一、PointNet++解决了PointNet存在的哪些问题
- PointNet的point-wise MLP,仅仅是对每个点表征,对局部结构信息整合能力太弱 --> PointNet++的改进:sampling和grouping整合局部邻域
- PointNet的global feature直接由max pooling获得,无论是对分类还是对分割任务,都会造成巨大的信息损失 --> PointNet++的改进:hierarchical feature learning framework,通过多个set abstraction逐级降采样,获得不同规模不同层次的local和global feature(最后一个set abstraction输出可以认为是global feature),这样获得的global特征更高级,表征能力更强。
- 分割任务的全局特征global feature是直接复制与local feature拼接,这样直接进行拼接的话,可利用的global feature太少了,生成discriminative feature能力有限 --> PointNet++的改进:分割任务设计了encoder-decoder结构,先降采样再上采样,使用skip connection将对应层的local-global feature拼接,这样的特征更高级,更具有判别性。
- 当然PointNet++还解决了当点云不均匀的时候,在密集区域学习出来的特征可能不适合稀疏区域的问题,解决方法就是对不同半径的子区域进行特征提取后进行特征堆叠,不同半径的子区域的特征提取的维度变换也会随着半径的不同而不同
二、PointNet++的SA模块中有不可导的FPS采样操作,梯度如何能够反向传播?
3D检测里面有这样一类操作,用白话讲,可以归类为“路由”:即把特征从哪里取出来,或把特征汇聚到哪里去。“路由”的建立过程本身可以不可导(比如FPS和ball query)。但“路由”一旦建立,特征的传递和映射过程一般都是可导的。所以对于FPS操作在反向传播时的具体实现我认为和torch.scatter的梯度反传类似,初始化一个0张量,然后按照scatter赋值过去。
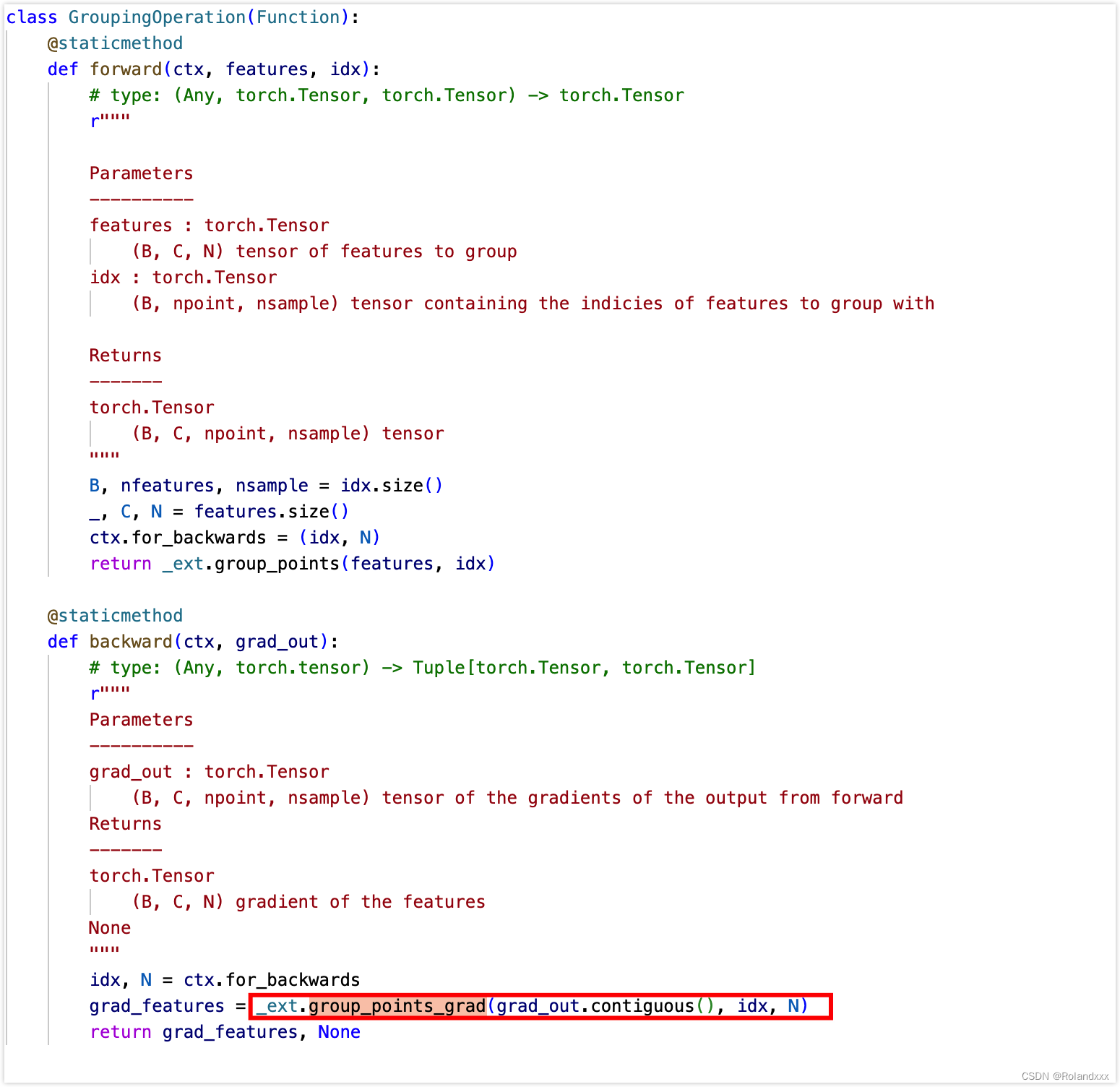
对于pointnet++中的一个例子(因为不能debug进用C++写的自定义的cuda算子,debug没法进c++的代码的,只能到调用的那一步,所以推荐直接采用全局搜索),对于前向传播中那些不能导的操作,是要重写一下backward函数的,重写时可能会调用自己实现的cuda代码。可以看到重写的backward函数返回值只有第一个有梯度,第二个没有梯度。backward的参数输入来自于forward的输出的梯度,backward返回值对应于forward的输入的梯度,所以说明idx没有梯度,被截断了,说明idx这条路是死的,但是features这条路依然有梯度:
案例:
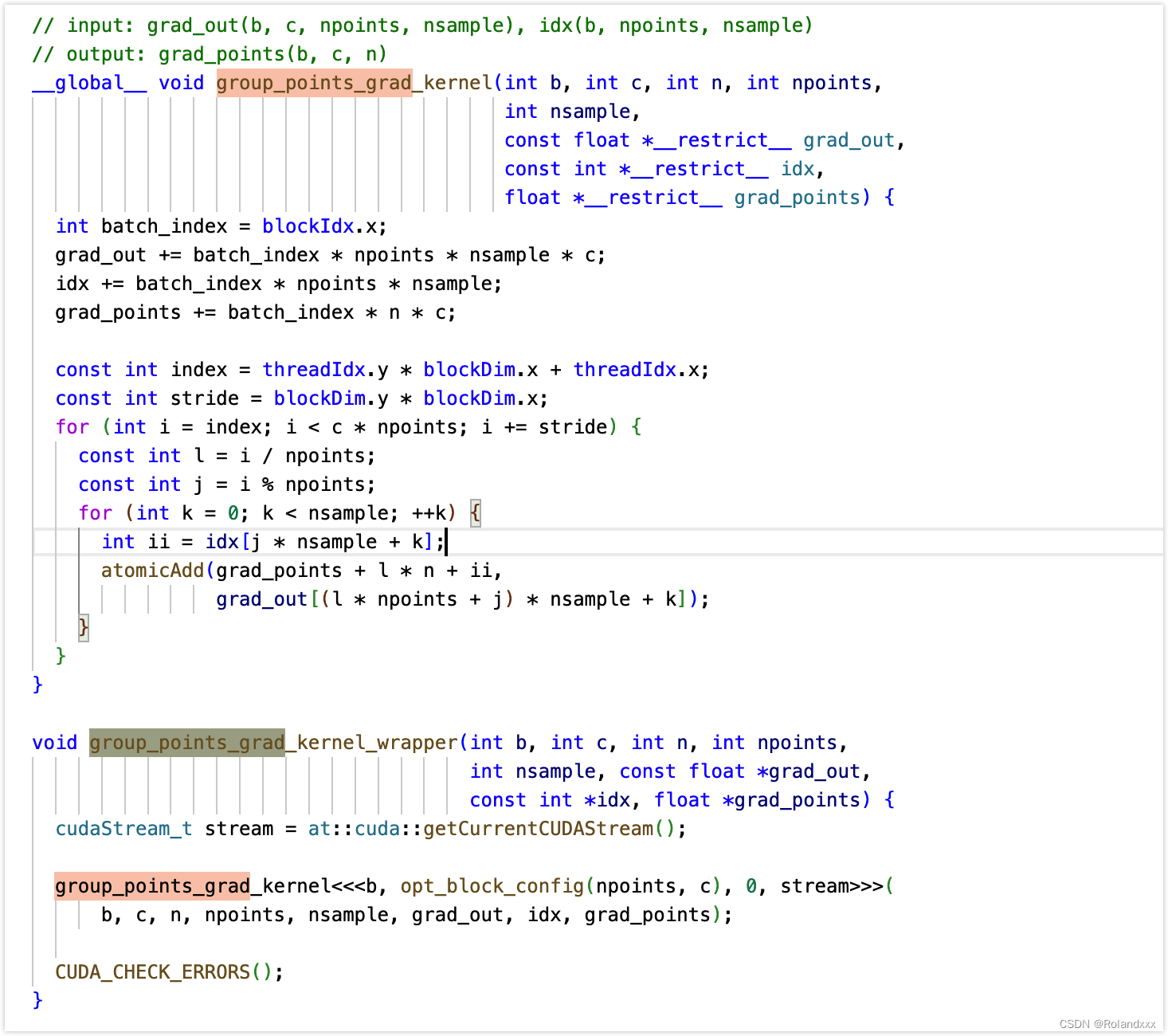
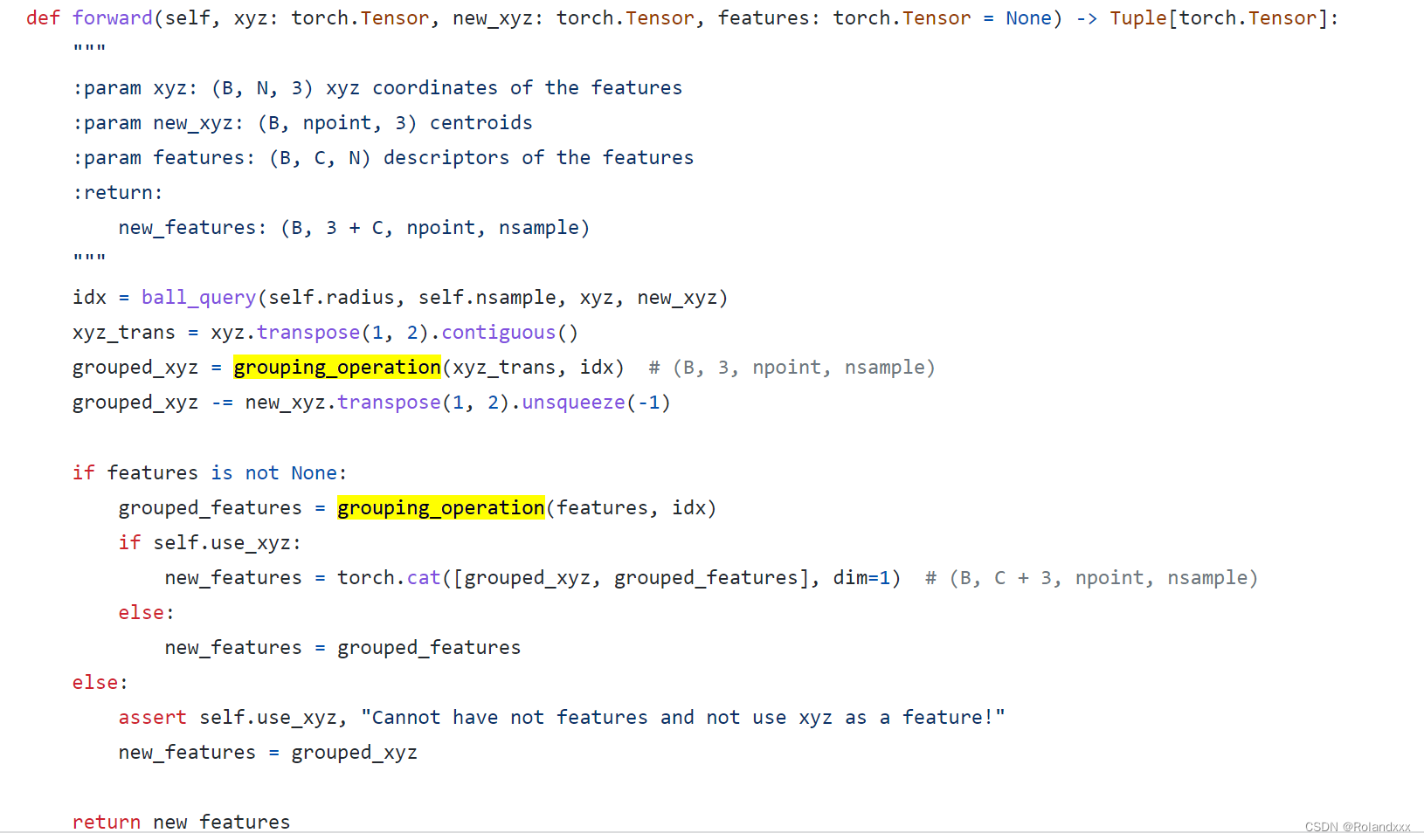
外部调用逻辑:
Refer: