文章目录
摘要
(1)文本做的是文本识别
(2)在以前的研究中,文本检测和识别是分离的。
(3)本文设计了一个端到端的文本识别框架,它将文本检测和文本识别与文本内核相结合,集成了全局文本特征信息,从多个尺度上优化识别,降低了检测的依赖性,提高了系统的鲁棒性。
(4)识别准确率的结果如下
| 数据集 | 行级 | 页级 |
|---|---|---|
| CASIA-HWDB2.0-2.2 | 99.12% | 99.03% |
| ICDAR-2013 | 94.27% | 94.20% |
1. Introduction
(1)最近几年中,手写文本识别方法有两种类型,即页级识别方法和行级识别方法。对于离线的中文手写文本识别,大多数研究都是基于行级文本识别。
(2)针对行级识别方法,主要分为两种研究方向:
-
过分割方法
过分割方法首先将文本行图片分割为一系列基本段,然后将这些段组合生成候选字符模式,形成一个分割候选格,并对每个候选模式进行分类,以分配几个候选字符类来生成一个字符候选格。Wang Q F等人[1]首先从贝叶斯决策的视角提出了过分割的方法,并通过置信变换将分类器的输出转换为后验概率。Song W等人提出了一种利用异构CNN的深度网络,从分割候选格中获取层次监督信息。
过分割方法的局限性:
如果文本行分割不正确,就会给后续的识别带来很大的困难。
-
无分割方法
基于深度学习的无分割方法就是来解决“过分割方法的局限性”的。Messina等人的[3]提出了多维长-短期记忆递归神经网络(MDLSTM-RNN),使用连接员时间分类器[4](CTC)作为端到端文本行识别的损失函数。Xie[5]等人[5]提出了一种CNN-ResLSTM模型,通过数据预处理和增强管道对文本图片进行校正,以优化识别。Xiao等[6]提出了一种带有像素级整正的深度网络,将像素级整正集成到CNN和基于RNN的识别器中。
(3)针对页级识别方法,主要分为“两阶段识别法”和“端到端识别法”:
-
两阶段识别法
两阶段识别法分别应用两种模型对文本检测和文本识别,通常首先检测文本行,然后剪出文本行进行识别。Li X等人[7]提出了基于分段的PSENet,通过逐步尺度扩展来检测任意形状的文本线。Liu Y等人[8]提出了基于三阶贝塞尔曲线的ABCNet用于曲线文本线检测。Liao M等人[9]提出了Mask TextSpotter v3,它具有分段建议网络(SPN)和硬RoI掩蔽功能,可用于鲁棒的场景文本定位。
-
端到端识别法
端到端方法逐渐将图像压缩成几行或一整行特征图进行识别。主要注意的是,不检测文本行的页级识别方法丢失了文本位置的信息。
无论是行级识别还是两阶段识别方法,都是先确定文本行的位置信息,再去进行文本行的分割和识别。即将检测和识别分离开。
(3)本文思路
-
我们认为检测和识别不应该被分开
检测只能提供文本行的位置信息,这使得在识别期间很难利用全局文本信息。无论检测框相对真实文本行是大是小,都会影响后面的识别。这是因为文本行图像的对齐是在原始文本页面图像中,其鲁棒性不足以进行识别。而对文本行的检测非常重要,如果不能很好地检测到文本行,就无法准确地识别文本行图像。
我们认为,文本识别的关键在于准确地识别文本,我们只需要知道文本的大致位置,而不是精确的检测。 在本文中,我们提出了一种具有鲁棒性的端到端文本核分割和文本页面识别框架,以统一文本检测和识别。
(4)本文贡献
- 我们提出了一种新的端到端文本页面识别框架,它利用全局信息来优化检测和识别。
- 本文提出了一种基于中心线的文本线与文本核对齐的方法,并基于中心线从特征映射中提取文本线条。
- 我们提出了一种具有多尺度信息集成的文本线识别模型,它使用TCN和Self-attention来代替RNNs。
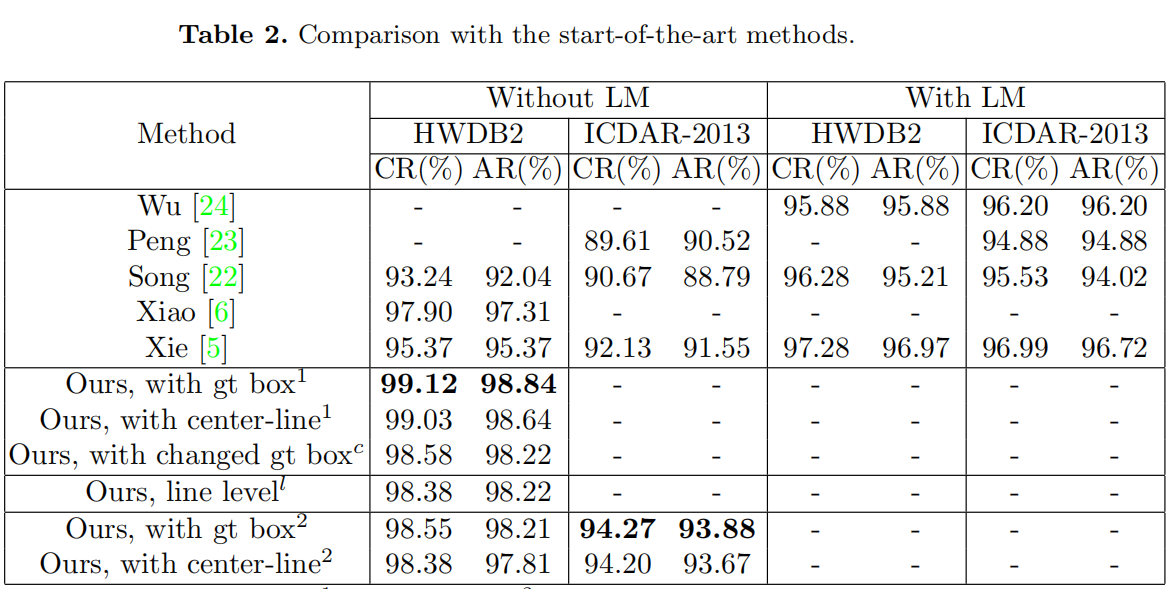
- 我们已经做了一系列的实验来验证我们的模型的有效性,并与其他最先进的方法进行了比较。我们在CASIA-HWDB数据集和ICDAR-2013数据集上都实现了最先进的性能。该方法的页面级识别性能甚至优于行级识别方法。
2. Method
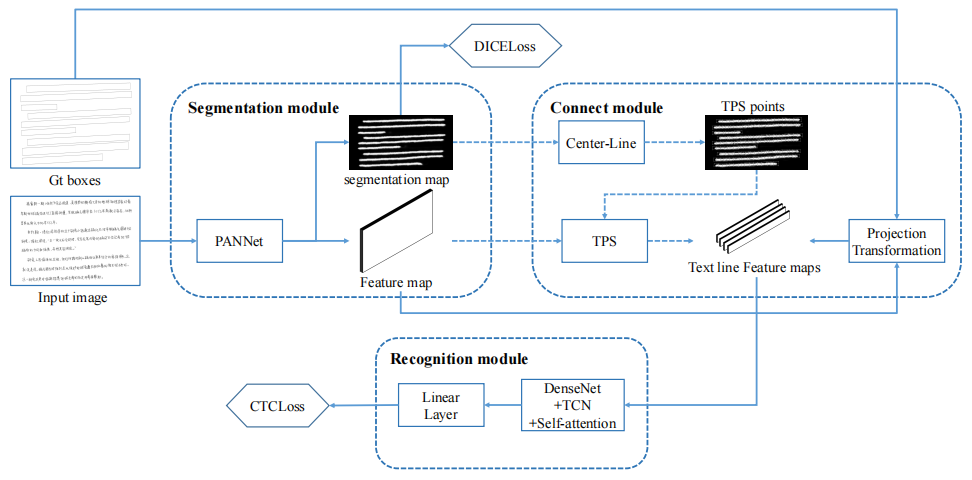
我们的方法框架如图2所示。该框架由三个用于文本检测和识别的模块组成。分割模块用于生成文本行核心区域的分割图和文本页面的特征图。引入连接模块,根据分割图提取文本行特征图。识别模块基于DenseNet[15]和TCN以及Self-attention。
识别结果如下:

2.1 Segmentation module
分割模块对输入的图像进行处理,生成具有原始图像大小四分之一的特征图和分割图。在这部分中,我们主要利用PANNet [12]的网络结构,使其在任意形状的文本分割上具有良好的性能。我们使用ResNet34 [13]作为其主干,并将主干生成的4个特征图对输入图像的步幅更改为4、4、8、8。我们提取更大的特征图,因为我们需要细粒度的特征信息来进行文本识别。
我们保留了PANnet的特征金字塔增强模块(FPEM)和特征融合模块(FFM),用于提取和融合不同尺度的特征信息,FPEM的重复次数为4次。
我们设置的文本行内核区域的大小是原始大小的0.6,这足以区分不同的文本行区域。
2.2 Connection module
利用连接模块根据分割图提取文本线特征图。我们认为特征图比原始图像包含高维信息,并且特征图可以在核心区域收集文本信息,这使文本线特征图的提取更具有鲁棒性。我们以核区域为中心,随机变换特征映射,如透视变换,使文本特征信息集中在核区域。我们将所有的文本线特征映射缩放到32像素的高度,以进行后续识别。
我们假设文本线是一条条带,它的中心线可以被认为是通过每个字符的中心线。一般来说,文本行的长度大于其高度,并且每个文本行都有一条中心线。我们使用文本线带的内切圆来找到文本的中心线。我们假设文本线带的最大内切圆的中心落在文本的中心线上。在训练过程中,我们使用透视转换来根据真实文本框对齐文本线。对齐的文本线特征图在内部方向进行随机仿射变换,进行数据增强,使模型学习将文本特征信息集中在核心区域。
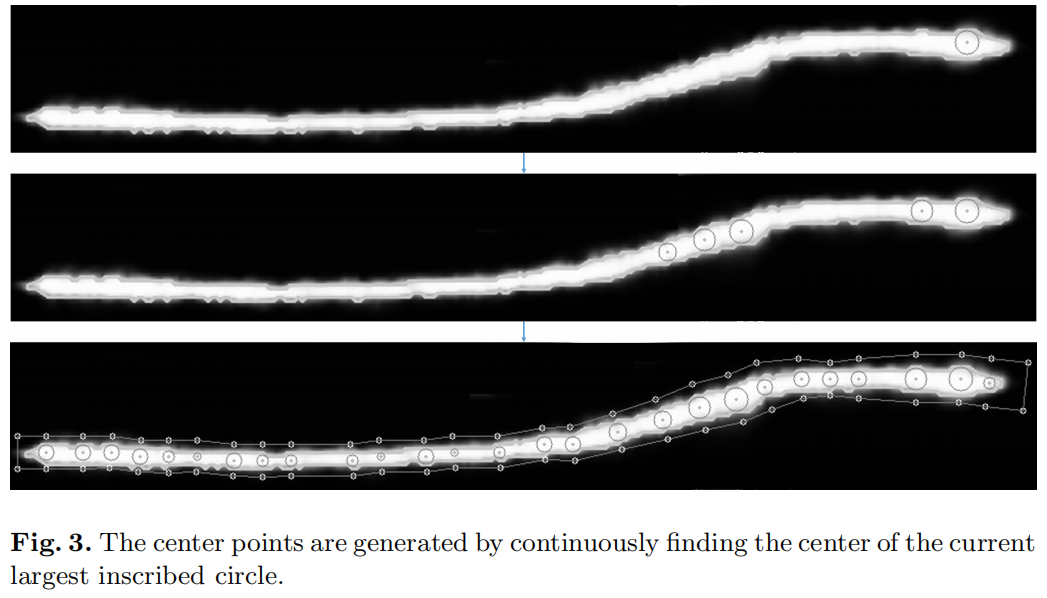
在评估中,我们基于分割图对齐文本线。但这样我们就只能得到文本线核区域的轮廓,我们也需要得到文本线的轨迹。本文提出了基于轮廓生成中心线的算法1。我们需要计算每个内点和轮廓边界之间的最短距离,这样我们才能得到最大值。轮廓中每个点的内切圆半径。距离表示两点之间的欧氏距离的计算。面积和P周长表示轮廓的面积和周长的计算。
该算法不断地找到轮廓线中最大的内切圆,并将其中心添加到轮廓线中心线的点集中,并将中心线两端延伸的点添加到中心点集中。图3显示了生成中心点的过程。我们假设起点的横坐标小于端点。我们可以根据中心点之间的距离来重新排序,如算法2所示。我们使用薄板样条(TPS)[14]插值对图像进行对齐,它可以匹配和变换相应的点,并最小化变形产生的弯曲能量。根据中心线的点和半径,我们可以生成TPS变换的坐标点,如图4所示。通过TPS变换,我们可以将不规则的文本线条转换为矩形。
2.3 Recognition module
这个模块大致相当于传统的文本线识别,除了我们用文本线特征映射替换了文本行图像。大多数方法使用rnn来构造时间序列特征映射的语义关系。我们认为RNNs有三个主要缺点:1)容易发生梯度消失;2)计算速度慢;3)处理长文本的效果不好。
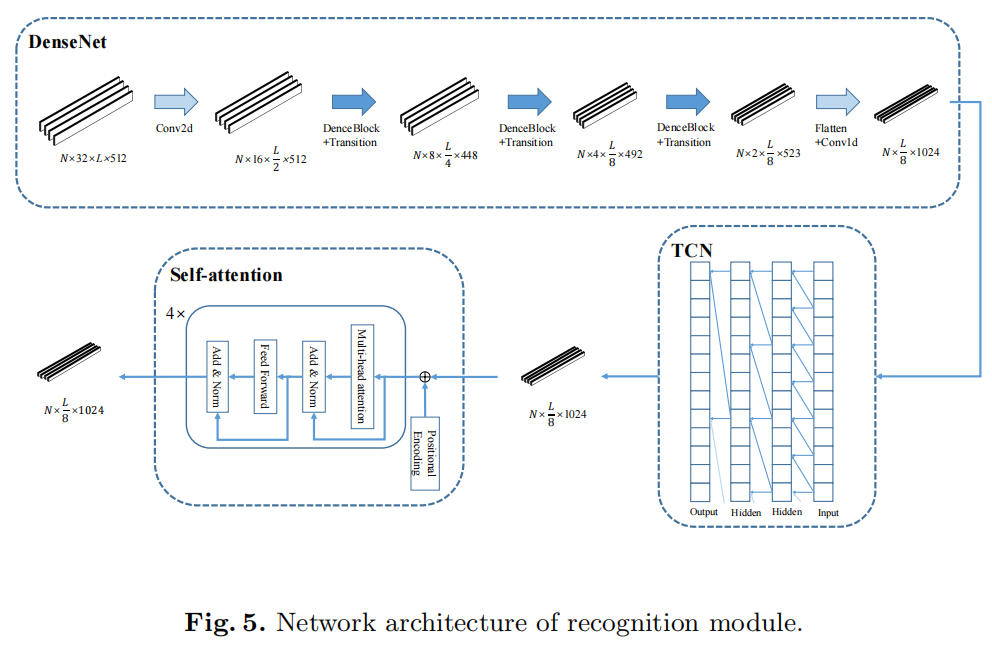
我们设计了一个不使用rnn的文本线识别的多尺度特征提取网络。与CNN相比,TCN和自注意具有更强的远距离信息整合能力。识别模块的结构如图5所示
对于文本行识别的任务,我们认为识别有三个层次。首先是根据每个角色的图像信息提取每个角色的特征。第二种方法是基于每个字符周围的几个字符进行辅助特征提取。第三种方法是基于全局文本信息对特征进行优化。
在第一层中,我们使用DenseNet作为骨干,对特征图进行进一步的特征提取,然后将特征图的高度逐步压缩为1,并将其转换为一个按时间顺序排列的特征图。瓶颈层数的乘法系数为4。每个致密层都添加了32个过滤器。我们在每个密集块之前添加了CBAM [16]层,以利用空间和通道方面的注意。DenseNet的其他详细配置见表1。
我们使用时间卷积网络(TCN)[17]来进行第二级的特征提取。在tcn上使用扩张卷积来获得比CNN更大的接受域。与rnn相比,它可以进行并行计算,计算速度更快,梯度也更稳定。在我们的模型中引入了一个4层的TCN,最大膨胀度为8,这使得该模型具有一个32大小的接受场。
在第三个层次上,我们采用了自注意的结构来进行全局信息的提取。我们只使用了变压器[18]的编码器层,而多头自注意机制是建立全局特征连接的核心。自我注意机制主要应用于自然语言处理领域,但通过文本识别获得的文本也具有语义特征。我们可以利用自我注意来构建语义联想来辅助识别。该模型采用了4层自注意编码器,隐层维数为1024,有16个平行注意头。
2.4 Loss Function
损失函数如下:
L = L t e x t + a L k e r n e l L = L_{text} + aL_{kernel} L=Ltext+aLkernel
L t e x t L_{text} Ltext是用CTCLoss计算的字符识别损失, L k e r n e l L_{kernel} Lkernel是文本核的损失, a a a是用来平衡两者重要性的,本文将 a a a设置成0.1。 L k e r n e l L_{kernel} Lkernel分析和计算如下:

3. Experimental Results