目录
前言
由于官方提供的Paddleocr模型是一个通用的OCR识别模型,在很多的日常的场景中识别准确还是可以的,但是在一些比较特殊的场景中,识别的精确度就不是很好。如果要让我们的模型更加符合自己的业务需要,那么就需要训练我们自己的OCR识别模型。OCR识别分为文本检测和文本识别,文本检测就是让模型找到文字所在的位置,而文本识别是在文本检测到的位置上进行文本识别。训练自己的模型第一步就是需要数据集,从理论上来说,只要给模型喂入数据集越庞大那么,那么模型的效果就会越好。
对于精度要求不高的场景,检测任务和识别任务需要的数据量是不一样的。对于检测任务,500张图像可以保证基本的检测效果。对于识别任务,需要保证识别字典中每个字符出现在不同场景的行文本图像数目需要大于200张(举例,如果有字典中有5个字,每个字都需要出现在200张图片以上,那么最少要求的图像数量应该在200-1000张之间),这样可以保证基本的识别效果。
由此可见文本识别所需要的数据集要比文本检测的数据集大的多的多。因此我们不仅要获得大量的真实数据,而且还要合成大量的数据。百度官方通用模型中的文本识别模型用了520W左右的数据集(真实数据26W+合成数据500W)。所以该文章就来讲讲怎么批量合成文本识别模型的数据集。
一、数据集的总体概括
1.1 训练集和测试集
训练OCR文本识别模型的数据集是训练集和测试集组成的测试集和训练集应有如下文件结构:
训练集的文件结构:
|-train_data
|-rec
|- rec_gt_train.txt
|- train
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...测试集的文件结构:
|-train_data
|-rec
|- rec_gt_test.txt
|- test
|- word_001.jpg
|- word_002.jpg
|- word_003.jpg
| ...其实测试集和训练的文件结构是相同的,都是由图片文件和标签文件所组成的。标签内容如下所示:
" 图像文件名 图像标注信息 "
train_data/rec/train/word_001.jpg 简单可依赖
train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单标签文件的左边记录的是图片文件里面的保存路径,方便模型在训练的时候找到对应的图片,文件的右边记录的是对应路径下的图片文件的标签,就是文本识别的内容。让我们来直观的感受一下图片的图片和标签


由上图可以很直观的看到数据集里面的图片文件和里面的图片文件和对应的标签文件。
1.2 文本识别所需字典
文本识别需要一个字典,使模型在训练时,可以将所有出现的字符映射为字典的索引。因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 utf-8 编码格式保存:

word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“and” 将被映射成 [2 5 1]
因此要训练我们自己的文本识别模型的训练就需要两个东西,一个是数据集,一个是希望被正确识别的字符的字典。废话不多说,就让我们开始数据集的合成还有字典的制作吧。
二、文本识别数据集的合成前期准备
2.1 数据集合成概括
首先文本识别数据集的合成需要两个东西,一个是文本语料,一个是目标场景图片,如下图所示,可以很直观的知道数据集的合成是怎么做的,就是将输入的文本语料通过文本风格迁移到指定的背景模板中。


2.2 语料和目标场景图像模板的准备和处理
之所以要训练我们自己的模型,就是因为百度的官方模型不适合某些特定的场景,比如我现在所做的船号识别项目,就是要识别船舶号,所以就会有对应的语料,如图所示:

这些语料大家通过自己的项目需求去获取,可以通过爬虫或者别的手段,总之我们要大量的语料来合成数据。
下面就是对语料数据进行处理了,首先将语料数据里面的汉子和数字分开,分成如下图所示 :

有些人会问,为什么要把汉字和数字分开呢,因为我在合成的时候发现,汉字和数字在一行的时候合成的效果特别差,就合成不了数字,大家仔细看下下面两图的对比,发现汉字是可以合成的,但是后面的数字的合成效果是很差的。


而数字和汉字分开,合成的效果就会很好,如下图所示:
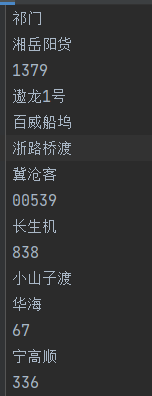

所以我们要将语料中的数字和汉字分开去合成数据集。
2.3 制作语料
我这里有一份原始的语料,都是关于船舶号的,上面已经给大家展示过了。现在我们的第一件事就是将数字和汉字分开,可以用以下脚本进行处理:
# 以只读模式读取文件
file = open("C:/Users/86159/Desktop/number.txt", "r", encoding='utf-8')
# 创建一个列表
lines = []
# 逐行将文本存入列表lines中
for i in file:
lines.append(i)
file.close()
# 创建一个新的列表
new = []
# 逐行遍历,将列表中的每一个元素中的数字和特殊符号剔除
for line in lines:
line = line.replace('0', '')
line = line.replace('1', '')
line = line.replace('2', '')
line = line.replace('3', '')
line = line.replace('4', '')
line = line.replace('5', '')
line = line.replace('6', '')
line = line.replace('7', '')
line = line.replace('8', '')
line = line.replace('9', '')
line = line.replace('-', '')
line = line.replace('.', '')
line = line.replace('#', '')
new.append(line)
# 将剔除数字和特殊符号的列表转化为集合,这样可以将剔除字母和特殊符号的汉字去重
# 集合中可以将重复元素去重
new = list(set(new))
# print(new)
# 以写的方式打开文件,如果文件不存在,就会自动创建,如果存在就会覆盖原文件
file_write_obj = open("C:/Users/86159/Desktop/number1.txt", 'w')
# 将处理完的列表写到一个新的txt文件中
for var in new:
file_write_obj.writelines(var)
# file_write_obj.writelines('\n')
file_write_obj.close()原始数据和处理完的数据对比:


可以看到语料中的数字已经被剔除了(包括一些不必要的特殊符号),下面就需要将原始语料数据中的数字提取出来。脚本如下:
import re
# 以只读模式读取文件
file = open("C:/Users/86159/Desktop/number.txt", "r", encoding='utf-8')
# 创建一个列表
lines = []
# 逐行将文本存入列表lines中
for i in file:
lines.append(i)
file.close()
# 创建一个新的列表
new = []
# 逐行遍历,将每行中的数字提取出来,放入到新的列表中
for line in lines:
pattern = re.compile(r'\d+')
res = re.findall(pattern, line)
for a in res:
new.append(a)
# 将列表转化为集合,将列表中的重复内容去重,再转化为列表
new = list(set(new))
# 以写的方式打开文件,如果文件不存在,就会自动创建,如果存在就会覆盖原文件
file_write_obj = open("C:/Users/86159/Desktop/number2.txt", 'w')
for var in new:
file_write_obj.writelines(var)
file_write_obj.writelines('\n')
file_write_obj.close()
如下图所示,提取的数字去重后如下图。

将去除数字的汉字文本和去除汉字的数字文本合并起来,然后将文本打乱(生成的语料文本就没有规律了,这样比较科学),合成语料文本脚本如下:
# 以只读模式读取文件
import random
file1 = open("C:/Users/86159/Desktop/number1.txt", "r", encoding='utf-8')
file2 = open("C:/Users/86159/Desktop/number2.txt", "r", encoding='utf-8')
# 创建一个列表
lines = []
# 逐行将文本存入列表lines中
for i in file1:
lines.append(i)
file1.close()
for i in file2:
lines.append(i)
file2.close()
random.shuffle(lines)
print(lines)
# 以写的方式打开文件,如果文件不存在,就会自动创建,如果存在就会覆盖原文件
file_write_obj = open("C:/Users/86159/Desktop/number3.txt", 'w')
for var in lines:
file_write_obj.writelines(var)
# file_write_obj.writelines('\n')
file_write_obj.close()如果出现如下错误,则是因为刚刚生成的两个txt文档是ANSI格式的,我打开刚刚生成的两个文档,将txt文件另保存为UTF-8格式。


生成如下的语料文本,至此准备语料文本已经结束 :

2.4 制作字典
因为语料文本已经制作完成,该语料中每一个字都需要出现在字典中,所以我们需要将语料中的每一个出现的字都提取到字典中。提取字典的脚本如下:
# 以只读模式读取文件
file = open("C:/Users/86159/Desktop/number3.txt", "r", encoding='utf-8')
# 创建一个列表
lines = []
# 逐行将文本存入列表lines中
for i in file:
lines.append(i)
file.close()
# print(lines)
# 创建一个新的列表
new = []
# 将列表中每个元素都拆开放入到列表中
for line in lines:
for i in line:
new.append(i)
# 利用集合的特性将列表中重复的数据剔除,生成一个新的列表
new = list(set(new))
# 以写的方式打开文件,如果文件不存在,就会自动创建,如果存在就会覆盖原文件
file_write_obj = open("C:/Users/86159/Desktop/number4.txt", 'w')
for var in new:
file_write_obj.writelines(var)
file_write_obj.writelines('\n')
file_write_obj.close()生成的字典如下所示(每行只有一个字,这样就可以方便用数字映射了):

注意:该字典只是我们合成数据的字典,一个完整的字典是真实数据的字典和合成数据的字典的总和,这样才能在我们训练完识别模型的时候,对文字进行识别,可以识别出字典中的每个字。
2.5 制作目标场景图像模板
这个步骤就相对比较简单了,合成数据的背景就是真实图片的背景,生成的文字就是真实图片中的文字的风格。因此我们值需要找到真实图片将其处理一下就好了。
首先图片主要支持高度在32左右的风格图像。 如果输入图像尺寸相差过多,效果可能不佳(这个我尝试过用其他尺寸的分辨率,效果特别差,对宽度没有什么过多要求)。而且图片最好是方方正正的那种图,如下那种斜的图,或者歪七劣八的图最好处理成方方正正的图(否则效果极差)。

最好是如下的图,高度为32,里面的字是清晰可见。
![]()
![]()
三、数据集合成
3.1 项目克隆
首先将百度的paddleocr这个开源的项目克隆下来,项目地址。点击克隆就可以将项目的压缩包下载下来。

再去下载数据集合成模型,项目地址。 将下载的style_text_models.zip模型放入到StyleText目录下,并解压。至此之中,项目模型就已经搭建完毕(由于是paddleocr,所以项目是在paddlepaddle框架下,框架和环境的搭建,可以参考我的这一篇文章,利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装---免额外安装CUDA和cudnn(适合小白的保姆级教学))。

3.2 修改配置文件,合成数据集
打开项目中的dataset_config.yml文件,修改该文件中的参数来批量合成数据,

需要修改的yml文件中的参数如下所示:
Global:
output_num: 10 # 输出图片数量,需要根据语料个数和图片木板数量相乘得到
output_dir: output_data # 输出图片的目录,没有系统会自己创建
use_gpu: false # 是否用GPU
image_height: 32
image_width: 320
standard_font: fonts/en_standard.ttf
TextDrawer:
fonts:
en: fonts/en_standard.ttf
ch: fonts/ch_standard.ttf
ko: fonts/ko_standard.ttf
StyleSampler:
method: DatasetSampler # 风格图片模板目录
image_home: examples # 风格图片模板目录
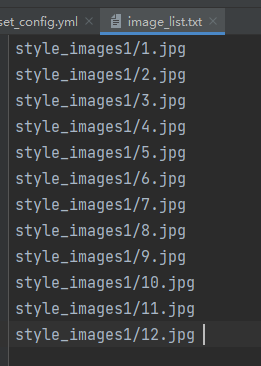
label_file: examples/image_list.txt # 风格图片路径列表文件
with_label: true # 标志label_file是否为label文件。(有没有标签好像影响不大)
CorpusGenerator:
method: FileCorpus # 语料生成方法,目前有FileCorpus和EnNumCorpus可选。
language: ch # 语料的语种,目前支持英文(en)、简体中文(ch)和韩语(ko)
corpus_file: examples/corpus/example.txt # 语料文件路径。语料文件应使用文本文件。语料生成器首先会将语料按行切分,之后每次随机选取一行。
Predictor:
method: StyleTextRecPredictor
algorithm: StyleTextRec
scale: 0.00392156862745098我的语料一共有52877个,风格图片模板一共有12个,所以我的输出图片为634524个,合成的数据图片有63万,足够训练用了。我的yml文件里面的参数如下:

这里来说说我修改的参数,和注意事项:首先我我的语料和图片风格模板相乘为634524,所以我的output_num填写为634524。输出文件夹为output_data,这里我没有修改,就是用的yml文件里面原本的,到时候就会自动给我生成一个这样的文件,里面保存着生成的图片和标签。因为我的电脑是带有GPU的,所以use_gpu我写的是true,建议使用GPU,这样生成的速度会快很多。除了以上参数,其他的就不要动。

而下面的一部分修改的话,我是在examples目录下自己创建了一个style_images1目录来放风格的照片,然后再image_list.txt这个文件里面将图片的路径写进去,这样就会根据文件中的路径去读取我们的风格背景照片。(这里要注意的是如果你的风格图片没有标签的话,with_label一定要写false,要不然会报错,事实上不必带有把标签写进去,因为有没有标签好像效果都一样(我做过尝试))


method为料生成方法,目前有FileCorpus和EnNumCorpus可选。如果使用EnNumCorpus(语料里面只有字母和数字,这个方法只可以生成数字和字母,识别不了其他的),则不需要填写其他配置,否则需要修改corpus_file和language;我们这里是生成汉字,所以选择method为FileCorpus,language选的是ch,但是语料的语种,目前支持英文(en)、简体中文(ch)和韩语(ko);corpus_file为语料文件路径。语料文件应使用文本文件。语料生成器首先会将语料按行切分,之后每次随机选取一行。


至此,我们的参数就都修改完毕了,就可以运行代码生成图片了,我们首先要进入StyleText路径下面,因为我们的生成图片的模型代码和所以的文件都在这个目录下面,我用的是pycharm这款IDE,在终端控制台进入到该目录下

然后运行以下的命令就可以进行图像的合成了
python tools/synth_dataset.py -c configs/dataset_config.yml![]()
这里要注意的是第一次运行的时候可能会报错如下,这是因为我们的代码识别不了语料文件里面的中文。

 解决的方法是点开报错上面的那行路径链接。到了corpus_generators.py这个代码里面,在代码的第28行,将下图中红色框框里面的代码加上即可解决问题。
解决的方法是点开报错上面的那行路径链接。到了corpus_generators.py这个代码里面,在代码的第28行,将下图中红色框框里面的代码加上即可解决问题。

3.3 查看生成的数据
最后在output_data生成我们的合成图片和图片的标签
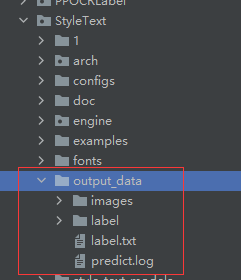
生成的图片(部分)展示

标签(部分)为如下所示:

至此我们的所有工作都完成了。生成的图片和标签就可以直接用来进行OCR文件识别模型的训练了。