根据“检索感兴趣的文档”引出聚类和相似度的学习。
一、检索文档和测量文档相似度的算法
1、2个问题
(1)如何衡量2个文章的相似度;
(2)如何找出另一篇文章。
2、相似度测量
(1)词袋模型
不考虑词的顺序,只统计每个词出现的次数。

(2)单词统计的相似度测量
单词次数统计,然后进行点乘,作为相似度测量的结果。

但上述直接点乘容易造成:较长的文章,相似度越高,因此,需要先进行归一化,再点乘。
3、用tf-idf提高重要词的优先级
(1)稀有词
比如梅西等,在单个文档、整个文档库出现的概率都很低,但很重要
(2)关键词
比如soccer, football等,在部分文档出现概率高,但整个文档库出现概率低,对主题的反映也很重要。
特性为“局部常用,全局罕见”。
(3)tf-idf
用来描述特性“局部常用,全局罕见”的方法为tf-idf:term frequency - inverse document frequency词频-逆向文件频率法。

解释下逆序文档频率:分子是所有文档数,分母是1+用到该单词的文档数。
当word i经常使用,也就是docs using word很大时,逆序文档频率为0;
当word i很少使用,也就是docs using word很小时,逆序文档频率很大。
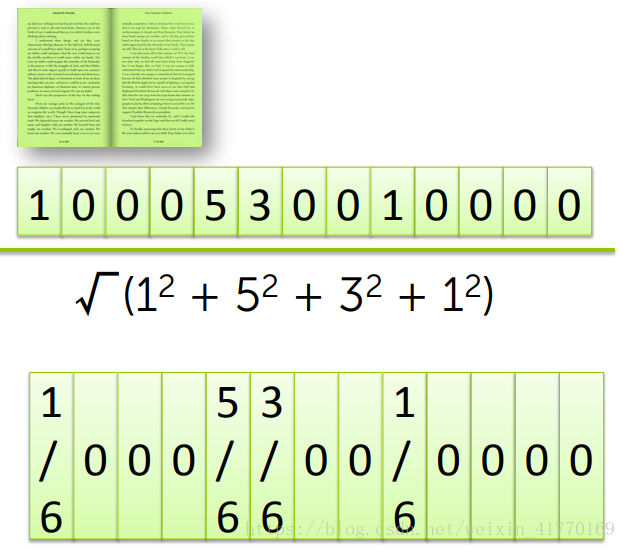
(4)tf-idf举例
计算出term frequency,再计算inver document frequency,最后将2个点乘。

4、用最近邻域算法来寻找文章
(1)最近邻(1个)

(2)k近邻

二、聚类模型与算法
1、聚类有2个步骤
(1)先将数据分成多个有集群中心的集群cluster

(2)当新的点来时,计算它到集群外围或者集群中心的距离即可分类。

2、k-means算法
k均值:(1)k类;(2)相似度测量:到集群中心的距离;(3)集群中心的更新:均值

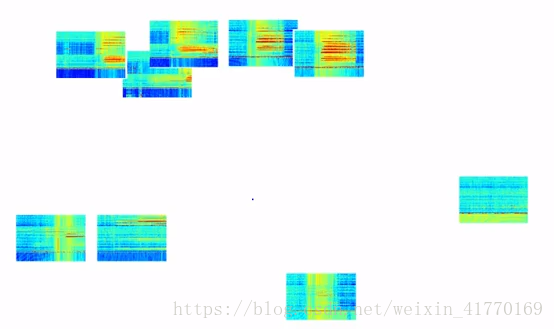
3、聚类的其他应用
(1)图像聚类

(2)疾病分类:对症下药
(3)电商产品推荐

(4)社区聚类
如果当前社区没有房价交易记录,则可以寻找相似社区,再用相似社区的房价来预测
社区聚类来监控犯罪,一旦发现其他社区也有类似的犯罪迹象,则优化警力。
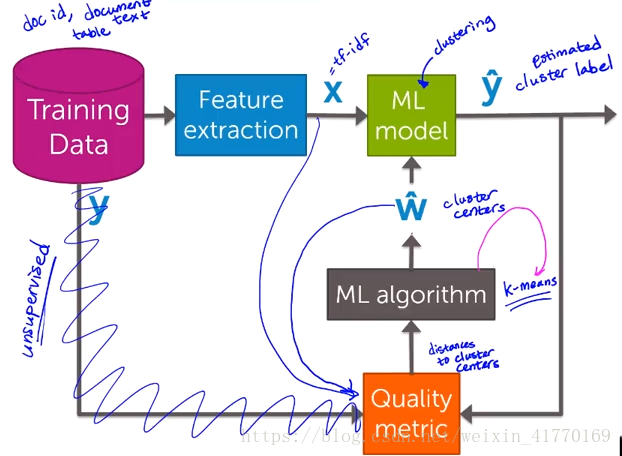
三、聚类和相似度总结
k-means算法是无监督算法,因此没有原始标签。k-means是通过每个集群中,各个点到集群中心的距离来评估的。好的集群,各个点到集群中心的距离都很小。

(1)每个训练点,经过特征提取,也就是比如单词统计、tf-idf等;
(2)随机选取聚类中心;
(3)计算点到聚类中心的距离,最近的聚类就划分为这一类;
(4)度量准则:如果距离不够小,则通过k-means算法的均值法,重新更新聚类中心;
(5)重复(3)(4),直到距离足够小,也就是收敛为止。