《Identity Mappings in Deep Residual Networks》
- 2016,kaiming He et al,ResNet V2。
深度残差网络作为一种极深的网络框架,在精度和收敛等方面都展现出了很好的特性。作者通过对残差块(residual building blocks)背后的计算传播方式进行分析,表明了当跳跃连接(skip connections)以及附加激活项都使用恒等映射(identity mappings)时,前向和后向的信号能够直接的从一个block 传递到其他任意一个block。一系列的“消融”实验(ablation experiments)也验证了这些恒等映射的重要性。这促使我们提出了一个新的残差单元,它使得训练变得更简单,同时也提高了网络的泛化能力。
深度残差网络(ResNets)由很多个“残差单元”组成。每一个单元都可以表示为:
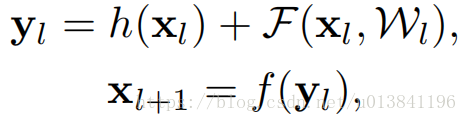
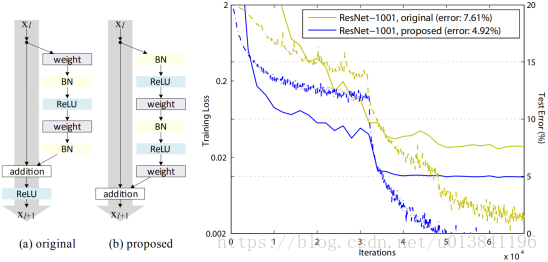
如图所示,(a) 原始残差单元;(b) 本文提出的残差单元;右:1001层ResNets 在CIFAR-10上的训练曲线。实线对应测试误差(右侧的y轴),虚线对应训练损失(左侧的y轴)。本文提出的单元使得ResNet-1001的训练更简单。
1.分析:如果addition操作之后是恒等映射,则Residual network的数学表达变成:
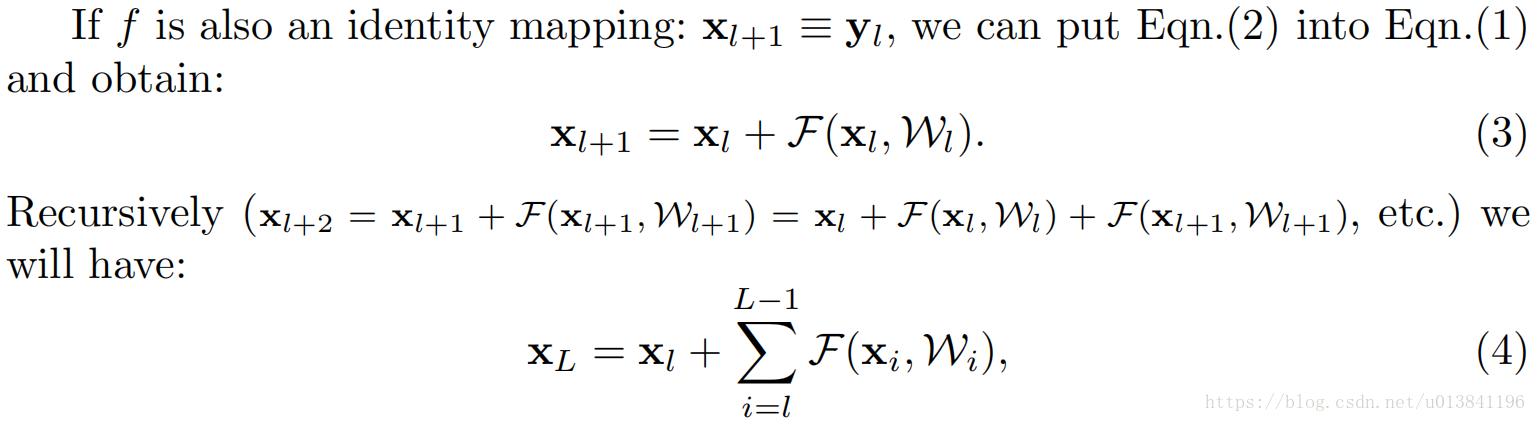
反向传播公式:
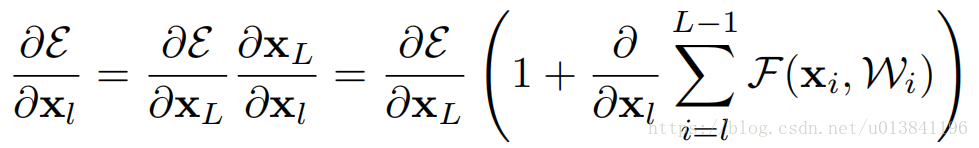
公式表现为两个项之和,第一项直接通道,可以把深层的梯度传递到任意浅层,可以看出浅层的梯度很难为0,第二项为卷积通道,对于一个mini-batch总的全部样本不可能都为-1。这意味着,哪怕权重是任意小的,也不可能出现梯度消失的情况。
2.恒等跨越连接的重要性:
作者把原来的identity mapping改成线性映射,并分析其影响(h(x)=kx )
前向和反向公式为:

此网络的后向传播过程受λ控制,若λ>1,则第一项会非常大,因而会导致梯度爆炸;若λ<1,则第一项会非常小,甚至消失。反向传播的信号只能从第二项传递,但是其优化难度更大。综上,这个结构妨碍了信息的传播,恒等映射更好。
3.Experiment on Skip connection:
在shortcut上添加各种结构,进行对比试验,试验结果证明了恒等映射最好。
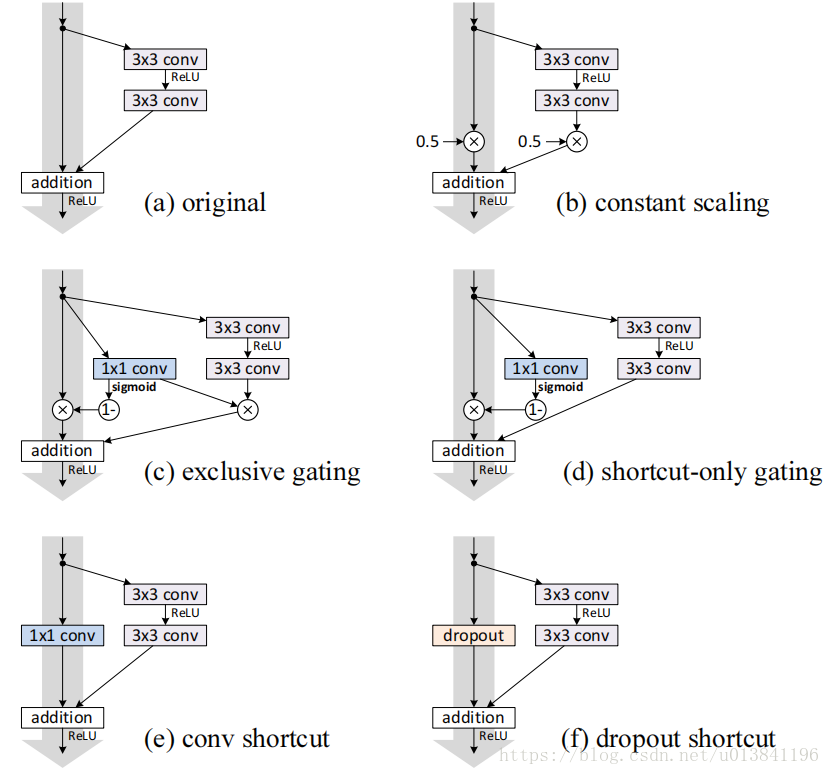
分类错误率,当错误率高于20%,记为“fail”。
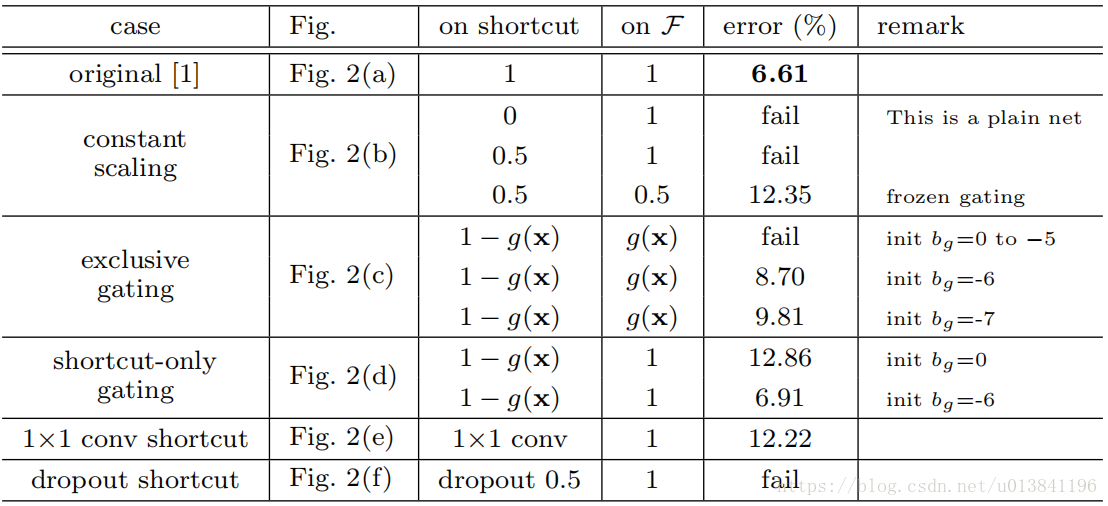
事实上, shortcut-only gating和1x1包含原来的identity shortcut, 其表达能力应该更强,但是造成其结果degradation的原因是优化问题,而非representational abilities。
4.On the Usage of Activation Functions
之前的网络结构都是假设f是恒等映射,这一部分研究relu激活函数的影响,并提出了一个“pre-activation”结构,能进一步提高了网络的性能。
对比实验:

Post-activation or pre-activation?
原始的residual unit的设计中,activation xl+1=f(yl)对于两个分支都有影响,我们设计了一个非对称的结构,只对F分支,也就是:
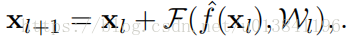
这就等于pre-activation形式了:
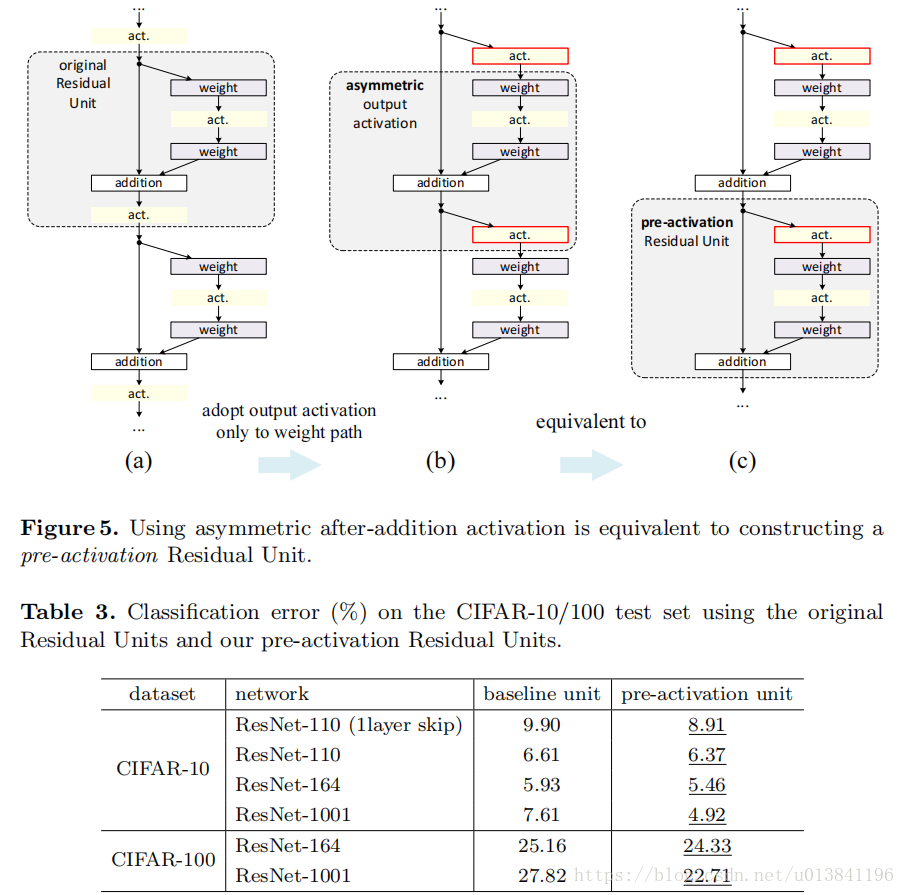
这里设置了fig4中的两种方案,d的提高不明显,可以看出BN和ReLU更配,他俩适合在一起,table3更说明了这个问题。
这种结构有双重效果:
1.缓解了优化难度。此结构中合并之后是恒等过渡,使得梯度的传播更加顺畅。其次减少了信息的流失,使得下一个block保存更多的信息。
2.减少过拟合。新结构多加了一个BN层,使得信息更加规范化。
ResNet V2和ResNet V1的主要区别在于,作者通过研究ResNet残差学习单元的传播公式,发现前馈和反馈信号可以直接传输,因此skip connection 的非线性激活函数(如ReLU)替换为Identity Mapping(y=x),使用内部的“pre-activation”结构。同时,ResNet V2在每一层中都使用了Batch Normalization。这样处理之后,新的残差学习单元将比以前更容易训练且泛化性更强。