Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentatio
企业开发
2023-08-12 20:39:30
阅读次数: 0
痛点:speech2speech translation平行数据稀缺,常规的方法是级联ASR-MT-TTS的方法制造平行数据。
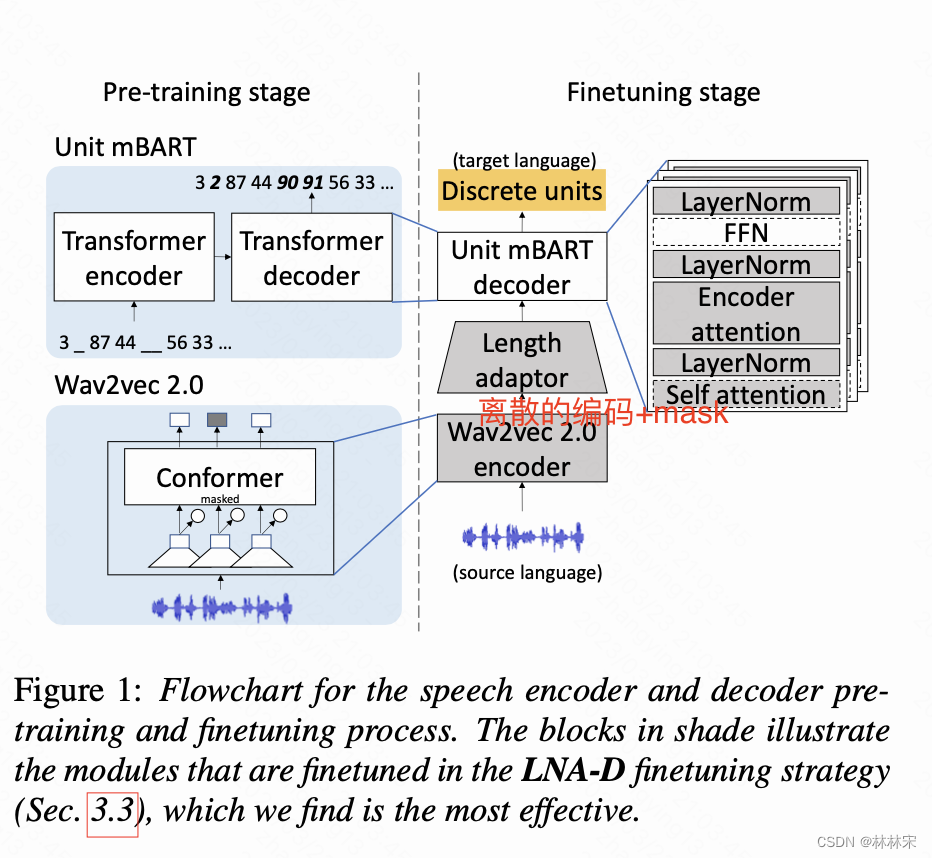
方案:使用无标签数据+自监督方法+数据增广,使用一个speech-to-unit translation的工具(S2UT),将音频编码为离散的表征,然后通过pretrain+局部finetune的方法,对离散的表征进行优化,最后通过unit HiFi-GAN vocoder 合成为另外一个语种的音频。
that work well for speech-to-text translation (S2T,翻译成另外一个语种的text) to the S2UT domain by studying both speech encoder and discrete unit decoder pre-training.
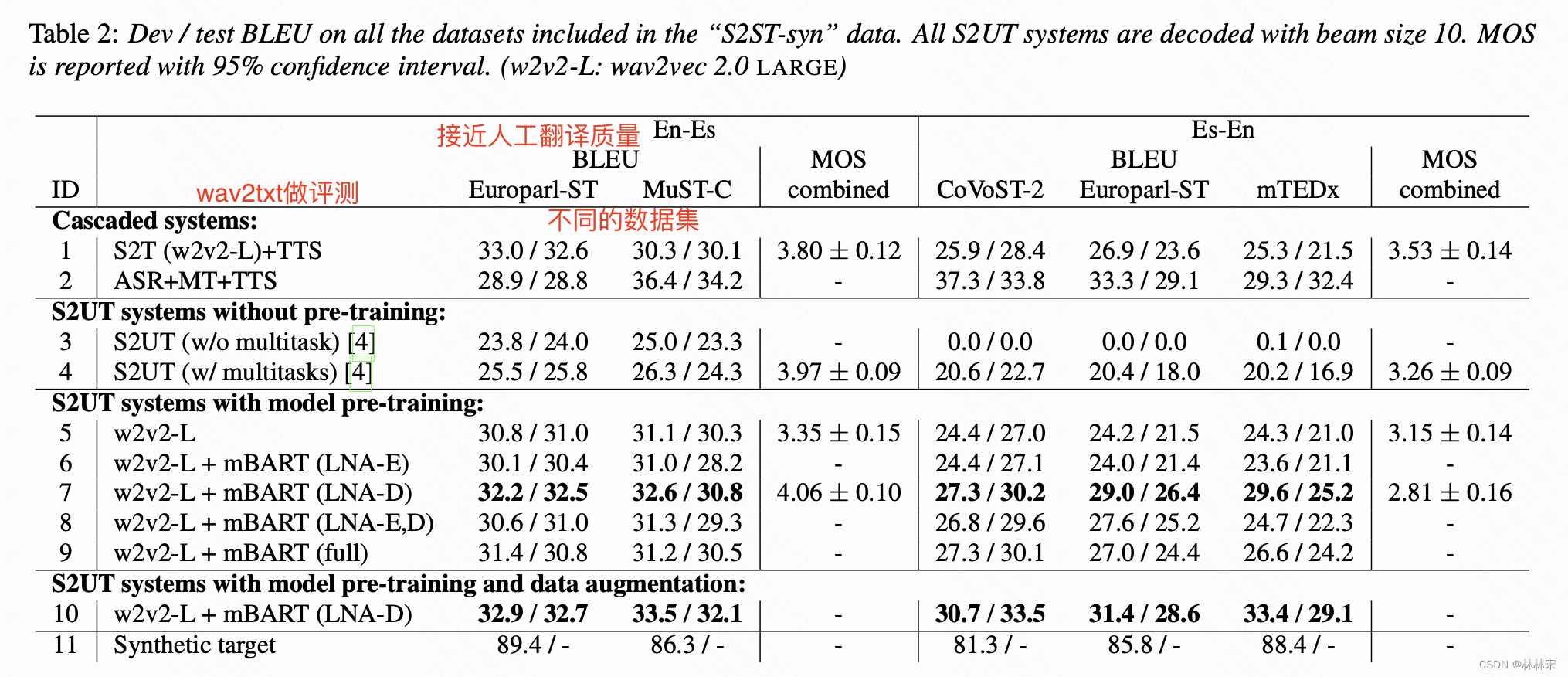
结果:在Spanish- English translation的任务上,相比多任务学习提升6.6-12.1BLEU,并且可以通过进一步的数据增广和MT增加弱标签数据对性能进一步提升。
自监督speaker encoder预训练在ASR、S2T(speech2text translation),speaker identification上都有应用。
本文将【27】中单语言编码的方法扩展到multilingual unit pretraining,然后使用不同的discrete unit decoder pre-training
HuBERT输入音频,得到离散表征,通过预训练的k-means进行聚类。20ms/frame,移除序列中连续重复的units,得到reduced discrete units。
还有speech decoder(mBART),以及一个unit HiFi-GAN vocoder(基于unit-to-waveform单独训练的)
wav2vec2.0:multi-layer conv对音频编码,conformer-based encoder(原文用transformer-based) 进行文本表征,通过对比学习,以及input mask学习
mBART用于对text数据降噪,输入noisy text,输出orignal text x x x
对输入的text,以及文本的长度,进行一定比例的随机mask
Transformer-based encoder-decoder architecture
encoder和decoder之间加adaptor layer(conv1d),作用是(1)帮助消除两个模块representation之间的mismatch;(2)消除长度mismatch:source audio和 reduced target units.
局部finetune:使用layer norm+attention的结构,假设layer norm反映了encoder的统计信息,attention关注decoder的输入序列优化。
fintune的四种方式:
LNA-E:The LayerNorm and self attention parameters in the encoder and all the parameters in the decoder are finetuned.
LNA-D:The whole encoder and the LayerNorm and both encoder and self attention in the decoder are finetuned.可以在前k step将encoder的参数freeze
LNA-E,D:Only LNA parameters are finetuned both on the encoder and the decoder side
full:全量更新,前k step将encoder的参数freeze
将一些ASR的数据拿来做S2ST任务的数据增广。怎么用起来?
txt经过翻译转成另外一种语言的text,然后通过一个text2unit 的模块,将文本直接处理为离散表征。代替text2speec & speech2unit的过程。
multilingual HuBERT:基于En, Es and French unlabeled speech 训练,k-means,unit-based HiFi-GAN vocoder
转载自 blog.csdn.net/qq_40168949/article/details/129710089