1 - 引言
目标检测和识别,是计算机视觉最常见的挑战之一。
目标检测和识别的区别在于:目标检测是用来确定图像的某个区域是否含有要识别的对象,而识别是程序识别对象的能力。识别通常只处理已检测到对象的区域。
在计算机视觉中有很多目标检测和识别的技术
- 梯度直方图(Histogram of Oriented Gradient, HOG)
- 图像金字塔(image pyramid)
- 滑动窗口(sliding window)
与特征检测算法不同,这些算法是互补的,比如在HOG中也会使用滑动窗口技术,下面我们来介绍一下这些技术
2 - 目标检测与识别技术
2.1 - 基本概念与术语介绍
要实现目标检测和识别,我们先要了解这方面的一些技术手段和术语
- 梯度直方图(Histogram of Oriented Gradient, HOG)
HOG是一个特征描述符,因此HOG与SIFT、SURF、ORB属于同一类型的描述符
HOG不是基于颜色值而是基于梯度来计算直方图的。但是这种特征会受到两个方面的影响
- 尺度问题
- 位置问题
为了解决这些问题,需要使用图像金字塔和滑动窗口
- 图像金字塔
图像金字塔是图像的多尺度表示。
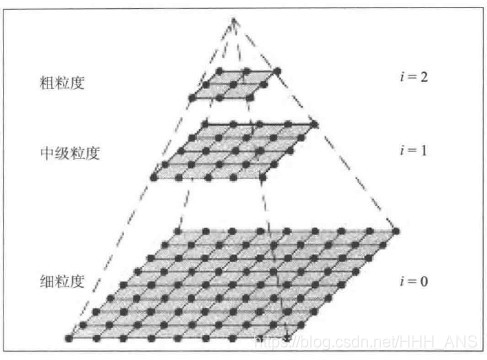
-
滑动窗口
通过一个滑动窗口扫描较大图像的较小区域来解决定位问题,进而在同一图像的不同尺度下重复扫描。
但是滑动窗口会遇到一个问题,区域重叠,比如在对人脸检测的时候可能对同一张人脸的四个不同位置进行匹配,但是我们只需要一个结果,所以我们需要使用非最大抑制来确定一个评价最高的图片区域。 -
扫描二维码关注公众号,回复: 4897683 查看本文章

SVM的最优超平面是目标检测的重要组成部分,用来区分哪些像素是目标,哪些像素不是目标
再了解一些基本概念后,我们可以试着搭建一些简单的检测程序
2.2 - 检测人示例
OpenCV自带的HOGDescriptor函数可检测人
import cv2
import numpy as np
def is_inside(o,i):
ox,oy,ow,oh = o
ix,iy,iw,ih = i
return ox > ix and oy > iy and ox + ow < ix + iw and oy + oh < iy +ih
def draw_person(image, person):
x,y,w,h = person
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,255,2))
img = cv2.imread('images/timg (2).jpg')
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
found, w = hog.detectMultiScale(img)
found_filtered = []
for ri, r in enumerate(found):
for qi, q in enumerate(found):
if ri != qi and is_inside(r,q):
break
else:
found_filtered.append(r)
for person in found_filtered:
draw_person(img,person)
cv2.imshow("people detection",img)
cv2.waitKey(0)

3 - 创建和训练目标检测器
虽然使用OpenCV内置的函数可以很容易得到应用的简易模型,但是仅仅使用内置的函数是远远不够的,我们需要改进这些特征,搞明白这些检测器能否应用与其他目标。
我们可以使用词袋(Bag-of-Word,BOW)技术
3.1 - 词袋
词袋(BOW)最早并不是针对计算机视觉的,而是用于语言分析和信息检索领域,BOW用来在一系列文档中计算每个词出现的次数,用这些次数构成向量来重新表示文档。
而在计算机视觉中,BOW方法的实现步骤如下:
- 取一个样本数据集
- 对数据集中的每幅图像提取描述符(采用SIFT,SURT等方法)
- 将每一个描述符都添加到BOW训练器中
- 使用K-means聚类将描述符聚类到K簇中
3.2 - 汽车检测
- 先下载数据集
- 实现代码:
import cv2
import numpy as np
from os.path import join
# 获取不同类别图像的路径
def path(cls, i):
return "%s/%s%d.pgm" % (datapath, cls, i + 1)
# 以灰度格式读取图像,并从图像中提取SIFT特征,然后返回描述符
def extract_sift(fn):
im = cv2.imread(fn, 0)
return extract.compute(im, detect.detect(im))[1]
# 声明训练图像的基础路径,最新下载地址:
# http://cogcomp.org/Data/Car/CarData.tar.gz
datapath = "./data/at/CarData/TrainImages/"
# 查看下载的数据素材,发现汽车数据集中图像按:pos-x.pgm 和 neg-x.pgm 命名,其中x是一个数字。
# 这样从path读取图像时,只需传递变量i的值即可
pos, neg = "pos-", "neg-"
# 创建两个SIFT实例,一个提取关键点,一个提取特征;
detect = cv2.xfeatures2d.SIFT_create()
extract = cv2.xfeatures2d.SIFT_create()
# 创建基于FLANN匹配器实例
flann_params = dict(algorithm=1, trees=5)
flann = cv2.FlannBasedMatcher(flann_params, {})
# 创建BOW训练器,指定簇数为40
bow_kmeans_trainer = cv2.BOWKMeansTrainer(40)
# 初始化BOW提取器,视觉词汇将作为BOW类输入,在测试图像中会检测这些视觉词汇
extract_bow = cv2.BOWImgDescriptorExtractor(extract, flann)
# 从每个类别中读取8个正样本和8个负样本,并增加到训练集的描述符
for i in range(8):
bow_kmeans_trainer.add(extract_sift(path(pos, i)))
bow_kmeans_trainer.add(extract_sift(path(neg, i)))
# cluster()函数执行k-means分类并返回词汇
# 并为BOWImgDescriptorExtractor指定返回的词汇,以便能从测试图像中提取描述符
voc = bow_kmeans_trainer.cluster()
extract_bow.setVocabulary(voc)
# 返回基于BOW描述符提取器计算得到的描述符
def bow_features(fn):
im = cv2.imread(fn, 0)
return extract_bow.compute(im, detect.detect(im))
# 创建两个数组,分别存放训练数据和标签
# 调用BOWImgDescriptorExtractor产生的描述符填充两个数组,生成正负样本图像的标签
traindata, trainlabels = [], []
for i in range(20):
traindata.extend(bow_features(path(pos, i)))
trainlabels.append(1) # 1表示正匹配
traindata.extend(bow_features(path(neg, i)))
trainlabels.append(-1) # -1表示负匹配
# 创建一个svm实例
svm = cv2.ml.SVM_create()
# 通过将训练数据和标签放到NumPy数组中来进行训练
svm.train(np.array(traindata), cv2.ml.ROW_SAMPLE, np.array(trainlabels))
'''
以上设置都是用于训练好的SVM,剩下要做的是给SVM一些样本图像
'''
# 显示predict方法结果,并返回结果信息
def predict(fn):
f = bow_features(fn)
p = svm.predict(f)
print(fn, "\t", p[1][0][0])
return p
# 定义两个样本图像的路径,并读取样本图像信息
car, notcar = "./images/car.jpg", "./images/bb.jpg"
car_img = cv2.imread(car)
notcar_img = cv2.imread(notcar)
# 将图像传给已经训练好的SVM,并获取检测结果
car_predict = predict(car)
not_car_predict = predict(notcar)
# 以下用于屏幕上显示识别的结果和图像
font = cv2.FONT_HERSHEY_SIMPLEX
if (car_predict[1][0][0] == 1.0):
cv2.putText(car_img, 'Car Detected', (10, 30), font, 1, (0, 255, 0), 2, cv2.LINE_AA)
if (not_car_predict[1][0][0] == -1.0):
cv2.putText(notcar_img, 'Car Not Detected', (10, 30), font, 1, (0, 0, 255), 2, cv2.LINE_AA)
cv2.imshow('BOW + SVM Success', car_img)
cv2.imshow('BOW + SVM Failure', notcar_img)
cv2.waitKey(0)
cv2.destroyAllWindows()

现在我们完成了汽车的目标检测,但是我们希望可以增加以下功能:
- 检测图像中同一物体的多个目标
- 确定检测到的目标在图像中的位置
3.3 - 多目标汽车和位置检测
步骤如下:
- 获取一个训练集数据
- 创建BOW训练器并获得视觉词汇
- 采用词汇训练SVM
- 尝试对测试图像的金字塔采用滑动窗口进行检测
- 对重叠的矩形使用非最大抑制
- 输出结果
该项目的结构如下:

下面给出例程:
首先下载项目文件
实际应用中,只需修改car_sliding_windows.py文件即可,附内容:
import cv2
import numpy as np
from car_detector.detector import car_detector, bow_features
from car_detector.pyramid import pyramid
from car_detector.non_maximum import non_max_suppression_fast as nms
from car_detector.sliding_window import sliding_window
def in_range(number, test, thresh=0.2):
return abs(number - test) < thresh
test_image = "./images/car3.jpg"
svm, extractor = car_detector()
detect = cv2.xfeatures2d.SIFT_create()
w, h = 150, 80
img = cv2.imread(test_image)
rectangles = []
scaleFactor = 1.25
for resized in pyramid(img, scaleFactor):
scale = float(img.shape[1]) / float(resized.shape[1])
for (x, y, roi) in sliding_window(resized, 20, (w, h)):
if roi.shape[1] != w or roi.shape[0] != h:
continue
try:
bf = bow_features(roi, extractor, detect)
_, result = svm.predict(bf)
a, res = svm.predict(bf, flags=cv2.ml.STAT_MODEL_RAW_OUTPUT | cv2.ml.STAT_MODEL_UPDATE_MODEL)
# 所有小于-1.0的窗口被视为一个好的结果
if result[0][0] == 1 and res[0][0] < -1.0:
print("Class: %d, Score: %f, a: %s" % (result[0][0], res[0][0], res))
# 提取感兴趣区域(ROI)的特征,它与滑动窗口相对应
rx, ry, rx2, ry2 = int(x * scale), int(y * scale), int((x + w) * scale), int((y + h) * scale)
rectangles.append([rx, ry, rx2, ry2, abs(res[0][0])])
except:
pass
# 将矩形数组转换为NumPy数组
windows = np.array(rectangles)
# 非最大抑制nms,按打分最高到最低排序
boxes = nms(windows, 0.25)
# 打印检测结果
for (x, y, x2, y2, score) in boxes:
print(x, y, x2, y2, score)
cv2.rectangle(img, (int(x), int(y)), (int(x2), int(y2)), (0, 255, 0), 1)
cv2.putText(img, "%f" % score, (int(x), int(y)), cv2.FONT_HERSHEY_PLAIN, 1, (0, 255, 0))
cv2.imshow("img", img)
cv2.waitKey(0)
cv2.destroyAllWindows()

对于支持向量机(SVM)来说,不需要每次都训练检测器,可以保存训练结果到文件,以后需要用到时,使用load函数直接加载即可。
svm.save('/svmxml')
感觉OpenCV提供的例程效果不是很好,要想在实际中完成比较好的效果还是需要耐心的修改优化程序
4 - 总结
我们介绍了许多的概念,HOG、BOW、SVM、金字塔、滑动窗口和非最大抑制,内容还是很多的,需要一点时间来吸收