Self-Supervised Learning of 3D Human Pose using Multi-view Geometry
Kocabas M, Karagoz S, Akbas E. Self-Supervised Learning of 3D Human Pose using Multi-view Geometry[J]. arXiv preprint arXiv:1903.02330, 2019.
Abstract
训练精确的3D人体姿势估计器需要大量的3D真值数据,这些数据的收集成本很高。由于缺乏3D数据,已经提出了各种弱或自监督的姿势估计方法。然而,除了2D真值姿态数据之外,这些方法还需要各种形式的附加监督(例如,不成对的3D真值数据,部分标签数据)或多视图设置中的相机参数。
为了解决这些问题,我们提出了EpipolarPose,一种用于3D人体姿态估计的自我监督(Self-Supervise)学习方法,它不需要任何3D真值数据或相机外部参数。在训练期间,EpipolarPose从多视图图像估计2D姿势,然后利用**对极几何(epipolar geometry)**来获得3D姿势和相机几何,随后用于训练3D姿势估计器。
对极几何是立体视觉几何。当两个相机从两个不同位置拍摄3D场景时,在3D点和2D映射之间会有一定的几何相关性,在图像点之间产生约束。这个关系是基于针孔相机模型近似得到的。
参考:https://blog.csdn.net/lin453701006/article/details/55096777
计算机视觉基础——对极几何(Epipolar Geometry)
https://blog.csdn.net/baidu_38172402/article/details/83304245
我们证明了该方法在标准基准数据集上的有效性(Human3.6M 和 MPI-INF-3DHP),在弱/自监督方法中达到了最先进的效果。此外,我们提出了一种新的性能评估方法 Pose Structure Score(PSS),它是一种尺度不变的结构感知度量,用于评估姿势相对于其ground-truth的结构合理性。代码和预训练模型发布于https://github.com/mkocabas/EpipolarPose。
1 Introduction
室外的人体姿势估计是计算机视觉中的挑战性问题。 尽管存在用于二维(2D)姿态估计的大规模数据集[2,20],但3D数据集[16,23]要么限于实验室内设置或者在尺寸和多样性方面受限。
由于室外采集三维人体姿态标注的成本较高,且三维数据集有限,因此研究人员采用弱监督或自监督的方法,在现有二维姿态数据集的基础上,通过最小的额外监督,获得精确的三维姿态估计量。为此目的已发展了各种方法。除了2D姿势真值之外,这些方法还需要各种形式的额外监督(例如不成对的3D真值数据[42],部分标签[31])或多视图设置中的(外在的)相机参数[30]。 据我们所知,只有一种方法[9]可以通过仅使用2D真值来生成3D姿态估计器。 在本文中,我们提出了另一种这样的方法。
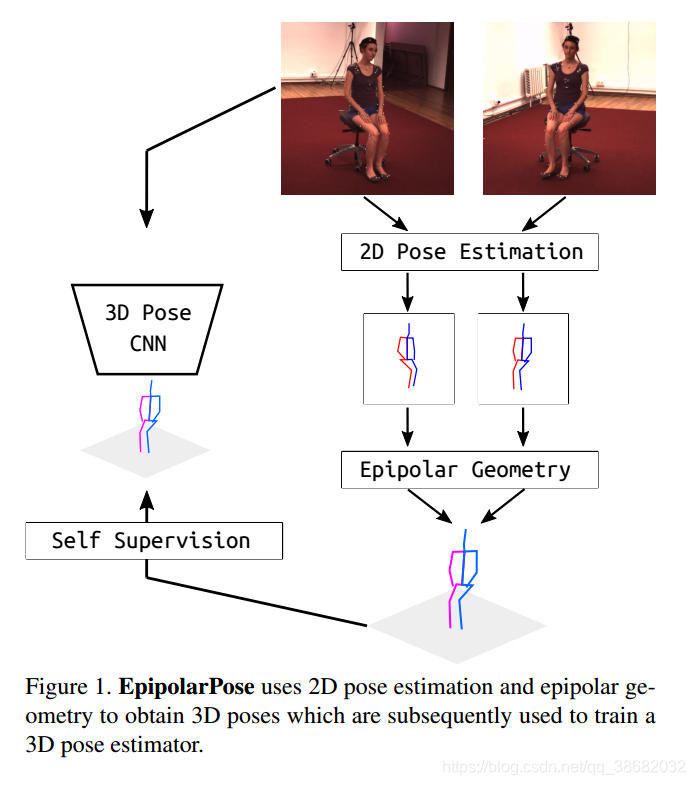
我们的方法“EpiloparPose”使用2D位姿估计和对极几何来获得3D位姿,然后用来训练3D位姿估计器。"EpipolarPose"适用于任意数量的相机(必须至少有2台),它不需要任何3D监控或外部相机参数,但是,如果提供这些参数,它可以利用它们。在Human3.6M[16]和 mpi - info - 3dhp[23]数据集上,我们在弱/自监督方法中,提出了一种新的最先进的三维姿态估计方法。
传统评价指标
- MPJPE(mean per joint position error):每个关节位置误差的平均值
- PCK(percentage of correct keypoints):正确关键点的百分比
本文提出指标
- PSS(pose structure score)
人体姿态估计允许后续更高层次的推理应用,例如自动系统(汽车、工业机器人)和动作识别。在这类任务中,Pose中的结构误差(structural errors)可能比传统评价指标的定位误差(localization errors)更为重要。这些度量独立地对待每个关节,因此不能对姿态整体结构进行评估。图4显示了相对于参考位姿结构上非常不同的pose,却具有相同的MPJPE。为了解决这个问题,我们提出了一种新的性能度量方法,称为位姿结构评分(PSS),它对位姿中的结构错误非常敏感。PSS计算一个尺度不变的性能评分,能够根据一个姿态的基本事实对其结构合理性进行评分。注意,PSS不是一个损失函数,它是一个性能度量,可以与MPJPE和PCK一起用来描述位姿估计器的表示能力
为了计算PSS,我们首先需要对真实姿态的自然分布进行建模。为此,我们使用了一种非监督聚类方法。p表示一个预测的pose,q代表真实pose。首先,我们分别找到最接近p和q的聚类中心。如果p,q最接近(即分配)相同的聚类,那么q的PSS是1,否则为0。
Contributions
- 提出了一种利用单幅图像预测人体三维姿态的方法。训练中,不需要任何三维监督或摄像机参数。它利用对极几何和二维真实姿态完成自己的三维监督。
- 在弱/自监督的三维人体姿态估计方法中达到最先进
- 为了更好地捕捉结构误差,提出了一种新的三维人体姿态估计性能指标——姿态结构评分(PSS)。
2 Related work
我们的方法EpipolarPose,是一个利用单视图进行姿态估计;在训练过程中采用多视图、自我监督的方法。在文献中讨论这种方法之前,我们首先简要回顾一下完全单视图(在训练和预测期间)和完全多视图方法。
Single-viewd methods
在最近的许多工作中,卷积神经网络(CNN)被用来直接从图像中估计三维关节的坐标[39,40,4135,23]。Li和Chan[19]是第一个证明深度神经网络可以在单幅图像的三维人体姿态估计中达到合理的精度。他们使用了两个深度回归网络和身体部位检测。Tekin等人的[39]研究表明,将传统的用于监督学习的CNNs与用于结构学习的自动编码器相结合可以获得良好的效果。与一般的回归操作相反,Pavlakos等人[29]首先将三维人体姿态估计作为体素空间中的三维关键点定位问题。最近,Sun等人提出了“积分位姿回归(integral pose regression)” 结合体积热图与soft-argmax activation,并获得了最先进的结果。
此外,还有两阶段方法将三维位姿推理任务分解为两个独立的阶段:估计二维位姿,并将其提升到三维空间[8,24,22,12,47,8,41,23]。这一类别的最新方法使用最先进的2D位姿估计器[7, 44, 25, 18]来获取图像平面上的关节位置。Martinez等人[22]使用一个简单的深度神经网络,可以通过最先进的二维位姿估计器产生的 2D pose估计结果进行三维姿态估计。Pavlakos等人[28]提出了利用节点间的有序深度关系来绕过完全三维监督的想法。
在本分类下的方法需要全三维监督,或者需要在全三维监测的基础上进行额外的监测(如纵坐标深度)
Multi-view methods
此类别中的方法在测试和训练期间都需要多视图输入。早期的工作[1,5,6,3,4]使用标定相机获得的二维位姿估计,通过三角剖分或图像结构模型生成三维位姿。最近,许多研究人员[11, 10]采用深度神经网络对多视图输入进行全三维监督建模。
Weakly/self-supervised methods
由于缺乏3D标注,许多文章[9,31,42,30]研究了基于弱监督/自我监督的人体姿态估计方法。Pavlakos等人使用图形结构模型从多视图图像的关键点热图中获得全局位姿结构。然而,他们的方法需要全标定相机和一个关键点探测器产生二维热图。
Rhodin等人的[31]利用多视图一致性约束来监督网络。他们需要少量的3D真实数据,以避免退化的解决方案(POSE崩溃到单一位置)。因此,缺乏室外三维真实数据是该方法的一个限制因素[31]。
最近引入了深度逆图形网络[38,45]已应用于人体姿态估计问题[42,9]。Tung等人训练了一个生成式对抗网络,该网络通过预测三维位姿的投影与输入二维关节之间的重建损失训练了一个三维姿态发生器,以及训练了一个区分预测的3D pose 与真实3D pose的鉴别器 。在这项工作之后,Drover等人通过修改鉴别器来识别可信的2D投影,消除了对3D真实数据的需要。
据我们所知,只有EpipolarPose和Drover等人的方法不需要任何3D监督或摄像机参数。虽然他们的方法没有利用图像特征,但EpipolarPose利用了图像特征和极对几何,并产生了更准确的结果(误差比Drover等人的方法小4.3毫米)
3 Models and Methods
总体训练方法流程图如图2所示。橙色背景的部分表示推断流程。对于EpipolarPose的训练,假设设置如下。有n台相机(必须满足n≥2)同时拍摄场景中人的照片。摄像机的id从1到n,连续的摄像机彼此接近(即基线较小)。相机产生图像 。然后,连续图像对的集合形成训练样本。
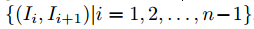
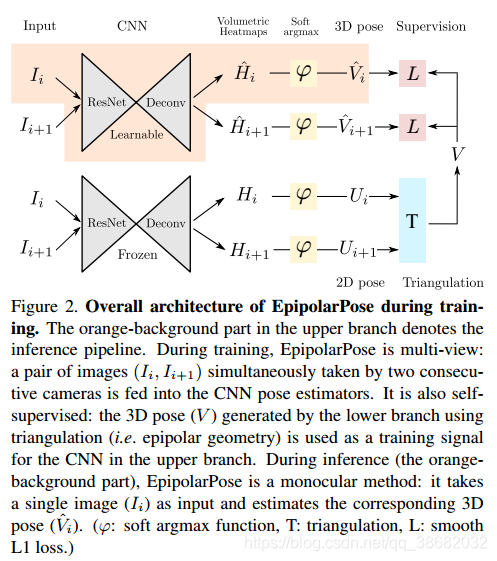
3.1 Training
在EpipolarPose的训练流程中(图2),有两个分支,每个分支以相同的姿态估计网络开始(ResNet后跟反卷积网络[36])。 这些网络在MPII人类姿势数据集(MPII)上进行了预训练[2]。 在训练期间,仅训练上半分支中的姿态估计网络; 另一个被冻结了。
可以使用2台以上的摄像机训练EpipolarPose,但为了简单起见,我们将在此描述n = 2的训练管道。对于n = 2,每个训练样本仅包含一个图像对。图像 分别输入三维(上分支)和二维(下分支)的姿态估计网络,分别地得到体素热图
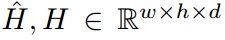
w;h为反卷积后的空间尺寸,d为超参数,定义深度分辨率。应用soft argmax 激活函数 之后,我们得到了3D pose 和 2D pose 。从一张给定的体积热图,可以得到一个三维姿态(通过将softargmax应用于所有3个维度)和2D姿态(只对x, y轴应用softargmax)。作为二维位姿分支的输出,我们要在全局坐标系中得到三维人体姿态 。将第 图片中的 关节的2D坐标表示成为 ,它的3D坐标表示为 ,我们可以用针孔图像投影模型(pinhole image projection model)来描述它们之间的关系。
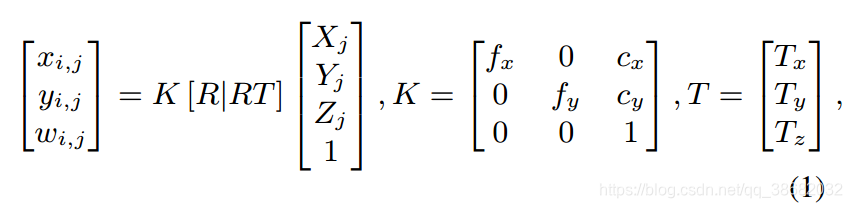
softargmax : https://blog.csdn.net/qq_38682032/article/details/88607568
- : 节点在 图片中的深度(相机作为参考系)
- :编码相机的内部参数 (比如焦距 ,投影中心 )
-
: 相机外部参数 :旋转,平移
(为了简易性忽略相机失真)
当相机外部参数不可用时,通常是在动态捕捉环境下,我们可以使用身体关节作为标定目标。我们假设第一个摄像机是坐标系的中心,这意味着第一个摄像机的R是恒定的。
对于
和
中对应的关节,在图像平面上,
我们用RANSAC算法得到的基本矩阵
,满足以下条件。
我们通过矩阵F,计算必要矩阵
通过SVD分解
,我们得到了
的4种可能解。
我们通过做cheirality check来验证可能的位姿假设,从而确定正确的位姿。cheirality check基本上是指三角形的三维点应该有正的深度[26]。
The cheirality check basically means that the triangulated 3D points should have positive depth
我们在训练中省略了大小,因为我们的模型使用了正则化的姿态作为真值。
最后,为了得到对应的同步二维图像的三维位姿 ,我们利用如下所示的三角剖分(即对极几何)。对所有在图像对 中没有遮挡的节点,使用polynomial triangulation[13] 三角化一个三维点 .
为了计算由上支(3D分支)预测相机帧内三维位姿之间的损失,我们将 投影到对应的相机空间,然后最小化 来训练 3D 分支。
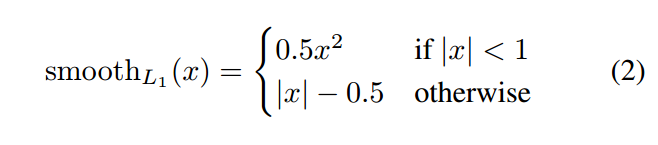
为什么我们需要一个冻结的二维姿态估计器?
在EpipolarPose的训练流程中,有两个分支,每个分支都从一个位姿估计器开始。上分支中的估计器是可训练的,下分支中的另一个估计器是冻结的。下分支估计器的工作是生成二维位姿。有人可能会质疑冻结估计的必要性,因为我们也可以从可训练的上分支获得二维姿态。当我们尝试这样做时,我们的方法产生退化解,其中所有关键点都崩溃到一个位置。事实上,其他多视图方法也面临同样的问题[31,37]。Rhodin等人[31]通过使用一小组ground-truth示例解决了这个问题,然而,在大多数室外环境中,获得这样的ground-truth可能是不可行的。最近提出的另一种解决方案[37]是最小化估计相对旋转(estimated relative rotation) 与真值 之间的角距离(angular distance)。然而,在动态捕获的设置中很难获得ground truth 。为了克服这些缺点,我们只在训练期间使用一个冻结的二维位姿检测器。
3.2 Inference
推断涉及图2中的橙色背景部分。只用输入单张图像,产生3D 体积热图$\hat{H_i},应用soft-argmax 激活函数 ,最终输出估计的3D pose 。
3.3 Refinement, an optional post-training
文献中有几种技术[22,12,40]可以将检测到的二维关键点提升到三维关节中。这些方法能够从模拟的随机摄像机投影产生的动作捕捉(MoCap)数据学习广义的2D→3D映射。将一个细化单元(refinement unit ,RU)集成到我们的自监督模型中,可以进一步提高姿态估计的精度。为了实现这一目标,我们对RU的输入层进行了修改,使其能够接受Epipolarpose的噪声三维检测,并使其学习一种细化策略。(见图3)

整体RU架构的灵感来自[22,12]。它有2个计算块,每个计算块都有一定的线性层,然后是Batch Normalization[15]、Leaky ReLU[21]激活层和Dropout层,将三维噪声输入映射到更可靠的三维位形预测。为了方便各层之间的信息流动,我们添加了残差连接[14],并应用中间损失来方便中间层的监督访问。
3.4 Pose Structure Score
正如我们在第1节中讨论的,传统的评估指标(如MPJPE、PCK)单独对待每个关节,因此不能将整个姿态作为结构进行评估。在图4中我们给出了相对于参考位姿,具有相同MPJPE,但在结构上非常不同的例子。我们提出了一种新的性能度量方法,称为姿态结构评分(PSS)对位姿中的结构误差敏感。PSS计算一个尺度不变的性能评分,能够评估一个姿态相对于其真值的结构合理性。请注意,PSS不是一个损失函数,它是一个性能评分,可以与MPJPE和PCK一起用来描述位姿估计器的表示能力。PSS是一个相对于真实姿态误差指示器,这种误差在后续需要语义意义的姿态任务中(如动作识别、人机交互),有可能导致错误的推理。
给定一个由 个pose组成的真值集合 , ,我们正则化每一个pose向量 .然后我们用k-means聚类方法计算 个聚类中心 然后,为了计算一个预测位姿 对其真值位姿 的PSS,我们使用如下公式
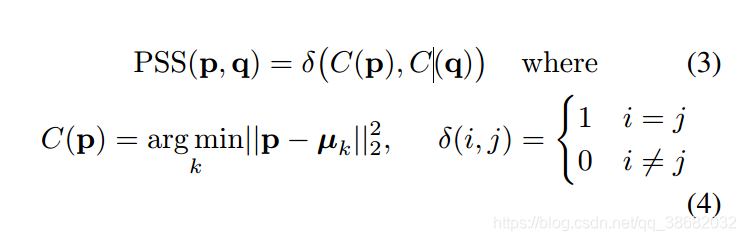
- K-means: K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
一组姿态的PSS是等式(3)中计算出的个例得分的平均值,图5为姿态聚类的t-SNE[43]图。图6描述了表示Human3.6M数据集中典型姿态的聚类中心

在我们的实验中,我们选择了50 和100 数量的pose clusters。我们用PSS@50和PSS@100表达式表示相应的PSS结果。注意,PSS计算正确姿势的百分比,因此得分越高越好。为了测试聚类的稳定性,我们执行了以下操作。我们用随机初始化运行k-均值100次。然后,对于每一次运行,我们在clusters之间建立成对的对应关系。对于每个对应关系,我们计算并集上的交集(IOU,intersection over union)。所有配对和对应关系的平均IOU为0.78。此外,当我们使用不同的kmeans运行时,姿态估计模型的PSS值变化±0:1%。这些分析证明了簇的稳定性
Implementation details
我们使用Intergral Pose[36]架构 二维和三维分支,ResNet-50 [14]作为后端。
- 输入图像 ,
- 输出热图 , J 为 number of joints
- 预训练:在MPII[2]上进行训练后,初始化实验中使用的所有模型。
- mini-batches size:32 (每个样本都包含图片对
)
如果有两个以上的相机可用,我们将所有相机的视图包含在一个mini-batch中。 - epoch:140
- optimizer: Adam [17]
- learning rate: ,在90和120 steps 时乘0.1
- 数据增强:random rotations of ±30◦ and scaled by a factor between 0.8 and 1.2.
此外,我们利用合成遮挡[34]使网络对遮挡关节具有鲁棒性。为了简单起见,我们运行一次2D分支来生成三角化的3D目标,并使用缓存标签训练3D分支。我们使用PyTorch实现了整个流程
[27]。
4 Experiments
Datasets
Human3.6M(H36M)
MPI-INF-3DHP (3DHP)
Metrics
-
MPJPE(mean per joint position error), 平均关节点位置误差
-
PMPJPE (procrustes aligned mean per joint position error),
-
PCK (percentage of correct keypoints)
-
PSS at scales @50 and @100.
为了和[31]对比,还增加了正则化MPJPE,PCK -
NMPJPE
-
NPCK
(实验部分未阅读完)
5 Conclusion
在这项工作中,我们已经证明,即使没有任何三维真值数据和相机的外部参数,多视图图像也可以获得自我监督。作为我们方法的核心,EpipolarPose可以利用从多视图图像获得的二维位姿使用对极几何自监督三维位姿估计器。在弱/自监督方法中,EpipolarPose在Human3.6M和mpi - info - 3d - hp基准测试中取得了最先进的结果。此外,还讨论了基于定位的MPJPE和PCK等度量方法在人体姿态估计任务中的不足
6 Follow Reading
1、对极几何
2、Integral human pose regression (反卷积框架)
3、 2D推测3D的可靠性