背景:如果想要局部平滑,而且数据量很大,我们可以有如下方法。
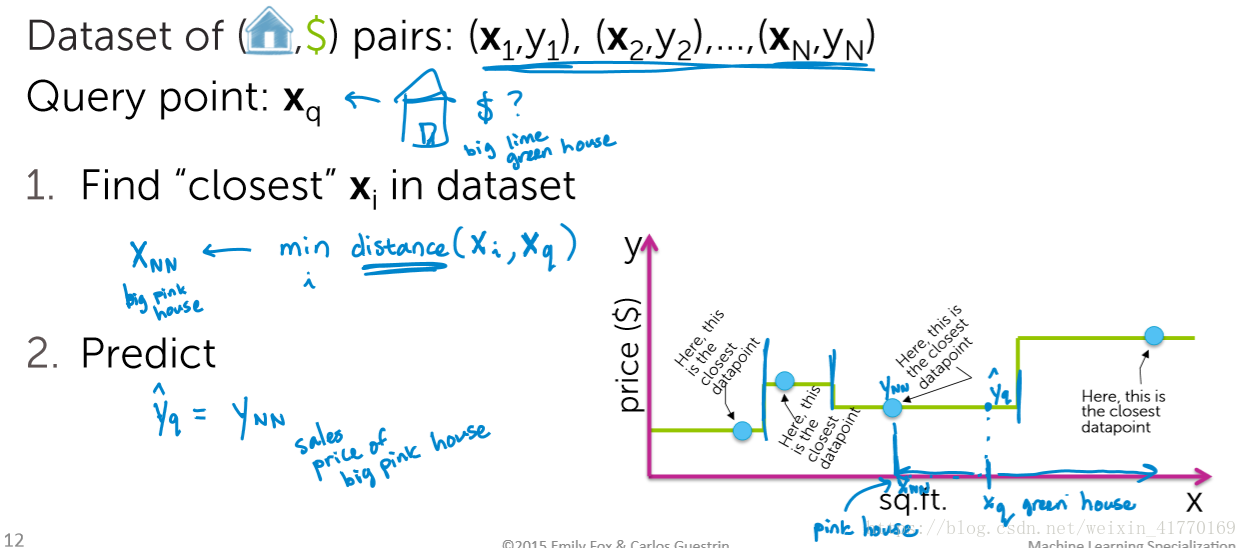
一、最简单方法:最近邻回归
1、1找1近邻的步骤
比如:卖房子的时候,房产中介会找一个最像的房子来定价我们的房子
2、距离
对于一些重要的特征,我们可以加大权重(下面是欧氏距离):

其他距离种类:曼哈顿距离、汉明距离等。
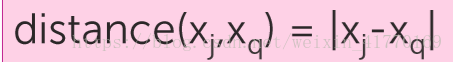
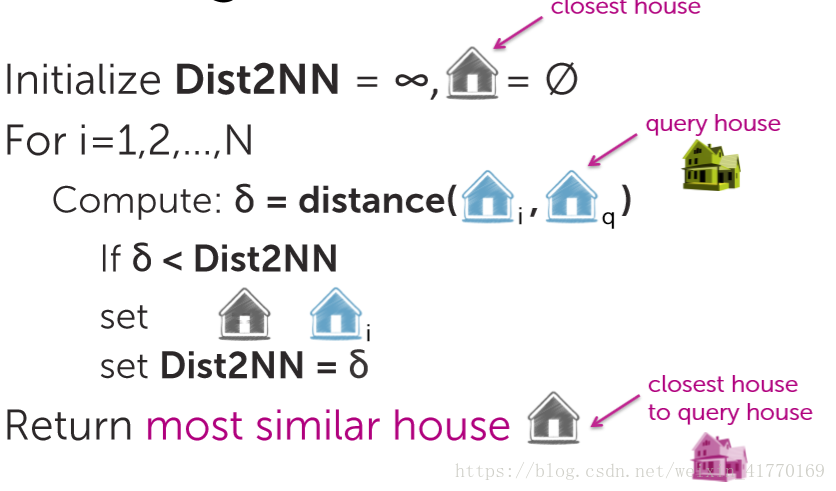
3、1NN:1近邻
初始化最小距离,最近邻为空,查询房屋为q
对所有的房屋进行遍历:
求所有房屋与房屋q的距离
如果距离<最小距离,则更新最小距离以及最相似房屋索引;否则最小距离保持不变,且最相似房屋索引不变;
全部遍历结束后,返回最相似房屋i。
缺点:
(1)对大块区域没有数据或很少数据时敏感,拟合的不好
(2)对噪声敏感
4、kNN:k近邻


优点:对噪声鲁棒
缺点:不连续,比如当待售房子是100平,跟它最相似的3个房子分别为101平,140平和180平。原则上,应该主要参考101平的房子,但是这种情况下没有这种倾向。
5、加权KNN
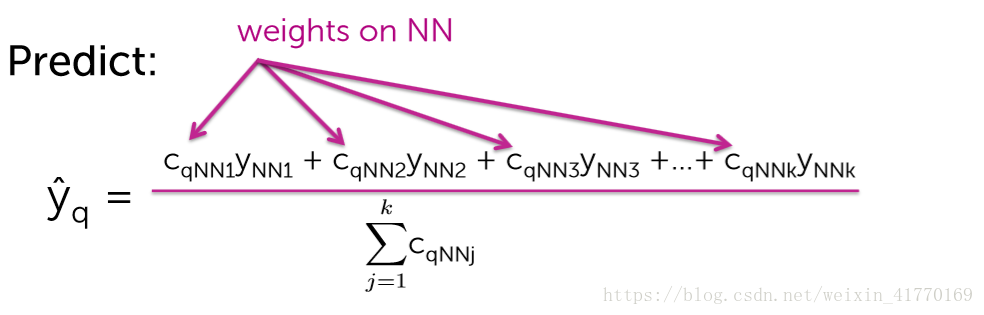
离得更近的具有更大的权重,离得远的具有更小的权重。权重最简单的计算方法为距离的倒数,如下:

继续升级权重,提出核权重的概念。其实就是把权重的公式概念化。
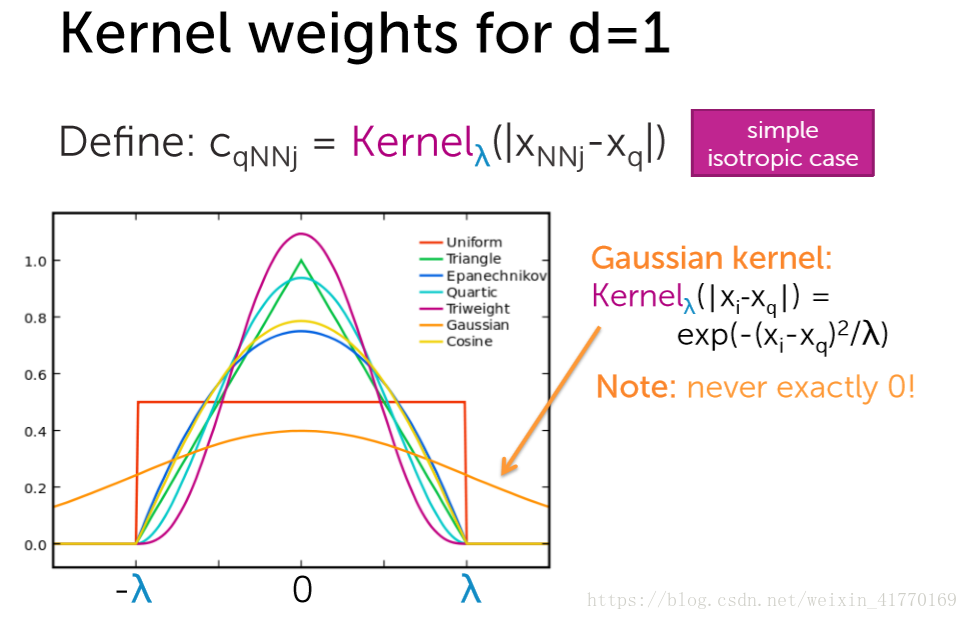
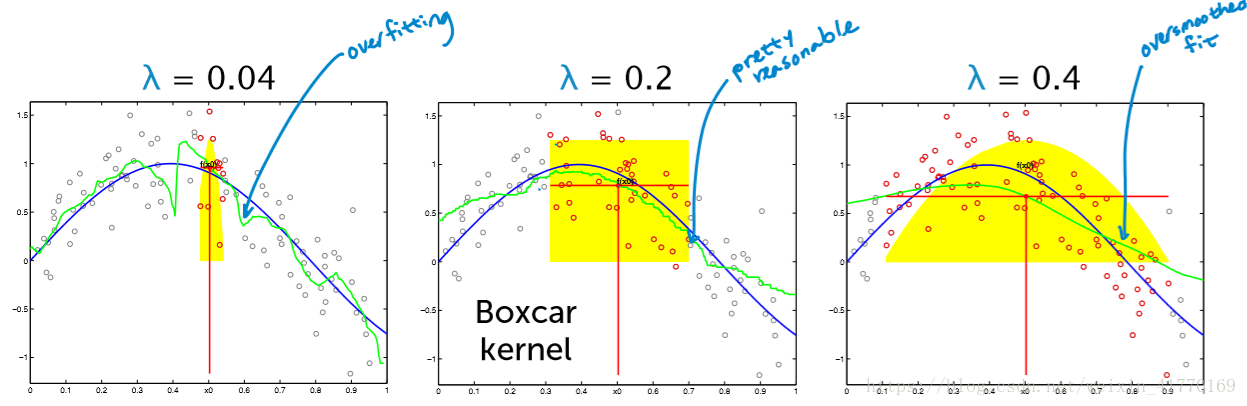
二、核回归
核回归其实就是升级版的加权KNN,区别就在于,核回归不是加权的N个邻居,而是所有的点。
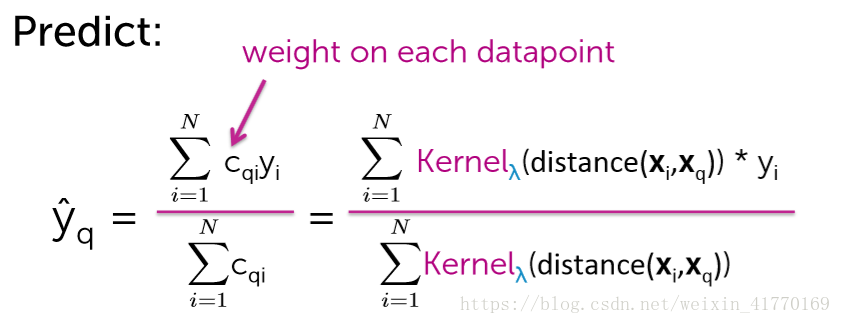
要确定两个:(1)核,(2)lambda。其中,核的选择比lambda的选择更重要。
lambda的选择:根据验证集验证时的验证损失来确定。
三、计算复杂度
1NN的计算复杂度:O(N)
KNN的计算复杂度:O(N*logk)
如果N很大,则计算复杂度将非常高,因此,我们以后将引入聚类。
将KNN用来分类:比如邮件分类,使用KNN进行权重投票。
四、测试
- 核回归的lambda选择