聚类分析——聚类
定义:把数据对象划分成子集的过程,每个子集是一个簇,使得簇中的对象彼此相似,但与其他簇中对象彼此相异。
形成聚类的原则就是:使类内部的相似性最大,类间的相似性最小。
聚类方法:
1. 划分的方法(基于距离的)
k-均值(k-means):
-
把N个对象划分成k个簇,用簇中所有对象的均值表示簇的中心点(质心);
-
通过欧式距离划分各个对象,并迭代使每个簇中心不再发生变化为止;
-
最后通过平方误差函数对聚类进行评估,当平方误差函数达到最优时,聚类效果最好,即簇内相似度高,簇间相似度低。
k-中心点(k-medoids)
- 把N个对象划分成k个簇,用簇中某个对象代表簇的中心点,即代表对象;
- 通过欧式距离划分各个对象,并迭代使每个簇得到最优的代表对象为止;
- 具体,用每个簇中的非代表对象依次去替换代表对象,使得替换的代价总和为负时,即找到了一个更好的代表对象,此时可替换为新的代表对象来表示当前簇。
- 形成新的k个中心点的簇,untill不再发生簇的重新分配,即替换的代价总和都为正时,聚类结束。
2. 基于层次的方法
BIRCH算法
- 通过聚类特征树(CF-Tree)对所有对象进行层次划分;
- 将建立的CF-Tree进行筛选,去除一些异常CF节点‘
- 用其他聚类算法对所有CF元祖进行聚类,得到一棵好的CF-Tree;
- 利用生成的CF-Tree的所有CF节点的质心,作为初始质心,对所有样本点按距离远近进行聚类。
注:算法的关键是CF-Tree的建立,其他步骤是为了优化最后的聚类结果。
ROCK算法
- 列表内容
CURE算法
Chameleon算法
3. 基于密度的方法
DBscan算法
Optics算法
4. 基于网格的方法
k-均值(k-means)
注:仅适合于数值属性的数据。
1. 算法思想
k-means算法,也称k-均值算法,它把N个对象划分成k个簇,用簇中对象的均值表示每个簇的中心点(质心),通过迭代使每个簇内的对象不再发生变化为止,此时的平方误差准则函数达到最优,即簇内对象相似度高,簇间相似度低。其具体过程描述如下:
(1.)首先,随机选择k个对象,代表要分成的k个簇的初始均值或中心。
(2.)计算其余对象与各个均值的欧式距离,找到距离最短的对象,将其分配到距离中心最近的簇中。
(3.)计算每个簇中所有对象的平均值(均值),作为每个簇的新的中心。
(4.)再次计算所有对象与新的k个中心的欧式距离,根据**"距离中心最近原则”** ,重新划分所有对象到各个簇中。
(5.)重复(3.)(4.)步骤,直至所有簇中心不变为止。(即本轮生成的簇与上一轮生形成的簇相同)。聚类结束。
2. k-均值算法划分聚类的三个关键点
(1.)数据对象的划分
-
距离度量的选择
计算数据对象之间的距离时,要选择合适的相似性度量,较著名的距离度量是欧几里得距离和曼哈顿距离,常用的是欧氏距离,公式如下:
这里xi,xj表示两个d维数据对象,即对象有d个属性,xi=(xi1,xi2,…,xid),xj=(xj1,xj2,…,xjd)。d(xi,xj)表示对象xi和xj之间的距离,距离越小,二者越相似。
根据欧几里得距离,计算出每一个数据对象与各个簇中心的距离。 -
选择最小距离
即如果d(p,mi)=min{d(p,m1),d(p,m2),…,d(p,mk)}
那么,p∈ci;P表示给定的数据对象;m1,m2,…,mk分别表示簇c1,c2,…,ck的初始均值或中心。
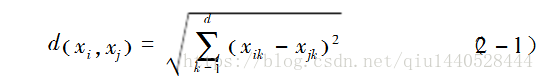
(2.)准则函数的选择
k-均值算法采用平方误差准则函数来评估聚类的性能,即聚类结束后,对所有聚类簇用该公式评估。公式如下:
对于每个簇中的每个对象,求对象到其簇中心距离的平方,然后求和。
其中,E表示数据库中所有对象的平方误差和,P表示给定的数据对象,mi表示簇ci的均值。
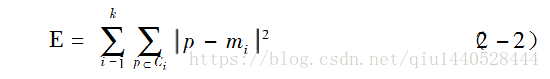
(3.)簇中心的计算
用每个簇内所有对象的均值作为簇中心,公式如下:
这里假设簇c1,c2,…,ck中的数据对象个数分别为n1,n2,…,nk。

3. k-均值算法实现
输入:k,簇数目
D,包含N个对象的数据集
输出:k个簇的集合
方法:
1. 从D中N个对象任意选择k个对象作为初始簇中心;
2. 根据欧氏距离,依次比较其余每个对象与各个簇中心的距离;选择距离最近的簇,依次把N个对象划分到k个簇中;
3. 完成第一次划分后,重新计算新的簇中心即均值,然后重新划分数据对象,直到新的簇中心不再发生变化。