目录
0 摘要
1 导入包与加载数据
2 数据可视化分析
3 特征工程
4 LR初步建模与结果
5 优化方法---重新进行特征工程 选特征、 模型融合
6 总结
0.摘要
最近利用两周多的时间准备做了一下kaggle上的第一个热门比赛,链接为Kaggle的Titanic幸存预测。
这是一个基本的二分类问题,下面就这一分类问题竞赛的处理思路及代码实现,包括探索性数据分析,特征工程,缺失值填充和模型调优等方面进行描述。
语言:Python; 工具:pycharm+jupyter notebook(这个可以一步步运行实时显示每步的结果很方便) ; 所用的库来自:anaconda(建议新手下载,不需要一个个库自己安装,里面包含绝大部分python库) 。下载安装步骤可以百度
1.导入包与加载数据
注意一下,可视化分析过程中中文显示可能出问题,注意加上最后的代码
#数据处理
import pandas as pd
import numpy as np
import random
import sklearn.preprocessing as prescessing
#可视化
import matplotlib.pyplot as plt
import seaborn as sns
#内嵌画图
%matplotlib inline
#ML
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import GradientBoostingClassifier,GradientBoostingRegressor,RandomForestClassifier,RandomForestRegressor
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import learning_curve
#各种模型、数据处理方法
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
from sklearn.metrics import precision_score
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curve
import os
##############
##############
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf',size=14)
sns.set(font=myfont.get_name())
#coding:utf-8
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号os.chdir('G:\\我的坚果云\\4-计算机\\数据分析与挖掘\\kaggle1-泰坦尼克预测\\')
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')#训练数据总预览 ,同理测试数据也是一样的方法
train.head(3)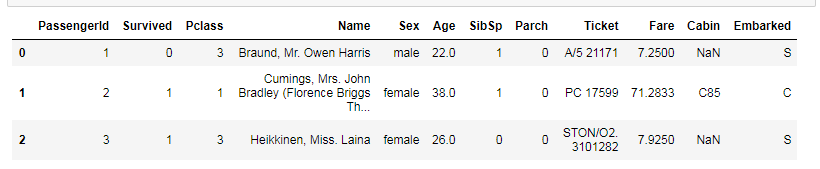
相关系数矩阵(如下)可以查看各属性之间的相关关系,主要看survived与其他数值型属性的关系,
颜色数表越接近1,存在强的正相关关系;反之,越接近-1,存在强的负相关关系。
sns.set(context="paper", font="monospace",style="white")
f, ax = plt.subplots(figsize=(8,6))
train_corr = train.drop('PassengerId',axis=1).corr() #.corr() 计算相关系数矩阵,只负责数值型的数据列
sns.heatmap(train_corr, ax=ax, vmax=.9, square=True)
ax.set_xticklabels(train_corr.index, size=15)
ax.set_yticklabels(train_corr.columns[::-1], size=15)
ax.set_title('train feature corr', fontsize=20)
# plt.show()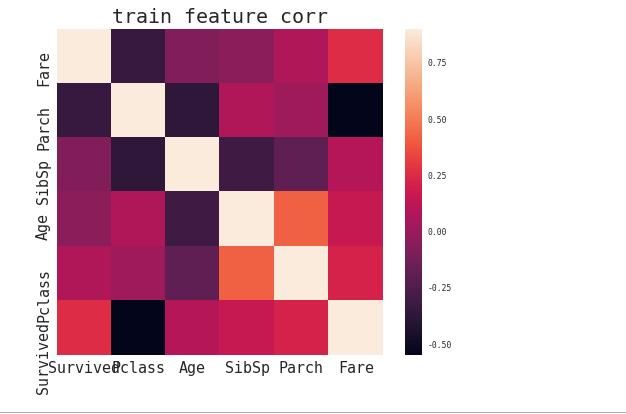
一共十个属性,分别是:
Age:年龄
Sex: 性别
Name: 名字(里面包含尊称等信息)
Ticket : 船票编号
Cabin : 客舱号
Embarked : 登船港口(1起点S:Southampton,经过点C:Cherbourg,2起点Q:Queenstown)
Fare : 船票价格
Parch : 船上父母/子女数(不同代直系亲属数)
SibSp : 船上兄弟姐妹数/配偶数(同代直系亲属数)
Pclass : 客舱等级(1表示1等舱)
分类的结果:
Survived : 生存情况(1=存活, 0=死亡)
2. 数据可视化分析
2.1 年龄这一属性
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf',size=14)
sns.set(font=myfont.get_name())
#coding:utf-8
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#################
fig,(ax1,ax2,ax3) = plt.subplots(3,1,figsize=(8,5))
sns.set_style('white')
sns.distplot(train.Age.fillna(-20), rug=True,kde=False, color='b', ax=ax1) #用指定值或插值方法(如ffill和bfill)填充缺失数据
ax1.set_title('年龄分布')
ax1.set_xlabel('')
ax2.set_title('获救/未获救下年龄分布')
k1 = sns.distplot(train[train.Survived==0].Age.fillna(-20), hist=False, color='b', ax=ax2, label='dead')
k2 = sns.distplot(train[train.Survived==1].Age.fillna(-20), hist=False, color='r', ax=ax2, label='alive')
ax2.set_xlabel('')
ax3.set_title('不同性别下的年龄分布')
sns.distplot(train[train.Sex == 'female'].dropna().Age, hist=False, color='pink',label='female')
sns.distplot(train[train.Sex == 'male'].dropna().Age, hist=False, color='green', label='male')
ax3.set_xlabel('')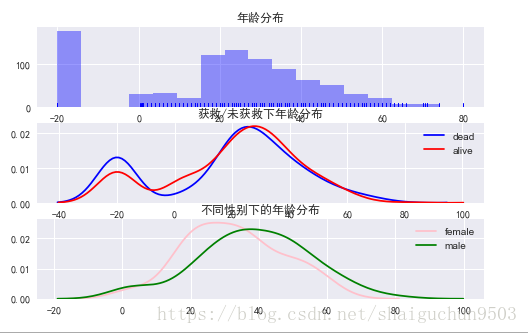
分析:
1、年龄缺失情况严重!年龄缺失的我们用-20代替,然后做如上图所示的年龄分布图以及各年龄下的存活情况分布图
2、发现age与survived不是线性关系, 3、缺失数据来看,获救的的人中缺失的数据少
2.2 Pclass(仓位等级)这一属性
##画出pclass下存活情况的柱状图
y_dead = train[train.Survived == 0].groupby('Pclass')['Survived'].count()
y_alive = train[train.Survived == 1].groupby('Pclass')['Survived'].count()
a =train[train.Survived == 0].groupby('Pclass')['Survived']
y_dead
pos = [1,2,3]
ax = plt.figure(figsize=(6,3)).add_subplot(111)
ax.bar(pos, y_dead, color='blue', label='dead')
ax.bar(pos, y_alive, color='red',bottom=y_dead, label='dead')
ax.set_xticks(pos)
ax.set_xticklabels(['Pclass%d'%(i) for i in range(1,4)])
ax.set_title('Pclass survived count')
#####################各船舱pclass下,年龄分布情况,三张图表示三个仓
agelist = []
for pclass_num in range(1,4):
for survived_ in range(0,2):
agelist.append(train[(train.Pclass==pclass_num)& (train.Survived==survived_)].Age.values)
#agelist 列表内是六个array一维数组
fig,axes = plt.subplots(3,1,figsize=(10,6))
i_pclass=1
for ax in axes:
sns.distplot(agelist[i_pclass*2-2],hist=False, ax= ax, label='Pclass:%d,survived:0'%(i_pclass), color='b')
sns.distplot(agelist[i_pclass*2-1],hist=False,ax= ax, label='Pclass:%d,survived:1'%(i_pclass), color='r')
i_pclass+=1
ax.set_xlabel('age', size=15)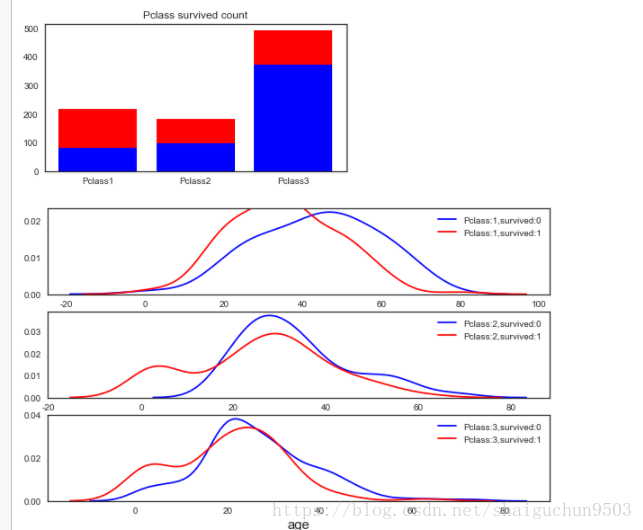
分析 :
头等舱(Pclass=1)、商务舱(Pclass=2)、屌丝仓(Pclass=3)人数对比 :
1、pclass3屌丝仓人数最多,1,2等仓人数相近。
2、从获救比例来看, 头等舱遥遥领先, 屌丝仓死亡比例相当惊人。
3、由第二张图知 头等舱仓位1获救人中年轻人偏多,集中在30-40岁 4、中等仓和3等仓小孩的获救率还可以
2.3、Sex 性别 这一属性
#查看各性别的人数 以及 获救的概率
print(train.Sex.value_counts()) #value_counts 直接用来计算series、dataframe里面相同数据出现的频率
print('********************************************')
print(train.groupby('Sex')['Survived'].mean())
###########各性别中获救、非获救情况的年龄分布
ax = plt.figure(figsize=(8,4)).add_subplot(111)
sns.violinplot(x='Sex', y='Age', hue='Survived', data=train.dropna(), split=True)
ax.set_xlabel('Sex',size=20)
ax.set_xticklabels(['Female','male'], size=18)
ax.set_ylabel('Age',size=20)
ax.legend(fontsize=25,loc='best')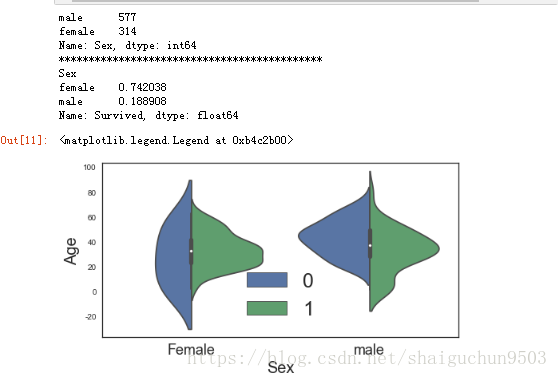
分析:
1、人数来看:男性为主,577个 ,占比65%
2、女性生存的概率相当高,为74% 3、从图看出,女性中生存者主要在20-40岁,男性中同样同样集中在年轻人甚至小孩子
2.4、分析Fare 票价 这一属性
fig = plt.figure(figsize=(6, 2))
ax = plt.subplot(111)
# ax.tick_params(labelsize=15)
# sns.kdeplot(train.Fare, ax=ax)
sns.distplot(train.Fare, ax=ax)
ax.legend(fontsize=15)
pos = range(0,400,50)
ax.set_xticks(pos)
ax.set_xlim([0, 200])
ax.set_ylabel('dist', size=20)
ax.set_xlabel('Fare')
ax.set_title('Fare dist', size=20)
#####################
fig = plt.figure(figsize=(6,2))
ax = plt.subplot(111)
sns.distplot(train[train.Survived == 0].Fare,hist=False, label='dead', color='b')
sns.distplot(train[train.Survived == 1].Fare,hist=False, label='alive', color='r')
# ax1.set_xlim([0,300])
# ax1.legend(fontsize=15)
ax1.set_title('Fare survived', size=20)
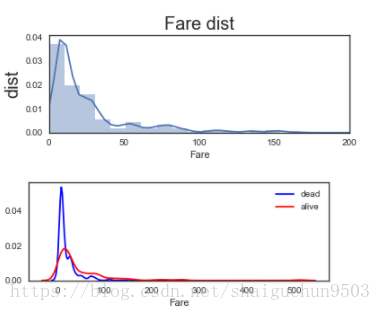
分析: 1、买票的人中低价票占比最多
2、高价票获救更容易,因为高价时获救密度曲线比非获救密度大
2.5、分析sibsp与parch 表系亲属与直系亲属人数 这一属性
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(211)
sns.countplot(train.SibSp)
ax1.set_title('SibSp', size=20)
ax2 = fig.add_subplot(212, sharex=ax1)
sns.countplot(train.Parch)
ax2.set_title('Parch', size=20)
#############################
fig = plt.figure(figsize=(10,6))
ax1 = fig.add_subplot(311)
train.groupby('SibSp')['Survived'].mean().plot(kind='bar', ax=ax1)
ax1.set_title('Sibsp Survived Rate', size=16)
ax1.set_xlabel('')
ax2 = fig.add_subplot(312)
train.groupby('Parch')['Survived'].mean().plot(kind='bar', ax=ax2)
ax2.set_title('Parch Survived Rate', size=16)
ax2.set_xlabel('')
ax3 = fig.add_subplot(313)
train.groupby(train.SibSp+train.Parch)['Survived'].mean().plot(kind='bar', ax=ax3)
ax3.set_title('Parch+Sibsp Survived Rate', size=16)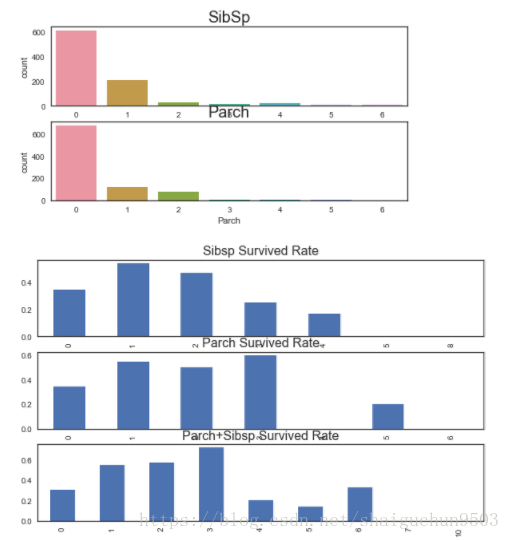
分析:
1、大多数都没有亲戚,表亲1个居多,直系亲戚1,2个居多
2、分组统计不同人数亲戚的获救率来看,都近似呈现先高后低, 亲人数目多少和是否获救不是简单的线性关系
2.6、分析Embark 上岸地点 这一属性
ax = plt.figure().add_subplot(111)
x = ['C','Q','S']
y1 = train[train.Survived == 0].groupby('Embarked')['Survived'].count()
y2 = train[train.Survived == 1].groupby('Embarked')['Survived'].count()
ax.bar(x, y1, color='b', label='dead')
ax.bar(x, y2, color='r', label='alive',bottom=y1)
ax.set_title('Embarked survived count', size=18)
ax.legend()#不加没有图例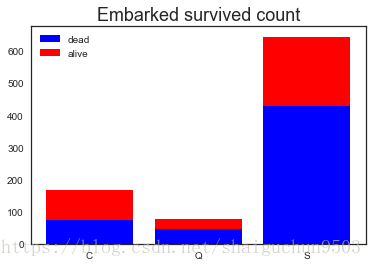
分析: 前往S岸准备登岸的人最多,获救的人也最多;但是C岸是获救比率最高的
2.7、分析Cabin 船舱号 这一属性
print(train.Cabin.isnull().value_counts()) #看看cabin属性为空的是多少
print(train.groupby(train.Cabin.isnull())['Survived'].mean())#查看cabin各属性值下的获救比率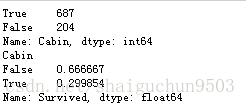
分析:
cabin缺失情况严重,在为空时获救概率较低,不为空时获救概率高
注意 这里值得处理与深挖,缺失值怎么处理,有的cabin值为多个怎么处理?
2.8、分析Ticket 船票号 这一属性
print(train.Ticket.head())
print('*******************************')
print(train.Ticket.nunique()) #查看该属性有没有重复的,结果表示共681个不同的结果,而实际共891条数据,所以存在重复的
print('*********************************')
##发现有的船票号有字母,有的没有,下面分析一下存活情况区别
def word_survived(x):
import re
pattern = re.compile('[a-z]|[A-Z]')
try :
re.search(pattern, x).group()
return 1
except:
return 0
train['Ticket_e'] = train.Ticket.apply(lambda x:word_survived(x))
train.groupby('Ticket_e')['Survived'].mean()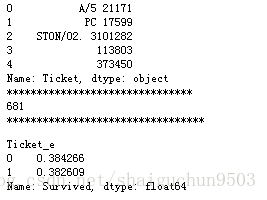
分析:票价这一特征由一开始知没有缺省数据,但是有200多个数据是重复的(681项是唯一的)
2.9、分析name 名字 这一属性

分析:名字差异性很大,感觉没多大收益价值。提取出称谓可能蕴含地位年龄等信息可以作为备选集使用
3. 特征工程
#训练集、测试集查看数据的缺失情况
del train['Ticket_e'] #删除上面的增加的一列
print ('***********Train*************')
print ('test')
print (train.isnull().sum())
print ('***********test*************')
print (test.isnull().sum())

分析:
1、age cabin在训练集和待预测集中均有缺失,cabin缺失的个数很多
2、embarked 在训练集中有2个缺失值 3、另外测试集中fare缺失一个
下面要考虑怎么处理这些缺失值
由上部分分析我们先去掉name、ticket这俩属性用剩下的特征建模,这俩特征暂时不作为模型训练特征
3.1、首先我们对缺失数据进行处理,
分别是: embarked用众数填充, cabin为空、不为空作为新特征 age离散化
3.1.1 对embarked进行处理
##1.1 对embarked进行处理
print(train[train.Embarked.isnull()])###shouxian查看缺失的这俩个数据各属性以及结果是什么情况
print('#################################')
print(train.Embarked.value_counts())#查看各登岸区的情况
print('************************')
print(train[train.Pclass == 1].Embarked.value_counts())#因为缺失的两个人都是头等舱,查看一下头等舱去哪个位置登岸的最多,选择最多的进行填充
#由上面知 ,采用’众数填充法‘,直接填充缺失embarked值为’S‘
train.Embarked.fillna('S',inplace =True) #加上inplace=TRUE 结果不显示打印
3.1.2 对缺失的cabin进行处理
train['Cabin'] = train['Cabin'].isnull().apply(lambda x:'Null' if x is True else 'Not Null')
test['Cabin'] = train['Cabin'].isnull().apply(lambda x:'Null' if x is True else 'Not Null')train.head()
3.1.3 对缺失的年龄age进行处理
为空的归为一类
分类的按年龄分段进行离散
#以5岁为一个周期离散,同时10以下,60岁以上的年分别归类
def age_map(x):
if x<10:
return '10-'
if x<60:
return '%d-%d'%(x//5*5, x//5*5+5)
elif x>=60:
return '60+'
else:
return 'Null'
train['Age_map'] = train['Age'].apply(lambda x: age_map(x))
test['Age_map'] = test['Age'].apply(lambda x: age_map(x))
#打印出来看看
train.groupby('Age_map')['Survived'].agg(['count','mean'])

3.1.4 test集对缺失Fare的处理
test[test.Fare.isnull()] #查看缺失数据的特征是啥样的,考虑下面怎么补全
test.loc[test.Fare.isnull(),'Fare']=test[(test.Pclass==3)&(test.Embarked=='S')&(test.Sex=='male')].dropna().Fare.mean() 
3.2 对数据Fare做scaling处理, 因为分布太广,处理后可加速模型的收敛速度
import sklearn.preprocessing as preprocessing
#将范围标准化到(-1,1)
scaler = preprocessing.StandardScaler()
#Fare
fare_scale_param = scaler.fit(train['Fare'].values.reshape(-1, 1))
train.Fare = fare_scale_param.transform(train['Fare'].values.reshape(-1, 1))
test.Fare = fare_scale_param.transform(test['Fare'].values.reshape(-1, 1))
3.3 将类别变量全部onehot
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。 例如:
自然状态码为:000,001,010,011,100,101
独热编码为:000001,000010,000100,001000,010000,100000
可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
解决了分类器不好处理属性数据的问题
在一定程度上也起到了扩充特征的作用
train_x = pd.concat([train[['SibSp','Parch','Fare']], pd.get_dummies(train[['Pclass','Sex','Cabin','Embarked','Age_map']])],axis=1)
train_y = train.Survived
test_x = pd.concat([test[['SibSp','Parch','Fare']], pd.get_dummies(test[['Pclass', 'Sex','Cabin','Embarked', 'Age_map']])],axis=1)
4 LR初步建模与结果
base_line_model = LogisticRegression()
param = {'penalty':['l1','l2'], 'C':[0.1, 0.5, 1.0,5.0]}
grd = GridSearchCV(estimator=base_line_model, param_grid=param, cv=5, n_jobs=3) #网格搜索算法是一种通过遍历给定的参数组合来优化模型表现的方法。
grd.fit(train_x, train_y)
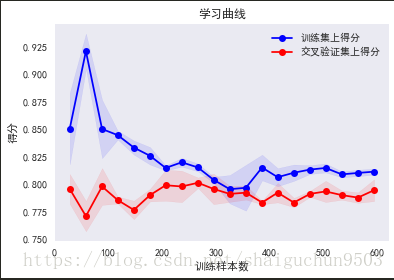
查看模型欠拟合过拟合情况
train_sizes, train_scores, test_scores = learning_curve(grd, train_x,train_y, cv=None, n_jobs=1,train_sizes=np.linspace(.05, 1., 20), verbose=0)
# train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True)
title ='学习曲线'
ylim=None
plot=True
train_scores_mean = np.mean(train_scores, axis=1) #axis=0表示列,1表示行
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u'训练样本数')
plt.ylabel(u'得分')
# plt.gca().invert_yaxis()#翻转y轴并得到当前轴,此处y轴小数在上
# plt.gca()
plt.grid() #显示网格
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b") #yansetianchong
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")#图例
# plt.draw()
plt.show()
# plt.gca().invert_yaxis()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_
保存文件
gender_submission = pd.DataFrame({'PassengerId':test['PassengerId'].as_matrix(),'Survived':grd.predict(test_x).astype(np.int32)})
gender_submission.to_csv('./gender_submission_LRmodel.csv', index=None)
5 优化方法---重新进行特征工程 选特征、 模型融合
5.1 数据分析回顾与特征整理
1 Sex Feature:女性幸存率远高于男性
2 Pclass Feature:乘客船舱等级越高,幸存率越高
3 SibSp Feature:配偶及兄弟姐妹数适中的乘客幸存率更高
4 Parch Feature:父母与子女数适中的乘客幸存率更高
5 Age Feature:未成年人幸存率高于成年人
6 Fare Feature:支出船票费越高幸存率越高
7 Title Feature(New,从名字中提取出的):不同称呼的乘客幸存率不同
8 FamilyLabel Feature(New,从3和4的特征综合FamilySize=Parch+SibSp+1):家庭人数为2到4的乘客幸存 率较高
9 Deck Feature(New,利用cabin船舱号提取出):不同甲板的乘客幸存率不同,先把Cabin空缺值填充为'Unknown',再提取Cabin中的首字母构成乘客的甲板号
10 TicketGroup Feature(New 从Ticket船票属性提取出):与2至4人共票号的乘客幸存率较高,新增TicketGroup特征,统计每个乘客的共票号数。按生存率把TicketGroup分为三类。
11 embarked登陆港口这一属性也有影响
12 Pclass : 客舱等级(1表示1等舱)
用上面的特征进行新的模型建模。新添加了4组特征,其中7/9为分类数据类型,8/10为数值型数据类型。
没有选择的特征是:Name(从中选取了新特征,该特征没用了踢掉)、Ticket改为新属性、Cabin也是提取了新特征
5.2数据清洗
缺失值处理---------------
1、Age Feature:Age缺失量为263,缺失量较大,用Sex, Title, Pclass三个特征构建随机森林模 ??????(为啥)
2. Embarked Feature:Embarked缺失量为2,缺失Embarked信息的乘客的Pclass均为1,且Fare均为80,# 因为Embarked为C且Pclass为1的乘客的Fare中位数为80,所以缺失值填充为C。
3. Fare Feature:Fare缺失量为1,缺失Fare信息的乘客的Embarked为S,Pclass为3,# 所以用Embarked为S,Pclass为3的乘客的Fare中位数填充。
#把姓氏相同的乘客划分为同一组,从人数大于一的组中分别提取出每组的妇女儿童和成年男性。
特征转换
选取特征,转换为数值变量,划分训练集和测试集。
all_data=all_data[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','FamilyLabel','Deck','TicketGroup']]
all_data = pd.get_dummies(all_data)
train=all_data[all_data['Survived'].notnull()]
test=all_data[all_data['Survived'].isnull()].drop('Survived',axis=1)
X = train.as_matrix()[:,1:]
y = train.as_matrix()[:,0]
5.3建模
1)参数优化
#用网格搜索自动化选取最优参数,事实上我用网格搜索得到的最优参数是n_estimators = 28,max_depth = 6。
2)训练模型
select = SelectKBest(k = 20)
clf = RandomForestClassifier(random_state = 10, warm_start = True,
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
pipeline = make_pipeline(select, clf)
pipeline.fit(X, y)
3)交叉验证
cv_score = cross_validation.cross_val_score(pipeline, X, y, cv= 10)
print("CV Score : Mean - %.7g | Std - %.7g " % (np.mean(cv_score), np.std(cv_score)))
5.4预测
对测试集进行分类,最终实现最好成绩挤进前百分之2

