原文地址:https://zhuanlan.zhihu.com/p/27988828
前段时间感觉状态比较差,给自己放了个假,加上刚回到学校事情有些多,拖了几周没更新,实在抱歉。
github地址:rbgirshick/py-faster-rcnn
论文地址:Towards Real-Time Object Detection with Region Proposal Networks
RCNN:目标检测(2)-RCNN - 知乎专栏
Fast RCNN:目标检测(4)-Fast R-CNN - 知乎专栏
摘要
言归正传,目标检测领域由RCNN开始,通将引入卷积神经网络取得了长足的进展,但是始终未能摆脱传统区域建议算法的限制。Fast RCNN提到如果去除区域建议算法的话,网络能够接近实时,而selective search方法进行区域建议的时间一般在秒级。产生差异的原因在于卷积神经网络部分运行在GPU上,而selective search运行在CPU上,所以效率自然是不可同日而语。一种可以想到的解决策略是将selective search通过GPU实现一遍,但是这种实现方式忽略了接下来的检测网络可以与区域建议方法共享计算的问题。因此Faster RCNN从提高区域建议的速度出发提出了region proposal network 用以通过GPU实现快速的区域建议。通过共享卷积,RPN在测试时的速度约为10ms,相比于selective search的秒级简直可以忽略不计。Faster RCNN整体结构为RPN网络产生区域建议,然后直接传递给Fast RCNN。当然重点就是这个RPN网络咯,我们看看RPN如何产生区域候选。下图是Faster RCNN的整体网络结构:

对于一幅图片的处理流程为:图片-卷积特征提取-RPN产生proposals-Fast RCNN分类proposals。
区域建议的产生
在目标检测领域,区域建议与后续的检测往往是分开进行的,而对于区域建议算法一般分为两类:基于超像素合并的(selective search、CPMC、MCG等),基于滑窗算法的,也就是我们在selective search一文中提到的穷举法。自从卷积网络出现后,滑窗也自然高级了一点,比如说可以在卷积特征层上滑窗,由于卷积特征层一般很小,所以得到的滑窗数目也少很多。但是产生的滑窗准确度也就差了很多,毕竟感受野也相应大了很多。Faster RCNN的做法是,既然区域建议的精度不够,那么类似于Faster RCNN,给每一个region再来个回归得到更加精细化的位置就是咯。

RPN对于feature map的每个位置进行滑窗,通过不同尺度以及不同比例的K个anchor产生K个256维的向量,然后分类每一个region是否包含目标以及通过回归得到目标的具体位置。
- 这里使用的滑窗大小为
,感觉很小,但是其相对于原图片的感受野约为200左右个像素。
- anchor box的作用是产生不同比例及尺度的region proposal,通过将anchor中心点与滑窗中心点对齐,然后以一定的比例及大小裁剪滑窗。比如裁剪一个512*512的大小,比例为1:2的滑窗实现就是对于滑窗中心点向外扩充像素使得对应原图包含的像素点个数为512*512,比例为1:2。然后对于这一块进行卷积提取固定维度的特征。
- RPN是一个全卷积神经网络的结构,也就是将全连接层通过卷积层去替换(我将在下一篇文章里面写FCN)。因此可以接受任意大小的输入,同时输出所有的anchors对应的特征。实验细节部分会详细说这一点。
- 由于采用的是滑窗的方式,因此全连接层(上图获得256-d向量的位置)是共享权重的,每个滑窗的权重都是相同的。其实现方式是通过
多尺度样本的产生
由于目标检测的目标尺度可能相差很大,因此我们需要尽可能产生不同尺寸的region proposals,常见的有两种方法,加上本文的一共三种方法:
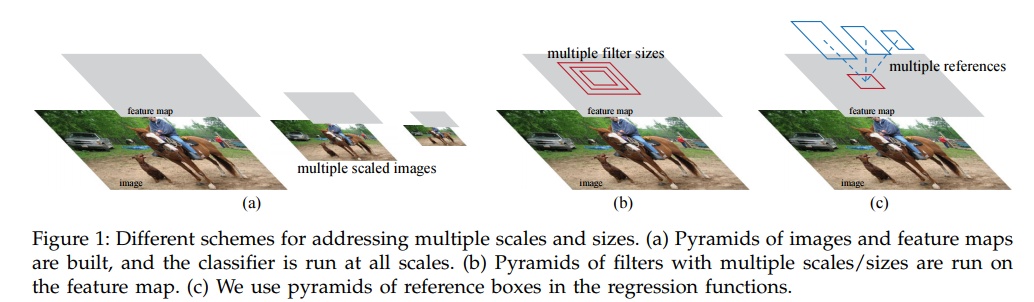
- 图像金字塔:通过将图像放缩到不同的尺寸,然后提取特征去做。有点类似于RCNN中的实现方式,显然这样需要为每一个尺寸重复提取卷积特征,成本很高。
- 卷积特征金字塔:先对于图像提取卷积特征,然后将卷积特征放缩到不同的尺寸。类似于SPP的实现方式。在SPP中我们也看到,这里面的图像也需要放缩到几种尺寸,产生多尺度结果。
- anchor金字塔:通过不同尺度的anchor在卷积特征上滑窗相当于是anchor金字塔,不需要图像有多个尺寸,仅需要有多个尺寸的anchor就好了。文章使用了3种尺度以及3种比例。

感觉区域大小很重要,3尺寸的1比例与3比例相差很小,因为比例准不准没关系,后面还有回归层去微调呢,但是如果尺寸不够那回归层就无能为力了。
损失函数的设计
RPN包含两个网络分支,分类层以及回归层。分类层给出一个二分类label,也就是这个region是否包含目标,回归层产生目标的位置。其中与任意ground-truth box的IOU大于0.7即认为是包含目标的,而对于任意ground-truth box的IOU都小于0.3则认为是负样本。对于回归采用的与Fast RCNN一致。
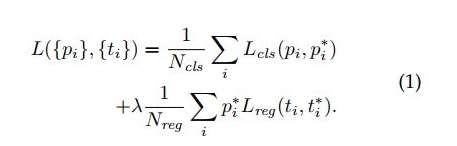
- 分类损失一个是二分类,一个是类别相关的分类。
- 回归损失一个是非类别相关的,Fast RCNN是类别相关的。
- Fast RCNN ROI pooling后面跟着两个FC然后再到相应的分类或是回归,RPN则是一个全卷积的过程,包括对于后续的向量全连接操作都是通过
卷积实现的。而且无论回归还是分类从256-d向量到后面都只有一个卷积层。
- 9个anchor的参数不共享,但是每个滑窗位置的参数是共享的。
RPN的训练过程
- RPN可以通过BP算法端到端训练,为了防止类似样本向负样本倾斜,我们在每一个批次中采样256个anchors,然后这些anchors中正负样本比例为1:1。
- RPN与Fast RCNN权重共享训练
文章使用的四步交替训练的方法:
- 通过预训练模型初始化RPN网络,然后训练RPN。
- 通过预训练模型初始化Fast RCNN,并使用RPN产生的proposal训练RPN。
- 通过Fast RCNN初始化RPN中与其共有的网络层,然后固定这些层训练其他层。
- 固定Fast RCNN中的共有层,通过RPN训练Fast RCNN。
实验细节
文章对于图像的预处理是放缩使得短边为600个像素,以VGG为例,经过四次的池化操作,每个卷积层像素的感受野对应于原图为16个像素。对于1000*600的图片,其卷积特征层尺寸为60*40,所以anchors数量为60*40*9,而去除在边缘的不完整的anchors,最后能得到6000个anchors,而这些anchors的特征是同时计算出来的。比如针对一个图像尺寸128*128,其对应于卷积层特征尺寸为9*9,然后对于所有的9*9小块进行卷积得到的feature map就是所有的anchor对应的特征。RPN产生的region proposal重叠较多,通过NMS去除重叠后大约剩余2K个proposal,在测试时仅选用前300个proposal,效果也是相当的好。
- 不同尺度的anchors对应的真实的proposal大小
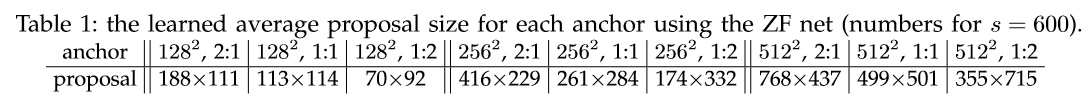
可以看到,我们的尺寸和比例还是起到了作用的,相应尺寸和比例的proposal也基本符合要求的。
- proposal个数
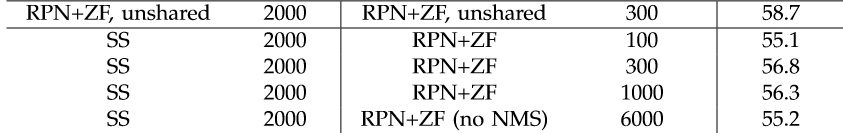
可以看到300个proposal其实并没有降低识别准确率,而且NMS对结果也没啥影响,所以测试时取前300个proposal,这样可以大幅提高速度。
- 分阶段权重共享的优点

权重共享大约能够提升个1.5个百分点,还是很有效果的。同时我们也看到数据集扩充对于识别结果影响最大,通过COCO+07+12训练然后再07上测试能够达到78.8%,提高10个点。
- 时间性能

通过ZF基本可以实现实时的,所以文章标题也是朝着实时目标检测迈进嘛~
总结
至此,可以说RCNN目标检测系列已经是相当的完美了,无论是结果还是效率都可以商用了。但是网络的通用性不太好,在最新的网络比如Inception、ResNet系列直接套用Faster RCNN是不合适的,如何使用这些新的网络呢?接下来我们将研究FCN、RFCN这两个方法