kd-tree:在高维数据时很难处理,而且搜索难度高。
1、LSH是一种找到近似邻居的方法。
比如以下这种情况,找不到真正的最近邻。因为我们只在要寻找的点所在的bin中找最近邻。
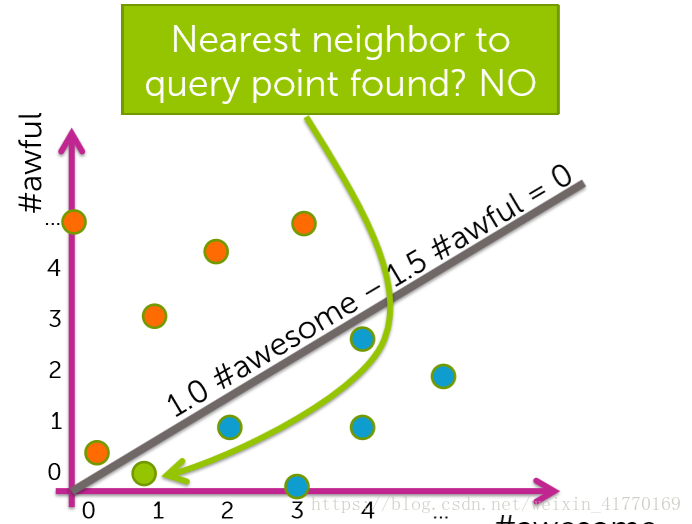
2、3个挑战:
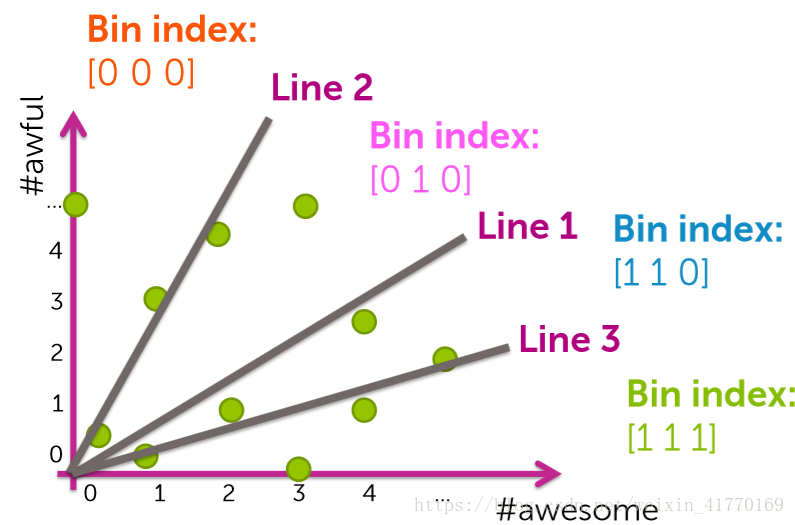
(1)分割线很难找
(2)质量函数很差时,很难解决:2个点离的很近,但被分到了2个bin中,很难解决
(3)计算量有时候很大:有时候1个bin中分的数据太多
3、提高效率:减少每次查询的点数
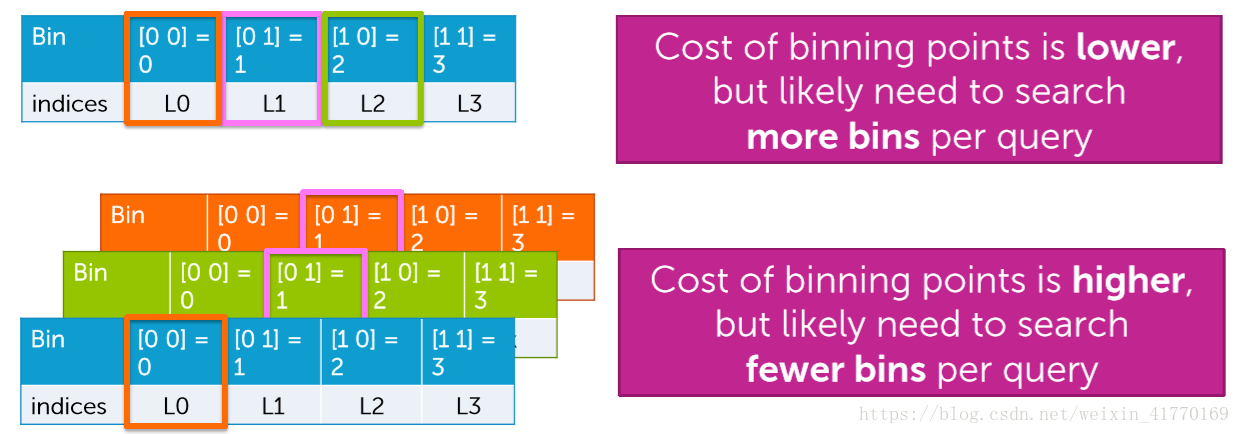
(1)通过增加bin数,减少搜索消耗
(2)通过搜索临近的bin,来减少搜索消耗

(3)以上只是一个表table,分多个bin。可以继续提高效率,多个table,每个table再多个bin。
4、测试
搜索到的跟待查询的数据点不相似,除了搜索更多的表和bin,还有就是扩大当前搜索的bin,也就是对应减少lines。
所以说,增加lines是不对的。
