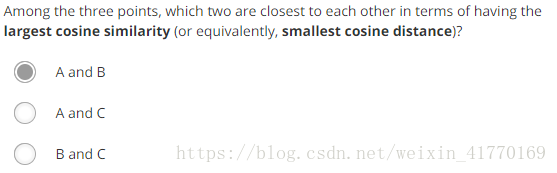一、介绍最近邻搜索算法
1、1NN伪代码
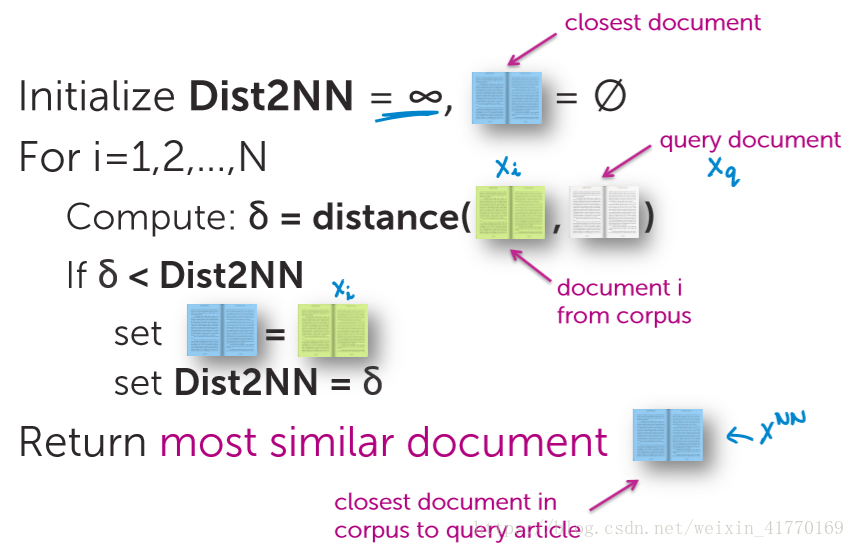
2、knn伪代码

3、文档表示:word counts
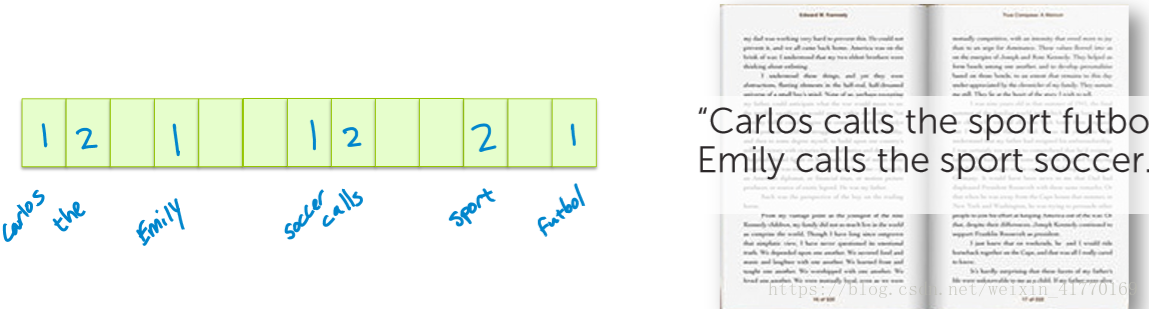
4、文档表示:tf*idf

5、距离矩阵
最简单的比如:
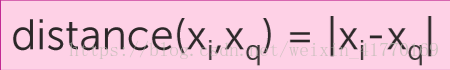
加权重的特征:有些特征比较重要,则权重较大。


6、相似度计算
(1)矩阵乘法
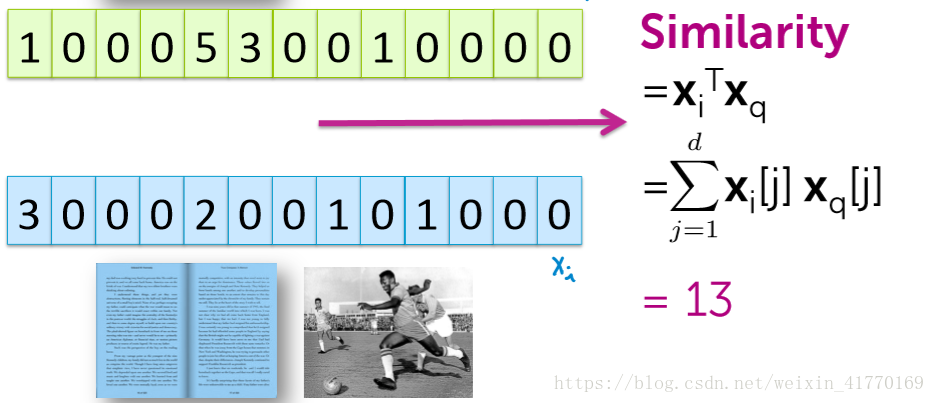
为了避免长短文章问题,进行归一化。

(2)cosine


二、kd-tree
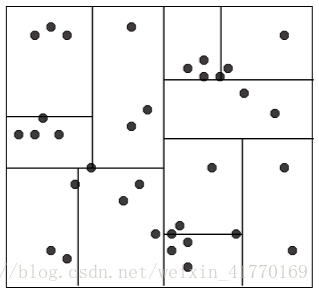
矩阵剪枝,对中小型维度的数据库比较有效。高维数据难处理。
NN搜索在kd-tree中:
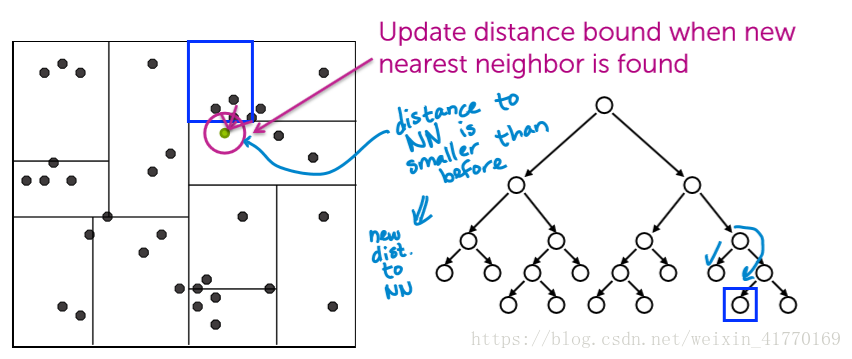

剪掉大部分分支,在剩下的中求k最近邻。
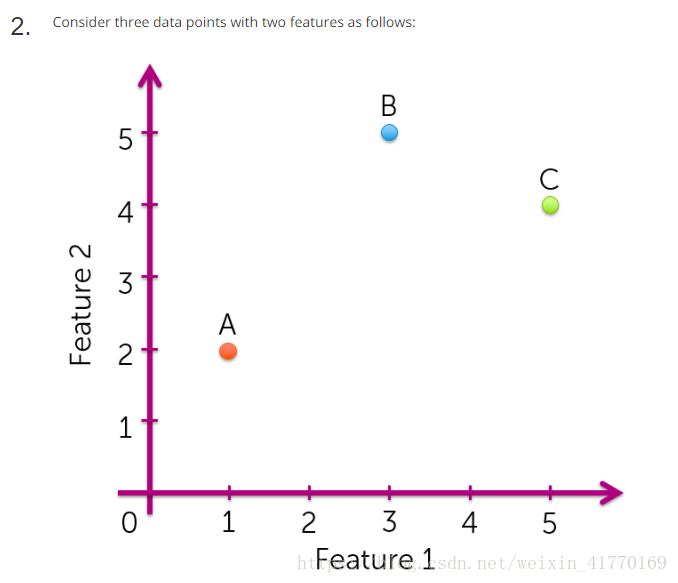
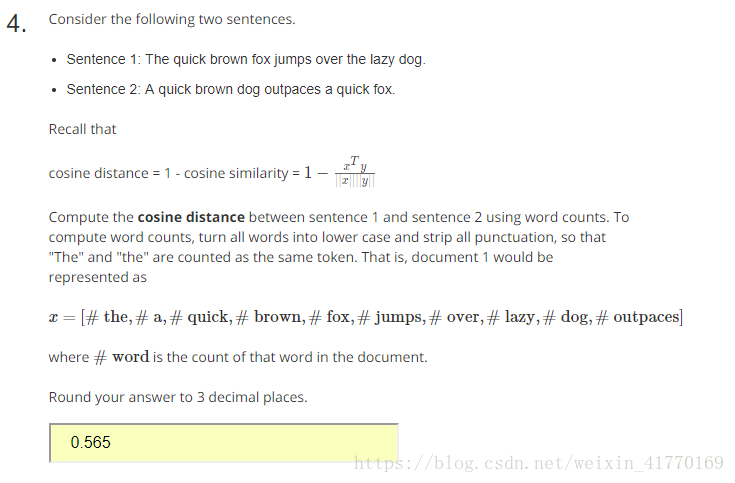
三、测试:cosine相似度公式见题4
一、介绍最近邻搜索算法
1、1NN伪代码
2、knn伪代码
3、文档表示:word counts
4、文档表示:tf*idf
5、距离矩阵
最简单的比如:
加权重的特征:有些特征比较重要,则权重较大。
6、相似度计算
(1)矩阵乘法
为了避免长短文章问题,进行归一化。
(2)cosine
二、kd-tree
矩阵剪枝,对中小型维度的数据库比较有效。高维数据难处理。
NN搜索在kd-tree中:
剪掉大部分分支,在剩下的中求k最近邻。
三、测试:cosine相似度公式见题4