- 《GraphCodeBERT: Pre-training Code Representations with Data Flow》ICLR 2021 (TH-CPL A会,公认顶会,但未上 CCF 榜)
- 作者部分与 CodeBERT 重叠,主要来自 MSRA Intern 和 MSRA 研究员,学生来自国内多个顶尖高校。
- 资源:code | pdf
- 相关资源:tree-sitter
Abstract
之前的模型(eg. CodeBERT)把代码当作 tokens sequence,这显然忽略了代码结构信息,而这包含了关键的代码语义信息,有助于增强代码理解过程。本文提出的 GraphCodeBERT 是一个考虑了代码结构的面向编程语言的预训练模型。本文没有采用抽象语法树(AST)这样的代码语法结构,而是在预训练阶段使用数据流,这是一种编码变量之间 “where-the-value-comes-from” 关系的代码语义结构。Data Flow 结构不复杂,不会带来不必要的 AST 的深层结构,这个性质让模型更高效。
GraphCodeBERT 基于 Transformer,除了采用了 MLM 任务,还引入了2个感知结构的预训练任务。
- predict code structure edges
- align representations between source code and code structure
本文通过 a graph-guided masked attention 函数来有效地实现模型对代码结构的利用。
模型评估:code search, clone detection, code translation, and code refinement;结果表明代码结构和新引入的预训练任务可以改善 GraphCodeBERT,并在四个下游任务中取得 SOTA(2021年)。并且进一步展示了:在代码搜索任务中,该模型更倾向于 structure-level attentions 而不是 token-level attentions。
1 Introduction
当前很多工作把源码视为字符序列,然后训练预训练模型,来支持代码相关的任务…然而过去的工作没有考虑代码内部的结构信息,这样的结构信息对理解代码的语义有很大的帮助。以表达式 v=max_value-min_value 为例,v 是根据 max_value 和 min_value 计算得到的。当然,程序员不一定根据语义对变量进行命名,因此仅从变量名 v 很难理解其语义。代码的语义结构提供了一种利用变量之间的依赖关系的来理解变量 v 的语义的方法。
本文提出了 GraphCodeBERT 利用代码的语义级信息(数据流)来进行代码的预训练。数据流图(DFG) 中的节点表示变量,边表示“where-the-value-comes-from”的关系。与 AST 相比,数据流不那么复杂,没有带来不必要的深层结构,这一特性使得模型更加高效。为了从源代码和代码结构中学习代码表示,引入了两个新的结构感知预训练任务。
- data flow edges prediction:用于从代码结构中学习表示
- variable-alignment across source code and data flow:用于在源码和代码结构之间对齐表示
GraphCodeBERT 基于 Transformer 结构,通过引入 graph-guided masked attention function 来扩展它,以 incorporate the code structure。本文在 CodeSearchNet 上对 GraphCodeBERT 进行预训练,这个数据集包含带有自然语言文档说明的来自6种编程语言的2.3M个函数。
论文主要贡献:
- 首个利用语义结构(DFG)学习代码表示的预训练模型;
- 提出两种新的从源码和数据流中感知代码结构的预训练任务;
- 在测试的四个下游任务中显著改进(2021年的SOTA);
2 Related Works
Pre-Trained Models for Programming Languages (Kanade et al., 2019; Feng et al., 2020; Karampatsis & Sutton, 2020; Svyatkovskiy et al., 2020; Buratti et al., 2020).
- Kanade et al. (2019) pre-train a BERT model on a massive corpus of Python source codes by masked language modeling and next sentence prediction objectives
- Feng et al. (2020) propose CodeBERT, a bimodal pre-trained model for programming and natural languages by masked language modeling and replaced token detection to support text-code tasks such as code search
- Karampatsis & Sutton (2020) pre-train contextual embeddings on a JavaScript corpus using the ELMo framework for program repair task.
- Svyatkovskiy et al. (2020) propose GPT-C, which is a variant of the GPT-2 trained from scratch on source code data to support generative tasks like code completion.
- Buratti et al. (2020) present C-BERT, a transformer-based language model pre-trained on a collection of repositories written in C language, and achieve high accuracy in the abstract syntax tree (AST) tagging task.
Neural Networks with Code Structure code completion (Li et al., 2017; Alon et al., 2019; Kim et al., 2020), code generation (Rabinovich et al., 2017; Yin & Neubig, 2017; Brockschmidt et al., 2018), code clone detection (Wei & Li, 2017; Zhang et al., 2019; Wang et al., 2020), code summarization (Alon et al., 2018; Hu et al., 2018) and so on (Nguyen & Nguyen, 2015; Allamanis et al., 2018; Hellendoorn et al., 2019).
- Nguyen & Nguyen (2015) propose an AST-based language model to support the detection and suggestion of a syntactic template at the current editing location.
- Allamanis et al. (2018) use graphs to represent programs and graph neural network to reason over program structures.
- Hellendoorn et al. (2019) propose two different architectures using a gated graph neural network and Transformers for combining local and global information to leverage richly structured representations of source code.
3 Data Flow
与 AST 不同的是:对于相同源代码,数据流在不同的抽象语法(abstract grammars)下是相同的。数据流支持模型考虑远距使用相同变量或函数时所引起的远程依赖关系。

4 GraphCodeBERT
模型训练的细节参考附录 A。
4.1 Model Architecture

本文延续 CodeBERT 的工作,使用 multi-layer bidirectional Transformer 作为模型的 backbone。同时本文构建的模型除了使用源码,还采用了 paired comments 来对模型进行预训练,使得支持更多代码相关的任务,并且本文还将源码处理成数据流(DFG)图作为模型的输入。
【下面是 Transformer 架构和 Attention 的原理的描述,如果没学过的话,还得专门看讲这俩的文章】
GraphCodeBERT 把输入 X = { [ C L S ] , W , [ S E P ] , C , [ S E P ] , V } X=\{[CLS], W, [SEP], C, [SEP], V\} X={[CLS],W,[SEP],C,[SEP],V} 转化为 input vectors H 0 H^0 H0。对每个 token,其 input vector 通过将相应的 token embeddings 和 position embeddings 相加得到的。对所有的变量,我们采用 special position embedding 来表示他们是数据流中的节点。
模型在 input vector 上应用了 N transformer layers 来产生 contextual representations H n = t r a n s f o r m e r n ( H n − 1 ) H^n = transformer_n(H^{n-1}) Hn=transformern(Hn−1)。每 层 transformer 都包含一个 architecturally identical transformer 用于应用多头自注意力操作【看不懂这里文字描述的话结合下面公式理解】。

- MultiAttn:multi-headed self-attention mechanism
- FFN:two layers feed forward network
- LN:a layer normalization operation
对于第 n 层 Transformer,其 multi-headed self-attention 的输出 G n ^ \hat{G^n} Gn^ 通过下式计算:

(4)中的 M 在 4.2 中解释。
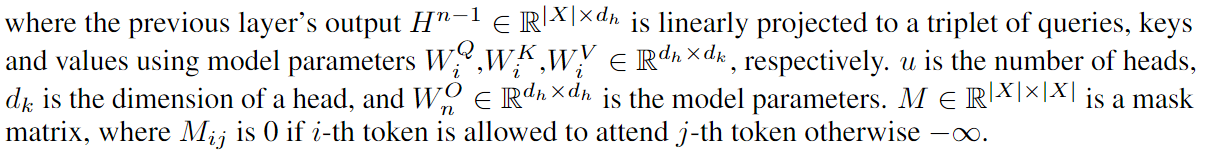
4.2 Graph-Guided Masked Attention
为了让 Transformer 处理 graph 结构,设计了 graph-guided masked attention function 来过滤不相关信号,这个设计用于新设计的两个预训练任务中。
具体来说,Attention masking function 通过给 attention score q j T k i q_j^Tk_i qjTki 加一个负无穷的数,可以避免 k i k_i ki attended by the query q j q_j qj,从而在使用 softmax 函数后 attention weight 变为零,实现了类似于滤波的效果。
【这里是针对 Edge Prediction 预训练任务】
为了表示变量之间的依赖关系,如果 v i v_i vi 和 v j v_j vj 在数据流中存在有向边或他们是同一节点的情况下,a node-query q v i q_{v_i} qvi is allowed to attend to a node-key q v j q_{v_j} qvj,否则将会在 attention score 中增加一个负无穷来遮盖。
(ps: E E E 代表 nodes 之间的边)
【这里是针对 Node Alignment 预训练任务】
为了表示源码中的 tokens 和数据流图中的 nodes 之间的关系,定义了一个集合 E ′ E' E′:

- 这里的
/的意思是or,即 node、code 的双向边都属于 E ′ E' E′,其中的变量 v i v_i vi与代码token中的 c j c_j cj相对应。我们然后允许 node q v i q_{v_i} qvi and code k c j k_{c_j} kcj attend each other,当且仅当其属于集合 E ′ E' E′。 【但实际上对应的预训练任务似乎只用了node->code单向边…】
这里给出式(4)中M的定义:其中 DFG 中的有向边 < v j , v i > ∈ E <v_j,v_i>\in{E} <vj,vi>∈E

4.3 Pre-Training Tasks
Masked Language Modeling
- masked language modeling for learning representation from the source code.
- sample randomly 15% of the tokens from the source code and paired comment,then replace them with a [MASK] token 80% of the time, with a random token 10% of the time, and leave them unchanged 10% of the time;
- 这里数据同时用了 NL、PL 数据,所以当 PL 上下文不足以推断恢复出原本的 token 的信息时,可以结合 NL 的信息作为补充。
Edge Prediction
- data flow edge prediction for learning representation from data flow;
- The motivation is to encourage the model to learn structure-aware representation that encodes the relation of “where-the-value-comes-from” for better code understanding;
- randomly sample 20% of nodes V s V_s Vs in data flow, mask direct edges connecting these sampled nodes by add an infinitely negative value in the mask matrix, and then predict these masked edges E m a s k E_{mask} Emask;

- E c = V s × V ∪ V × V s E_c=V_s\times{V}\cup{V}\times{V_s} Ec=Vs×V∪V×Vs;
- δ ( e i j ∈ E ) = 1 \delta(e_{ij}\in{E})=1 δ(eij∈E)=1 当且仅当 < v i , v j > ∈ E <v_i,v_j>\in{E} <vi,vj>∈E,否则为0;
- probability p e i j p_{e_{ij}} peij of existing an edge from i-th to j-th node is calculated by dot product following a sigmoid function using representations of two nodes from GraphCodeBERT;
- 平衡正负样本:sample negative and positive samples with the same number for E c E_c Ec;
Node Alignment
- variable-alignment across source code and data flow for aligning representation between source code and data flow;=> predict edges between code tokens and nodes;
- motivation: encourage the model to align variables and source code according to data flow;

- randomly sample 20% nodes V s ′ V_s' Vs′ in the graph, mask edges between code tokens and sampled nodes, and then predict masked edges E m a s k ′ E_{mask}' Emask′;

- E c ′ = V s ′ × C E_c'=V_s'\times{C} Ec′=Vs′×C
- 平衡正负样本:sample negative and positive samples with the same number for E c ′ E_c' Ec′;
5 Experiments
详细的实验参数在附录。
5.1 Natural Language Code Search
- 数据集:CodeSearchNet code corpus (Husain et al., 2019)
- 本文的修改:根据手工规则过滤了低质量的查询,并将1000个候选扩展到整个代码语料库,这更接近现实场景;更多细节参考附录 B。
- 评估指标:Mean Reciprocal Rank (MRR)

- calculate inner product of code and query encodings as relevance scores to rank candidate codes;
- GraphCodeBERT 与其他基线方法之间的 t-test t-检验: p p p<0.01 证明起到了显著提升。
5.2 Code Clone Detection
代码克隆是指多份代码段在给定相同输入的情况下得到相似的结果。这项任务旨在度量两个代码片段之间的相似性。
- 数据集:BigCloneBench dataset (Svajlenko et al., 2014)
相关工作
- Deckard (Jiang et al., 2007) :compute vectors for structural information within ASTs ;
- (Datar et al., 2004):Locality Sensitive Hashing (LSH) to cluster similar vectors for detection;
- RtvNN(White et al., 2016): recursive autoencoder to learn representations for AST;
- CDLH(Wei & Li, 2017):learn representations of code fragments via AST-based LSTM and hamming distance is used to optimize the distance between the vector representation of AST pairs;
- ASTNN (Zhang et al. 2019):uses RNNs to encode AST subtrees for statements,then feed the encodings of all statement trees into an RNN to learn representation for a program.(已经跟GNN差不多了吧…)
- FA-AST-GMN (Wang et al., 2020):uses GNNs over a flow-augmented AST to leverages explicit control and data flow information for code clone detection;

5.3 Code Translation
代码翻译任务:将源码从一种语言翻译到另一种语言;
- 数据集:Following Nguyen et al. (2015) and Chen et al. (2018), we conduct experiments on a dataset crawled from the same several open-source projects as them
- 对比方法:
- Naive:directly copying the source code as the translation result;
- PBSMT(Koehn et al., 2003):phrase-based statistical machine translation ,本文章被用于:(Nguyen et al., 2013; Karaivanov et al., 2014);
- Transformer:与本文预训练模型相同的层数;
- pre-trained model:对于 pre-trained model,用预训练模型初始化 encoder,随机初始化 decoder 和 source-to-target attention 的参数,然后微调。

5.4 Code Refinement
代码优化旨在自动修复代码中的错误,这有助于降低错误修复的成本。
- 数据集:dataset released by Tufano et al. (2019)
- 对比方法:
- Naive:directly copies the buggy code as the refinement result
- Transformer:与本文模型相同层数和大小。用预训练模型初始化 encoder,随机初始化 decoder 和 source-to-target attention 的参数,然后在训练集上微调。

5.5 Model Analysis
Ablation Study 任务:natural language code search

Node-vs. Token-level Attention Table 6 shows how frequently a special token [CLS] that is used to calculate probability of correct candidate attends to code tokens (Codes) and variables (Nodes).

- 说明了数据流在代码理解过程中起着重要的作用。
Comparison between AST and Data Flow

- AST Pre-order Traversal:使用先序遍历算法将所有AST节点线性化为一个序列。
- AST Subtree Masking:introduce subtree masking (Nguyen et al., 2019) for self-attention of the Transformer;
- AST 中的每个节点查询只关注它自己的子树后代,每个叶子查询只关注 AST 的叶子;
Transformer 有一个时间复杂度 O ( n 2 ) O(n^2) O(n2)、空间复杂度 O ( n ) O(n) O(n)的自注意力单元(n是输入序列的长度),这在长输入中效率极其低下。当序列长度较短(如小于128)时,AST甚至会损害性能,而 GraphCodeBERT 在不同序列长度时都会持续带来性能提升,并获得比基于AST的方法更好的MRR分数。主要原因是数据流不那么复杂,节点数量约占5%~20%(表6),这没有带来不必要的深层次AST,使模型更加准确和高效。
Case Study

- 阈值:0.5;
6 Conclusion
- 提出首个考虑代码结构的代码表示预训练模型,提出2个结构感知的预训练任务提高了性能。
- 代码搜索任务中的案例研究表明,在预训练模型中应用数据流可以提高代码理解能力。