项目目录结构
链接:https://pan.baidu.com/s/1wbZvvonRBL3xy7xO3w57eA
提取码:8888
开源项目链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/doc/doc_en/recognition_en.md
数据集准备
label
路径 识别的内容
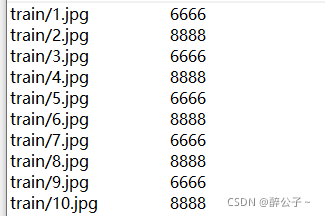
img
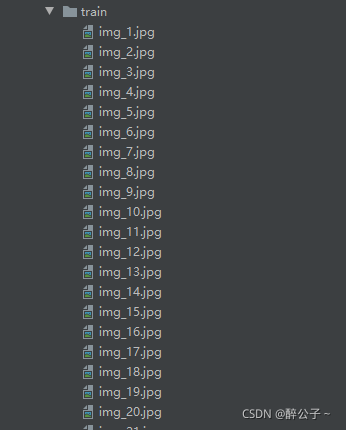
当然你的图片名称要和你label里面的内容 一 一 对应。
参数修改
配置文件所在位置:
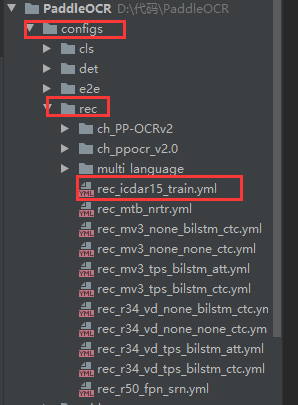
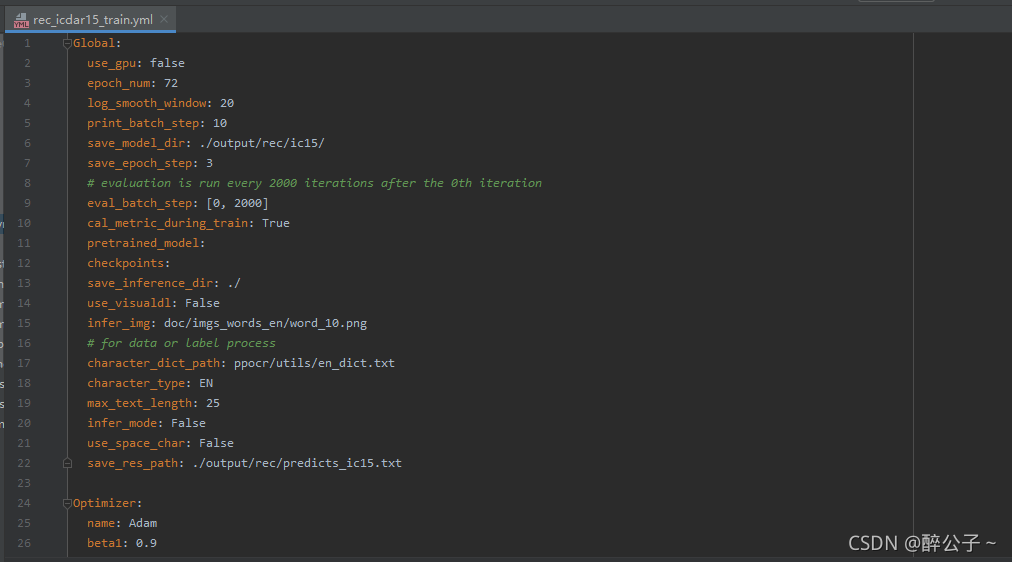
训练
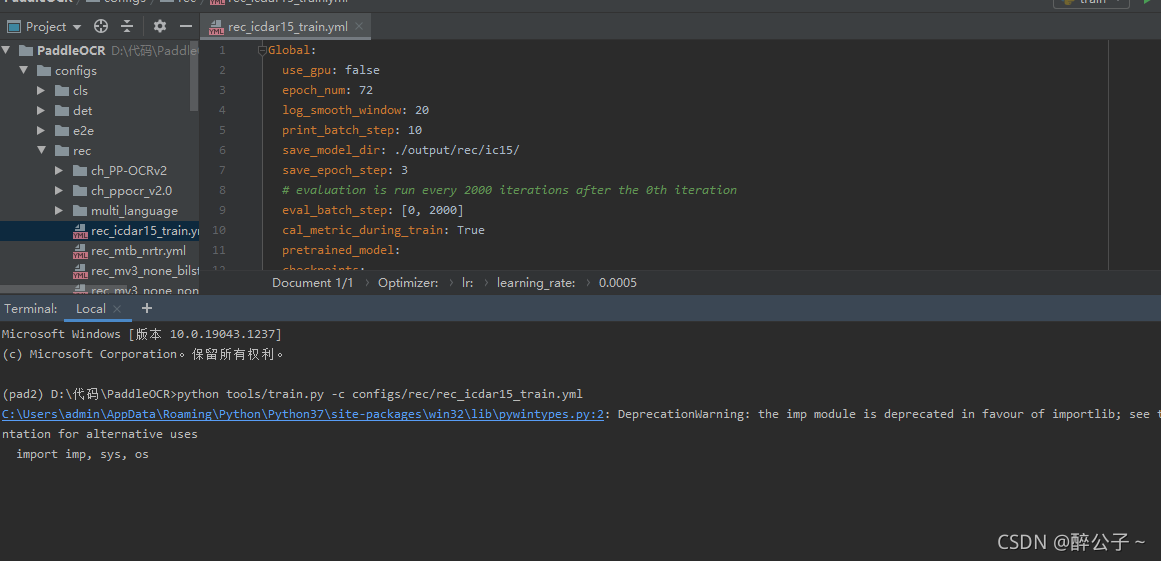
如果前面的内容都没有问题的话
在终端输入
python tools/train.py -c configs/rec/rec_icdar15_train.yml
文字识别板块使用GPU很快速的!
预测
python tools/infer_rec.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./output/rec_CRNN/best_accuracy Global.infer_img=/home/song/wk_test/home/aistudio/PaddleOCR/iimg/213_3.jpg

checkpoints参数在这里是你加载的三个配置权重模型,paddle训练完有三个文件,这里加载的时最好的模型(paddle会自动根据你所设置的文件名称对应加载相应的模型)
infer_img 参数在这里是你要预测的图片
希望这篇文章对你有用!
谢谢点赞评论!