RRNet: A Hybrid Detector for Object Detection in Drone-captured Images
Abstract
我们提出了一种名为RRNet的混合检测器,用于在城市场景无人机(UAVs)和无人机拍摄的图像中进行目标检测。在这种具有挑战性的任务中,目标通常呈现出各种不同的大小,并且非常密集。因此,我们将anchor free检测器与re-regression模块相结合。通过摒弃prior anchors,我们的模型不再需要对边界框大小进行回归,从而在密集场景中实现了更好的多尺度目标检测性能。基于无锚点的检测器首先生成coarse boxes,然后在粗略的预测结果上应用re-regression module,以产生精确的边界框。此外,我们还引入了自适应 resampling augmentation strategy来地增强数据。我们的实验表明,RRNet在VisDrone2018数据集上显著优于所有最先进的检测器。
1. Introduction
无人机(UAVs)在学术界和实际应用中得到了广泛采用。因此,我们需要理解和分析由它们捕获的图像数据。在深度学习时代,基于深度神经网络(DNNs)的目标检测器显著提高了目标检测的性能。然而,正常自然图像和无人机拍摄图像之间存在许多显著差异,这些差异使得目标检测成为一项具有挑战性的任务。首先,这些图像中的目标尺度各异。如图1a所示,远处的目标非常小,而近处的目标很大。此外,在城市中存在大量密集的场景(例如图1b),这导致目标之间有很多遮挡,使得目标检测更加困难。

当前基于深度学习的目标检测器分为两类。第一类是两阶段检测器。它们使用region proposal网络来确定先前的锚点是目标还是背景。 prior anchors是几个手动定义的潜在边界框。然后,它们使用两个head networks将潜在锚点分类到一组类别,并估计锚点与真实边界框之间的偏移量。另一类称为单阶段检测器。与两阶段检测器不同,单阶段检测器舍弃了region proposal网络。它们直接使用两个检测器来预测先前锚点的类别和偏移量。这两种类型的检测器的prior anchors是在低分辨率图像网格上生成的。每个prior anchors只能根据IoU(交并比)分配一个对象边界框。然而,对于由无人机捕获的图像,固定形状的锚点几乎无法处理各种尺度的目标。最近,提出了另一种类型的检测器,即无锚点检测器。它们将边界框的预测简化为 key point和 size estimation。这对于检测具有不同尺度的目标提供了更好的方式。然而,目标大小之间的巨大差异(例如从101到103)使得回归变得困难。
在本论文中,我们提出了一种名为RRNet的混合检测器。无论对象的尺度如何,对象的中心点始终存在。因此,我们使用两个检测器来预测每个对象的中心点、宽度和高度,而不是使用锚点框。然后,我们将这些中心点和尺寸转换为 coarse bounding boxes。最后,我们将深度特征图和粗略的边界框输入到一个Re-Regression模块中。Re-Regression模块可以调整粗略的边界框并生成最终准确的边界框。
此外,已有的证据表明,良好的数据增强甚至可以在不改变网络架构的情况下推动深度模型达到最先进的性能。因此,我们提出了一种数据增强策略,称为自适应重采样(AdaResampling)。这个策略可以在图像上logically增强对象。
我们的实验表明,所提出的模型在VisDrone2018数据集上明显优于现有的最先进检测器。从原理上讲,我们的RRNet是一个无锚点检测器和两阶段检测器的混合模型。我们认为Re-Regression模块对于取得好的结果至关重要。
总结起来,本论文的主要贡献如下:
- 我们提出了一种新颖的混合目标检测器,由一个coarse detector和一个re-regression模块组成,用于在无人机拍摄的图像中进行目标检测。
- 我们提出了一种自适应增强策略,称为AdaResampling,用于对目标进行逻辑增强。
- 我们的检测器在ICCV VisDrone2019目标检测挑战赛中取得了AP50、AR10和AR100的最佳结果。
2. Related work
略过
3. AdaResampling
在这一部分,我们介绍了一种自适应增强方法,称为AdaResampling。受到Kisantal等人的启发,所提出的增强的主要思想是重新采样confusing objects,并将它们多次贴在图像上。
图2a是从COCO数据集中采样的图像。在这种类型的图像上随机贴上裁剪过的目标不会破坏图像的逻辑性。然而,如图2b所示,简单的复制粘贴增强可能会生成一个非常荒谬的图像。我们注意到存在两种不匹配。第一种是背景不匹配。例如,用1标记的车辆飞在天空中。背景不匹配可能导致模型产生更多的误检边界框。原因是分类器依赖于目标特征和上下文特征。分类器可以学习背景的先验知识,以辅助自身进行分类。第二种是尺度不匹配。如果我们将一个大的目标复制到远处的背景中,该目标(例如图2b中的2)将比周围的其他目标大得多。通常,周围的其他目标可以为当前目标的尺寸回归提供有用的知识。尺度不匹配会破坏这种知识。

为了消除这两种不匹配,我们提出了一种自适应增强策略,称为AdaResampling。图3展示了AdaResampling的流程。
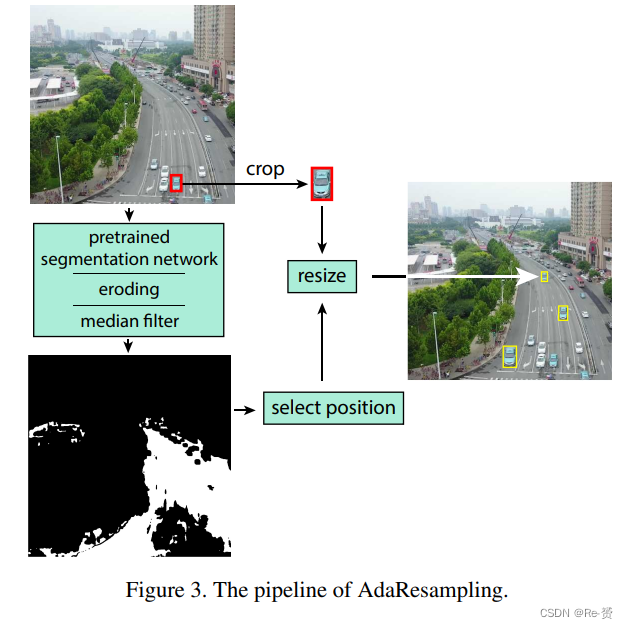
首先,我们将无人机拍摄的图像输入预训练的语义分割网络,以获取prior的道路地图。由于无人机拍摄图像与用于训练分割网络的数据集之间存在差异,分割网络可能会产生噪声结果。我们不要求高召回率,而是要求道路区域的高精度。因此,我们使用eroding algorithm和3×3中值滤波器尽可能地去除伪造的道路区域。然后,我们根据道路地图从有效的位置采样,以放置增强的目标。接下来,裁剪的目标通过一个变换函数进行尺寸调整。高度与宽度的比例是恒定的。缩放后的高度可以通过一个简单的线性函数计算:
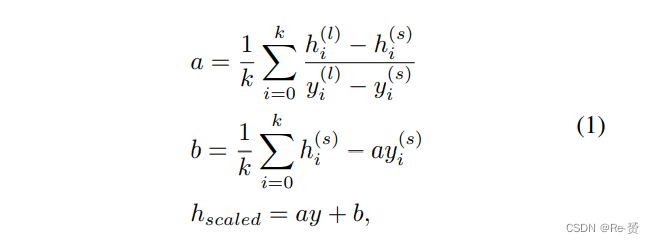
其中 h(l)、h(s)、y(l) 和 y(s) 分别表示最大和最小目标的高度和 y 坐标。我们仅使用最大和最小的 k pedestrian来计算 a。y 是所选有效位置的 y 坐标。最后,缩放后的目标可以放置在所选的位置。我们定义一个密集系数 d 来控制resampled 目标的数量。resampled 的目标数量 n 可以通过以下公式计算
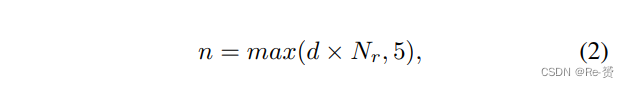
Nr 是prior road pixels的数量。图3的右侧是通过我们的AdaResampling增强的训练图像。我们可以看到车辆只能放置在道路上,并且增强的目标的尺度是合适的。
4. Re-Regression Net
我们对VisDrone2018数据集进行了一些统计数据的收集。结果如图4所示。
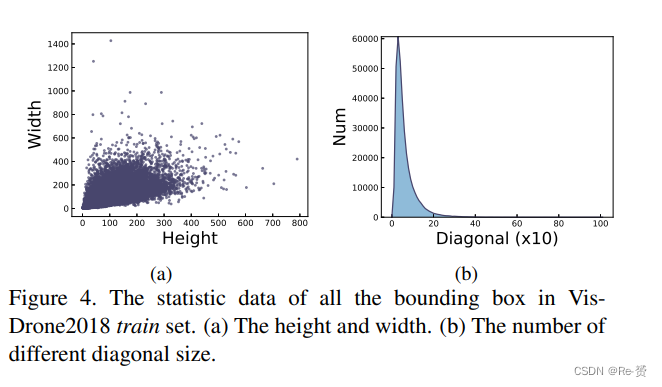
图4a显示了所有边界框的高度和宽度。目标的尺寸范围从101到103像素不等。很难定义一个合适的prior anchors集合来覆盖这么大的间隔。此外,图4b显示了所有边界框的对角线长度。大多数目标的尺寸小于50×50像素。我们认为基于关键点的检测器更适合小目标检测。因此,我们提出了RRNet。图5的上半部分显示了RRNet的架构。我们首先将图像输入到一些卷积块中,以获取初始特征图。然后,两个HourGlass块(HGBlock)提取了具有更多语义信息的robust feature maps。我们将这些特征输入到两个独立的检测器中。heatmap detector产生了一个与目标中心点相关的概率热图。此外,另一个检测器将为所有中心点提供尺寸估计。
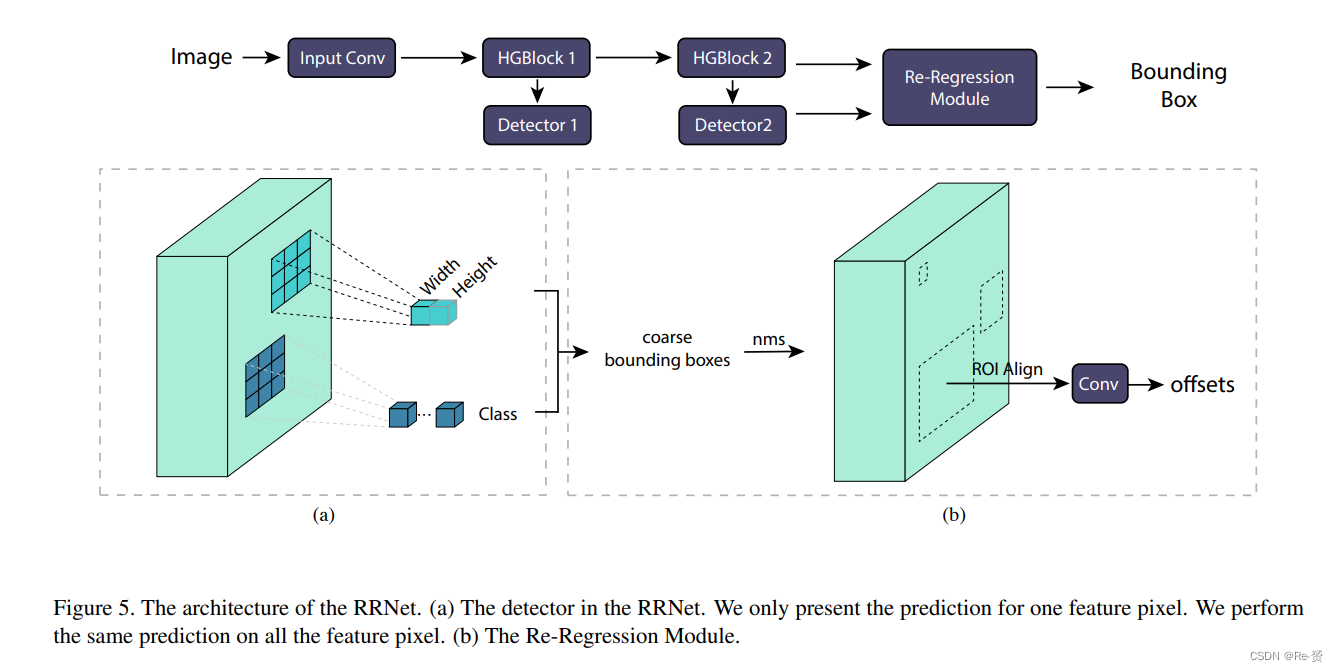
4.1. Coarse detector
如图5所示,粗略检测器由一个尺寸估计块和一个类别预测块组成。尺寸估计部分用于直接预测每个目标的高度和宽度。类别预测网络的操作非常类似于语义分割网络。我们为每个像素预测category-sensitive的中心点,并最终应用sigmoid激活函数,以获得每个类别的独立概率。
4.2. Re-Regression
我们将热图和尺寸预测转换为粗略的边界框。最后,我们应用re-regress模块来对这些粗略检测框进行优化,生成精细的边界框。
Re-Regression模块允许我们的模型优化粗略的边界框。我们将由HGBlock 2生成的特征图和粗略的边界框输入到Re-Regression模块中。Re-Regression模块类似于Faster-RCNN头部,但不包括分类网络。首先,我们使用非极大值抑制(NMS)算法来过滤重复的边界框。然后,我们使用ROIalign来对齐特征,并使用两个卷积层来预测偏移值。最后,我们将偏移值应用于粗略的边界框,得到最终的预测。
5. Experiments
我们使用VisDrone2018数据集来评估我们的模型。我们报告了mAP、AP50、AP75和AR1∼500等指标。
5.1. Data augmentation
与大多数深度神经网络类似,我们的基本数据增强包括水平翻转和随机裁剪。在训练阶段,我们的裁剪尺寸为512×512。我们使用提出的AdaResampling方法对行人、步行者、自行车、三轮车、雨篷三轮车和机动车进行增强。密集系数d被设置为0.00005。在AdaResampling中使用的预训练分割网络是在Cityscapes数据集上预训练的Deeplabv3 网络。
5.2. Network details
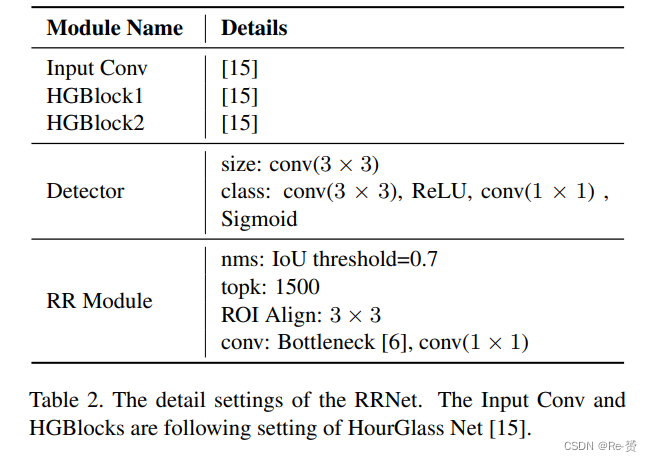
表2展示了我们RRNet的详细设置。输入卷积和HGBlocks(HourGlass块)遵循HourGlass网络的官方设置。在对粗略边界框进行重新回归之前,我们首先根据它们的分类置信度选择前1500个边界框。然后,我们使用非最大值抑制(NMS)算法,设置IoU阈值为0.7,以过滤重复的边界框。ROI Align的大小设置为3。
5.3. Training details
在我们的实验中,我们采用Adam作为优化器。每个mini-batch在每个GPU上有4个图像,我们在4个GPU上进行训练,总共进行100,000次迭代,初始学习率为2.5e-4,在第60,000次和第80,000次迭代时学习率减小10倍。分类的损失函数是焦点损失(focal loss),回归使用平滑L1损失。整体的训练目标函数是:
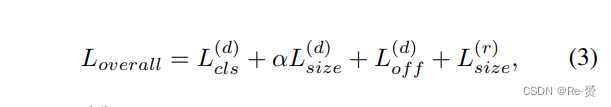
L(d)是粗略检测器的损失函数,L®是Re-Regression模块的损失函数。L(d)和α的设置遵循CenterNet的方式。与Faster RCNN 类似,L(d)size是应用于偏移向量的操作:
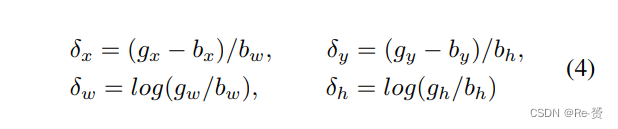
5.4. Inference details
在推理阶段,我们舍弃第一个检测器,仅对第二个检测器进行粗略边界框的预测。然后,我们对得分最高的1500个粗略检测框应用Re-Regression模块,接着使用(soft non-maximum suppression)来进行后处理。
5.5. Performance
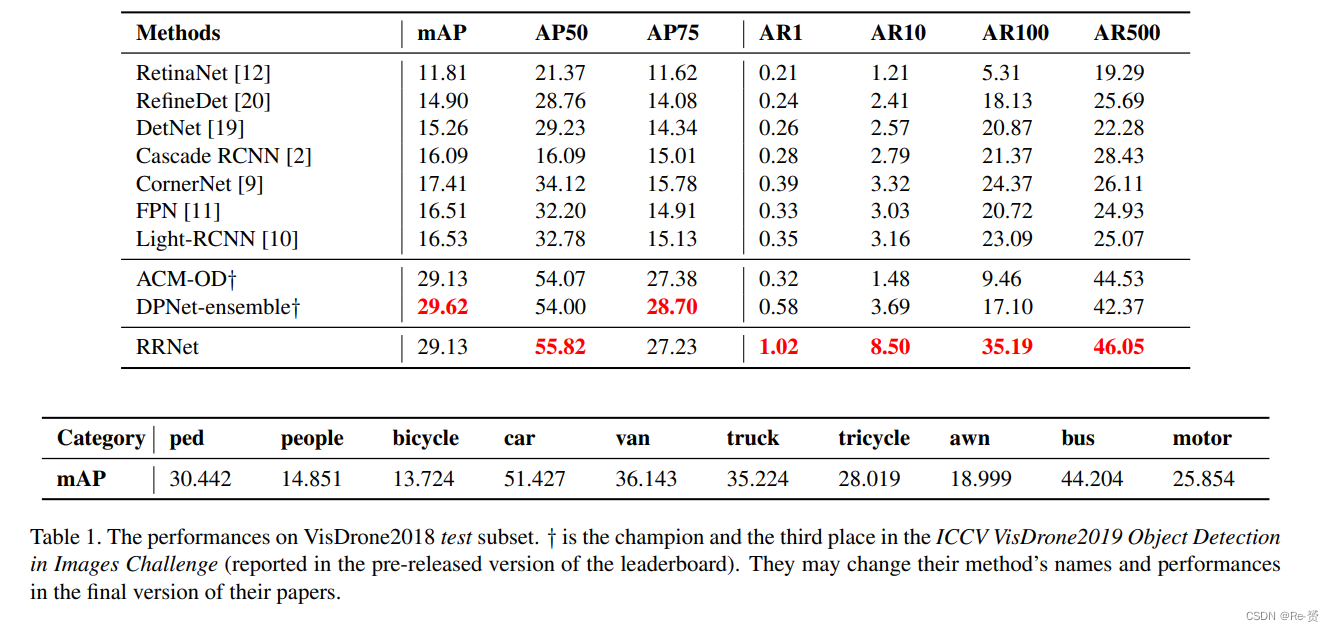
我们在表格1中展示了RRNet与现有最先进目标检测器的比较结果。可以看出,RRNet在所有最先进的基准模型中表现更好。我们还列出了DPNet-ensemble和ACM-OD的性能,它们是该挑战赛的第一和第三名。我们的RRNet在AP50和AR方面取得了最高的成绩。值得注意的是,我们的RRNet的所有AR都明显高于其他模型。这些结果表明一个结论,即我们的网络可以检测更多的难例。
此外,在表格1中还有一些有趣的结果。基于关键点的检测器(例如CornerNet 、RRNet)的性能优于所有基于锚点的检测器。
6. Ablation study
略过
7. Conclusion
In this paper, we proposed an adaptive resampling augmentation and a hybrid object detector, the RRNet, for object detection on images captured by UAVs or drones. It presents excellent performance on very small objects in a dense scene. Our experiments demonstrated that RRNet outperforms the state-of-the-art. We achieve the highest performance of AP50, AR10, and AR100 in the ICCV VisDrone2019 Object Detection in Images Challenge.