- 上一篇PointNet的源码解读:http://t.csdn.cn/5oVfC
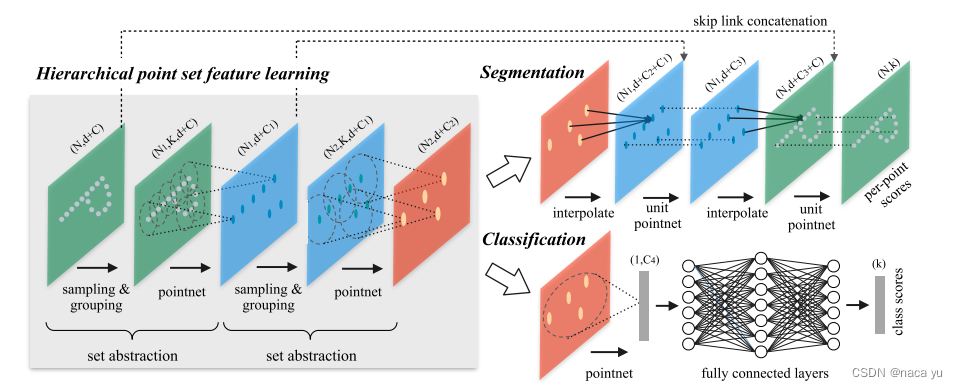
Model(Classification)
class get_model(nn.Module):
def __init__(self,num_class,normal_channel=True):
super(get_model, self).__init__()
in_channel = 3 if normal_channel else 0
self.normal_channel = normal_channel
# 两个MSG-SA+SA
self.sa1 = PointNetSetAbstractionMsg(512, [0.1, 0.2, 0.4], [16, 32, 128], in_channel,[[32, 32, 64], [64, 64, 128], [64, 96, 128]])
self.sa2 = PointNetSetAbstractionMsg(128, [0.2, 0.4, 0.8], [32, 64, 128], 320,[[64, 64, 128], [128, 128, 256], [128, 128, 256]])
self.sa3 = PointNetSetAbstraction(None, None, None, 640 + 3, [256, 512, 1024], True)
self.fc1 = nn.Linear(1024, 512)
self.bn1 = nn.BatchNorm1d(512)
self.drop1 = nn.Dropout(0.4)
self.fc2 = nn.Linear(512, 256)
self.bn2 = nn.BatchNorm1d(256)
self.drop2 = nn.Dropout(0.5)
self.fc3 = nn.Linear(256, num_class)
def forward(self, xyz):
B, _, _ = xyz.shape
if self.normal_channel:
norm = xyz[:, 3:, :]
xyz = xyz[:, :3, :]
else:
norm = None
l1_xyz, l1_points = self.sa1(xyz, norm)
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points)
x = l3_points.view(B, 1024)
x = self.drop1(F.relu(self.bn1(self.fc1(x))))
x = self.drop2(F.relu(self.bn2(self.fc2(x))))
x = self.fc3(x)
x = F.log_softmax(x, -1)
return x,l3_points
PointNetSetAbstractionMsg
class PointNetSetAbstractionMsg(nn.Module):
def __init__(self, npoint, radius_list, nsample_list, in_channel, mlp_list):
# 512->128, [0.1, 0.2, 0.4], [32, 64, 128], 3, [[32, 32, 64], [64, 64, 128], [64, 96, 128]]
super(PointNetSetAbstractionMsg, self).__init__()
self.npoint = npoint
self.radius_list = radius_list
self.nsample_list = nsample_list
self.conv_blocks = nn.ModuleList()
self.bn_blocks = nn.ModuleList()
for i in range(len(mlp_list)):
convs = nn.ModuleList()
bns = nn.ModuleList()
last_channel = in_channel + 3
for out_channel in mlp_list[i]:
convs.append(nn.Conv2d(last_channel, out_channel, 1))
bns.append(nn.BatchNorm2d(out_channel))
last_channel = out_channel
self.conv_blocks.append(convs)
self.bn_blocks.append(bns)
def forward(self, xyz, points):
"""
Input:
xyz: input points position data, [B, C, N]
points: input points data, [B, D, N]
Return:
new_xyz: sampled points position data, [B, C, S]
new_points_concat: sample points feature data, [B, D', S]
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
B, N, C = xyz.shape
S = self.npoint
# select points by fps
new_xyz = index_points(xyz, farthest_point_sample(xyz, S)) # [bs, s, c]
new_points_list = []
# 组合多个半径下的特征,multi-scale
for i, radius in enumerate(self.radius_list):
K = self.nsample_list[i]
group_idx = query_ball_point(radius, K, xyz, new_xyz) # [B, S, K=32->64->128]
grouped_xyz = index_points(xyz, group_idx) # bs, idx,
grouped_xyz -= new_xyz.view(B, S, 1, C)
if points is not None:
grouped_points = index_points(points, group_idx)
grouped_points = torch.cat([grouped_points, grouped_xyz], dim=-1) # [bs, s, k, c1+c2]
else:
grouped_points = grouped_xyz
grouped_points = grouped_points.permute(0, 3, 2, 1) # [B, D, K, S], k和s作为HW信息,将stride设置为1,相当于MLP,但是这样做计算会更高效
for j in range(len(self.conv_blocks[i])):
conv = self.conv_blocks[i][j]
bn = self.bn_blocks[i][j]
grouped_points = F.relu(bn(conv(grouped_points)))
new_points = torch.max(grouped_points, 2)[0] # [B, D', S]
new_points_list.append(new_points) # 存储不同scales
new_xyz = new_xyz.permute(0, 2, 1) # [bs, c, s]
new_points_concat = torch.cat(new_points_list, dim=1) # [bs, d', s]
return new_xyz, new_points_concat
farthest_point_sample
FPS:大概的算法逻辑是:首先初始化npoint个中心,然后将每个中心依次作为中心点更新xyz中每个点距离所在中心的最大距离并选定下一次迭代的中心点,最后得到在FPS方法下的聚类中心,这类方法相比随机初始化方法,能够避免聚类中心重合度高的问题,充分考虑点云的分布不均匀性。
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
# cetroids随机初始化,distance初始化为无限大,farthest为0,N的(b,)列表
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device) # npoint=512->128
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device) # 每个点对应
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(npoint): #npoint对应npoint个中心点
centroids[:, i] = farthest # 初始化指定j个batch的第i个中心点为farthest[j]
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3) # centroid:第i个点云对应的中心点坐标
dist = torch.sum((xyz - centroid) ** 2, -1) # b, n,3 - b, 1, 3 -> b, n
mask = dist < distance # 小于当前所有点到centroid的更新最近距离
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1] # 每个batch中所有点距离所在中心点最远的作为下一次的中心点继续迭代更新
return centroids # FPS得到的npoint个聚类中心
index_points
返回FPS指向的中心点所在的点云
def index_points(points, idx):
"""
Input:
points: input points data, [B, N, C]
idx: sample index data, [B, S]
Return:
new_points:, indexed points data, [B, S, C]
"""
device = points.device
B = points.shape[0]
view_shape = list(idx.shape) # view_shape = [2]
view_shape[1:] = [1] * (len(view_shape) - 1) # [2, ]
repeat_shape = list(idx.shape) # [2,]
repeat_shape[0] = 1 # [1,]
batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape) # [0,1...B-1]
new_points = points[batch_indices, idx, :]
return new_points
query_ball_point
按照半径聚合中心点附近的点云,返回每个点云的所在组号
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, 3]
new_xyz: query points, [B, S, 3]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1])
sqrdists = square_distance(new_xyz, xyz) # 每个中心点都与所有的点云计算二范数,[bs, s, n]
group_idx[sqrdists > radius ** 2] = N # bs, s, n,大于半径外的都赋值N,N是不存在的点云索引,作为无效值
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample] # 排序,group_idx仅有0-N-1值,通过排序,将N无效值通过取值前nsample个值滤除,group_idx.shape:[bs, s, nsample]
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample]) # bs, s, nsample
mask = group_idx == N # group_idx仍然带有无效值索引的统一赋值为其他有效值
group_idx[mask] = group_first[mask] # 将group_idx中的无效值赋值0
return group_idx
PointNetFeaturePropagation(Segmentation)
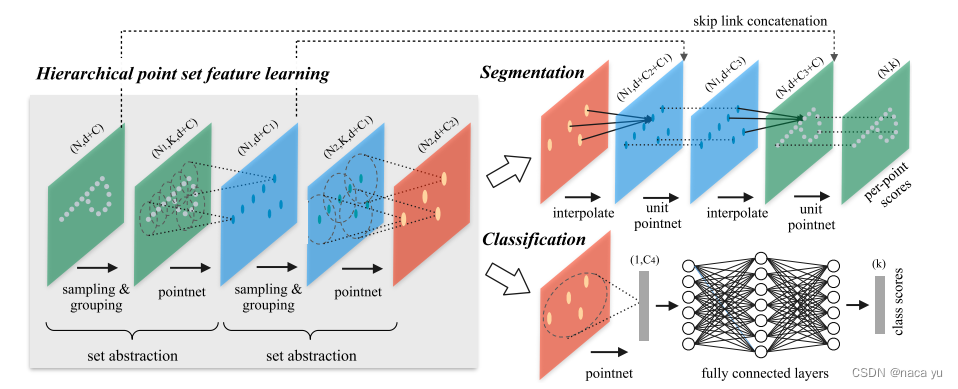
Model
- 相比Classfication,分割模型需要更加细粒度的点云,但是下采样降低了点云密度无法展现目标的形状,因此增加一些FP层基于过去的点云(未下采样前),采样高层的语义信息,这类似于UNET结构,结合语义和细节信息重建稠密点云并用于分类,使点云分割的效果更好。
class get_model(nn.Module):
def __init__(self, num_classes):
super(get_model, self).__init__()
self.sa1 = PointNetSetAbstractionMsg(1024, [0.05, 0.1], [16, 32], 9, [[16, 16, 32], [32, 32, 64]])
self.sa2 = PointNetSetAbstractionMsg(256, [0.1, 0.2], [16, 32], 32+64, [[64, 64, 128], [64, 96, 128]])
self.sa3 = PointNetSetAbstractionMsg(64, [0.2, 0.4], [16, 32], 128+128, [[128, 196, 256], [128, 196, 256]])
self.sa4 = PointNetSetAbstractionMsg(16, [0.4, 0.8], [16, 32], 256+256, [[256, 256, 512], [256, 384, 512]])
self.fp4 = PointNetFeaturePropagation(512+512+256+256, [256, 256])
self.fp3 = PointNetFeaturePropagation(128+128+256, [256, 256])
self.fp2 = PointNetFeaturePropagation(32+64+256, [256, 128])
self.fp1 = PointNetFeaturePropagation(128, [128, 128, 128])
self.conv1 = nn.Conv1d(128, 128, 1)
self.bn1 = nn.BatchNorm1d(128)
self.drop1 = nn.Dropout(0.5)
self.conv2 = nn.Conv1d(128, num_classes, 1)
def forward(self, xyz):
# 分别是位置信息和特征信息(包括位置)
l0_points = xyz
l0_xyz = xyz[:,:3,:]
l1_xyz, l1_points = self.sa1(l0_xyz, l0_points) # 分别是FPS处理后的新中心点的位置, 以及对应的聚合特征后的特征向量
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points)
l4_xyz, l4_points = self.sa4(l3_xyz, l3_points)
l3_points = self.fp4(l3_xyz, l4_xyz, l3_points, l4_points) # 经过FP处理后,上采样到l3层的点云数量,同时聚合多个层的特征,以下操作相同
l2_points = self.fp3(l2_xyz, l3_xyz, l2_points, l3_points)
l1_points = self.fp2(l1_xyz, l2_xyz, l1_points, l2_points)
l0_points = self.fp1(l0_xyz, l1_xyz, None, l1_points)
x = self.drop1(F.relu(self.bn1(self.conv1(l0_points))))
x = self.conv2(x)
x = F.log_softmax(x, dim=1)
x = x.permute(0, 2, 1)
return x, l4_points
PointNetSetAbstractionMsg
- 与分类一致,不赘述
PointNetFeaturePropagation

class PointNetFeaturePropagation(nn.Module):
def __init__(self, in_channel, mlp):
# 512+512+256+256, [256, 256]为例子
super(PointNetFeaturePropagation, self).__init__()
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv1d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm1d(out_channel))
last_channel = out_channel
def forward(self, xyz1, xyz2, points1, points2):
"""
Input:
xyz1: input points position data, [B, C, N]
xyz2: sampled input points position data, [B, C, S]
points1: input points data, [B, D, N]
points2: input points data, [B, D, S]
Return:
new_points: upsampled points data, [B, D', N]
"""
# self.fp4(l3_xyz, l4_xyz, l3_points, l4_points) 以fp4层为例,xyz1和xyz2分别是输入的点云以及SA下采样处理后的点云位置
xyz1 = xyz1.permute(0, 2, 1)
xyz2 = xyz2.permute(0, 2, 1)
points2 = points2.permute(0, 2, 1) # [bs, n, d]
B, N, C = xyz1.shape
_, S, _ = xyz2.shape
# S==1时是SSG也就是单尺度特征,我们使用MSG
if S == 1:
interpolated_points = points2.repeat(1, N, 1)
else:
# [bs, n, s]
dists = square_distance(xyz1, xyz2)
dists, idx = dists.sort(dim=-1)
dists, idx = dists[:, :, :3], idx[:, :, :3] # [B, N, 3],每个原始输入点云对应的周围3个下采样后的点云索引
dist_recip = 1.0 / (dists + 1e-8) # [bs, n, 3]
norm = torch.sum(dist_recip, dim=2, keepdim=True) # [bs, n, 1]
weight = dist_recip / norm # [bs, n, 3],进行归一化权重
# 将每个原始点云与周围的三个下采样后的点云求权值和:[bs, n, 3, d] .* [bs, n, 3, 1] -> [bs, n, d]
interpolated_points = torch.sum(index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2)
# 将融合了高层抽象特征的点云与原始特征融合
if points1 is not None:
points1 = points1.permute(0, 2, 1)
new_points = torch.cat([points1, interpolated_points], dim=-1) # [bs, n, d1+d2]
else:
new_points = interpolated_points
new_points = new_points.permute(0, 2, 1)
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
return new_points