1、简介
k-means一种非监督学习模型
输入:文档向量
输出:聚类标签
cluster定义:中心,形状
k-means是计算到center中心的距离,是忽略形状的。
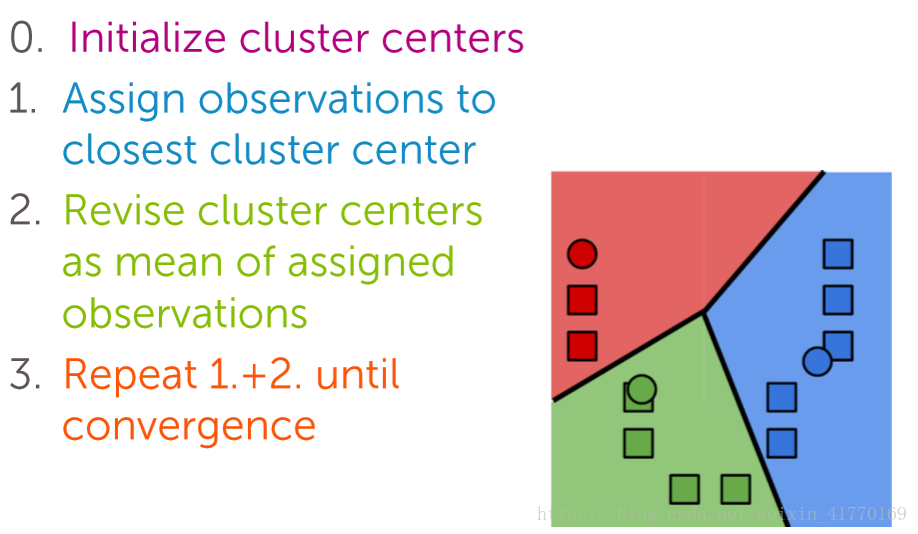
2、k-means算法步骤
扫描二维码关注公众号,回复:
1655709 查看本文章

3、k-means是一种坐标下降算法:

4、k-means收敛:局部最优
5、k-means++
跟k-means的区别在于:一开始聚类中心的初始化不一样,其他均一样


越远,越有可能成为新的聚类中心。
k-means++一开始初始化浪费时间较多,但后面收敛很快。
6、k-means中k的选择
k越大,越容易过拟合
k的选择见下图:

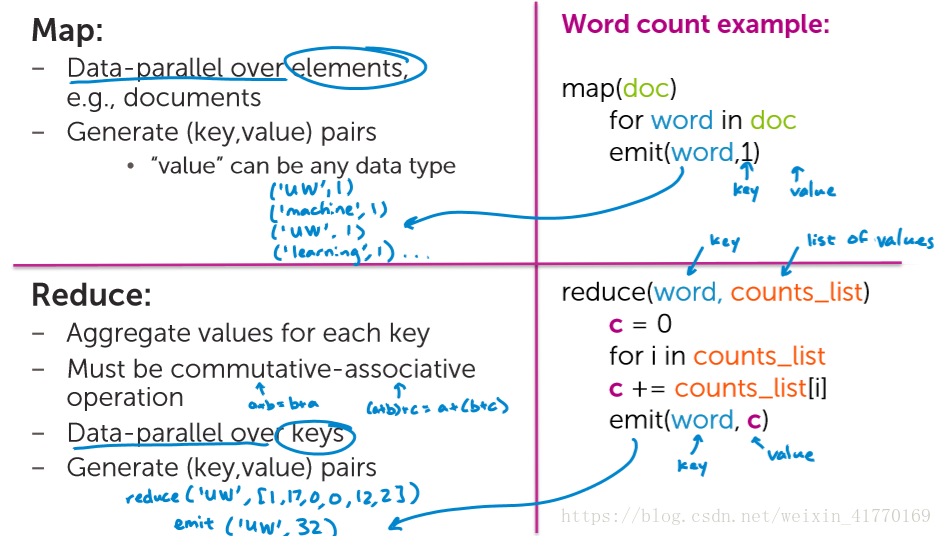
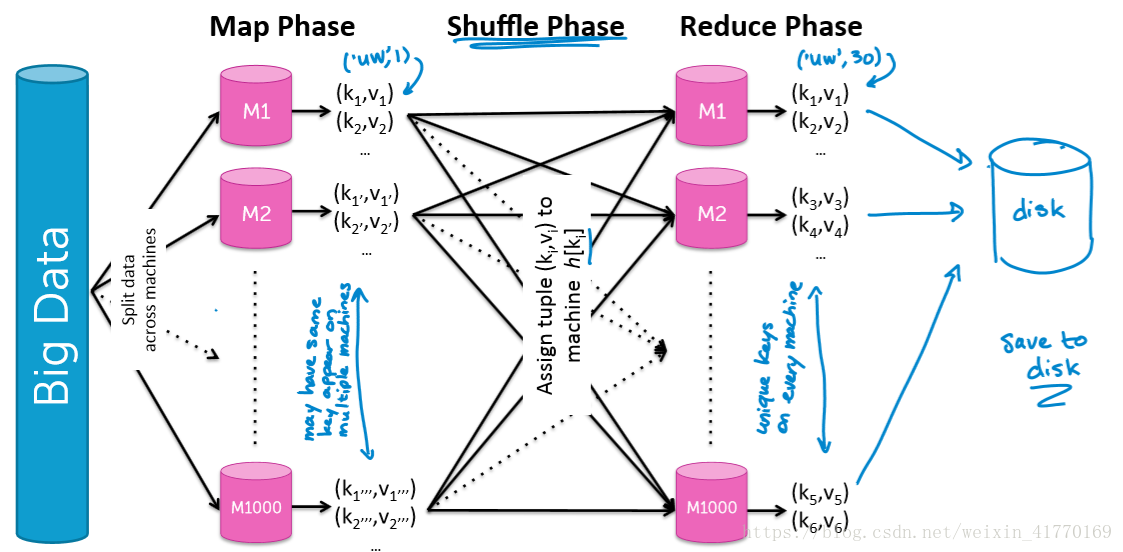
7、MapReduce映射和规约
每个机器先独立处理一部分文档
每个机器独立统计不同的words,其他机器将本机器要处理的发送过来。(Hash实现)

8、MapReduce实现k-means


9、测试
第4题答案是false,想不通,我觉得4是对的。

我选了1,2,5还有2,5都是错的。
