AlexNet特点
- 使用ReLU作为激活函数,解决了sigmoid在网络较深时的梯度弥散问题
- 使用Dropout随机忽略一部分神经元,以避免过拟合
- 使用重叠的maxpool,避免argpool的模糊化效果
- 提出LRN层,对局部神经元的活动创建竞争机制,使其中响应比较大的值变得相对更大,并抑制其它反馈较小的神经元,增强模型的泛化能力
- GTX 580*2 3GB
- 数据增强:随机从256256的原始图像中截取224224区域,并水平翻转,相当于增加了(256-224)^2*2=2048倍的数据量,大大减轻了过拟合
源代码
注释已经写得很清楚了,不再赘述~
from datetime import datetime
import math
import tensorflow as tf
import time
batch_size = 32
num_batches = 100
def print_activations(t):
# 打印网络结构
print(t.op.name,'',t.get_shape().as_list())
def inference(images):
parameters = []
# conv1
with tf.name_scope('conv1') as scope:
#使用截断正态分布函数初始化卷积核参数 卷积核尺寸11*11 通道3 卷积核数量64
kernel = tf.Variable(tf.truncated_normal([11,11,3,64],dtype=tf.float32,stddev=1e-1),name='weights')
# 完成对图像的卷积操作 strides步长4*4(即图像上每4*4区域只取样一次)
conv = tf.nn.conv2d(images,kernel,[1,4,4,1],padding='SAME')
# 初始化biases为0
biases = tf.Variable(tf.constant(0.0,shape=[64],dtype=tf.float32),trainable=True,name='biases')
bias = tf.nn.bias_add(conv,biases)
# ReLU激活函数对结果进行非线性处理
conv1 = tf.nn.relu(bias,name=scope)
print_activations(conv1)
# 将可训练参数(kernel,biases)添加至 parameters
parameters += [kernel,biases]
# 自主选择是否选用LRN depth_radius设为4
lrn1 = tf.nn.lrn(conv1,4,bias=1.0,alpha=0.001/9,beta=0.75,name='lrn1')
# 池化尺寸3*3(即将3*3大小的像素块降为1*1的像素) padding模式VALID,即取样是不能超过边框
pool1 = tf.nn.max_pool(lrn1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool1')
# 打印输出结果pool1的结构
print_activations(pool1)
# conv2
with tf.name_scope('conv2') as scope:
# 卷积核尺寸5*5 通道64(上一层输出通道数,也就是上一层是卷积核数量)卷积核数量194
kernel = tf.Variable(tf.truncated_normal([5,5,64,192],dtype=tf.float32,stddev=1e-1),name='weights')
# 卷积步长1*1 padding模式为SAME:矩形周围补2个像素
conv = tf.nn.conv2d(pool1,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0,shape=[192],dtype=tf.float32),trainable=True,name='biases')
bias = tf.nn.bias_add(conv,biases)
conv2 = tf.nn.relu(bias,name=scope)
print_activations(conv2)
parameters += [kernel,biases]
lrn2 = tf.nn.lrn(conv2,4,bias=1.0,alpha=0.001/9,beta=0.75,name='lrn2')
pool2 = tf.nn.max_pool(lrn2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool2')
print_activations(pool2)
# conv3
with tf.name_scope('conv3') as scope:
# 卷积核尺寸3*3 输入通道数192 输出通道数384
kernel = tf.Variable(tf.truncated_normal([3,3,192,384],dtype=tf.float32,stddev=1e-1),name='weights')
# 卷积步长1*1 padding模式为SAME:矩形周围补1个像素
conv = tf.nn.conv2d(pool2,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0,shape=[384],dtype=tf.float32),trainable=True,name='biases')
bias = tf.nn.bias_add(conv,biases)
conv3 = tf.nn.relu(bias,name=scope)
print_activations(conv3)
parameters += [kernel,biases]
# conv4
with tf.name_scope('conv4') as scope:
# 卷积核尺寸3*3 输入通道数384 输出通道数256
kernel = tf.Variable(tf.truncated_normal([3,3,384,256],dtype=tf.float32,stddev=1e-1),name='weights')
# 卷积步长1*1
conv = tf.nn.conv2d(conv3,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0,shape=[256],dtype=tf.float32),trainable=True,name='biases')
bias = tf.nn.bias_add(conv,biases)
conv4 = tf.nn.relu(bias,name=scope)
print_activations(conv4)
parameters += [kernel,biases]
# conv5
with tf.name_scope('conv5') as scope:
# 卷积核尺寸3*3 输入通道数256 输出通道数256
kernel = tf.Variable(tf.truncated_normal([3,3,256,256],dtype=tf.float32,stddev=1e-1),name='weights')
# 卷积步长1*1
conv = tf.nn.conv2d(conv4,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0,shape=[256],dtype=tf.float32),trainable=True,name='biases')
bias = tf.nn.bias_add(conv,biases)
conv5 = tf.nn.relu(bias,name=scope)
print_activations(conv5)
parameters += [kernel,biases]
# maxpool
pool5 = tf.nn.max_pool(conv5,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool5')
print_activations(pool5)
# fc6
# fc7
# fc8
return pool5,parameters
def time_tensorflow_run(session,target,info_string):
# 预热轮数 给程序预热
num_steps_burn_in = 10
# 总时间
total_duration = 0.0
# 总时间的平方和 以计算方差
total_duration_squared = 0.0
for i in range(num_batches+num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s:step %d, duration = %.3f' % (datetime.now(),i - num_steps_burn_in,duration))
total_duration += duration
total_duration_squared += duration*duration
# 计算每轮迭代的平均耗时mn
mn = total_duration / num_batches
vr = total_duration_squared /num_batches - mn*mn
# 标准差
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(),info_string,num_batches,mn,sd))
def run_benchmark():
with tf.Graph().as_default():
image_size = 224
images = tf.Variable(tf.random_normal([batch_size,image_size,image_size,3],
dtype=tf.float32,
stddev=1e-1))
pool5,parameters = inference(images)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
time_tensorflow_run(sess,pool5,'Forward')
objective = tf.nn.l2_loss(pool5)
grad = tf.gradients(objective,parameters)
time_tensorflow_run(sess,grad,"Forward-backward")
# 主函数
run_benchmark()
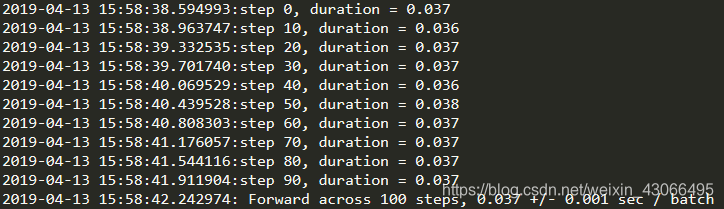
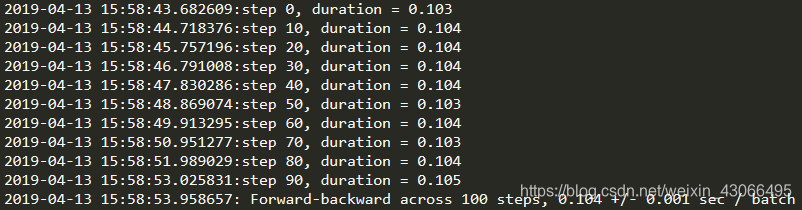
运行结果
cpu:i5 2.6GHz
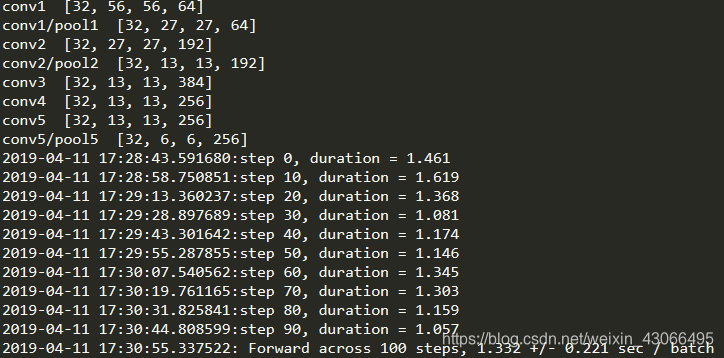
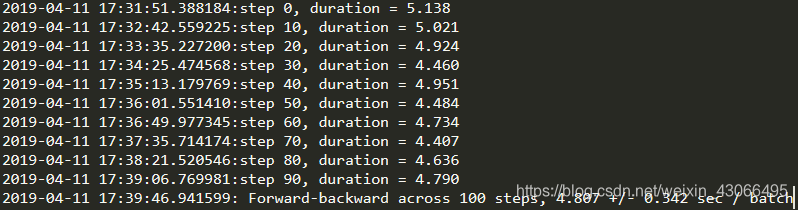
GPU:Nvida Quardro 2000 5GB
(教材上GTX 1080 跑的是0.026)