Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
发表于CVPR 2020
The dataset link is https://github.com/fanq15/Few-Shot-ObjectDetection-Dataset.
The code link is https://github.com/fanq15/FSOD-code.
The paper link is https://arxiv.org/abs/1908.01998.
摘要:
Propose a novel few-shot object detection network that aims at detecting objects of unseen categories with only a few annotated examples.
Central to our method are our Attention-RPN, Multi-Relation Detector and Contrastive Training strategy, which exploit the similarity between the few shot support set and query set to detect novel objects while suppressing false detection in the background.
To train our network, we contribute a new dataset that contains 1000 categories of various objects with high-quality annotations.
给定不同的对象作为support(在上方),此方法可以检测给定查询图像中相同类别中的所有对象。

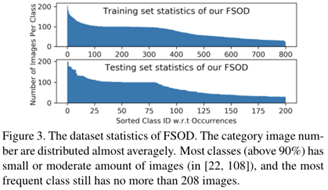
Few-shot learning关键在于,当新颖的类别呈现时,相关模型的泛化能力。因此,具有大量对象类别的高多样性数据集对于训练可以检测到看不见的对象的通用模型以及执行令人信服的评估是必要的。但是,现有的数据集[13、52、53、54、55]包含的类别非常有限,并且并非在少数评估设置中设计的。因此,建立一个新的few-shot物体检测数据集FSOD。
Dataset Construction

标签系统。将叶子标签合并到其原始标签树中,方法是将相同语义(例如,冰熊和北极熊)的叶子标签归为一类,并删除不属于任何叶子类别的语义。然后,删除标签质量较差的图像以及带有不合适尺寸的包装盒的图像。具体说,删除的图像具有小于图像大小的0.05%的框,这些框通常具有较差的视觉质量,因此不适合用作支持示例。
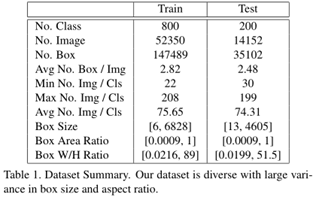
构建了一个包含1000个类别的数据集,其中明确地划分了类别以进行训练和测试,其中531个类别来自ImageNet数据集[56],而469个来自Open Image数据集[54]。
详细统计
Deep Attentioned Few-Shot Detection
Problem Definition
给定一个带有目标对象特写的支持图像sc和一个可能包含支持类别c的对象的查询图像qc,任务是在查询中查找属于该支持类别的所有目标对象,并用严格的边界标记它们。如果支持集包含N个类别,每个类别包含K个示例,此问题被定义为N-way K-shot检测。
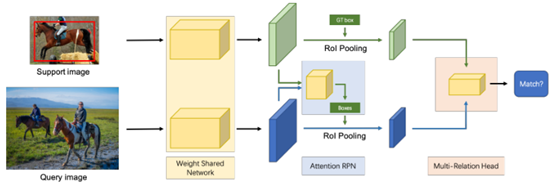
网络架构。查询图像和支持图像由权重共享网络处理。注意力RPN模块通过关注给定的支持类别来过滤掉其他类别的对象提议。然后,多关系检测器将查询建议和支持对象进行匹配。对于N-way训练,通过添加N -1个支持分支来扩展网络,其中每个分支都有自己的关注RPN和带有查询图像的多关系检测器。对于K-shot训练,通过权重共享网络获得所有支撑特征,并在属于其支撑特征同一类别的所有支撑中使用平均特征。
一个由多个分支组成的权重共享框架,其中一个分支用于查询集,另一个分支用于支持集。权重共享框架的查询分支是Faster R-CNN网络,其中包含RPN和检测器。用此框架来训练支持和查询功能之间的匹配关系,使网络学习相同类别之间的常识。在该框架的基础上,引入一种新颖的注意力RPN和具有多关系模块的检测器,以在查询中的支持框和潜在框之间产生准确的解析。
Attention-Based Region Proposal Network
RPN(图5)使用支持信息来过滤掉大多数背景框和不匹配类别的框。因此,生成了一个较小且更精确的候选提案集,其中包含潜在的目标对象。
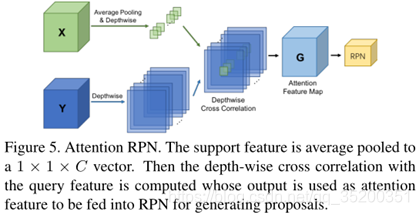
以depth-wise manner计算支持特征图和查询特征图之间的相似度。然后利用相似度图来构建提案生成。将支持特征表示为X∈S×S×C,将查询的特征图表示为Y∈H×W×C,将相似性定义为
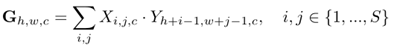
其中G是合成的注意力特征图,支撑特征X用作内核,以深度互相关方式[60]在查询特征图[58,59]上滑动。在本文中采用RPN模型的顶层特征,即ResNet50中的res4_6。
Multi-Relation Detector
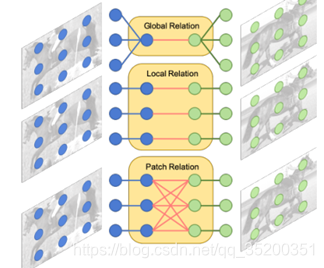
多关系检测器。不同的关系模块建模查询和支持图像之间的不同关系。全局关系模块使用全局表示来匹配图像;局部关系模块捕获像素到像素的匹配关系;补丁关系模块对一对多像素关系进行建模。
Two-way Contrastive Training Strategy
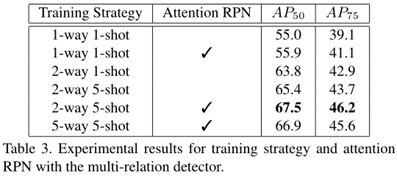
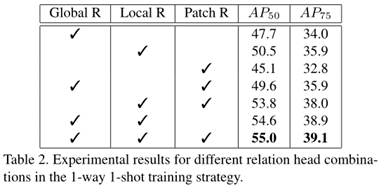
通过组合所有的关系模块,获得了完整的多重关系检测器,并获得了最佳性能。表明三个关系模块相互补充,可以更好地区分目标与不匹配的对象。因此,以下所有实验均采用完整的多关系检测器。
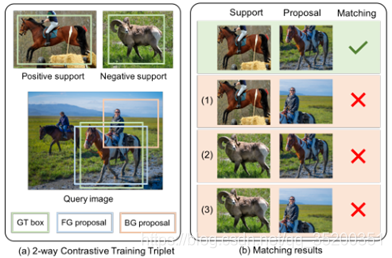
双向对比训练三组和不同的匹配结果。在查询图像中,只有正支持与GT具有相同的类别。匹配对包括正面支持和前景建议,非匹配对具有三类:(1)正面支持和背景建议;(2)负面支持和背景建议;(3)负面支持和背景建议。