IDR: Self-Supervised Image Denoising via Iterative Data Refinement
IDR 是一个无监督降噪模型。
1. noisy-clean pair 比较难获取
noisy-clean pair:
x: noidy image, y: clean image
但是 y比较难获取
noisr-noisy pair
x + n , x
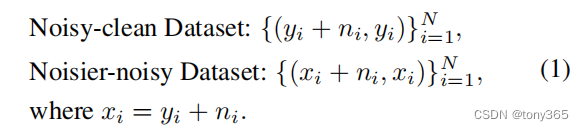
对噪声图像再添加噪声,得到 噪声更大的图像。
这里的n表示的是sensor的噪声模型(也可以是采样得到的,参考作者另一篇论文rethinking noise).
2. noiser-noisy pair 比较容易获取,但是训练效果呢?
作者的两个发现:
2.1 noiser-noisy 训练的模型,能够对 noisy 图像一定程度的降噪
如下图:
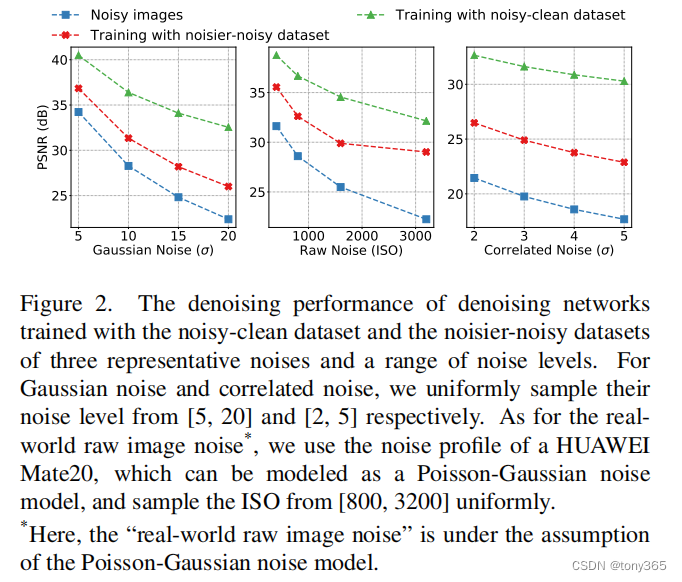
2.2 noiser-noisy数据 越接近 noisy-clean 数据,训练的效果越好。
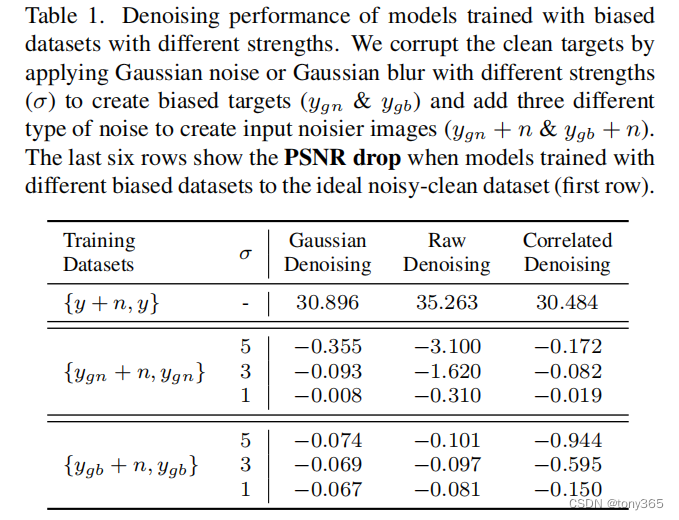
3.通过训练 让noiser-noisy数据 更接近 noisy-clean 数据
1.训练F0,生成新的数据集

2.利用新的数据集训练F1.
由于 新的数据集 更接近 noisy-clean 数据,因此训练的结果对于noisy的表现会更好。
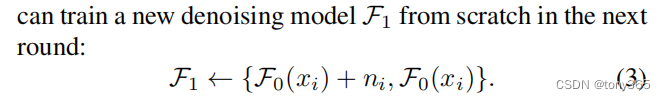
3.因此可以迭代训练,不断生成新的less biased数据集, 训练新的model

4.Fast Iterative Data Refinement
以上迭代训练需要生成多次数据集,训练多次model.
作者提出改进的方案:
a.每个epoch refine一次dataset, 不需要训练到完全收敛
b.利用上个epoch的model初始化下一个epoch的model
*
这样改进下来,和正常训练差别不大了,除了每个epoch要更新一次数据集。
实际的效果如下:
每次迭代,降噪效果都有改善。

5. sensenoise-500 dataset
IMX586, 3000x4000 pixels, low light conditions.
64 帧 = 4 帧 正常曝光noisy image + 60 帧 长曝光(1s-2s) use median value ad ground truth
正常曝光和长曝光的图像如何 保持亮度一致呢?需要设置 iso 和曝光时间:

图像示例:

最终图像数据是1010张(505pairs):
dng是噪声图, npy是groundtruth
5.1 数据集 error
部分ground truth 高亮区域偏红色。
6.训练
4种方案训练sensenoise 500
- pair
- add GP noise
- idr(本文)
- noise2noise: add gp noise
由于不知道数据集的实际噪声参数。因此add noise都是添加的一定范围
k = np.random.uniform(0.8, 3)
scale = np.random.uniform(1, 30)
# k = torch.FloatTensor(k)
# scale = torch.FloatTensor(scale)
in_img1 = add_noise_torch(gt_img, k, scale).to(device)
in_img2 = add_noise_torch(gt_img, k, scale).to(device) # 是否需要转化为int16类型,因为实际raw图数据都是整数
gt_img = gt_img.to(device)
# print(in_img.min(), in_img.max(), in_img.mean(), in_img.var())
# print(gt_img.min(), gt_img.max(), gt_img.mean(), gt_img.var()) # more and more little
gt_img = gt_img / 1023
in_img = in_img1 / 1023
in_img = torch.clamp(in_img, 0, 1)
in_img2 = in_img2 / 1023
in_img2 = torch.clamp(in_img2, 0, 1)
idr训练:
import glob
import os.path
import cv2
import numpy as np
import rawpy
import torch
import torch.optim as optim
from torch import nn
from torch.utils.data import DataLoader
from tqdm import tqdm
from skimage.metrics import peak_signal_noise_ratio as compare_psnr
from skimage.metrics import structural_similarity as compare_ssim
from model import UNetSeeInDark
from sensenoise500 import add_noise_torch
from sid_dataset_sensenoise500 import sensenoise_dataset, apply_wb_ccm, sensenoise_dataset_2, \
sensenoise_dataset_addnoise, sensenoise_dataset_addnoise_2, choose_k_sigma
import torchvision
if __name__ == "__main__":
# 1.当前版本信息
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.get_device_name(0))
np.random.seed(0)
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 2. 设置device信息 和 创建model
model = UNetSeeInDark()
model._initialize_weights()
gpus = [1]
#model = nn.DataParallel(model, device_ids=gpus)
device = torch.device('cuda:1')
model = model.cuda(device=gpus[0])
# 6. 是否恢复模型
resume = 0
last_epoch = 0
lr_epoch = 1
if resume and last_epoch > 1:
model.load_state_dict(torch.load(os.path.join(save_model_dir, f'checkpoint_{
last_epoch:04d}.pth'), map_location=device))
lr_epoch = 0.5**(last_epoch // 500)
# 3. dataset 和 data loader, num_workers设置线程数目,pin_memory设置固定内存
# train_dataset = sensenoise_dataset_addnoise_2(mode='train')
# train_dataset_loader = DataLoader(train_dataset, batch_size=4*len(gpus), shuffle=True, num_workers=8, pin_memory=True)
eval_dataset = sensenoise_dataset_2(mode='eval')
eval_dataset_loader = DataLoader(eval_dataset, batch_size=1, num_workers=8, pin_memory=True)
print('load dataset !')
files = glob.glob(os.path.join('/home/wangzhansheng/dataset/sidd/SenseNoise500/final_datasetv3/', '*.dng'))
files = sorted(files)[:400]
datas = []
for file in files:
input_path = file
txt_path = input_path[:-4] + '.txt'
para = np.loadtxt(txt_path)
wb_gain = np.array(para[:3]).astype(np.float32)
ccm = np.array(para[3:12]).astype(np.float32).reshape(3, 3)
iso = para[-1]
# gt_raw = np.load(gt_path).astype(np.int32)
# gt_raw = np.dstack((gt_raw[0::2, 0::2], gt_raw[0::2, 1::2], gt_raw[1::2, 0::2], gt_raw[1::2, 1::2]))
input_raw = rawpy.imread(input_path).raw_image_visible.astype(np.float32)
input_raw = np.dstack((input_raw[0::2, 0::2], input_raw[0::2, 1::2], input_raw[1::2, 0::2], input_raw[1::2, 1::2]))
datas.append([input_raw, wb_gain, ccm, input_path, iso])
print(file, len(datas))
# 4. 损失函数 和 优化器
loss_fn = nn.L1Loss()
learning_rate = 3*1e-4
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
lr_step = 500
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, lr_step, gamma=0.5)
# 5. hyper para 设置
epochs = 5000
save_epoch = 100
save_model_dir = 'saved_model_sensenoise500_addnoise_single_idr'
eval_epoch = 100
save_sample_dir = 'saved_sample_sensenoise500_addnoise_single_idr'
if not os.path.exists(save_model_dir):
os.makedirs(save_model_dir)
# 7. 训练epoch
epoch_infos = []
eval_infos = []
patch_size = 512
for epoch in range(last_epoch+1, epochs + 1):
print('current epoch:', epoch, 'current lr:', optimizer.state_dict()['param_groups'][0]['lr'])
if epoch < 101:
save_epoch = 10
eval_epoch = 10
else:
save_epoch = 100
eval_epoch = 100
# 8. train loop
model_copy = UNetSeeInDark().to(device)
model_copy.load_state_dict(model.state_dict())
model_copy.eval()
model.train()
g_loss = []
g_psnr = []
kk = 0
for idx in tqdm(np.random.permutation(len(datas))):
data = datas[idx]
#for data in np.random.shuffle(datas):
# gt_path = file
# txt_path = gt_path[:-4] + '.txt'
# para = np.loadtxt(txt_path)
# wb_gain = np.array(para[:3]).astype(np.float32)
# ccm = np.array(para[3:12]).astype(np.float32).reshape(3, 3)
# iso = para[-1]
#
# gt_raw = np.load(gt_path).astype(np.int32)
# iso, k, sigma = choose_k_sigma(iso/2)
# k = k * np.random.uniform(0.8, 1.2)
# sigma2 = np.sqrt(sigma) * np.random.uniform(0.8, 1.1)
# short_raw = k * np.random.poisson(gt_raw / k) + np.random.normal(0., sigma2, gt_raw.shape)
# gt_raw = gt_raw / 1023
# short_raw = short_raw / 1023
input_raw, wb_gain, ccm, gt_path, iso = data
# crop
h, w, c = input_raw.shape
h1 = np.random.randint(0, h - patch_size)
w1 = np.random.randint(0, w - patch_size)
# short_raw = short_raw[h1:h1 + patch_size, w1:w1 + patch_size, :]
short_raw = input_raw[h1:h1 + patch_size, w1:w1 + patch_size, :]
# augment
if np.random.randint(2, size=1)[0] == 1: # random flip
short_raw = np.flip(short_raw, axis=0)
#gt_raw = np.flip(gt_raw, axis=0)
if np.random.randint(2, size=1)[0] == 1:
short_raw = np.flip(short_raw, axis=1)
#gt_raw = np.flip(gt_raw, axis=1)
if np.random.randint(2, size=1)[0] == 1: # random transpose
short_raw = np.transpose(short_raw, (1, 0, 2))
#gt_raw = np.transpose(gt_raw, (1, 0, 2))
#in_img = torch.permute(input_patch, (0,3,1,2)).cuda(device=gpus[0])
short_raw = np.ascontiguousarray(short_raw[np.newaxis, ...])
gt_img = torch.from_numpy(short_raw).permute(0, 3, 1, 2)
if epoch > last_epoch + 1:
model_copy.eval()
with torch.no_grad():
gt_img_last = gt_img.to(device) / 1023
gt_img = model_copy(gt_img_last).cpu()
gt_img = torch.clamp(gt_img* 1023, 0, 1023)
# print(gt_img_last.min(), gt_img_last.max(), gt_img_last.mean(), gt_img_last.var())
# print(gt_img.min(), gt_img.max(), gt_img.mean(), gt_img.var()) # more and more little
if kk > 50000:
im1 = gt_img_last.cpu().float().numpy().squeeze().transpose(1, 2, 0)
im2 = gt_img.float().numpy().squeeze().transpose(1, 2, 0) / 1023
im1 = im1[..., [0, 1, 3]] ** (1 / 2.2)
im2 = im2[..., [0, 1, 3]] ** (1 / 2.2)
im1 = np.clip(im1 * 255 + 0.5, 0, 255).astype(np.uint8)
im2 = np.clip(im2 * 255 + 0.5, 0, 255).astype(np.uint8)
save_sample_dir3 = save_sample_dir + f'/{
epoch:04}dd/'
if not os.path.isdir(save_sample_dir3):
os.makedirs(save_sample_dir3)
filename_save = os.path.basename(gt_path)[:-4]
cv2.imwrite(os.path.join(save_sample_dir3, '%s_dddd1.png' % (filename_save)), im1[..., ::-1])
cv2.imwrite(os.path.join(save_sample_dir3, '%s_dddd2.png' % (filename_save)),
im2[..., ::-1])
iso, k, sigma = choose_k_sigma(iso/2)
# k = np.random.uniform(0.8, 3)
# scale = np.random.uniform(1, 30)
# k = torch.FloatTensor(k)
# scale = torch.FloatTensor(scale)
scale = np.sqrt(sigma)
in_img = add_noise_torch(gt_img, k, scale).to(device)
gt_img = gt_img.to(device)
# print(in_img.min(), in_img.max(), in_img.mean(), in_img.var())
# print(gt_img.min(), gt_img.max(), gt_img.mean(), gt_img.var()) # more and more little
gt_img = gt_img / 1023
in_img = in_img / 1023
in_img = torch.clamp(in_img, 0, 1)
# print(gt_img.shape, gt_img.min(), gt_img.max())
# print(in_img.shape, in_img.min(), in_img.max())
# print(wb_gain, ccm, iso, gt_path)
out = model(in_img)
loss = loss_fn(out, gt_img)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# training result
g_loss.append(loss.data.detach().cpu())
mse_value = np.mean((out.cpu().data.numpy() - gt_img.cpu().data.numpy()) ** 2)
psnr = 10. * np.log10(1. / mse_value)
g_psnr.append(psnr)
mean_loss = np.mean(np.array(g_loss))
mean_psnr = np.mean(np.array(g_psnr))
print(f'epoch{
epoch:04d} ,train loss: {
mean_loss},train psnr: {
mean_psnr}')
epoch_infos.append([epoch, mean_loss, mean_psnr])
# 9. save model
if epoch % save_epoch == 0:
save_model_path = os.path.join(save_model_dir, f'checkpoint_{
epoch:04d}.pth')
torch.save(model.state_dict(), save_model_path)
# 10. eval test and save some samples if needed
if epoch % eval_epoch == 0:
model.eval()
k = 0
with torch.no_grad():
psnr_12800_0 = []
psnr_12800_1 = []
ssim_12800_0 = []
ssim_12800_1 = []
for data in tqdm(eval_dataset_loader):
input_patch, gt_patch, wb_gain, ccm, gt_path, iso = data
in_img = input_patch.permute(0, 3, 1, 2).cuda(device=gpus[0])
gt_img = gt_patch.permute(0, 3, 1, 2).cuda(device=gpus[0])
out = model(in_img)
im1 = gt_img.detach().cpu().float().numpy().squeeze().transpose(1,2,0)
im2 = out.detach().cpu().float().numpy().squeeze().transpose(1,2,0)
im1 = np.clip(im1 * 255 + 0.5, 0, 255).astype(np.uint8)
im2 = np.clip(im2 * 255 + 0.5, 0, 255).astype(np.uint8)
temp_psnr = compare_psnr(im1, im2, data_range=255)
temp_ssim = compare_ssim(im1, im2, data_range=255, channel_axis=-1)
if iso <= 12800:
psnr_12800_0.append(temp_psnr)
ssim_12800_0.append(temp_ssim)
else:
psnr_12800_1.append(temp_psnr)
ssim_12800_1.append(temp_ssim)
# show training out
save_img = 1
if save_img and k<10:
k += 1
im_input = in_img.detach().permute(0, 2, 3, 1).cpu().float().numpy()[0]
im_gt = gt_img.detach().permute(0, 2, 3, 1).cpu().float().numpy()[0]
im_out = out.detach().permute(0, 2, 3, 1).cpu().float().numpy()[0]
wb_gain = wb_gain.data.cpu().numpy()[0]
ccm = ccm.data.cpu().numpy()[0]
gt_path = gt_path[0]
pattern_sensenoise500 = 'RGGB'
im_input_srgb = apply_wb_ccm(im_input[..., [0, 1, 3]], wb_gain, ccm, pattern_sensenoise500)
im_gt_srgb = apply_wb_ccm(im_gt[..., [0, 1, 3]], wb_gain, ccm, pattern_sensenoise500)
im_out_srgb = apply_wb_ccm(im_out[..., [0, 1, 3]], wb_gain, ccm, pattern_sensenoise500)
im_input_srgb = np.clip(im_input_srgb * 255 + 0.5, 0, 255).astype(np.uint8)
im_gt_srgb = np.clip(im_gt_srgb * 255 + 0.5, 0, 255).astype(np.uint8)
im_out_srgb = np.clip(im_out_srgb * 255 + 0.5, 0, 255).astype(np.uint8)
save_sample_dir2 = save_sample_dir + f'/{
epoch:04}/'
if not os.path.isdir(save_sample_dir2):
os.makedirs(save_sample_dir2)
# save_sample_path = os.path.join(save_sample_dir2, os.path.basename(gt_path)[:-4]+'.png')
# cv2.imwrite(save_sample_path, np.hstack((im_gt_srgb,im_input_srgb, im_out_srgb))[..., ::-1])
filename_save = os.path.basename(gt_path)[:-4]
cv2.imwrite(os.path.join(save_sample_dir2, '%s_psnr_%.2f_out.png' % (filename_save, temp_psnr)), im_out_srgb[...,::-1])
cv2.imwrite(os.path.join(save_sample_dir2, '%s_NOISY.png' % (filename_save)), im_input_srgb[...,::-1])
cv2.imwrite(os.path.join(save_sample_dir2, '%s_GT.png' % (filename_save)), im_gt_srgb[...,::-1])
print('eval dataset psnr: ', np.array(psnr_12800_0).mean(), np.array(psnr_12800_1).mean())
print('eval dataset ssim: ', np.array(ssim_12800_0).mean(), np.array(ssim_12800_1).mean())
eval_infos.append([epoch, np.array(psnr_12800_0).mean(), np.array(psnr_12800_1).mean(), np.array(ssim_12800_0).mean(), np.array(ssim_12800_1).mean()])
scheduler.step() # 更新学习率
np.savetxt('train_infos.txt', epoch_infos, fmt='%.4f') # epoch loss psnr
np.savetxt('eval_infos.txt', eval_infos, fmt='%.4f') # epoch psnr, ssim