2013年的RCNN,ICCV2015年的fast rcnn,以及NIPS2015的faster rcnn逐步确定了two stage目标检测的框架。
本文将会主要讲述三个方面的内容:
- 稍微对比一下rcnn,fast rcnn到faster rcnn的原理
- 以mmdetection中的faster rcnn复现代码为参考,讲述faster rcnn从图像输入,到计算RPN的loss,计算最后的全连接层输出的loss的全过程。
- 简述test的全过程。
1.rcnn,fast rcnn,faster rcnn

从上面的rcnn的结构图可以RCNN启发式的Selective Search选取候选框,用CNN提取到的特征训练分类器,以及进行bbox回归
但是需要事先提取多个候选框,这就会占用很多的内存,提取之后的region proposals需要归一化到统一尺寸,导致形变使得检测效果不佳,每个region proposals都需要经过一次CNN,导致特征重复提取,而且浪费时间
RCNN参考阅读:
https://zhuanlan.zhihu.com/p/23006190
https://blog.csdn.net/WoPawn/article/details/52133338
由于RCNN从原图中选出的所有的ROI都要经过一次convnet,这必然会导致速度非常慢,fast rcnn便是基于此进行改进。
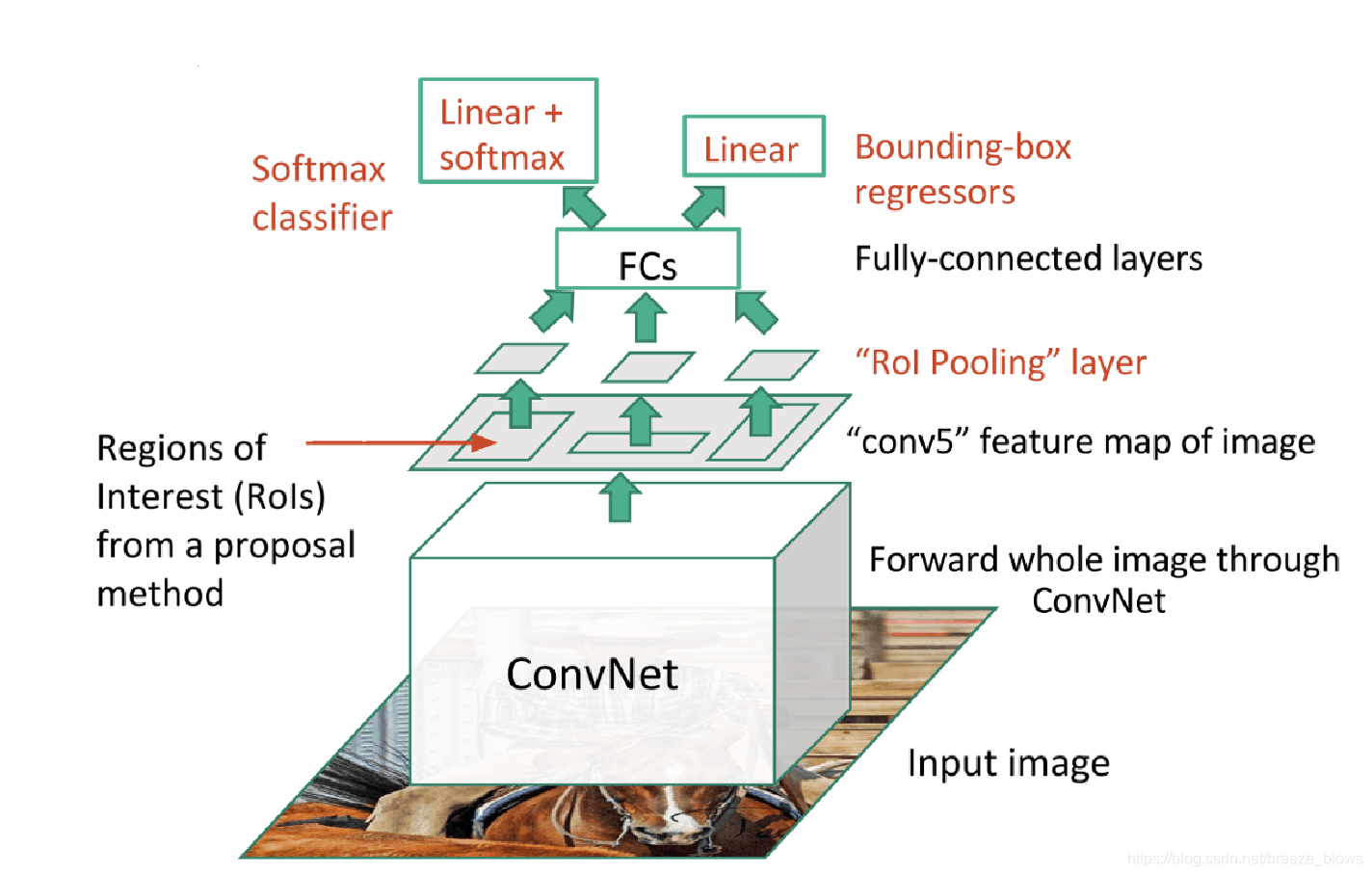
从fast rcnn的结构图中可以看出,不同于rcnn的是,fast rcnn是先将整个图片作为convnet的输入,然后在输出的feature map上面选取roi,然后再将得到的roi区域的特征进行后续的全连接层进行分类,回归。这样确实极大的提高了rcnn的速度,但是存在一个问题,就是在feature map上面选取roi的时候,由于roi的尺寸都是不同的,必须将roi的特征统一到相同的尺寸才可以统一送到后续的全连接层中,这里就需要用到ROI pooling,或者ROI Align
讲解ROI pooling与ROI Align
ROI pooling与ROI Align参考阅读:
http://blog.leanote.com/post/[email protected]/b5f4f526490b
https://www.jianshu.com/p/8b7d7036d715
fast rcnn参考阅读:
https://blog.csdn.net/gentelyang/article/details/80469553
https://blog.csdn.net/Wonder233/article/details/53671018
https://blog.csdn.net/WoPawn/article/details/52463853
rcnn,fast rcnn在选取roi的时候一般都会采用selective search等方式,faster rcnn则是直接提出了一种RPN来选取若干region proposal进一步提高了检测的精度。

2. faster rcnn过程
以下为mmdetection中faster rcnn的实现思路。
base_anchor的生成,给base_anchors分配gt的过程跟retinanet的过程一样,具体参见:Focal Loss for Dense Object Detection。不同的是在mmdetection的faster rcnn实现中,anchor_strides为[4,8,16,32,64], anchor_ratios=[0.5, 1.0, 2.0],但是scale只有一个,值为8。三种ration,一种scale,所以相当于在每个位置会产生三个base_anchor
2.1 网络结构
网络结构图中的rpn_conv,rpn_cls,rpn_reg是所有pyramid feature共享的,可以看出网路主要由两部分组成,一部分是RPN网络,用于产生region proposal,这里会计算一个RNP loss来使得RNP产生的region proposal越来越好。另外一部分就是RPN产生的region proposal经过ROI pooling之后在上图中的feature map中在提取特征,最后经过全连接层之后得到的bbox_pred,cls_prob与选出的region propos之间计算一个loss。下面的章节将依次计算这两个loss
2.2 RPN
这里以三分类的任务为例,首先考虑stride=4的时候,经过rpn_cls后输出rpn_cls_score[1,3,a,a], 这里的a其实就是图像原尺寸除以4之后的结果。经过rpn_reg后输出rnp_bbox_pred[1,12,a,a]。这里的3表示每个位置是前景即目标的概率,12表示该位置有三个框,每个框由四个坐标表示。经过RPN网络得到的rpn_cls_score[1,3,a,a],rnp_bbox_pred[1,12,a,a]会跟开始产生的base_anchor计算一个RPN损失,主要目的是为了区别背景与目标,进而选择出region proposal。计算RNP loss的方法如下:
- 在RPN阶段,给base_anchor分配gt的时候,pos_iou_thr=0.7,neg_iou_thr=0.3
- 从base_anchor中随机选取256个anchor,其中正样本:负样本=1:1,一般是先在属于正样本的base_anchor中随机选择256*0.5个正样本框,很多时候这里的正样本框都是不足256*0.5=128个的(会影响最后的精度,需要合适的去设置anchor的大小等),然后再用256减去正样本框得到负样本框的数目,接着在属于负样本的base_anchor中随机选择指定数目的负样本框。代码如下
def sample(self, assign_result, bboxes, gt_bboxes, gt_labels=None, **kwargs): """Sample positive and negative bboxes. This is a simple implementation of bbox sampling given candidates, assigning results and ground truth bboxes. Args: assign_result (:obj:`AssignResult`): Bbox assigning results. bboxes (Tensor): Boxes to be sampled from. gt_bboxes (Tensor): Ground truth bboxes. gt_labels (Tensor, optional): Class labels of ground truth bboxes. Returns: :obj:`SamplingResult`: Sampling result. """ bboxes = bboxes[:, :4] gt_flags = bboxes.new_zeros((bboxes.shape[0], ), dtype=torch.uint8) if self.add_gt_as_proposals: bboxes = torch.cat([gt_bboxes, bboxes], dim=0) assign_result.add_gt_(gt_labels) gt_ones = bboxes.new_ones(gt_bboxes.shape[0], dtype=torch.uint8) gt_flags = torch.cat([gt_ones, gt_flags]) num_expected_pos = int(self.num * self.pos_fraction) #计算出选择的正样本的个数 pos_inds = self.pos_sampler._sample_pos( assign_result, num_expected_pos, bboxes=bboxes, **kwargs) #从所有正样本中随机选择出num_expected_pos 个正样本 # We found that sampled indices have duplicated items occasionally. # (may be a bug of PyTorch) pos_inds = pos_inds.unique() num_sampled_pos = pos_inds.numel() num_expected_neg = self.num - num_sampled_pos #负样本等于总共需要的样本数减去已经选择正样本数目 if self.neg_pos_ub >= 0: _pos = max(1, num_sampled_pos) neg_upper_bound = int(self.neg_pos_ub * _pos) if num_expected_neg > neg_upper_bound: num_expected_neg = neg_upper_bound neg_inds = self.neg_sampler._sample_neg( assign_result, num_expected_neg, bboxes=bboxes, **kwargs) #从所有负样本中随机选择num_expected_neg个负样本 neg_inds = neg_inds.unique() return SamplingResult(pos_inds, neg_inds, bboxes, gt_bboxes, assign_result, gt_flags) - 在第二步选出的正样本编号pos_inds, 负样本编号neg_inds, 在计算分类损失的时候lables[pos_inds]=1,表示将正样本赋值为1,其余为负样本为0,这里的分类损失只是为了区别前景与背景。RPN输出的rpn_cls_score[1,3,a,a] resize为rpn_cls_score[a*a,3], clc_loss=BCEwithlogit(rpn_cls_score,lables,lable_weights), 这里的lable_weights[pos_inds,neg_inds]=1,其余为0,表示分类损失只计算正负样本。rpn_bbox_pred首先resize为rpn_bbox_pred[a*a*3,4], box_target[pos_inds,:]=pos_bbox_targets(pos_bbox与gt之间的偏差,具体算法见https://blog.csdn.net/breeze_blows/article/details/103268683中的
)box_weight[pos_inds]=1(表示只计算正样本), 最后的reg_loss=L1(rnp_bbox_pred,bbox_traget)*box_weight.
2.3 RPN选出region proposals
经过了上述了RNP loss之后,我们可以认为RNP最后输出的rpn_cls_score[1,3,a,a],rnp_bbox_pred[1,12,a,a]可以较好的作为选取region proposal的依据,具体做法如下:
1.在每pyramid feature的每一个level上,首先rpn_cls_score resize为rpn_cls_score[a*a,3],np_bbox_pred[1,12,a,a]resize为[a*a*3,4]之后经过sigmoi在进行排序选出得到最高的num_pre=2000个rpn_bbox_pred(这里代表着与gt的差值), rpn_bbox_pred与base_anchor反变换后变成proposals,经过nms=0.7选出不多于nms_post=2000个
2.经过上面的所有level之后选出的proposals,在经过proposal的得分score选出最多max_num=2000个proposals生成proposal_list。
def get_bboxes_single(self,
cls_scores,
bbox_preds,
mlvl_anchors,
img_shape,
scale_factor,
cfg,
rescale=False):
mlvl_proposals = []
for idx in range(len(cls_scores)): #对 def get_bboxes_single(self,
cls_scores,
bbox_preds,
mlvl_anchors,
img_shape,
scale_factor,
cfg,
rescale=False):
mlvl_proposals = []
for idx in range(len(cls_scores)): #对pyramid feature的每一个level进行选择
rpn_cls_score = cls_scores[idx]
rpn_bbox_pred = bbox_preds[idx]
assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
anchors = mlvl_anchors[idx]
rpn_cls_score = rpn_cls_score.permute(1, 2, 0)
if self.use_sigmoid_cls:
rpn_cls_score = rpn_cls_score.reshape(-1)
scores = rpn_cls_score.sigmoid()
else:
rpn_cls_score = rpn_cls_score.reshape(-1, 2)
scores = rpn_cls_score.softmax(dim=1)[:, 1]
rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).reshape(-1, 4)
if cfg.nms_pre > 0 and scores.shape[0] > cfg.nms_pre:
_, topk_inds = scores.topk(cfg.nms_pre) #选出最好的nms_pre个
rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
anchors = anchors[topk_inds, :]
scores = scores[topk_inds]
proposals = delta2bbox(anchors, rpn_bbox_pred, self.target_means,
self.target_stds, img_shape)
if cfg.min_bbox_size > 0:
w = proposals[:, 2] - proposals[:, 0] + 1
h = proposals[:, 3] - proposals[:, 1] + 1
valid_inds = torch.nonzero((w >= cfg.min_bbox_size) &
(h >= cfg.min_bbox_size)).squeeze()
proposals = proposals[valid_inds, :]
scores = scores[valid_inds]
proposals = torch.cat([proposals, scores.unsqueeze(-1)], dim=-1)
proposals, _ = nms(proposals, cfg.nms_thr) #nms去除一些proposals
proposals = proposals[:cfg.nms_post, :]
mlvl_proposals.append(proposals)
proposals = torch.cat(mlvl_proposals, 0)
if cfg.nms_across_levels:
proposals, _ = nms(proposals, cfg.nms_thr)
proposals = proposals[:cfg.max_num, :]
else:
scores = proposals[:, 4]
num = min(cfg.max_num, proposals.shape[0])
_, topk_inds = scores.topk(num) #所有level中选出的proposals在根据得分选出num个
proposals = proposals[topk_inds, :]
return proposals2.4 计算最后的损失
用RNP选出2000个proposals组成的proposal_list之后,会将gt也加入到这个proposal_list中(???,可能会为了确保至少有一个正样本吧),接着按照原来的一样的步骤为proposal_list分配gt,不同的是这里的neg_iou_thr=0.5,pos_iou_thr=0.5,最后按照正样本与负样本1:1选取512个proposals(选择方法与RPN阶段选取256个anchor一样)。选取的这512个proposals通过ROI Align的方法在特征图上提取特征得到roi_features[512,256,7,7],经过最后的全连接层之后得到clc_score[512,4], bbox_pred[512,16].这里的4表示有四个类(三个目标类加上背景类),[512,16]表示一共有512个位置,每个位置有四个类,每个类有一个bbox表示。
最后一步就是用得最后得到的512个proposals[512,4]与clc_score[512,4], bbox_pred[512,16].分别计算分类损失与回归损失。
分类损失:lables[:num_pos]=pos_gt_lables(512个proposals被分配gt之后得到的lable,num_pos表示正样本的数目,后面的元素当成背景类) , lable_weigths[num_pos, num_reg]=1, loss_clc = crossEntropyloss(clc_socre,lables)*lable_weights
回归损失:bbox_target[num_pos]=pos_bbox_target, bbox_weights[:num_pos]=1, 在bbox_pred[512,16]每行中选出指定类别对于的bbox变为[512,4], loss_reg=L1loss(proposals,bbox_pred]*bbox_weights
2.5 test
1.首先跟在train中一样的方式选出得分前1000的proposals,只不过参数有所区别
test_cfg = dict(
rpn=dict(
nms_across_levels=False,
nms_pre=1000,
nms_post=1000,
max_num=1000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100)2.用选出的1000个proposals变为roi[1000,5]在FPN不同的level(取得前四个level???)中提取roi_features[1000,256,7,7],经过最后的全连接层之后得到cls_score[1000,4],bbox_pred[1000,16] ,cls_score= F.softmax(cls_score, dim=1),用roi[:,1:]与bbox_pred[1000,16]变换生成最后的bboxs[1000,16], bboxes /= scale_factor(消除训练时候的尺寸变换).
3.cls_score[1000,4]中选取每一类,即每一列(背景类除外),选择每一列中大于score_thr=0.05的行,用这个行以及对应的类别label在bboxes[1000,16]中选出对应类的bboxs。最后在用NMS得到最后的bboxs以及为每个bboxs分配对应类的label。
3.其他
1.计算loss的时候,代码中写的是reg_loss与clc_loss的比重是1:1,即认为两个损失同等重要,难道不会一个loss比较大导致最后loss被某个loss所主导吗
算出来的最后损失除以正样本数目问题
多个二分类与多分类损失的区别
ROI Align参考: