前言
PaddlePaddle使用Trainer训练模型虽然直接了当,方便快捷,但是对于一些需要逐步训练的模型则比较麻烦。类似Tensorflow采用session.run的形式逐步训练模型,使得训练过程更加显而易见。PaddlePaddle新版本Fluid中,采用Executor也可以完成类似的训练。本文针对简单的回归问题简述以下PaddlePaddle的Executor训练过程。
1. Reader的建立
本文尝试使用神经网络模型拟合二次函数,首先我们建立以下二次函数的训练数据,并加上噪声:
train_x = np.linspace(-1, 1, 128) # shape (100, 1) noise = np.random.normal(0, 0.1, size=train_x.shape) train_y = np.power(train_x, 2) + noise def reader(): def reader_creator(): for i in range(128): yield train_x[i],train_y[i] return reader_creator
train_reader = paddle.batch(reader(),batch_size=64)
2. 网络的构建以及损失函数
我们构建一层10个神经元的隐藏层,代码如下:
#构建网络模型 input_layer = fluid.layers.data(name='data',shape=[1],dtype='float32') hid = fluid.layers.fc(input=input_layer, size=10, act='relu') output = fluid.layers.fc(input=hid, size=1, act=None) label = fluid.layers.data(name='label',shape=[1],dtype='float32') #损失函数采用均方差 cost = fluid.layers.square_error_cost(input=output,label=label) avg_cost = fluid.layers.mean(cost) #优化器选择 optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.01) opts = optimizer.minimize(avg_cost)
3. 训练模型
训练同往常一样,但是需要新建一个Executor和DataFeeder,然后直接对每个batch进行训练,直接明了。
#选择CPU place = fluid.CPUPlace() feeder = fluid.DataFeeder(place=place, feed_list=['data', 'label']) #克隆program用于后面测试 test_program = fluid.default_main_program().clone(for_test=True) exe = fluid.Executor(place) #初始化参数 exe.run(fluid.default_startup_program()) for pass_id in range(1000): #遍历每个batch for batch_id,data in enumerate(train_reader()): loss = exe.run(fluid.default_main_program(), feed=feeder.feed(data), fetch_list=[avg_cost])
4. 测试
这里也是同样运用exe.run,与上面训练差不多一样。这里还是用回训练集测试,将每个batch的结果保存在数组中。
#用于保存每个batch的结果,便签等 x_ = [] y_ = [] l_= [] for batch_id,data in enumerate(train_reader()): x,y,l=exe.run(program=test_program, feed=feeder.feed(data), fetch_list=[input_layer,output,label]) x_ =np.hstack((x_,x.ravel())) y_ =np.hstack((y_,y.ravel())) l_ =np.hstack((l_,l.ravel()))
5.结果
红线逐步拟合到散点
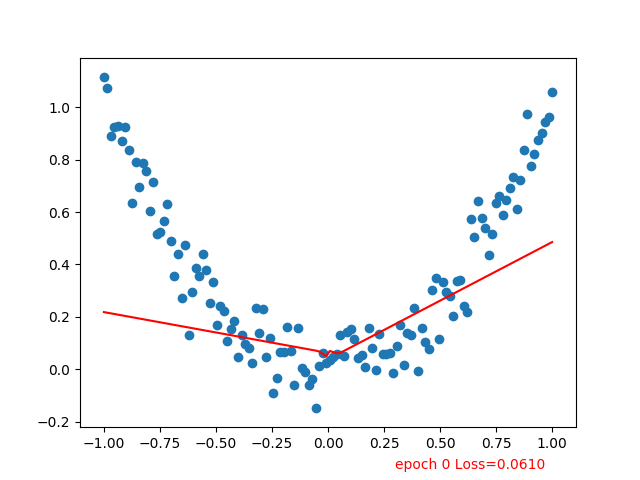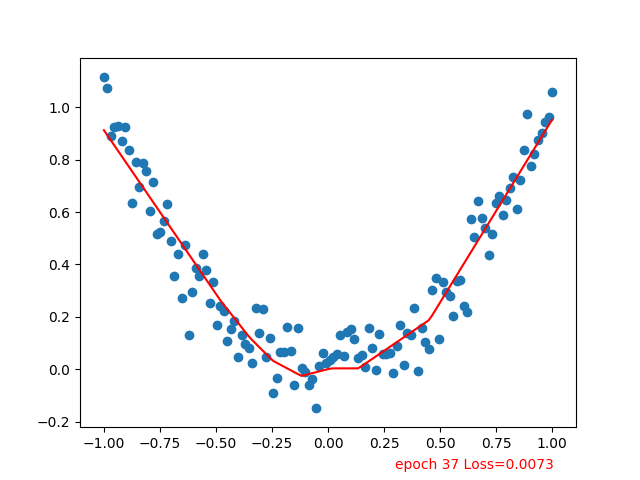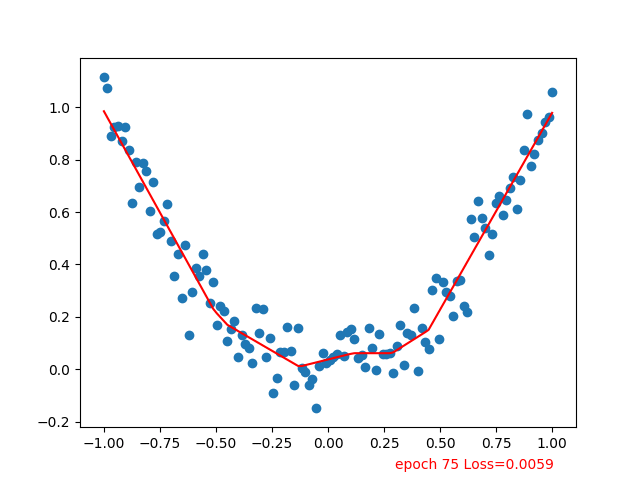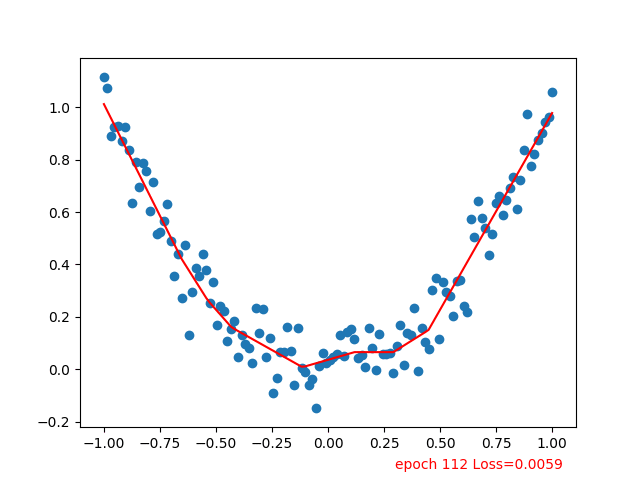
参考:Tensorflow-Tutorial/tutorial-contents/301_simple_regression.py
代码:GitHub