以labelme多边形标注为例,jpg和json文件放下hone/data/1下面:
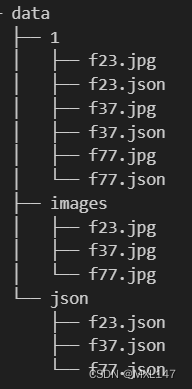
将json和jpg分别拿出来当道json和images文件夹下,方便后面处理。
mkdir /home/data/json
mkdir /home/data/images
cp /home/data/1/*.json /home/data/json
cp /home/data/1/*.jpg /home/data/imagesdet数据集准备
格式如下,参考:PaddleOCR/ocr_datasets.md at release/2.6 · PaddlePaddle/PaddleOCR · GitHub
" 图像文件名 json.dumps编码的图像标注信息"
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]cls数据集准备
格式如下,参考:PaddleOCR/angle_class.md at release/2.6 · PaddlePaddle/PaddleOCR · GitHub
" 图像文件名 图像标注信息 "
train/cls/train/word_001.jpg 0
train/cls/train/word_002.jpg 180res数据集准备
格式如下,参考:PaddleOCR/ocr_datasets.md at release/2.6 · PaddlePaddle/PaddleOCR · GitHub
代码
"""paddleocr数据集制作"""
import json
import os
import numpy as np
from scipy.spatial.distance import cdist
import argparse
import cv2
import shutil
class paddle_datasets():
def __init__(self, data_path):
super().__init__()
self.data_path = data_path
self.root_path = os.path.dirname(data_path)
self.det_path = os.path.join(self.root_path, 'det_data')
self.res_path = os.path.join(self.root_path, 'res_data')
self.cls_path = os.path.join(self.root_path, 'cls_data')
self.json_path = os.path.join(self.root_path, 'json')
self.crop_path = os.path.join(self.root_path, 'crop')
self.det_train_path = os.path.join(self.det_path, 'train')
self.det_val_path = os.path.join(self.det_path, 'val')
self.res_train_path = os.path.join(self.res_path, 'train')
self.res_val_path = os.path.join(self.res_path, 'val')
self.cls_train_path = os.path.join(self.cls_path, 'train')
self.cls_val_path = os.path.join(self.cls_path, 'val')
ls = [self.det_path,self.res_path,self.cls_path,self.crop_path,
self.det_train_path,self.det_val_path,
self.res_train_path,self.res_val_path,
self.cls_train_path,self.cls_val_path
]
for path in ls:
if not os.path.exists(path): os.mkdir(path)
def order_points(self, pts):
"""顺时针排序box四个点"""
pts = np.float32(pts)
center = np.array([0,0])
for i in range(4):
center = center + pts[i]
center = center / 4
# 水平框
left,right = [],[]
for i in range(4): left.append(pts[i]) if pts[i][0] < center[0] else right.append(pts[i])
if len(left) == len(right):
tl = left[0] if left[0][1] < left[1][1] else left[1]
tr = right[0] if right[0][1] < right[1][1] else right[1]
bl = left[1] if left[0][1] < left[1][1] else left[0]
br = right[1] if right[0][1] < right[1][1] else right[0]
else:
# 竖直框
top,bottom = [],[]
for i in range(4): top.append(pts[i]) if pts[i][1] < center[1] else bottom.append(pts[i])
tl = top[0] if top[0][0] < top[1][0] else top[1]
tr = top[1] if top[0][0] < top[1][0] else top[0]
bl = bottom[0] if bottom[0][0] < bottom[1][0] else bottom[1]
br = bottom[1] if bottom[0][0] < bottom[1][0] else bottom[0]
point = np.float32([tl, tr, br, bl])
return point
def get_rotate_crop_image(self, img, points):
"""
将给定四个点围成的区域裁剪下来并矫正
points = np.float32([[651.1627906976745, 2154.883720930233], [914.4186046511628, 2158.139534883721],
[907.9069767441861, 2214.883720930233], [647.4418604651163, 2208.837209302326]])
"""
img_crop_width = int(
max(
np.linalg.norm(points[0] - points[1]),
np.linalg.norm(points[2] - points[3])))
img_crop_height = int(
max(
np.linalg.norm(points[0] - points[3]),
np.linalg.norm(points[1] - points[2])))
pts_std = np.float32([[0, 0], [img_crop_width, 0],[img_crop_width, img_crop_height],
[0, img_crop_height]])
M = cv2.getPerspectiveTransform(points, pts_std)
dst_img = cv2.warpPerspective(
img,
M, (img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC)
dst_img_height, dst_img_width = dst_img.shape[0:2]
if dst_img_height * 1.0 / dst_img_width > 1:
dst_img = np.rot90(dst_img)
return dst_img
def json_to_txt(self, filename, flag, f):
"""将json转成文本检测要求的txt文件"""
fcrop = open(os.path.join(self.root_path, 'crop.txt'), 'a', encoding='utf-8')
with open(filename, encoding='utf-8') as data:
label = json.load(data)
# list_target = []
target = ''
ls = []
shapes = label['shapes']
img = label['imagePath'].split('.')[0]+'.jpg' # 图片名
for i,item in enumerate(shapes):
# 处理points
pts = item['points'] # 标注点
if len(pts) != 4:
continue
points = self.order_points(pts)
# 裁切图片
image = cv2.imread(os.path.join(self.data_path, img)) # cv2读入后图片为BGR格式
img_crop = self.get_rotate_crop_image(image, points)
crop_name = img.split('.')[0] + f'_crop_{str(i)}' + '.jpg'
cv2.imwrite(os.path.join(self.crop_path,crop_name), img_crop)
name = item['label']
crop_line = f'{crop_name}\t{name}\n'
fcrop.write(crop_line)
# 存标注点信息
dic = {}
dic['transcription'] = name
dic['points'] = points.tolist()
ls.append(json.dumps(dic,ensure_ascii=False))
ls = ','.join(ls)
line = f'{flag}/{img}\t[{ls}]\n'
f.write(line)
fcrop.close()
def make_detdata(self):
"""划分文本检测数据集"""
seed = [2]
ftrain = open(os.path.join(self.det_path, 'det_train_label.txt'), 'a', encoding='utf-8')
fval = open(os.path.join(self.det_path, 'det_val_label.txt'), 'a', encoding='utf-8')
for i, filename in enumerate(os.listdir(self.json_path)):
flag = 'val' if (i + 1) % 10 in seed else 'train' # 划分train和val,10张里取一张作为val
img = filename.replace('.json', '.jpg')
# 移动图片
from_path = os.path.join(self.data_path, img)
shutil.copy(from_path, self.det_val_path) if flag == 'val' else shutil.copy(from_path, self.det_train_path)
# 存标注信息
json_file = os.path.join(self.json_path, filename)
self.json_to_txt(json_file, flag, fval) if flag == 'val' else self.json_to_txt(json_file, flag, ftrain)
ftrain.close()
fval.close()
print("--------det数据集制作并划分完成--------")
def make_resdata(self):
seed = [1,6,8]
ftrain = open(os.path.join(self.res_path, 'res_train_label.txt'), 'a', encoding='utf-8')
fval = open(os.path.join(self.res_path, 'res_val_label.txt'), 'a', encoding='utf-8')
with open(os.path.join(self.root_path, 'crop.txt'), 'r', encoding='utf-8') as f:
lines = f.readlines()
for i,line in enumerate(lines):
flag = 'val' if (i + 1) % 10 in seed else 'train' # 划分train和val,10张里取一张作为val
img, _ = line.split('\t')
line = f'{flag}/{line}'
fval.write(line) if flag == 'val' else ftrain.write(line)
from_path = os.path.join(self.crop_path, img)
shutil.copy(from_path, self.res_val_path) if flag == 'val' else shutil.copy(from_path, self.res_train_path)
ftrain.close()
fval.close()
print("--------res数据集制作并划分完成--------")
def make_clsdata(self):
seed = [1,6,8]
ftrain = open(os.path.join(self.cls_path, 'cls_train_label.txt'), 'a', encoding='utf-8')
fval = open(os.path.join(self.cls_path, 'cls_val_label.txt'), 'a', encoding='utf-8')
with open(os.path.join(self.root_path, 'crop.txt'), 'r', encoding='utf-8') as f:
lines = f.readlines()
for i,line in enumerate(lines):
flag = 'val' if (i + 1) % 10 in seed else 'train' # 划分train和val,10张里取一张作为val
img, _ = line.split('\t')
path = os.path.join(self.crop_path,'0')
if os.path.exists(os.path.join(path,img)):
label = '0'
else:
label = '180'
path = os.path.join(self.crop_path,'180')
line = f'{flag}/{img}\t{label}\n'
fval.write(line) if flag == 'val' else ftrain.write(line)
from_path = os.path.join(path, img)
shutil.copy(from_path, self.cls_val_path) if flag == 'val' else shutil.copy(from_path, self.cls_train_path)
ftrain.close()
fval.close()
print("--------cls数据集制作并划分完成--------")
def forward(self):
self.make_detdata()
self.make_resdata()
# self.make_clsdata()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--data_path', default='home/data/1', type=str, help='iamges path')
args = parser.parse_args()
dataset = paddle_datasets(args.data_path)
dataset.forward()
制作完成后,home/data目录如下:

det_data下:

![]()
res_data下:

![]()
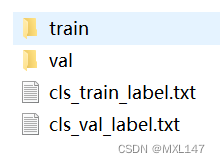
crop中是所有裁剪下来的图片,自己判断下文字的方向,将其分成两类:0和180。

将self.make_clsdata()取注,将self.make_detdata()和self.make_resdata()注掉,再次运行,得到cls_data文件夹,内容如下: