《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
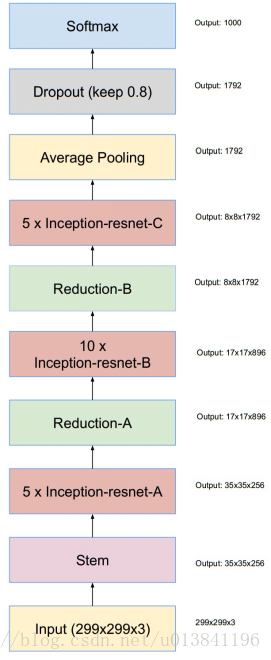
- 2016,Google,Inception V4,Inception ResNet V1、V2
Inception结构有着良好的性能,且计算量低。Residual connection不同于传统网络结构,且在2015 ILSVRC取得冠军,它的性能和Inception-v3接近。作者尝试将Inception结构和Residual connection结合,同时也设计了不用Residual connection版本的Inception-v4。通过对三个残差和一个Inception-v4进行组合,在top-5错误率上达到了 3.08%。
1.相关工作:
卷积网络在图像识别领域已经十分流行,经典网络有AlexNet、VGGNet、GoogLeNet等。Residual connection的提出是用于训练更深的网络,但是作者发现不使用Residual connection也可以训练更深的网络。Residual connection并不是必要条件,只是使用了Residual connection会加快训练速度。
Inception结构最初由GoogLeNet引入,GoogLeNet叫做Inception-v1;之后引入了BatchNormalization,叫做Inception-v2;随后引入分解,叫做Inception-v3。
2.网络架构:
Inception-v4网络,对于Inception块的每个网格大小进行了统一。
下图是Inception-v4的结构:所有图中没有标记“V”的卷积使用same的填充原则,即其输出网格与输入的尺寸正好匹配。使用“V”标记的卷积使用valid的填充原则,意即每个单元输入块全部包含在前几层中,同时输出激活图(output activation map)的网格尺寸也相应会减少。

Stem模块为:
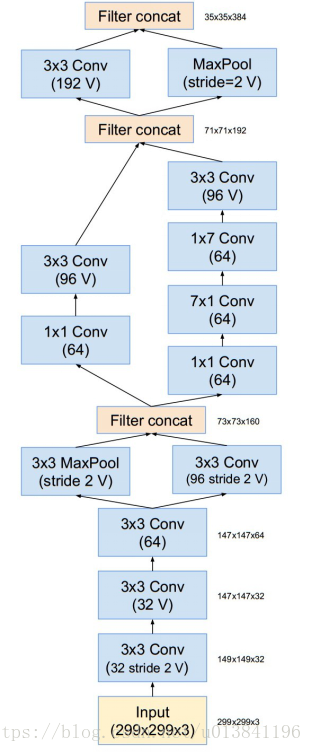
Inception-v4网络35×35网格的框架(对应图中Inception-A块):

Inception-v4网络17×17网格块的框架(对应图中Inception-B块):

Inception-v4网络的8×8网格模块的框架(对应图中Inception-C块):

不同的Inception模块的连接,减小了feature map,却增加了filter bank。
35x35变为17x17模块,即Reduction-A :

17x17变为8x8模块,即Reduction-B :

Inception-ResNet
我们尝试了残差Inception的几个版本。这里对其中的两个进行具体细节展示。第一个是“Inception-ResNet-v1”,计算代价跟Inception-v3大致相同,第二个“Inception-ResNet-v2”的计算代价跟Inception-v4网络基本相同。
Inception-ResNet的两个版本,结构基本相同,只是细节不同。整体结构为:
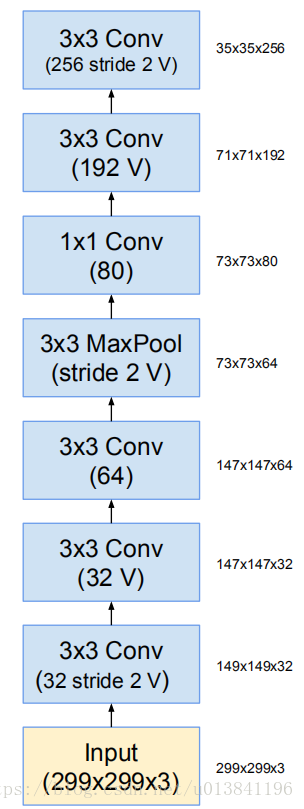
Inception-ResNet-v1和Inception-ResNet-v2对应的stem模块为:
注:Inception-ResNet-v2和Inception-v4使用相同的Stem模块
Inception-ResNet-v1的Stem模块:
Inception-ResNet-v1和Inception-ResNet-v2对应的Inception-resnet-A模块为:


Inception-ResNet-v1和Inception-ResNet-v2对应的Inception-resnet-B模块为:


Inception-ResNet-v1和Inception-ResNet-v2对应的Inception-resnet-C模块为:


注:Inception-ResNet-v1和Inception-ResNet-v2对应的35*35to17*17的reduction模块同Inception v4一样。
Inception-ResNet-v1和Inception-ResNet-v2对应的17x17变为8x8模块,即Reduction-B:


Inception-ResNet的stem模块和Reduction-B模块也略微不同。Inception-ResNet-v1和Inception-ResNet-v2主要在于Reduction-A结构不同:

其中k,l,m,n表示filter bank size。
3.对残差模块的缩放
我们发现,如果滤波器数量超过1000,残差网络开始出现不稳定,同时网络会在训练过程早期便会出现“死亡”,意即经过成千上万次迭代,在平均池化(average pooling) 之前的层开始只生成0。通过降低学习率,或增加额外的batch-normalizatioin都无法避免这种状况。
我们发现,在将残差模块添加到activation激活层之前,对其进行放缩能够稳定训练。通常来说,我们将残差放缩因子定在0.1到0.3。
注:He在训练Residual Net时也发现这个问题,提出了“two phase”训练。首先“warm up”,使用较小的学习率。接着再使用较大的学习率。

缩放模块仅仅适用于最后的线性激活。
4.实验结果
在验证集上各种结构的单个模型以及单次裁剪的top-1和top-5错误率。

5.结论
本文详细呈现了三种新的网络结构:
(1)Inception-ResNet-v1:混合Inception版本,它的计算效率同Inception-v3;
(2)Inception-ResNet-v2:更加昂贵的混合Inception版本,同明显改善了识别性能;
(3)Inception-v4:没有残差链接的纯净Inception变种,性能如同Inception-ResNet-v2我们研究了引入残差连接如何显著的提高inception网络的训练速度。而且仅仅凭借增加的模型尺寸,我们的最新的模型(带和不带残差连接)都优于我们以前的网络。