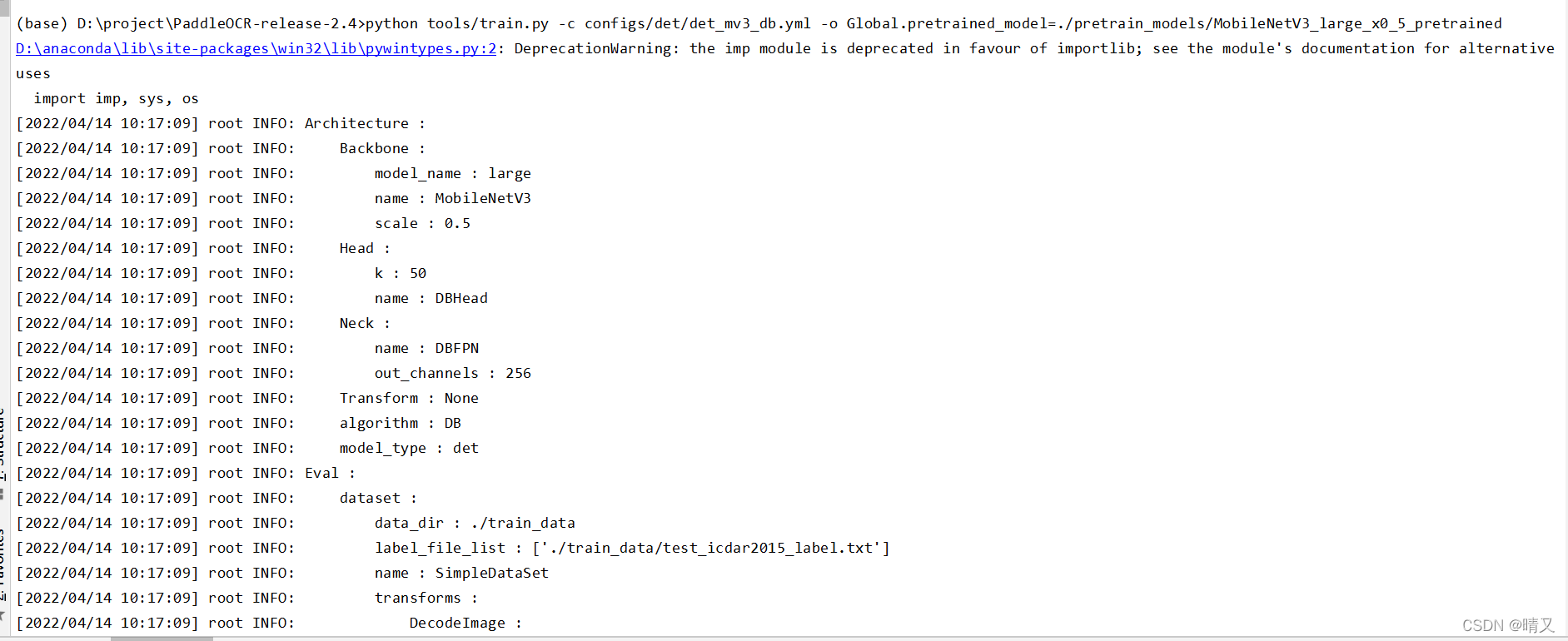
代码:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/PPOCRLabel/README_ch.md
注意:这是按官网给的在本机跑的手顺
如果是虚拟机或者物理机云服务器什么的,建议用它手顺里的自带的镜像跑。
手顺:向下拉,底下有个text detection,点进去,这就是官方的训练步骤

按步骤做
1. 数据和权重准备
1.1 数据准备
icdar2015 数据集包含使用可穿戴相机获得的 1000 张图像的训练集和包含使用可穿戴相机获得的 500 张图像的测试集。icdar2015可以从官方网站https://rrc.cvc.uab.es/?ch=4&com=downloads获得。下载需要注册。
注册并登录后,下载下图中红色框中标记的部分。
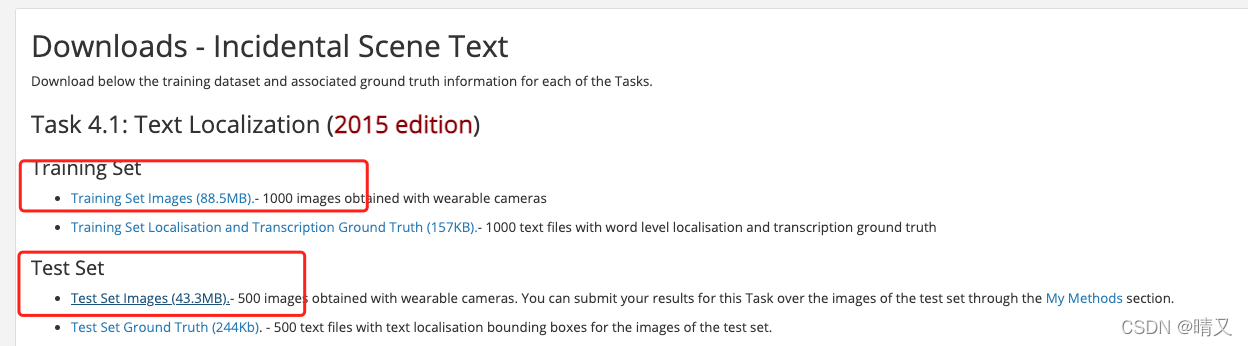
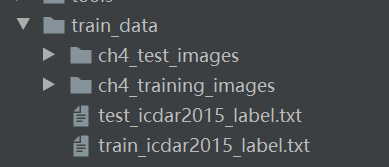
将下载的数据集解压缩到工作目录,假设它在 PaddleOCR/train_data/ 下解压缩。

此外,PaddleOCR将许多分散的注释文件组织成两个单独的注释文件,分别用于训练和测试,可以通过wget下载:
#Under the PaddleOCR path
cd PaddleOCR/
wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt
wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt
运行wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt:问题

‘wget’ 不是内部或外部命令,也不是可运行的程序
或批处理文件。
解决:
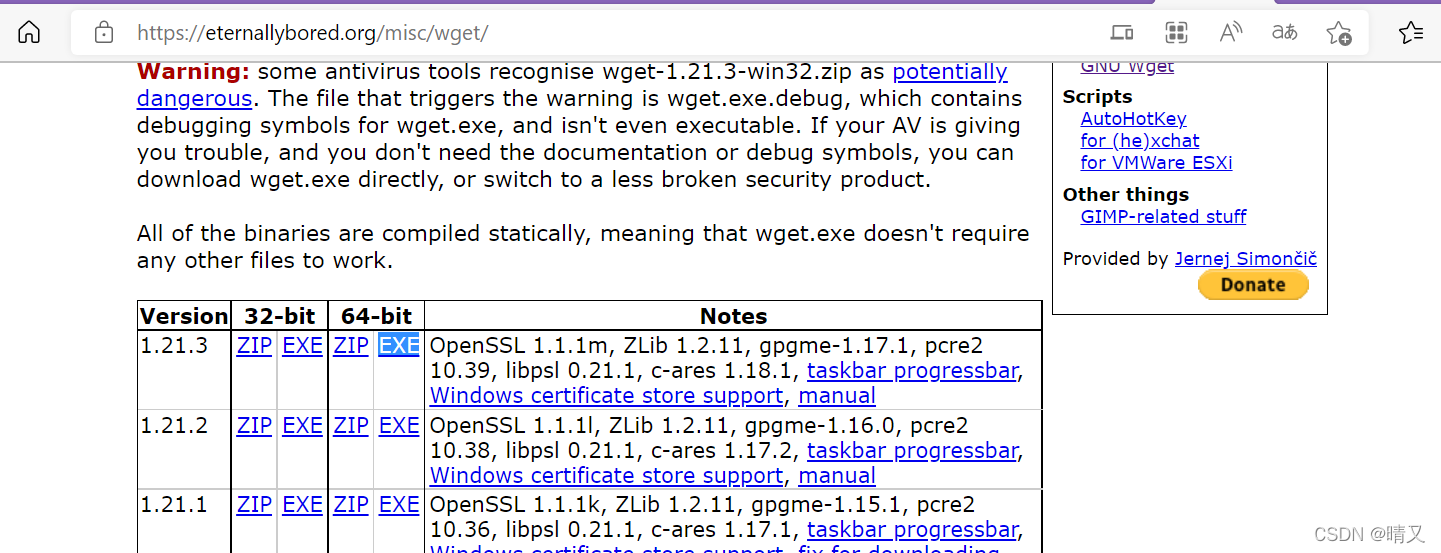
①链接:https://blog.csdn.net/weixin_43360896/article/details/111910872
②方法:
去wget官网https://eternallybored.org/misc/wget/下载,选择32位/64位,下载ZIP/EXE,将下载下来的EXE文件放到C:\Windows\System32即可。
再去运行刚刚两条代码:
# Under the PaddleOCR path
cd PaddleOCR/
wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt
wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt

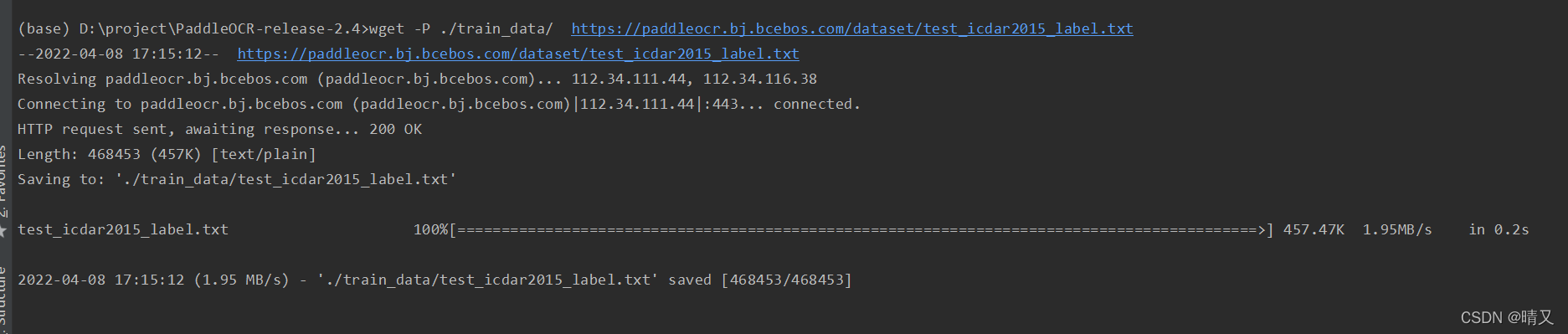
解压缩数据集并下载注释文件后,PaddleOCR/train_data/ 有两个文件夹和两个文件,它们是:
提供的注释文件格式如下所示,以“\t”分隔:
" Image file name Image annotation information encoded by json.dumps"
ch4_test_images/img_61.jpg [{
"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {
...}]

这是img61,里面包含"MASA"字样

字典中的 坐标 (x, y) 表示文本框的四个点的坐标,从左上角的点顺时针排列。
transcription表示当前文本框的文本。当其内容为“###”时,表示文本框无效,将在训练期间跳过。
如果您想在其他数据集上训练PaddleOCR,请根据上述格式构建注释文件。
1.2 下载预训练模型
首先下载预先训练的模型。PaddleOCR的检测模型目前支持3个骨干网,即MobileNetV3,ResNet18_vd和ResNet50_vd。您可以使用PaddleClas中的模型来根据需要替换主干网。骨干预训练权重的响应下载链接可以在(https://github.com/PaddlePaddle/PaddleClas/blob/release%2F2.0/README_cn.md#resnet%E5%8F%8A%E5%85%B6vd%E7%B3%BB%E5%88%97 中找到。
cd PaddleOCR/
# Download the pre-trained model of MobileNetV3
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams
# or, download the pre-trained model of ResNet18_vd
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet18_vd_pretrained.pdparams
# or, download the pre-trained model of ResNet50_vd
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet50_vd_ssld_pretrained.pdparams


2. 培训
2.1 开始训练
1.修改①
如果安装了 CPU 版本,请在配置中将参数 use_gpu 设置为 false。
路径:
configs/det/det_mv3_db.yml

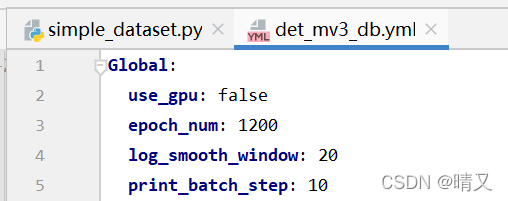
代码:
Global:
use_gpu: false
epoch_num: 1200
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/db_mv3/
save_epoch_step: 1200
# evaluation is run every 2000 iterations
eval_batch_step: [0, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
checkpoints:
save_inference_dir:
use_visualdl: False
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./output/det_db/predicts_db.txt
2.修改②
第一:
训练数据的路径
还是刚刚的文件
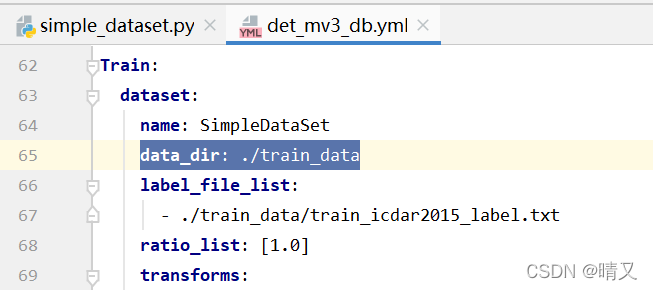 修改后面的路径,因为我的训练数据在:
修改后面的路径,因为我的训练数据在:
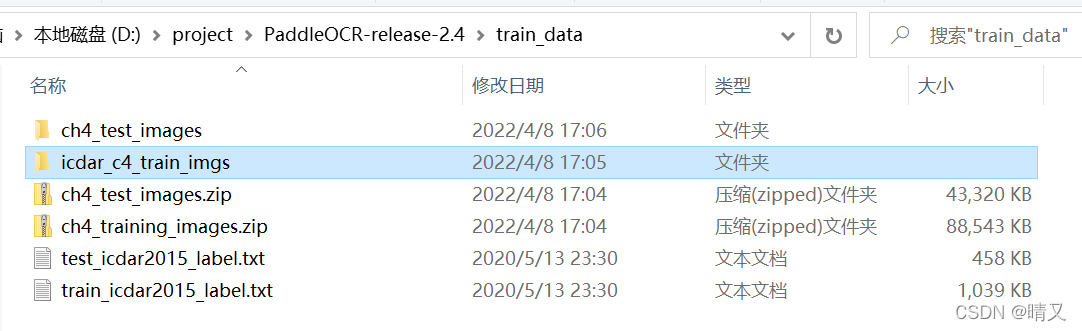
所以把路径修改为./train_data
代码:
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data
第二:
修改label_file_list:路径:
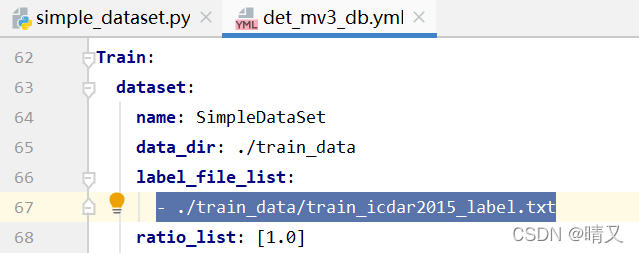
我的路径:
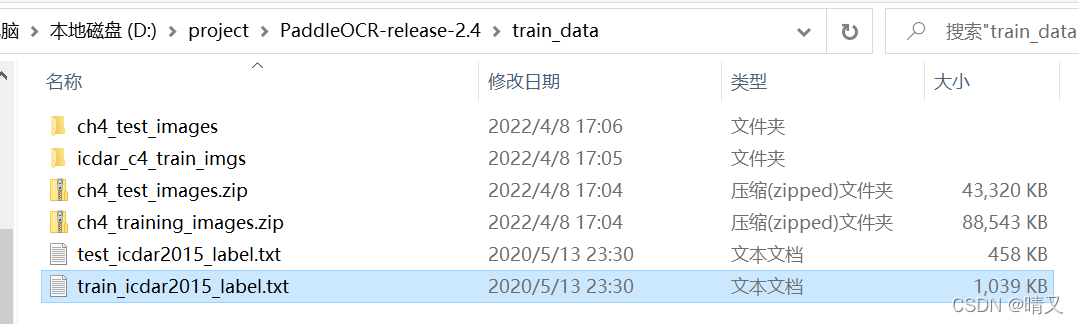
所以修改为:
./train_data/train_icdar2015_label.txt
代码:
label_file_list:
- ./train_data/train_icdar2015_label.txt
第三:
修改num_workers
(个人习惯)
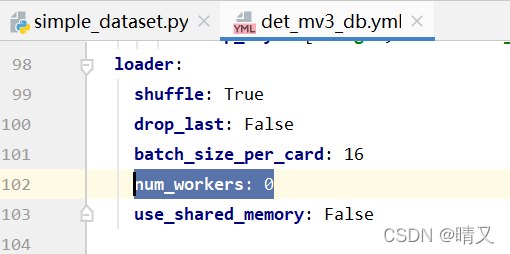
loader:
shuffle: True
drop_last: False
batch_size_per_card: 16
num_workers: 0
use_shared_memory: False
第四:
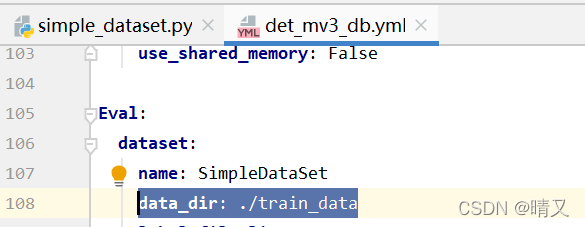
修改验证集相关
数据路径:
代码:
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data
根据这里看我的验证集在哪里:
第五:
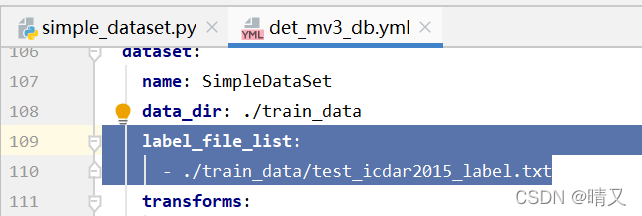
验证集标签路径:
label_file_list:
根据:
代码:
dataset:
name: SimpleDataSet
data_dir: ./train_data
label_file_list:
- ./train_data/test_icdar2015_label.txt
第六:
在这个网页下面

点这个PP-OCR Model Download进入新页面
找到这个表格
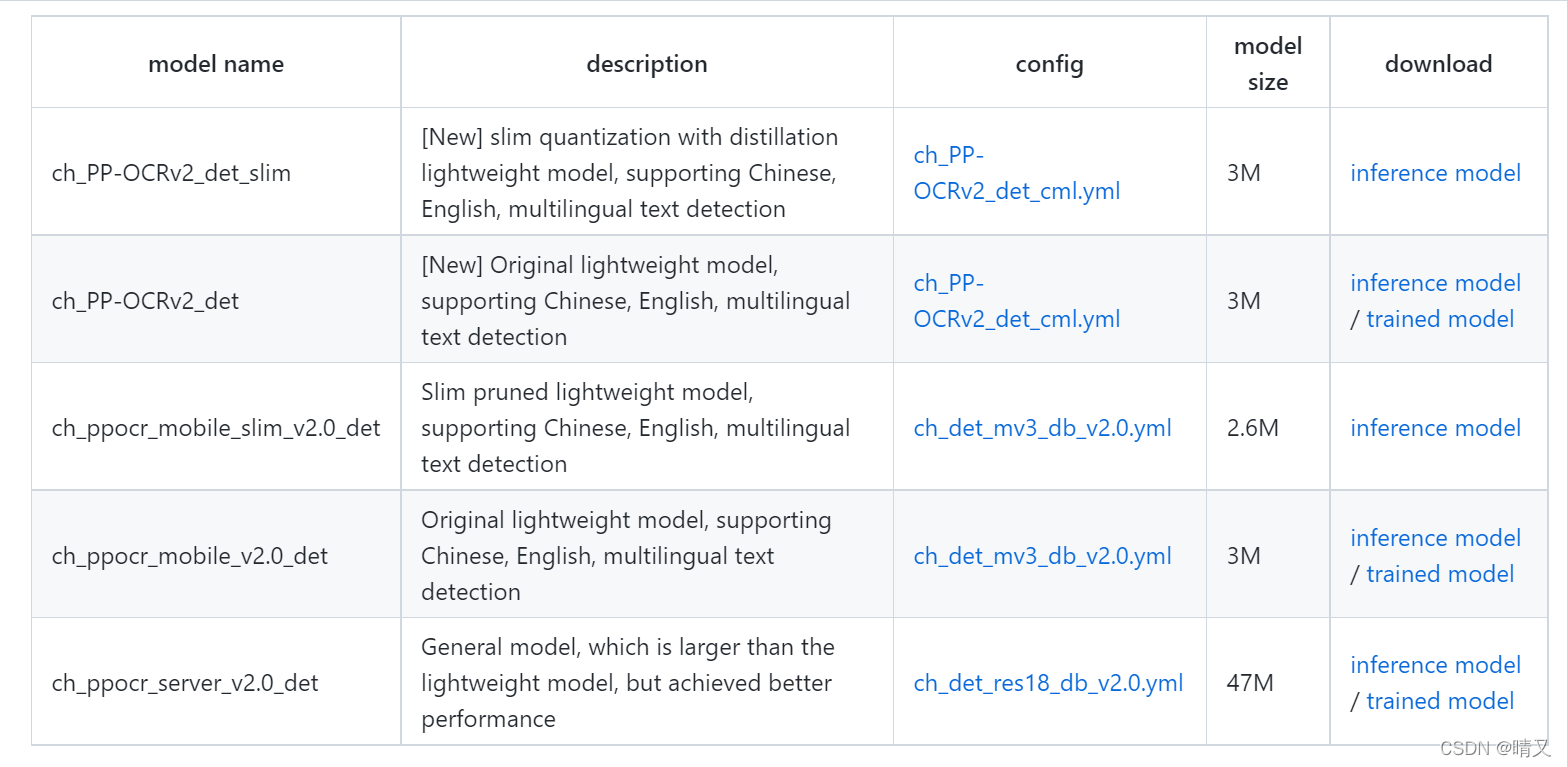
因为我们前面第一步修改的是det_mv3_db.yml这个文件
从表格里可看出,det_mv3_db.yml文件对应的是
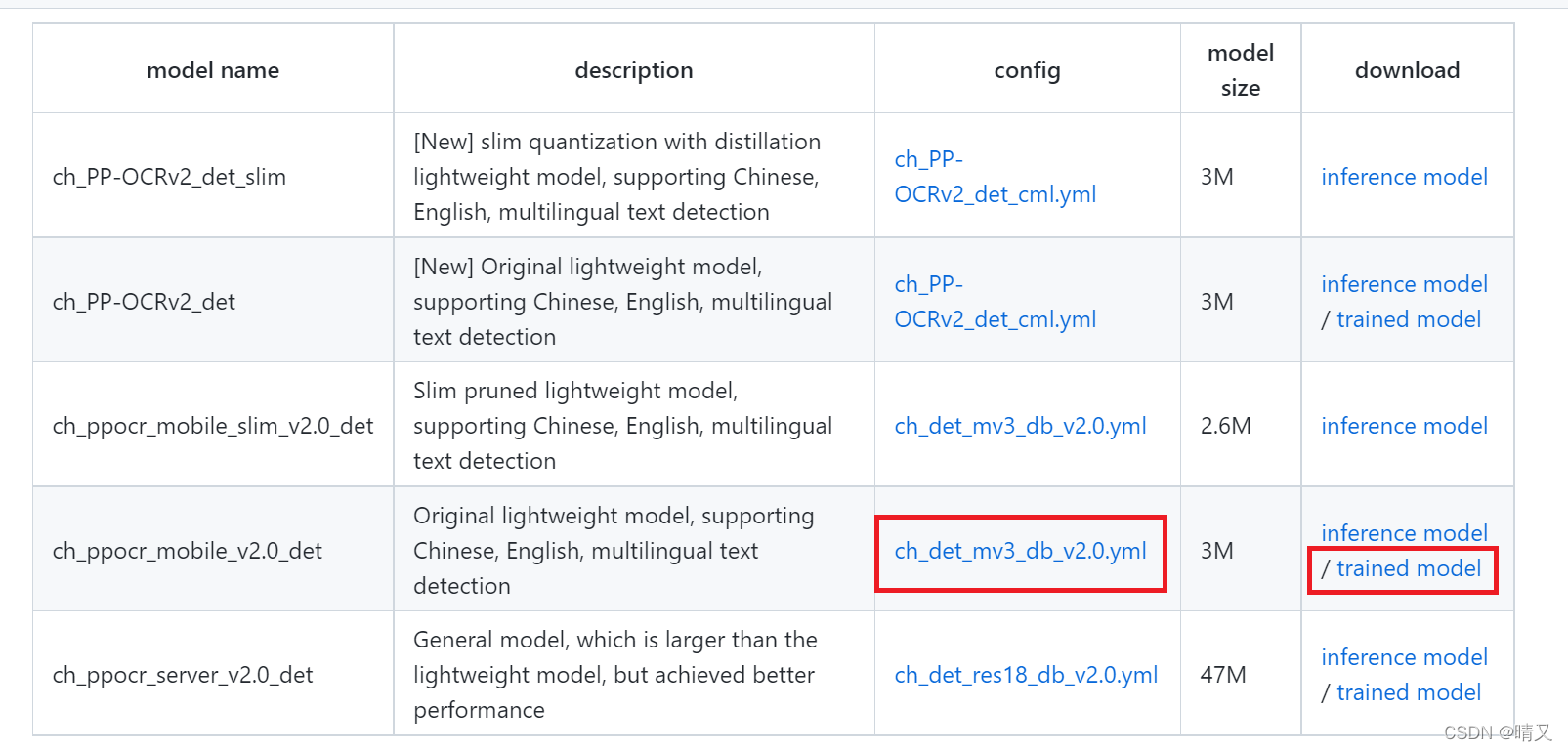
这个训练模型,所以我们需要下载,然后解压
打开文件夹
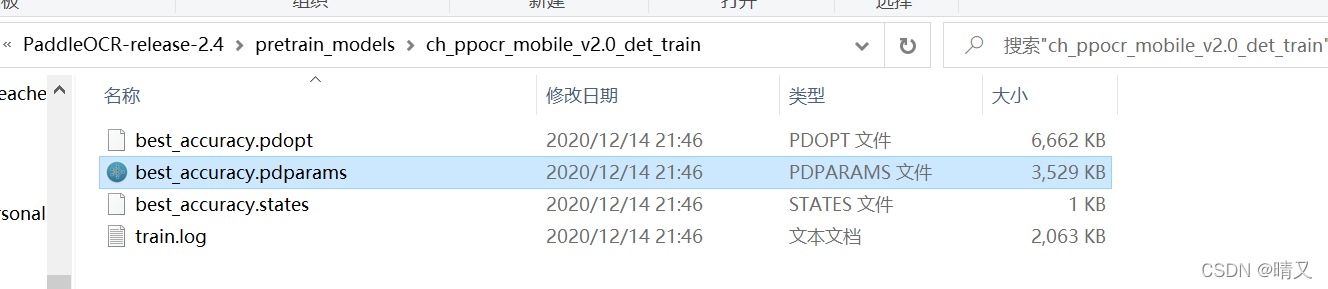
这个就是我们的预训练模型
把他的路径考到这里
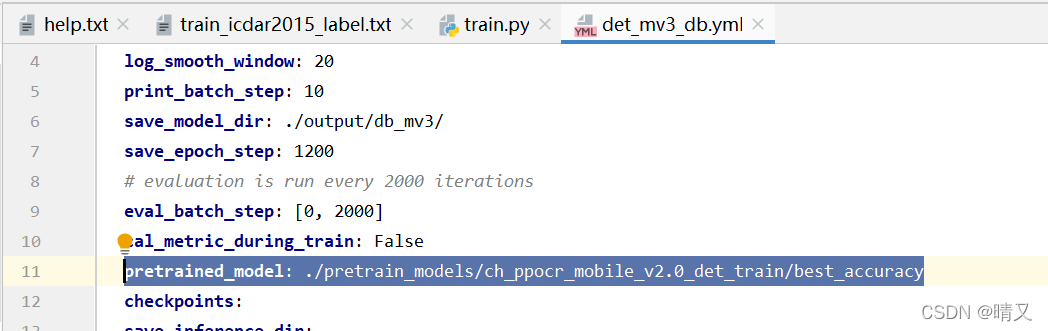
也就是接着这个文件去训练
2.2 加载训练模型、训练
代码:
python tools/train.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained