使用Transformers架构构建大型语言模型显著提高了自然语言任务的性能,超过了之前的RNNs,并导致了再生能力的爆炸。
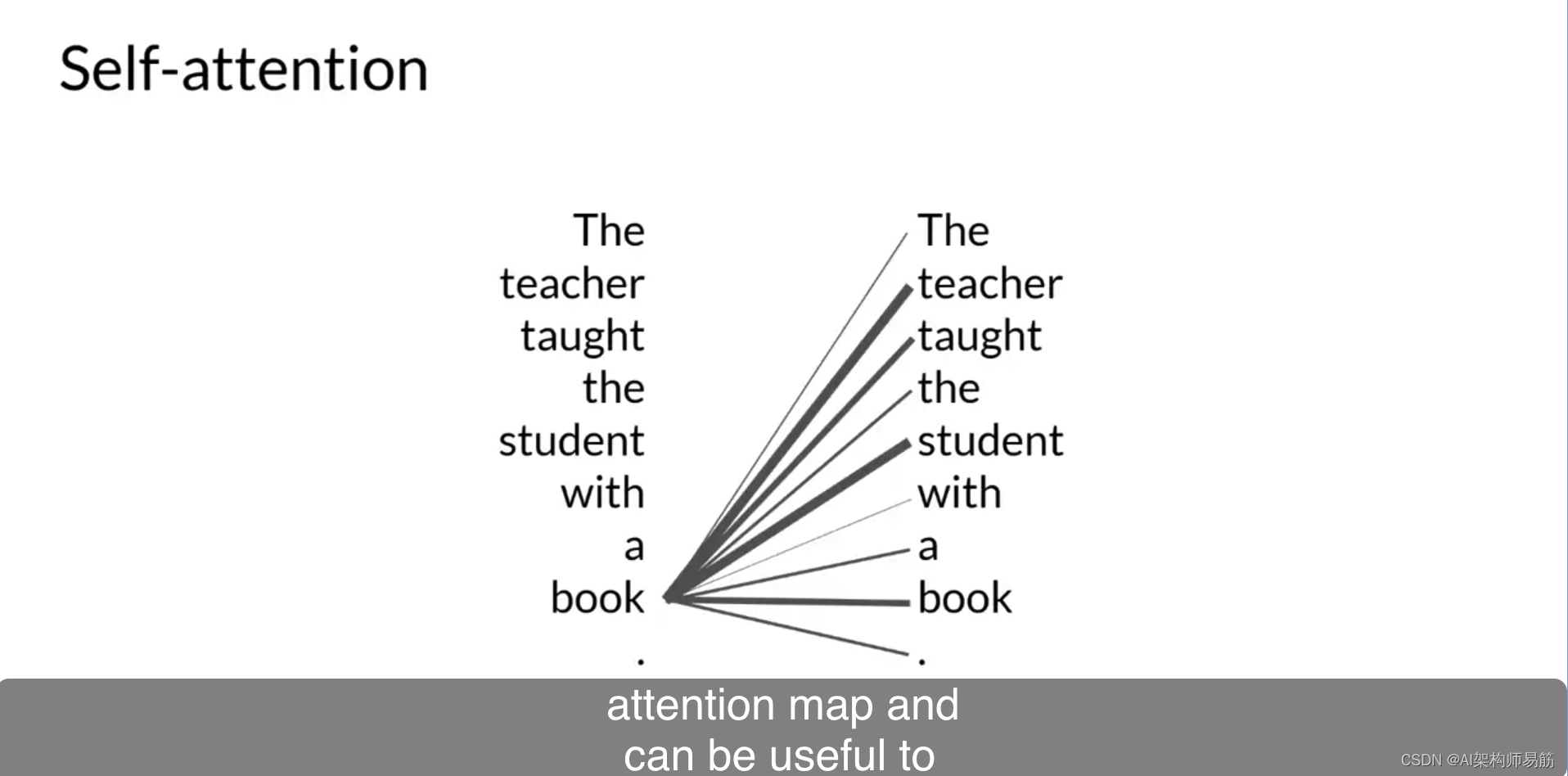
Transformers架构的力量在于其学习句子中所有单词的相关性和上下文的能力。不仅仅是您在这里看到的,与它的邻居每个词相邻,而是与句子中的每个其他词。将注意力权重应用于这些关系,以便模型学习每个词与输入中的其他词的相关性,无论它们在哪里。

这使得算法能够学习谁有这本书,谁可能有这本书,以及它是否与文档的更广泛的上下文相关。这些注意力权重在LLM训练期间学到,您将在本周晚些时候了解更多。


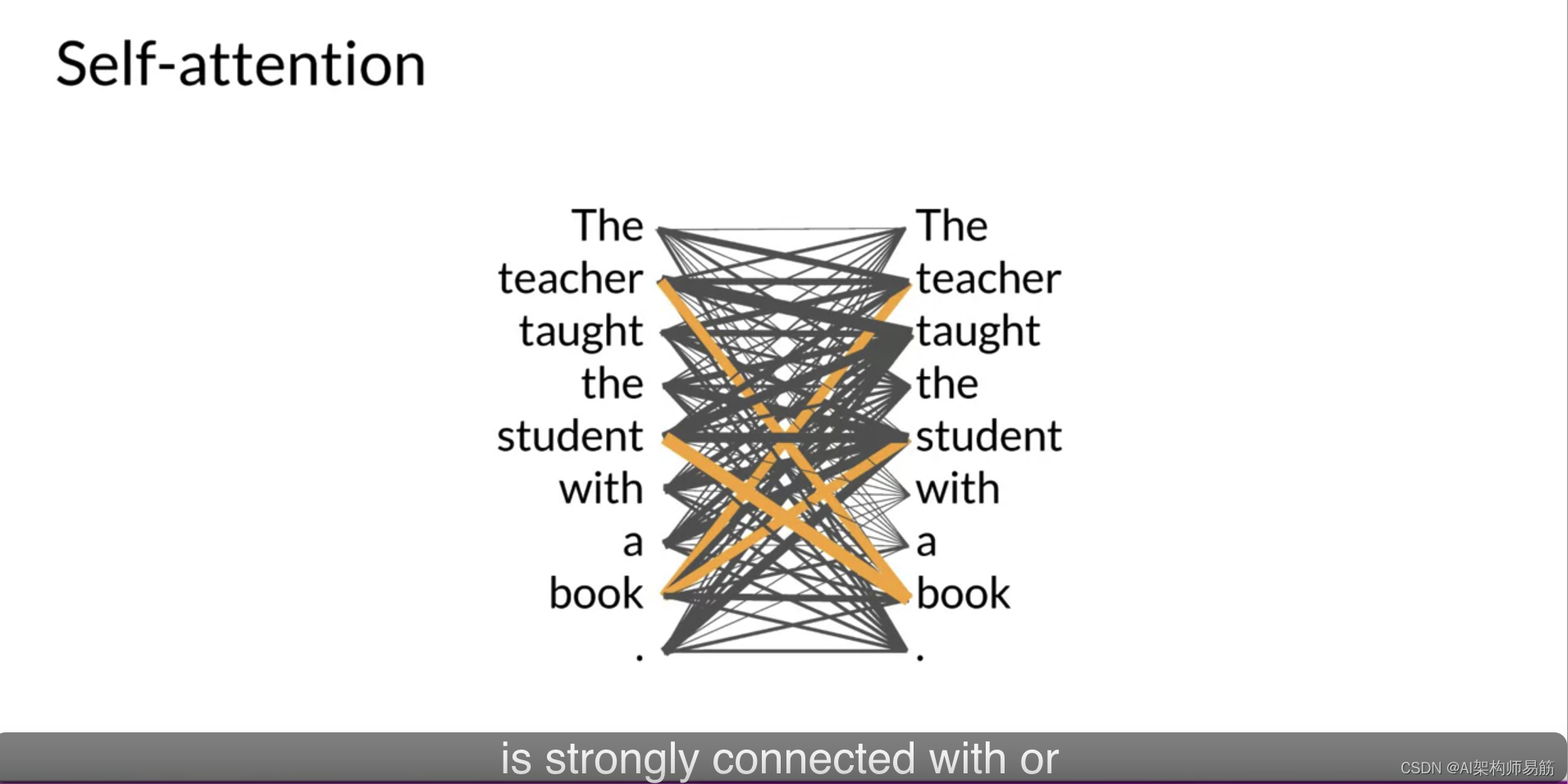
这个图被称为注意力图,可以用来说明每个词与每个其他词之间的注意力权重。在这个风格化的例子中,您可以看到单词“book”与单词“teacher”和“student”强烈地连接或关注。
这被称为自注意力,这种跨整个输入学习注意力的能力显著地提高了模型编码语言的能力。
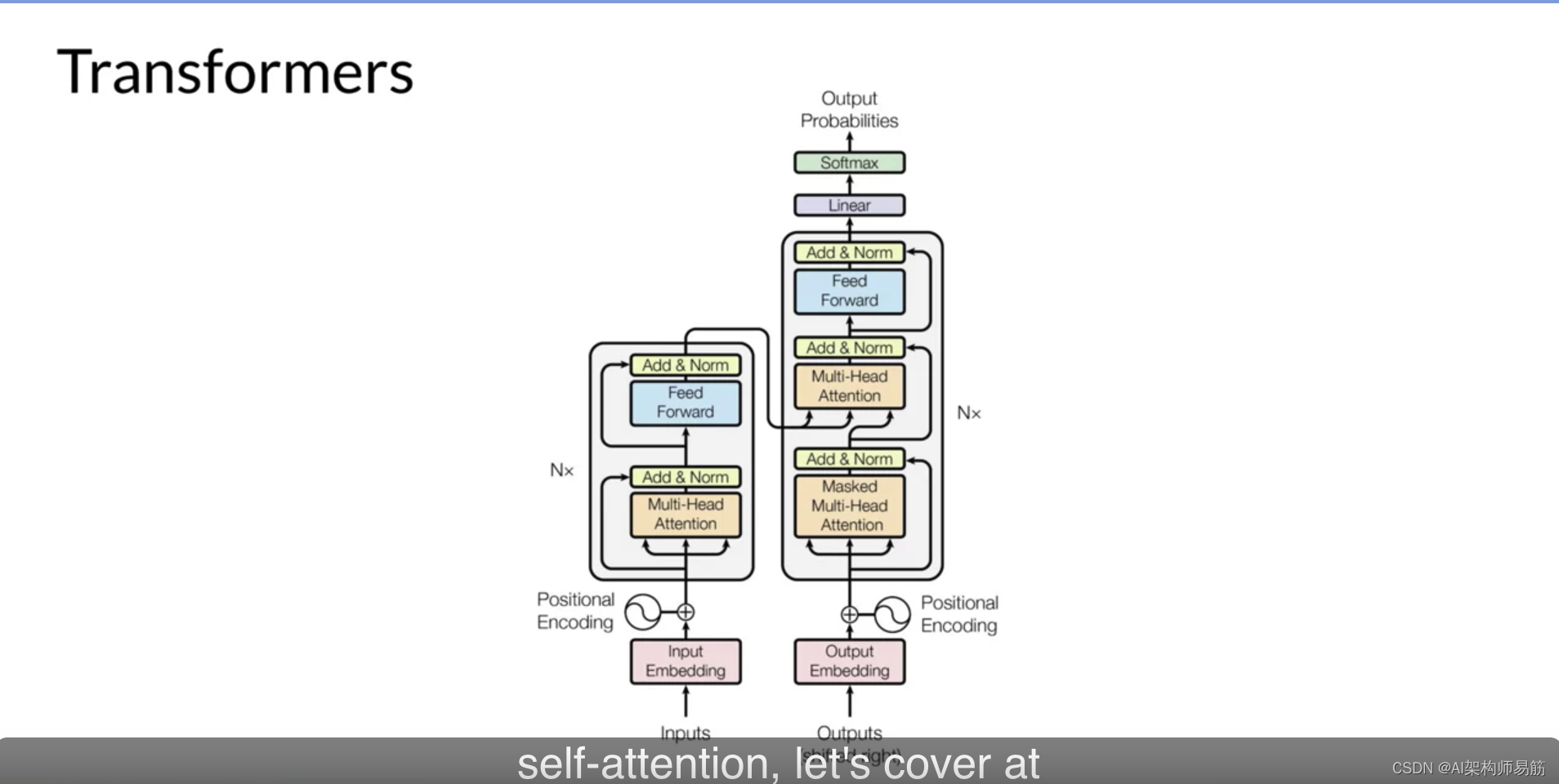
现在您已经看到了Transformers架构的一个关键属性,自注意力,让我们从高层次看看模型是如何工作的。这是一个简化的Transformers架构图,这样您可以从高层次关注这些过程发生的地方。Transformers架构分为两个不同的部分,编码器和解码器。
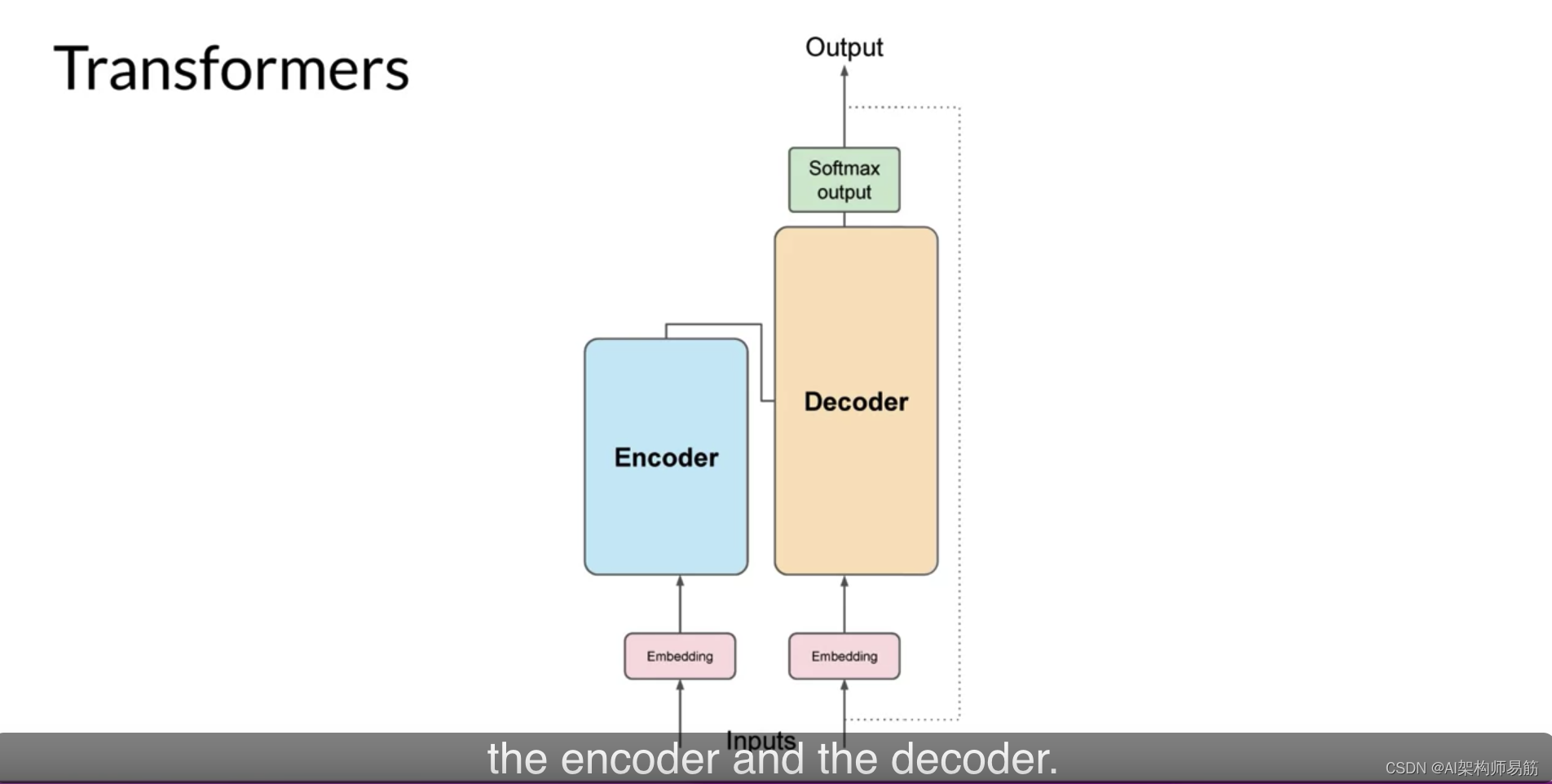
这些组件相互协作,并且它们有许多相似之处。此外,请注意,您在这里看到的图是从原始的“Attention is All You Need”论文中派生出来的。注意模型的输入是在底部,输出是在顶部,在可能的情况下,我们将尝试在整个课程中保持这一点。
现在,机器学习模型只是大型的统计计算器,它们使用数字而不是单词。因此,在将文本传递到模型进行处理之前,您必须首先对单词进行标记。简单地说,这将单词转换为数字,每个数字代表模型可以使用的所有可能单词的字典中的位置。您可以选择多种标记化方法。
例如,匹配两个完整单词的令牌ID,
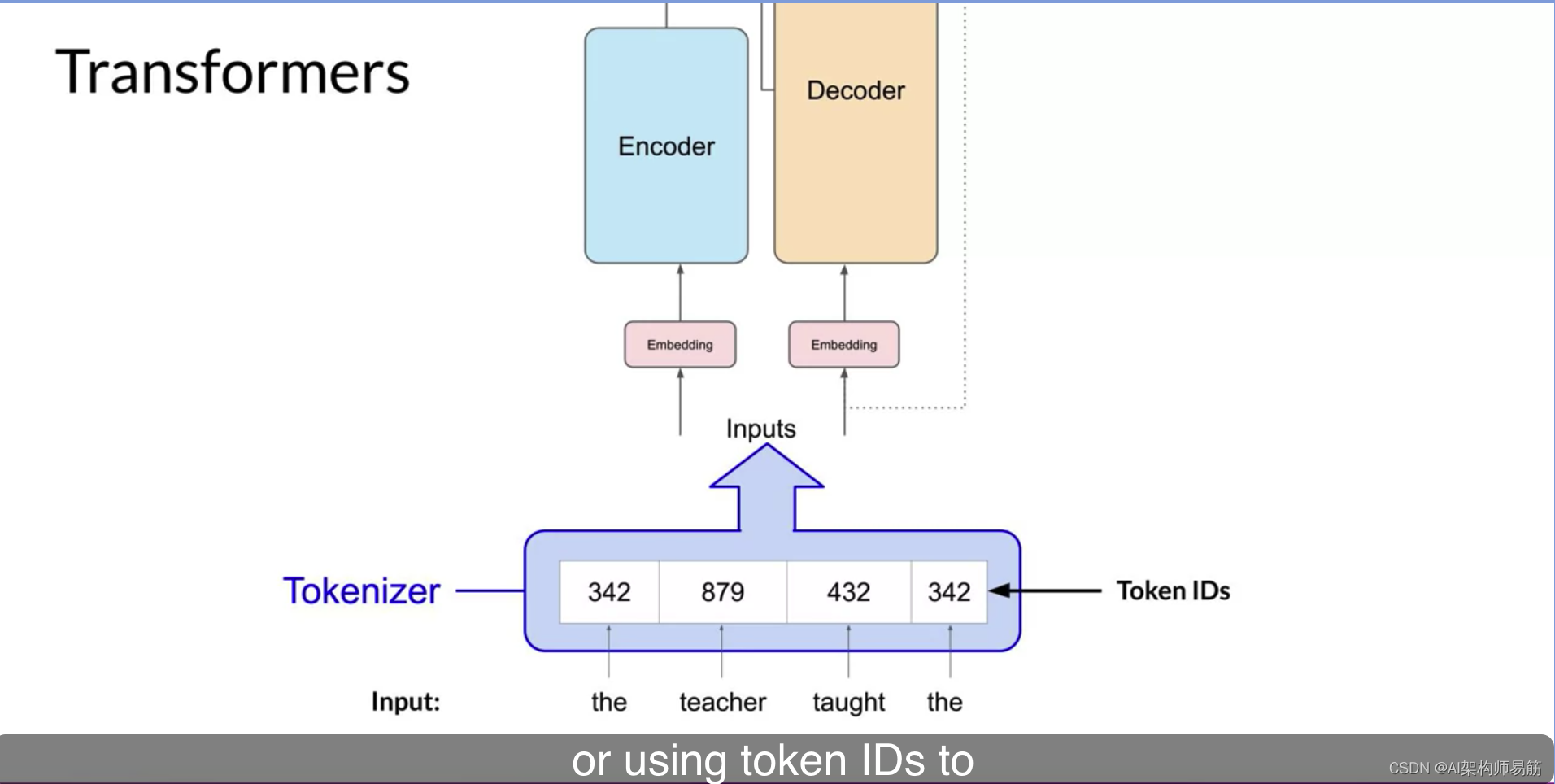
或使用令牌ID表示单词的部分。
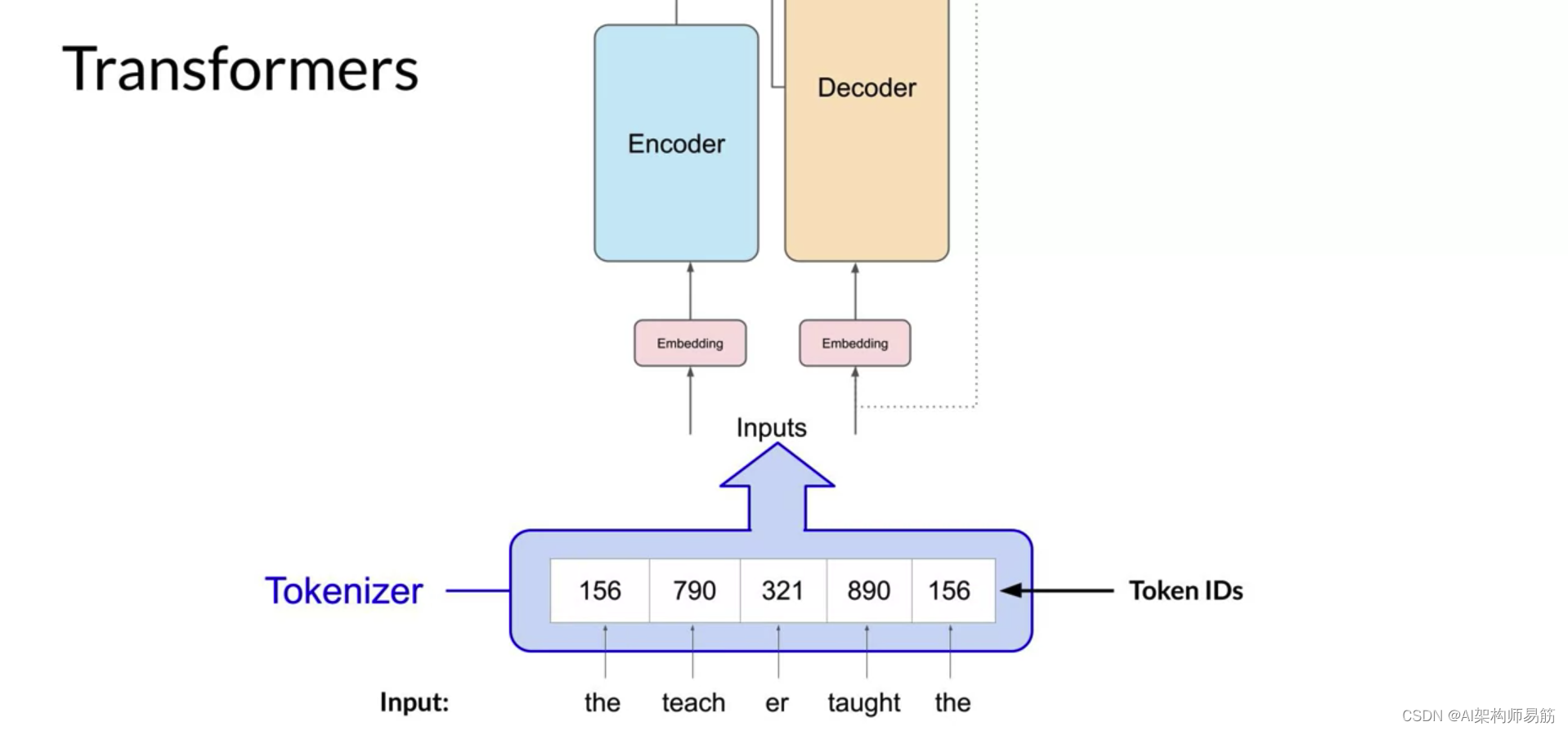
正如您在这里看到的。重要的是,一旦您选择了一个标记器来训练模型,您在生成文本时必须使用相同的标记器。现在您的输入表示为数字,您可以将其传递给嵌入层。这一层是一个可训练的向量嵌入空间,一个高维空间,其中每个令牌都表示为一个向量,并在该空间内占据一个唯一的位置。
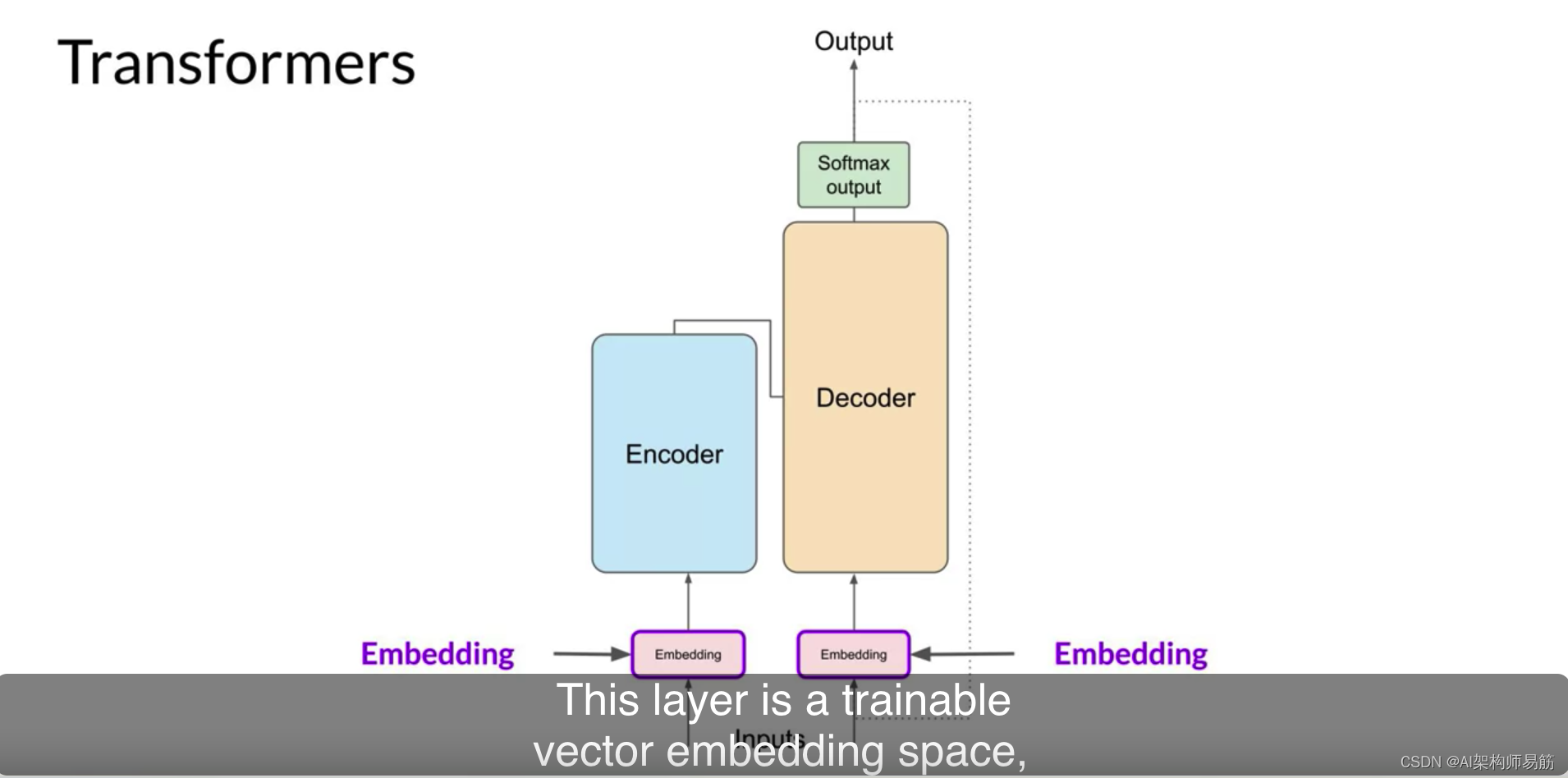
词汇表中的每个令牌ID都与一个多维向量匹配,直觉是这些向量学会编码输入序列中单个令牌的含义和上下文。嵌入向量空间在自然语言处理中已经使用了一段时间,像Word2vec这样的上一代语言算法使用了这个概念。如果您不熟悉这个,不用担心。您将在整个课程中看到这方面的例子,本周末的阅读练习中还有一些链接到其他资源。
回顾样本序列,您可以看到在这个简单的情况下,每个单词都与一个令牌ID匹配,每个令牌都映射到一个向量。在原始的Transformers论文中,向量的大小实际上是512,所以比我们可以放到这个图像上的要大得多。
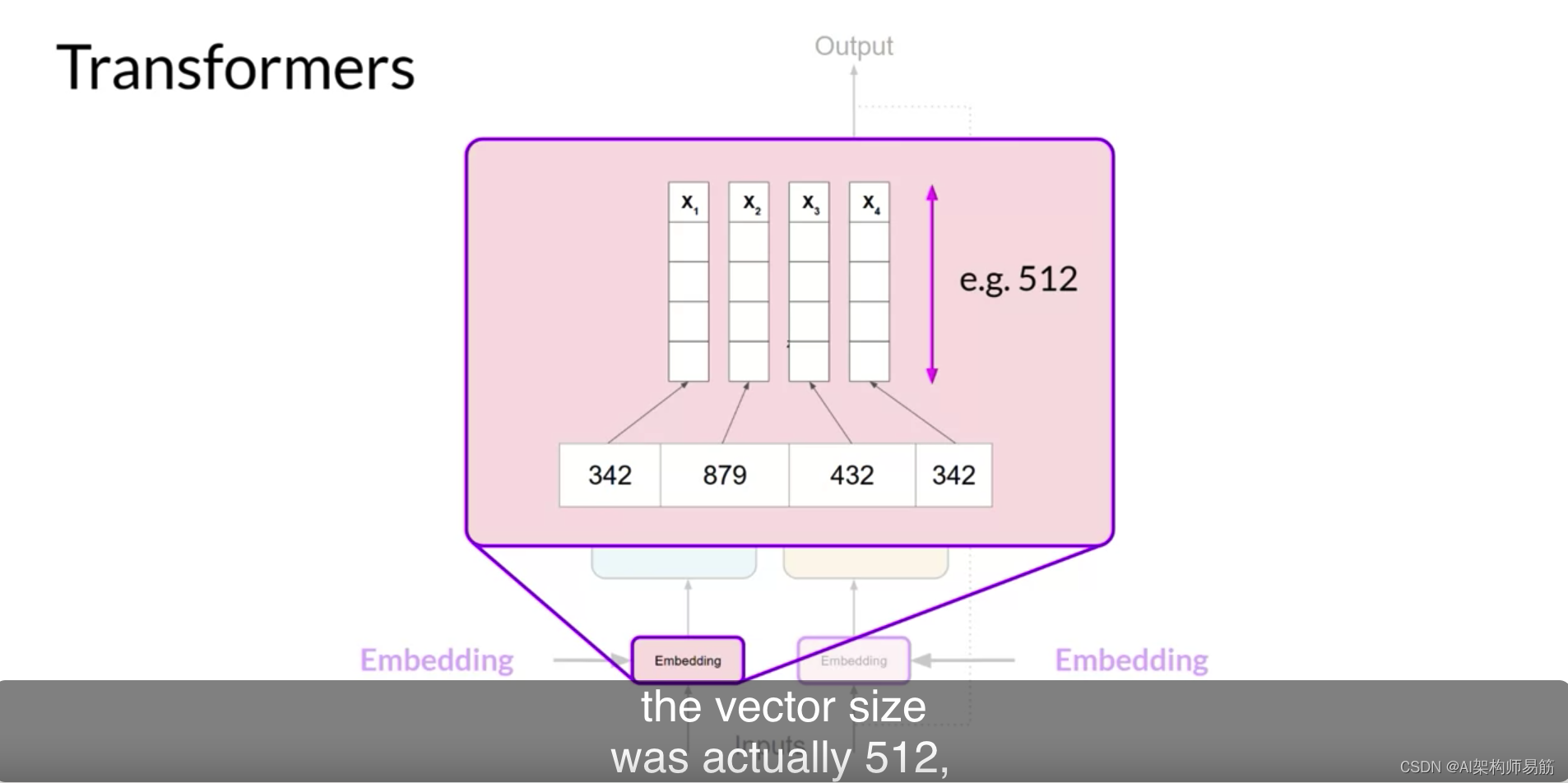
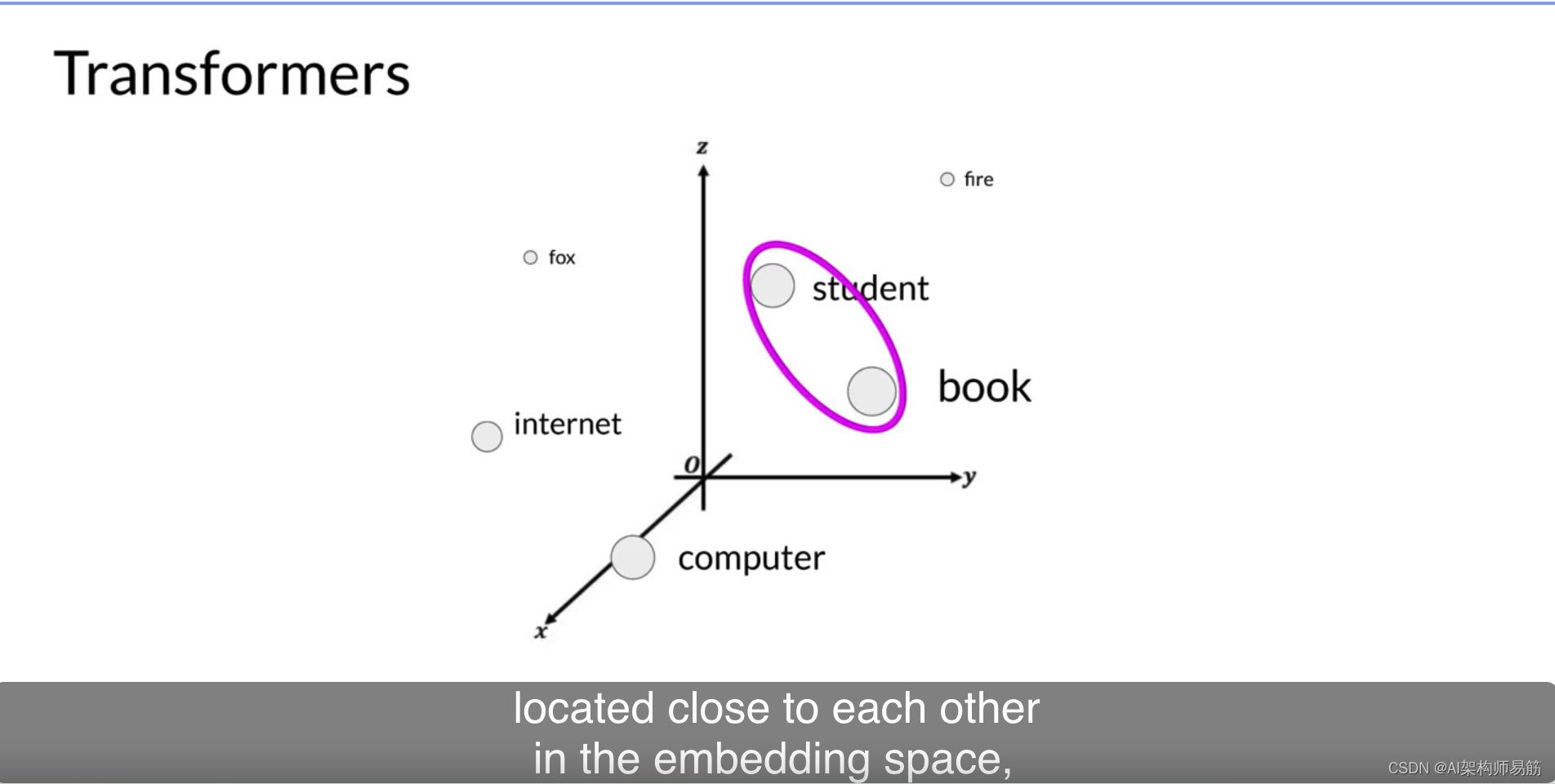
为了简单起见,如果您想象一个向量大小只有三个,您可以将单词绘制到一个三维空间中,并看到这些单词之间的关系。您现在可以看到如何关联嵌入空间中彼此靠近的单词,
以及如何计算单词之间的距离作为一个角度,
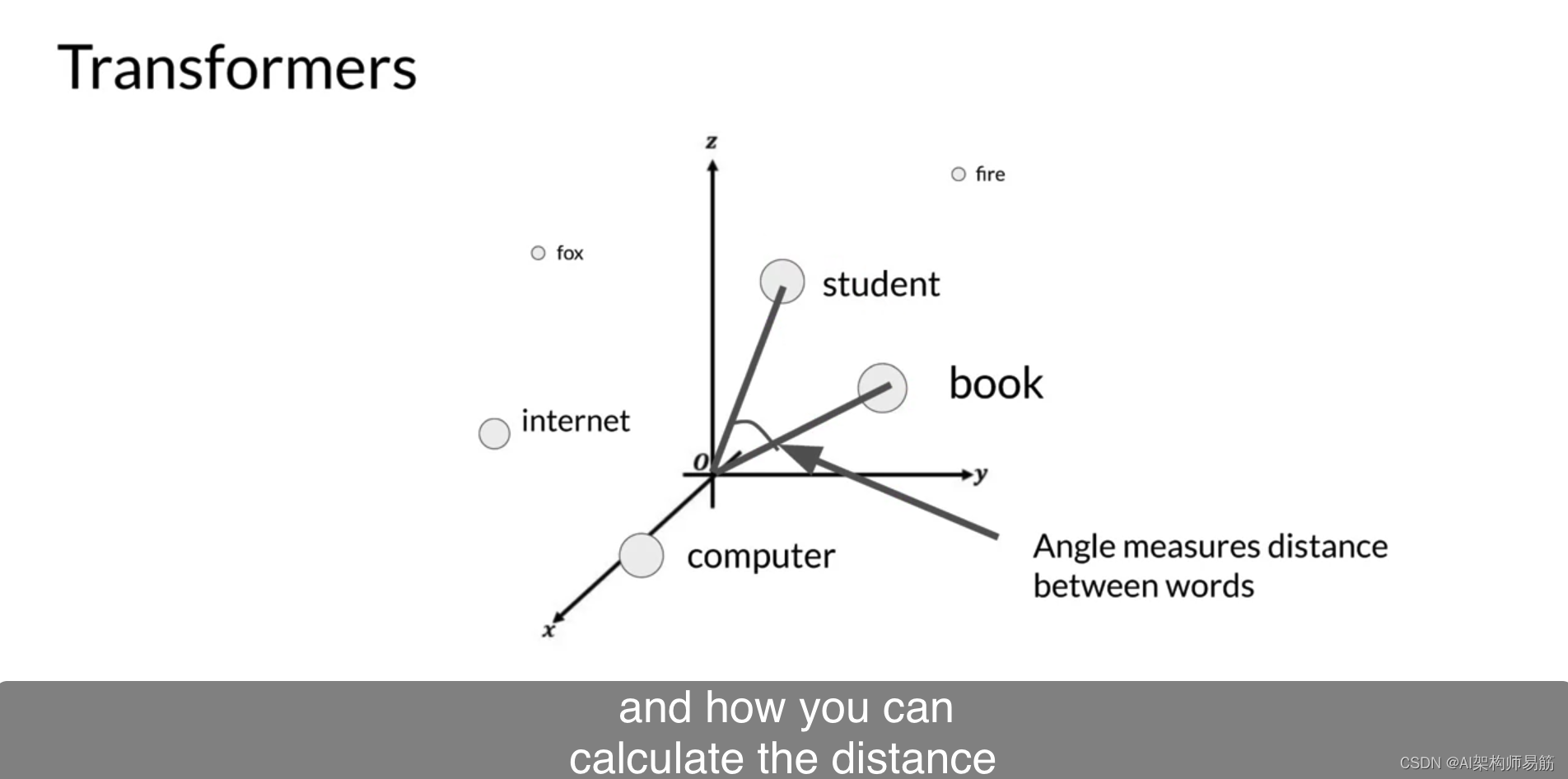
这使得模型具有数学上理解语言的能力。当您将令牌向量添加到编码器或解码器的基础时,您还添加了位置编码。
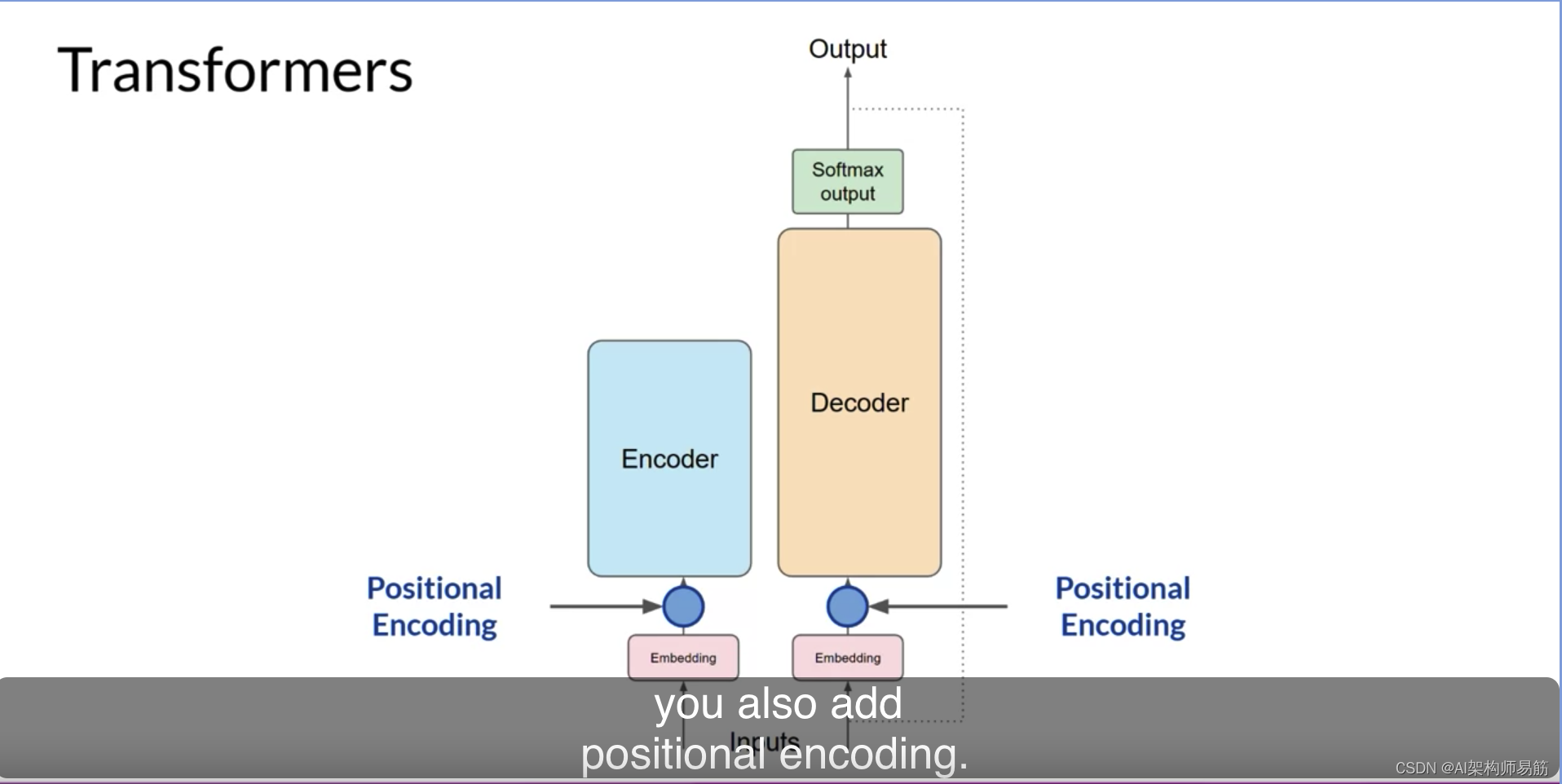
模型并行处理每个输入令牌。因此,通过添加位置编码,您保留了关于单词顺序的信息,并且不会丢失单词在句子中的位置的相关性。一旦您将输入令牌和位置编码相加,您就将结果向量传递给自注意力层。

在这里,模型分析输入序列中的令牌之间的关系。正如您之前看到的,这使得模型能够关注输入序列的不同部分,以更好地捕获单词之间的上下文依赖关系。在训练期间学到并存储在这些层中的自注意力权重反映了输入序列中每个单词与序列中所有其他单词的重要性。
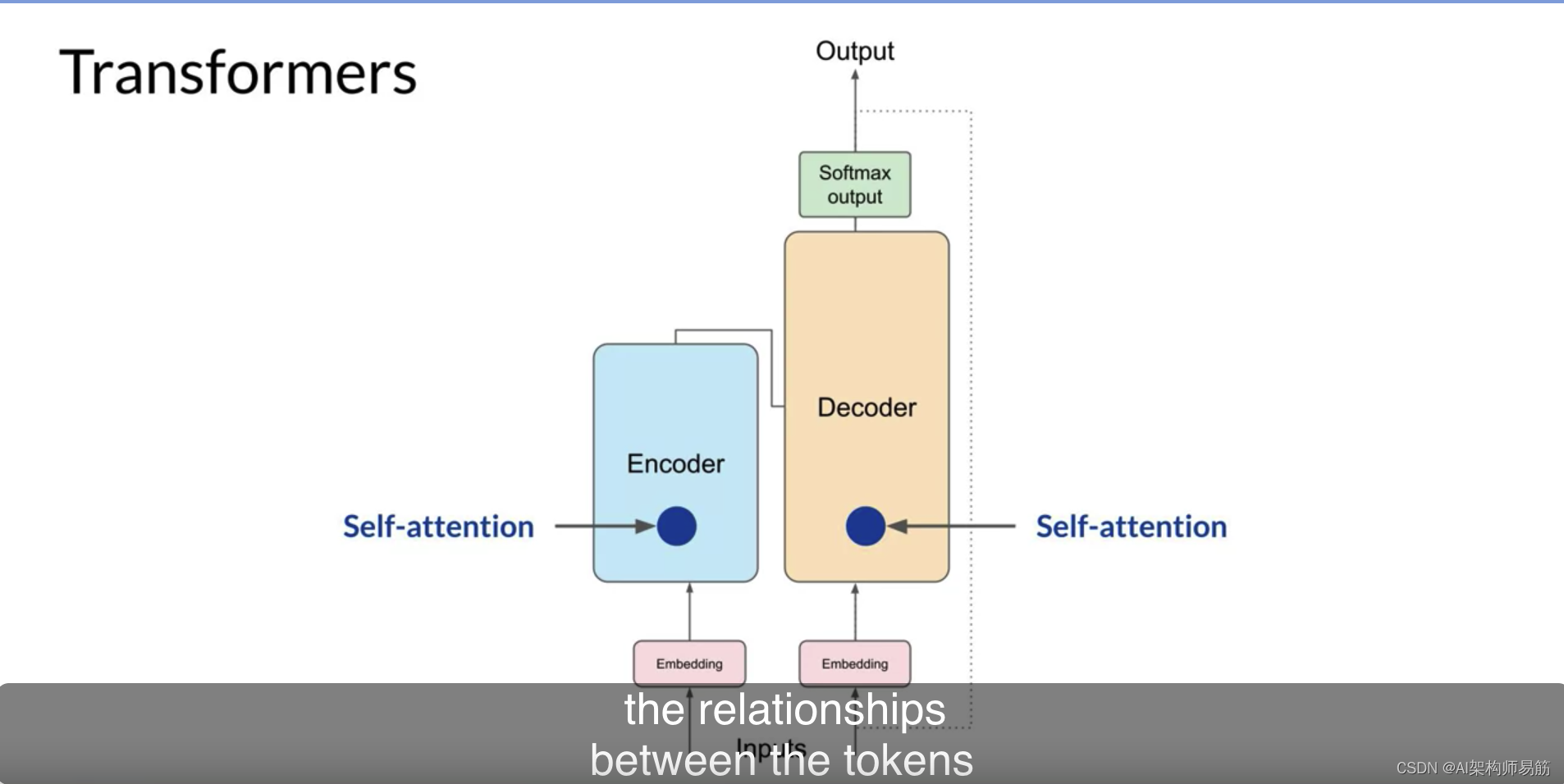
但这不仅仅发生一次,Transformers架构实际上具有多头自注意力。这意味着多组自注意力权重或头部并行独立地学习。注意力层中包括的注意力头数因模型而异,但范围在12-100之间是常见的。
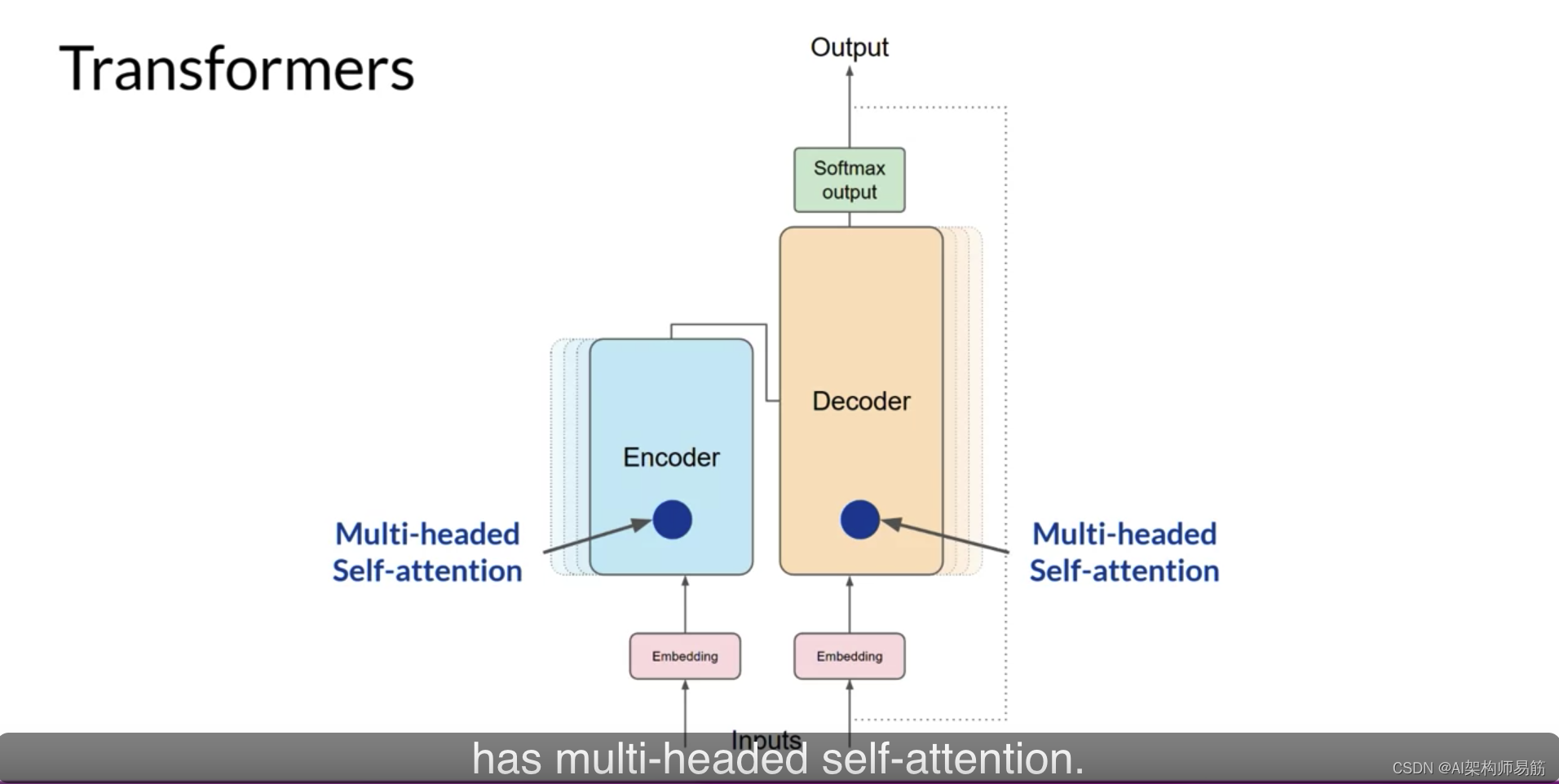
直觉是每个自注意力头将学习语言的不同方面。例如,一个头可能会看到我们句子中的人实体之间的关系。
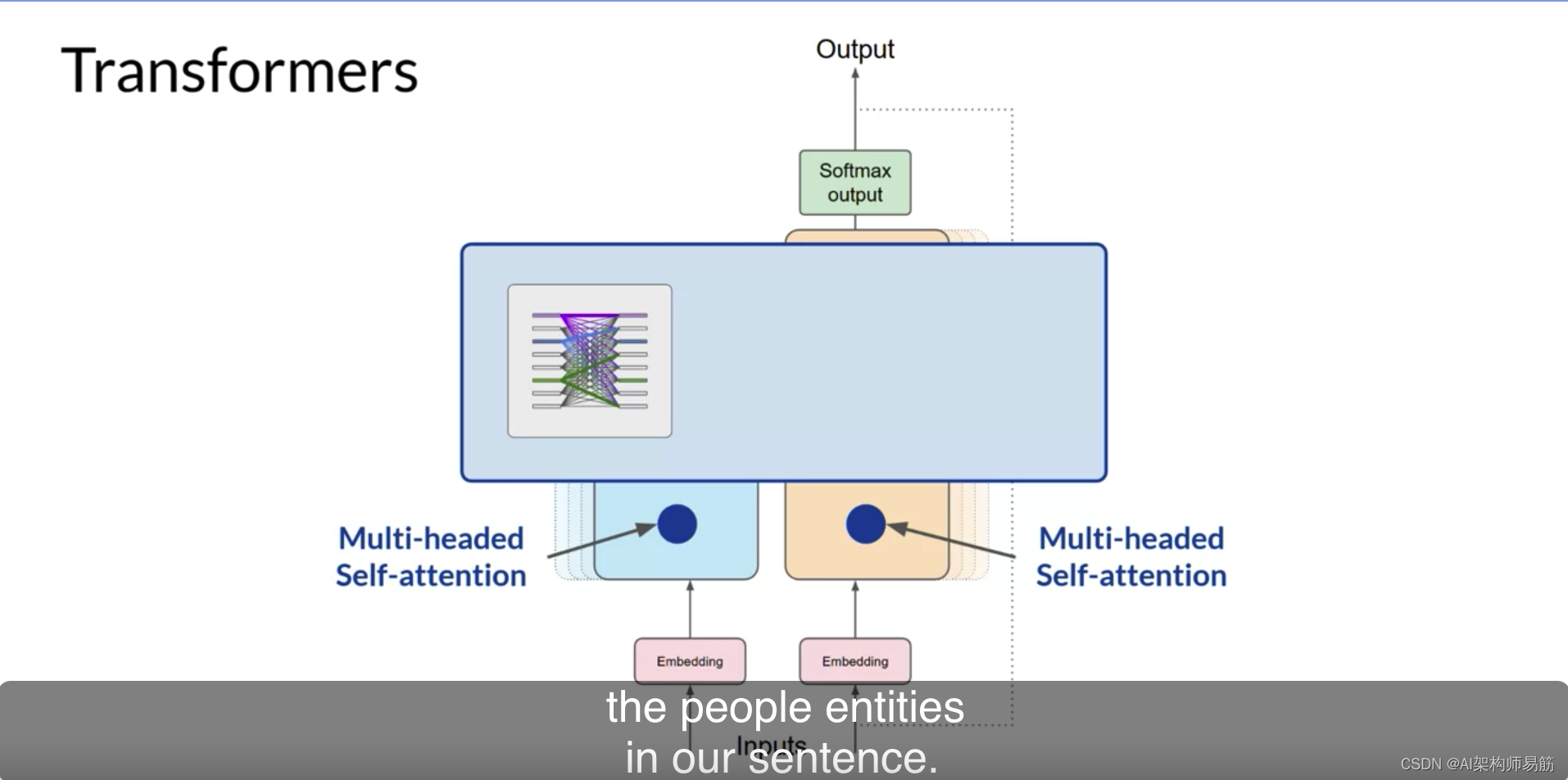
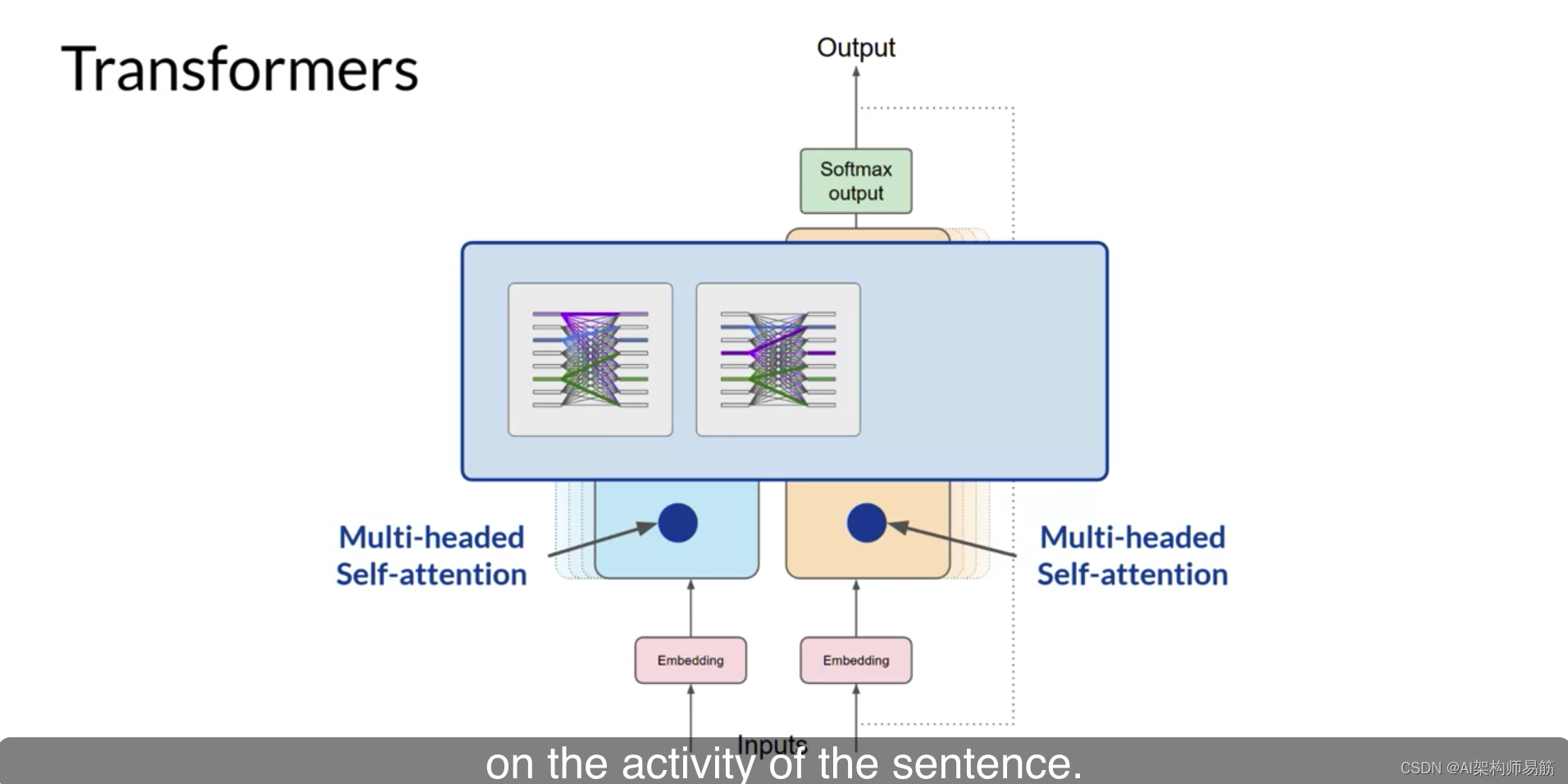
而另一个头可能专注于句子的活动。
而另一个头可能专注于其他属性,例如单词是否押韵。
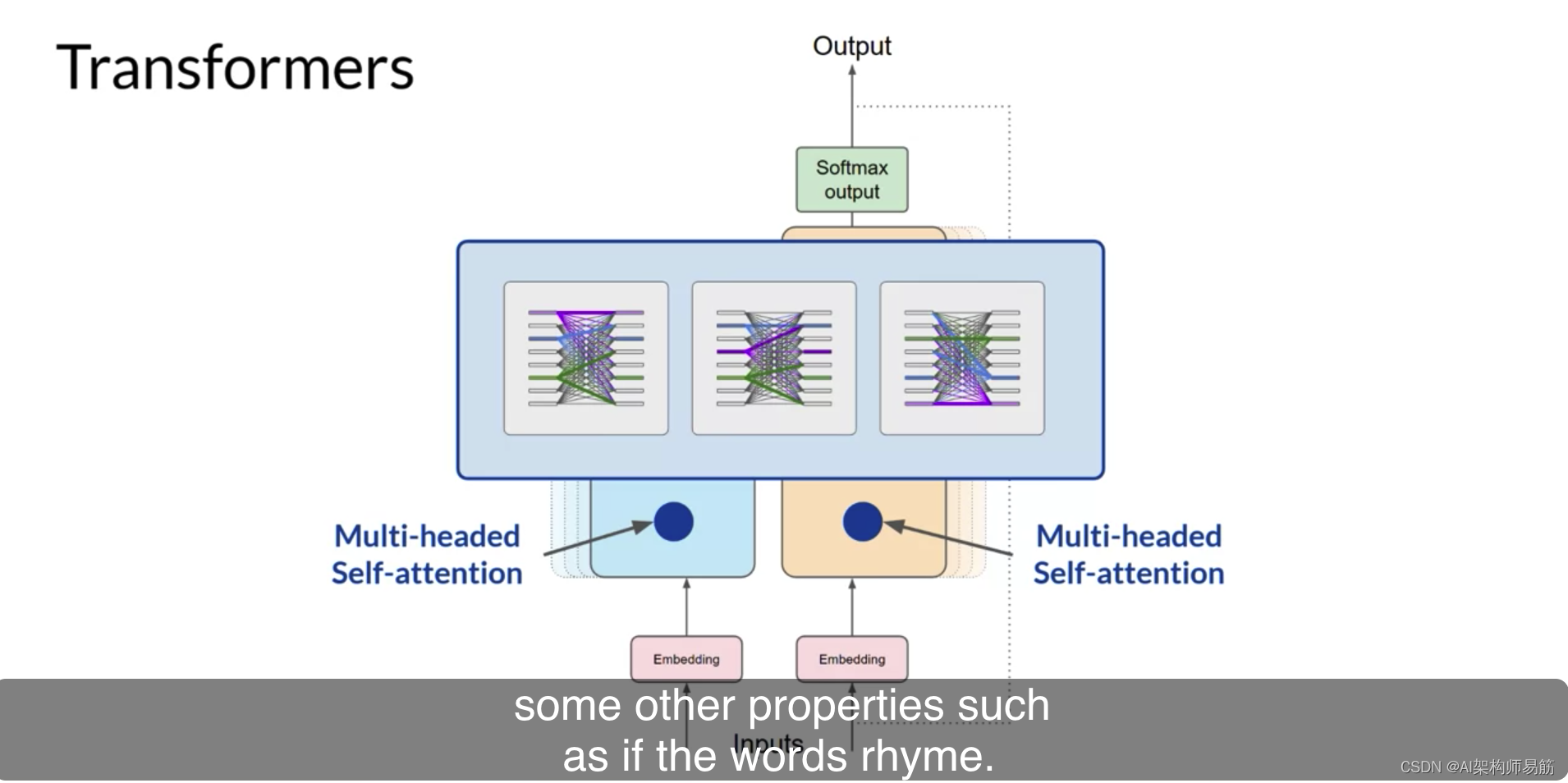
重要的是要注意,您不会提前指定注意力头将学习的语言方面。每个头的权重都是随机初始化的,只要有足够的训练数据和时间,每个头都会学习语言的不同方面。虽然一些注意力图很容易解释,就像这里讨论的例子,但其他的可能不是。
现在所有的注意力权重都已经应用到您的输入数据,输出通过一个完全连接的前馈网络进行处理。
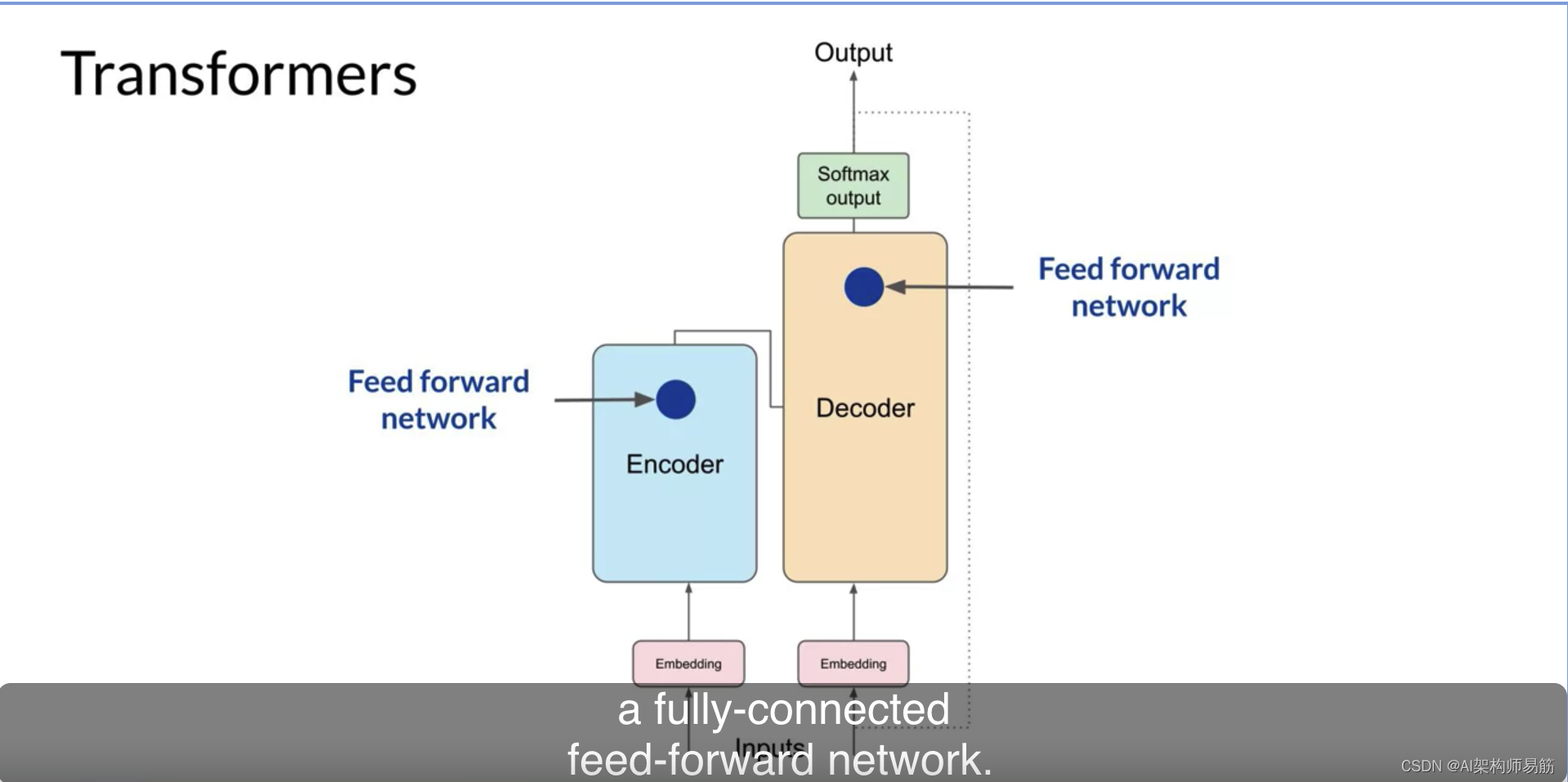
这一层的输出是与每个令牌在分词器字典中的概率得分成比例的logits向量。
然后,您可以将这些logits传递给最终的softmax层,其中它们被标准化为每个单词的概率得分。这个输出包括词汇表中每个单词的概率,所以这里可能有成千上万的分数。
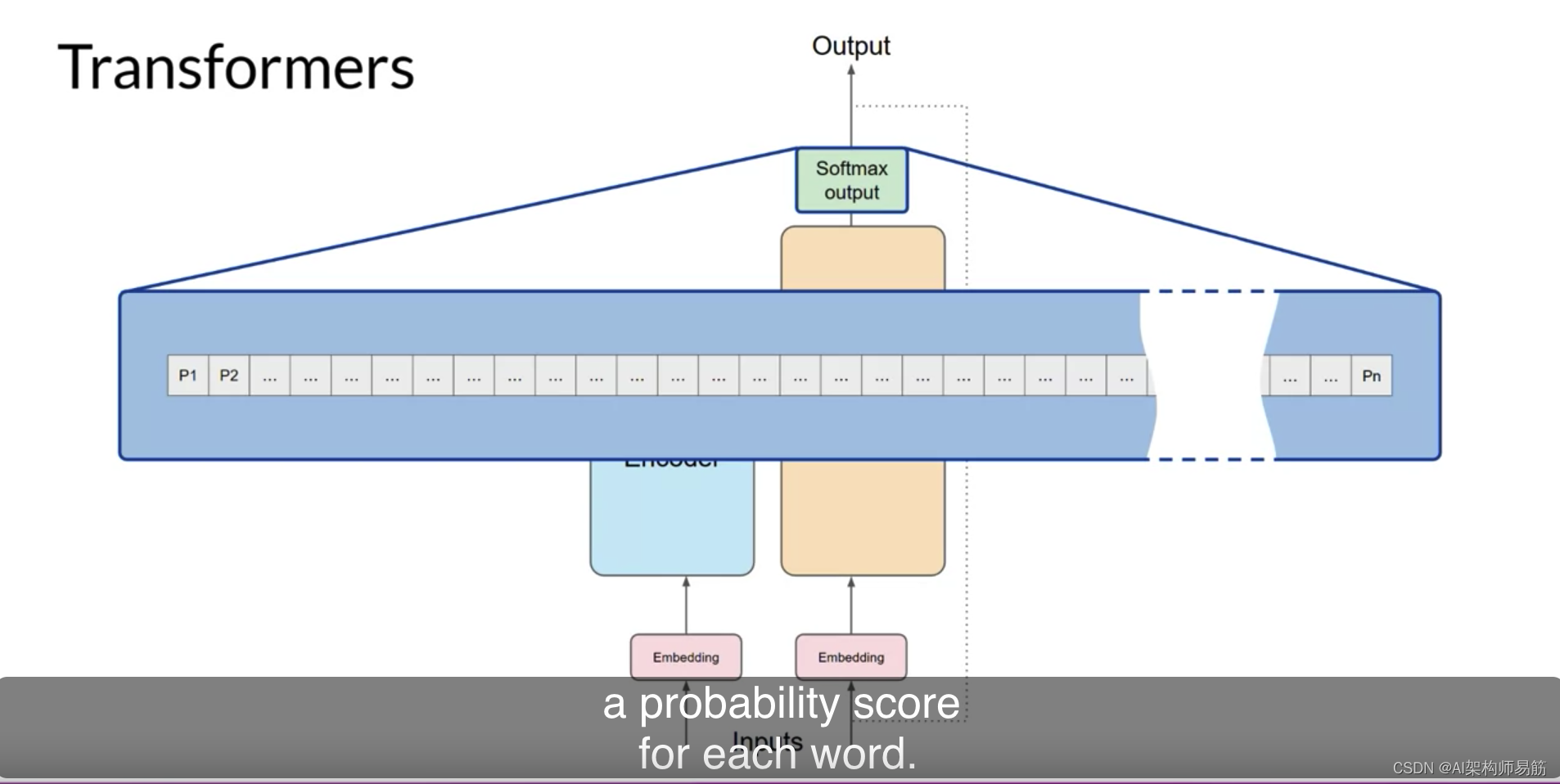
一个单一的令牌将有一个比其他所有令牌更高的分数。这是最有可能预测的令牌。但是,正如您在课程后面将看到的,您可以使用多种方法从这个概率向量中选择最终的选择。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/3AqWI/transformers-architecture