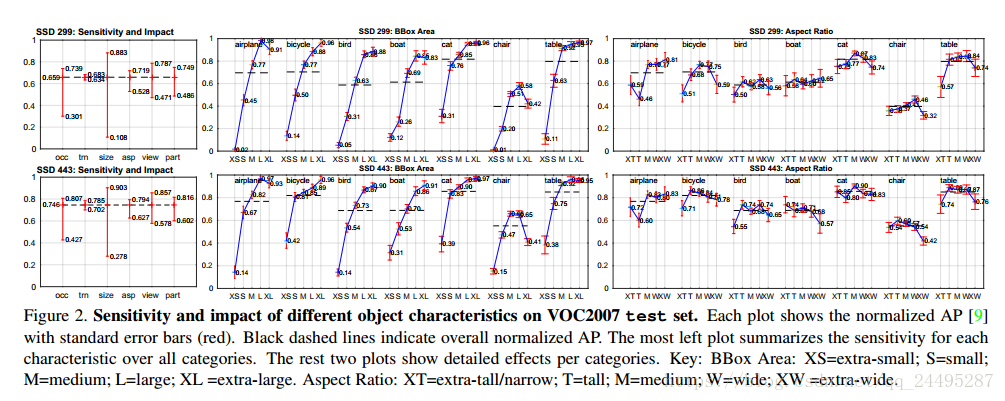
对边界框大小敏感。小的边框识别效果不好。在xs目标上ap几乎为0,这也许不意外因为在8*8上可能没有任何信息。
增加图像输入尺寸可以提高极小目标的检测,但是仍有提升的空间。