Robust End-to-End Offlfflffline Chinese Handwriting Text Page Spotter with Text Kernel
健壮的端到端离线中文手写文本页面监控器与文本内核
摘要
离线中文手写文本识别是模式识别领域长期存在的研究课题。在以往的研究中,文本检测和识别是分离的,这导致了文本识别高度依赖于检测结果。在本文中,我们提出了一个鲁棒的端到端中文文本页面检测器框架。它将文本检测和文本识别与文本内核相结合,集成了全局文本特征信息,从多个尺度上优化识别,降低了检测的依赖性,提高了系统的鲁棒性。我们的方法在CASIA-HWDB2.0-2.2数据集和ICDAR-2013比赛数据集上取得了最先进的结果。在没有任何语言模型的情况下,行级识别的正确率分别为99.12%和94.27%,页面级识别的正确率分别为99.03%和94.20%。代码将在GitHub上找到。
1. Introduction
离线中文手写文本识别仍然是一个具有挑战性的问题。主要的困难来自三个方面:人物的多样性、写作风格的多样性和人物接触的问题。近年来,基于深度学习的方法大大提高了识别性能。手写文本识别方法有两种类型,即页级识别方法和行级识别方法。对于离线的中文手写文本识别,大多数研究都是基于行级文本识别。
对于行级识别,主要分为两个研究方向:过度分割方法和无分割方法。过度分割方法首先将输入的文本线图像过度分割成一连串的原始片段,然后将这些片段组合起来,生成候选字符模式、形成一个分割的候选格子,并对每个候选格子进行分类,以分配几个候选字符类别,生成一个字符候选格子。Wang Q F等人[1]首先从贝叶斯决策的角度提出了过度分割的方法,并通过置信度转换将分类器输出转换为后验机器人。Song W等人提出了一种深度网络 使用异构CNN从分割候选网格中获得层次化的监督信息。分割候选格子中获取分级监督信息。
然而,过分割的方法也有其固有的局限性。如果文本行分割不正确,就会给后续的识别带来很大的困难。提出了一种基于深度学习的无分割方法来解决这一问题。Messina等人。[3]提出了多维长-短期记忆循环神经网络(MDLSTM-RNN),使用连接员时间分类器[4](CTC)作为端到端文本行识别的损失函数。Xie[5]等人[5]提出了一种CNN-ResLSTM模型,通过数据预处理和增强管道对文本图片进行校正,以优化识别。Xiao等[6]提出了一种带有像素级整正的深度网络,将像素级整正集成到CNN和基于RNN的识别器中。
对于页级识别,可以分为两阶段识别方法和端到端识别方法。两阶段识别方法分别应用两个模型进行文字检测和识别。端到端方法将图片逐渐压缩成几行或一整行的特征图进行识别。Bluche等人10提出了一种修改MDLSTMRNs的方法来识别英文手写段落。Yousef等人1提出了OrigamiNet,它将特征图的宽度不断压缩到l个维度进行识别。两阶段方法一般先检测文本线,然后切出文本线进行识别。Li X等人(7)提出了基于分割的PSENet,用渐进式比例扩展来检测任意形状的文本线。Liu Y等人(8)提出了基于三阶贝塞尔曲线的ABCNet,用于检测弯曲的文字线。Liao M等人9提出了Mask TextSpotter v3,采用分割建议网络(SPN)和hardRoI掩码,用于稳健的场景文本发现。
可以注意到,不检测文本线的页级识别方法失去了文本位置的信息。Liao M等人(9)的方法将硬Rol掩码应用到Rol图像中,而不是转换文本线,可能会处理非常大的特征图,并且在调整特征图大小时丢失信息。不管是线级识别还是两级识别方法,都是先获得文本线的位置信息,然后对文本线进行分割,再进行识别,这实际上是把检测和识别分开了。
我们认为检测和识别不应该被分开。检测只能提供文本线的局部信息,这使得在识别过程中难以利用全局的文本图像信息。无论检测框是大于还是小于地面真实框,都会给后续识别带来困难。这是因为文本线图像的对齐是在原始文本页图像中,其鲁棒性对于识别是不够的。而且文本线的检测非常重要,如果文本线不能被很好地检测出来,文本线图像就不能被准确识别。我们认为,文本识别的关键在于准确地识别文本,我们只需要知道文本的大致位置,而不是精确的检测。
在本文中,我们提出了一个稳健的端到端中文文本页面识别框架,该框架采用文本内核分割和多尺度信息集成的方式来统一文本检测和识别。我们的主要贡献如下:
1)我们提出了一个新颖的端到端文本页识别框架,它利用全局信息来优化检测和识别。
2)我们提出了一种将文本线与文本核对齐的方法,这种方法是基于中心线从特征图中提取文本线条。
3)我们提出了一个具有多尺度信息整合的文本线识别模型,它使用TON和Self-attention代替RNN。
4)我们做了一系列的实验来验证我们模型的有效性,并将其与其他最先进的方法进行比较。我们在CASIA-HWDB数据集和ICDAR-2013数据集上都达到了最先进的性能。我们方法的页级识别性能甚至优于行级识别方法。

端到端检测和识别的结果。粉色区域是核区域的分割结果,文本框由中心点生成算法生成。
2. Method
我们方法的框架在图2中描述。这个框架由三个模块组成,用于文本检测和识别。分割模块用于生成文本线核心区域的分割图和文本页的特征图。连接模块用于根据分割图提取文本行的特征图。识别模块用于文本行的识别,该模块是基于DenseNet(15)与TCN和Self-attention。分割和识别结果如图1所示。

图2. 我们的文本页识别框架的概述。虚线箭头表示,在预测时,文本线特征图由中心线与内核区域进行转换。
2.1 分割模块
分割模块对输入的图像进行处理,生成一个特征图和一个分割图,其大小为原始图像的四分之一。在这一部分,我们主要利用PANNet(12)的网络结构,因为它在任意形状的文本分割上表现良好。我们使用ResNet34(13)作为其骨架,并将骨架生成的4个特征图的步长改为4,4,8, 8相对于输入图像。我们提取较大的特征图,因为我们需要细粒度的特征信息来进行文本识别。我们采用PANnet的特征金字塔增强模块(FPEM)和特征融合模块(FFM)来提取和融合不同尺度的特征信息,FPEM的重复次数为4次,我们设定的文本线核心区域的大小为原始大小的0.6。
2.2连接模块
连接模块是用来根据分割图提取文本线特征图的。我们认为特征图比原始图像包含高维信息,而且特征图可以将文本信息聚集在核区,这使得文本线特征图的提取更加稳健。我们以核区为中心对特征图进行随机变换,如透视变换,使文本特征信息集中在核区,我们将所有的文本线特征图缩放到32像素的高度,以便后续识别。
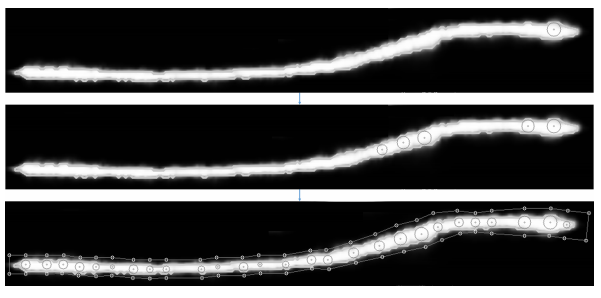
图3. 中心点是通过不断地寻找当前最大内切圆的中心而产生的。最大的内切圆的中心。
我们假设文本线是条状的,它的中心线可以被认为是穿过每个字符的中心。一般来说,文本线的长度大于高度,每条文本线都有一条中心线。我们使用文本线条的刻圆来寻找文本中心线。我们假设文本线条的最大内切圆的中心落在文本中心线上。
在训练过程中,我们使用透视变换将文本线与地面真实文本框对齐。对齐后的文本线特征图在内部方向上进行了随机的精细变换,以增强数据,这使得模型能够学会将文本特征信息集中在内核区域。
在评估中,我们根据分割图来对齐文本线。但这样我们只能得到文本线核心区域的轮廓,我们还需要得到文本线的轨迹。这里我们提出算法1来生成基于轮廓线的中心线。我们需要计算每个内点与轮廓线边界之间的最短距离,这样我们就可以得到轮廓线上每个点的最大内切圆半径。距离表示两点之间的欧几里得距离的计算。面积和周长表示轮廓线的面积和周长的计算。

该算法连续找到轮廓中最大的内切圆,并将其中心加入到轮廓中心线的点集中,同时我们也将中心线两端延伸的点加入到中心点集中,图3显示了中心点的生成过程。我们使用薄板-直线(TPS)14插值来对齐图像,它可以匹配和转换相应的点,并使变形产生的弯曲能量最小。根据中心线的点和半径,我们可以生成TPS变换的坐标点,如图4所示。通过TPS变换,我们可以将不规则的文本线条变换成矩形。
2.3 识别模块
这个模块大致相当于传统的文本线识别,只是我们用文本线特征图代替了文本线图像。大多数方法使用RNNs来构建时间序列特征图的语义关系。我们认为,RNNs有三个主要的缺点: 1)容易出现梯度消失:2)计算速度慢;3)对长文本的处理效果不好。


图4. 文本图片的TPS转换。实际上,我们的方法是在特征图中进行转换操作。
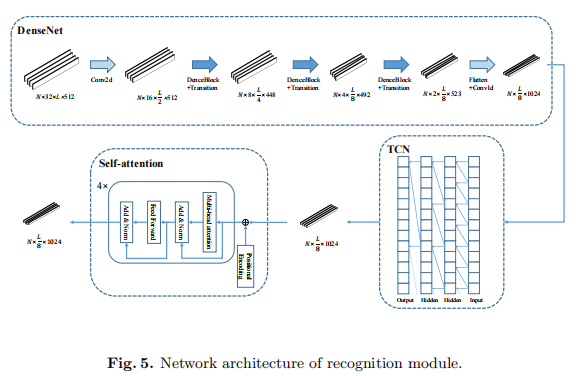
我们设计了一个多尺度特征提取网络,用于文字行的识别,而不使用RNNs。与CNN相比,TCN和Self-attention具有更强的长距离信息整合能力。其识别模块的结构如图5所示。
对于文本行识别的任务,我们认为识别有三个层次。首先是根据每个角色的图像信息提取每个角色的特征。第二种方法是基于每个字符周围的几个字符进行辅助特征提取。第三种方法是基于全局文本信息对特性进行优化。
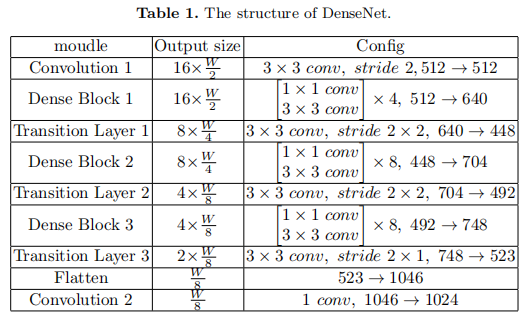
在第一层中,我们使用DenseNet作为骨干,对特征图进行进一步的特征提取,然后将特征图的高度逐步压缩为1,并将其转换为一个按时间顺序排列的特征图。瓶颈层数的乘法系数是4。每个致密层都添加了32个过滤器。我们在每个密集块之前添加了CBAM [16]层,以利用空间和通道方面的注意。DenseNet的其他详细配置见表1。
我们使用时间卷积网络(TCN)[17]来进行第二级的特征提取。在tcn上使用扩张卷积来获得比CNN更大的接受域。与rnn相比,它可以进行并行计算,计算速度更快,梯度也更稳定。在我们的模型中引入了一个4层的TCN,最大膨胀度为8,这使得该模型具有一个32大小的接受场。
对于第三层,我们采用自我注意的结构来进行全局特征提取。我们只使用了Transformer 18的Encoder层,而多头的self-attention机制是建立全局特征con.nections的核心。自我注意机制主要用于自然语言处理领域,但通过文本识别得到的文本也有语义特征。我们可以用Self-attention来构建语义关联来辅助识别。在我们的模型中采用了4层自我注意编码器,隐藏层维度为1024,有16个平行注意头。
2.4 损失函数
损失函数公式如下:
L = L t e x t + α L k e r n e l L = L_{text} + \alpha L{kernel} L=Ltext+αLkernel
L t e x t L_{text} Ltext是字符识别损失,用CTC计算,L内核是内核的损失,α是为了平衡两者的重要性,我们将α设为0.1。考虑到文本区域与非文本区域之间的不平衡,我们使用骰子系数作为方法来评估分割结果。
L k e r n e l = 1 − 2 ∑ i p t e x t ( i ) G t e x t ( i ) ∑ i P t e x t ( i ) 2 + ∑ i G t e x t ( i ) 2 L_{kernel} = 1 - { {2 \sum_i p_{text}(i)G_{text}(i)} \over {\sum_i P_{text}(i)^2 + \sum _i G_{text(i)^2}}} Lkernel=1−∑iPtext(i)2+∑iGtext(i)22∑iptext(i)Gtext(i)
Ptext (i)和Gtext (i)分别表示分割结果中第i个像素的值和文本区域的地面真实值。文本区域的地面真值为二值图像,其中文本像素为1,非文本像素为0
3 Experiment
3.1 数据集
我们使用CASIA-HWDB(19)作为主要数据集,它被分为训练集和测试集。它包括离线手写的孤立字符图片和离线无约束的手写文本页面图片。CASIA-HWDB1.0-1.2包含3,721.874张孤立的字符图片,共7,356类。CASIA-HWDB2.0-2.2包含5,091张文本页图片,包含2,703类的1,349,414个字符。CASIA-HWDB2.0-2.2分为4,076个训练样本和1,015个测试样本。ICDAR-2013中国手写识别大赛Task4 20是一个包含300个测试样本的数据集,包含1,421类的92.654个字符。CASIA-HWDB1.0-1.2的孤立字符图片被用来合成20.000张文本页图片,包含9.008.396个字符。我们根据文本线条的轮廓,采用最小包围矩形的方法重新生成文本线条框,如图6所示。我们使用与PANNet相同的方法来生成文本核,采用Vatticlipping算法21,通过剪切d像素来缩小文本区域。偏移像素d可以确定为d=A(1-r2)/L。其中A和L是代表文本区域的多边形的面积和周长,r是收缩率。
我们将一些混乱的中文符号转换成英文符号,如引号和逗号。

图6. 用最小的包围矩形重新生成文本框
3.2 实验设置
我们使用PyTorch来实现我们的系统。我们用Adam优化器训练整个系统,批量大小被设置为4。没有使用语言模型来优化识别结果。我们进行了两个主要的实验,其余的实验设置如下:
(1)训练集:CASIA-HWDB2.0-2.2的训练集:测试集:CASIA-HWDB2.0-2.2的测试集:学习率:初始化为1×10-4,每2个 epoch乘以0.9;Irain epoch:50。
(2)训练集:CASIA-HWDB2.0-2.2的训练集和20.000张合成的文本页图片;测试集:CASIA-HWDB2.0-2.2的测试集和ICDAR-2013的测试集:学习率:初始化为5×10-5,每2个epoch乘以0.9;Irain epoch:50:实验1的模型权重被用于初始化,除了最后的全连接层。

3.3 实验结果
使用地表真值盒(With ground truth box)
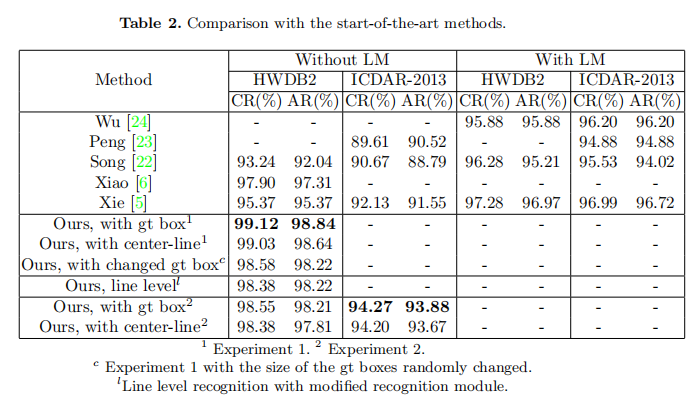
地面真值框被用于分割,因此我们的模型与文本行识别模型相当。但与以前的文本线识别模型相比,我们的模型可以利用文本页的全局信息进行识别,具有更强的抗干扰性和鲁棒性。值得注意的是,我们的方法在CASIA-HWDB2.0-2.2和ICDAR-2013数据集上的识别性能比之前的结果有很大的绝对优势,即1.22%的CR和2.14%的CR,如图7所示,我们的模型在CASIA-HWDB2.0-2.2数据集的识别性能甚至优于使用语言模型的方法。
我们还进行了一个实验,随机改变gt框的大小,gt框的轮廓点在垂直方向上随机移动-0.2到0.2的宽度,在水平方向上移动-l到l的宽度,CR只下降了大约0.5%,如表2所示,这表明我们的模型是非常稳健的。因为我们在文本页的特征图中对文本线进行分割和变换,我们扩大或缩小变换框,使文本信息集中在文本的核心区域,低维信息更敏感,如果这种数据增强直接在原始图片上进行运算,一些文本会变得不完整,不能被正确识别。

 带中线(With center-line)
带中线(With center-line)
可以看到,中心线分割的CR计算仅下降约0.1%,这充分证明了中心线分割的有效性。
由于在分段过程中可以将一行文本划分为多个文本行,因此有必要将切分得到的文本框与地面真相框相对应。如算法3所示,我们使用了计算匹配的交过并(IOU)的方法。在执行该算法之前,需要根据横坐标对所有已分割的框进行排序,以便以从左到右的方式将多个文本行添加到相应的组中。每个组对应于一个文本行标签。如果有额外的框,也就是说,所有的欠条都被计算为0,它们可以添加到任何组,这不影响CR和AR的计算
将所有分割框分组后,当该组的识别结果长度大于或等于标签长度的90%时,则认为检测结果正确。表3显示了我们的模型的检测性能。
分割模块的有效性(Effectiveness of the segmentation module)
我们可以稍微改变识别模块的结构,使其成为一个文本行识别模型。主要的修改是将3层密集区块改为5层密集区块,由[4,8,8]改为[1,48,8]。将输入数据转换为具有分段高度的64像素文字行图像,批处理大小设置为8,其他设置与试验1相似。识别结果表明,该分割模块可以很好地利用全局文本信息来优化文本特征提取,从而提高识别性能。

TCN与自我关注的有效性
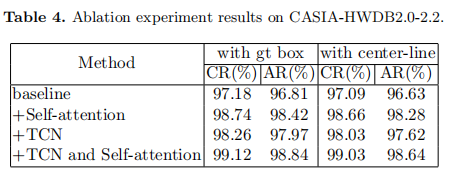
我们在CASIA-HWDB20-22数据集上进行了一系列消融实验,以验证TCN和自我注意的有效性,结果如表4所示。在测试集上,TCN模块和自我注意模块分别获得了108%和1.66%的CR改善。当TCN模块和自我关注模块一起应用时,CR提高了1.96%。
4 结论
在本文中,我们提出了一个新颖的稳健的端到端中文文本页面发现者框架。它利用全局信息将文本特征集中在核心区域,这使得模型只需要大致检测文本区域就可以进行识别。TPS变换被用来将文本线与中心点对齐。TCN和Self-attention被引入识别模块,用于多尺度文本信息提取。它可以进行端到端的文本去除和识别,或者在提供地面真实文本框时优化识别。这种结构可以很容易地被修改,分割模块和识别模块可以被更好的模型所取代。在CASIA-HWDB2.0-2.2和ICDAR-2013数据集上的实验结果表明,我们的方法实现了最先进的识别性能。未来的工作将是研究我们的方法在英语数据集上的表现。