这是一篇2023 CVPR的一篇文章,文章在STTran的基础上进行了相关工作。
论文地址:
2304.00733.pdf (arxiv.org)![]() https://arxiv.org/pdf/2304.00733.pdf代码地址:
https://arxiv.org/pdf/2304.00733.pdf代码地址:
GitHub - sayaknag/unbiasedSGG![]() https://github.com/sayaknag/unbiasedSGG
https://github.com/sayaknag/unbiasedSGG
摘要
由于场景的内在动态性、模型预测的时间波动以及视觉关系的长尾分布,加上基于图像的动态场景图生成(SGG)已经存在的挑战,从视频中生成动态场景图(SGG)的任务非常复杂和具有挑战性。
现有的动态SGG方法主要侧重于使用复杂架构捕获时空上下文,而没有解决上述挑战,特别是关系的长尾分布。这通常会导致产生有偏差的场景图。为了解决这些挑战,我们引入了一个名为TEMPURA(TEmporal consistency and Memory Prototype
guided UnceRtainty Atentuation for unbiased dynamic SGG)的新框架:时间一致性和记忆原型指导的无偏动态SGG的不确定性衰减。TEMPURA通过基于变换的序列建模来实现对象级时间一致性,使用记忆引导训练来学习合成无偏关系表示,并使用高斯混合模型(GMM)来减弱视觉关系的预测不确定性。大量的实验表明,我们的方法比现有方法取得了显著的(在某些情况下高达10%)性能提升,突出了其在生成更多无偏场景图方面的优势。
主要贡献
1)TEMPURA对与动态SGG相关的预测不确定性进行建模,并减弱噪声注释的影响,从而产生更无偏的场景图。
2)利用一种新颖的记忆引导训练方法,TEMPURA通过将知识从频繁的谓词类扩散到罕见的谓词类来学习生成更无偏的谓词表示。
3)利用基于Transformer的序列处理机制,TEMPURA促进了在时间上更加一致的对象分类,这在SGG文献中仍然相对未解决。
4)与现有的最先进的方法相比,TEMPURA在mean-Recall@K方面取得了显著的性能提升,突出了其在生成更多无偏场景图方面的优势。
提出的问题
1.(a) Action Genome中谓词类的长尾分布。(b) STTran和TRACE这两种最先进的动态SGG方法的视觉关系或谓词分类性能在尾类中显著下降。
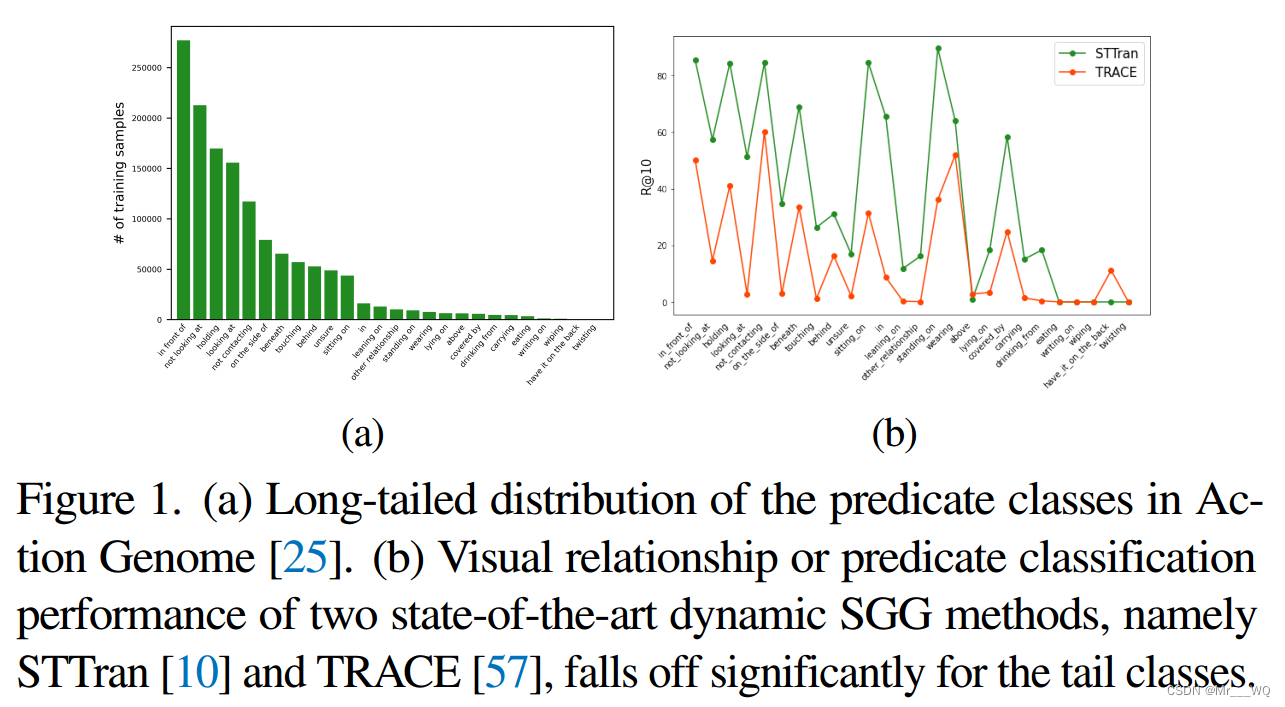
2.Action Genome的噪声场景图注释增加了预测场景图的不确定性。

3.视频中运动物体引起的遮挡和运动模糊使得现有的目标检测器,如FasterRCNN等无法产生一致的目标分类。

概述
为了从视频中生成更无偏的场景图,有必要解决图1、2和3中突出的挑战。为此,我们提出了无偏动态SGG的TEMPURA。如图4所示,TEMPURA与谓词嵌入生成器(PEG)一起工作,该生成器可以从任何现有的动态SGG模型中获得。由于基于变压器的模型已被证明是更好的时空动态学习器,我们将PEG建模为的时空Transformer,它建立在的普通Transformer架构之上。对象序列处理单元(object sequence processing unit, OSPU)使对象分类在时间上保持一致。记忆扩散单元(MDU)和高斯混合模型(GMM)头部分别解决了视频SGG数据中的长尾偏差和总体噪声问题。在接下来的章节中,我们将更详细地描述这些单元,以及TEMPURA的训练和测试细节。

图4. TEMPURA的框架。目标检测器为视频中的每个RGB帧生成初始目标建议。然后,这些建议被传递给OSPU,在那里,它们首先被链接到基于目标探测器置信度得分的序列中。这些序列被一个Transformer编码器处理,以产生暂时一致的对象嵌入,以改进对象分类。每个主客体对的建议和语义信息被传递给PEG,以生成它们之间关系的时空表示。作为一个时空Transformer,PEG的编码器学习关系的空间上下文,其解码器学习它们的时间依赖性。由于关系/谓词类的长尾性质,在训练期间使用与MDU结合的记忆库来消除PEG的偏差,从而能够产生更一般化的谓词嵌入。最后,K个GMM头对PEG嵌入进行分类,并对给定主客体对的每个谓词类相关的不确定性进行建模。
部分模块介绍
PEG与之前的论文STTran中的时空Transformer大同小异,此处不做过多叙述。
记忆引导训练
由于SGG数据集中的长尾偏差,直接PEG嵌入对罕见的谓词类有偏差,因此需要对它们进行去偏差。即对于任何给定的关系嵌入,
,记忆扩散单元(Memory Diffusion Unit, MDU)首先从谓词类为中心的记忆库ΩR中检索相关信息,并使用它来丰富给定的关系嵌入
,从而产生更平衡的嵌入
。记忆库
由一组记忆原型组成,每个原型都是谓词类的抽象,并作为其相应的PEG嵌入的函数计算。
论文中设定,原型被定义为特定类别的质心。
其中Nyrp是整个训练集中映射到谓词类别yrp的主题-对象对的总数。
渐进式记忆计算。ΩR以渐进的方式计算,即模型的最后状态用于计算当前状态的记忆,即epoch α的记忆使用epoch α−1的模型权重计算。这使得ΩR在每个时代都变得更加精致。由于第一个epoch没有可用的记忆,因此MDU在此状态下保持非活动状态,并且。
MDU:目的是得到更合理的关系嵌入
如结构图所示,对于给定的查询,MDU使用注意算子从ΩR中检索相关信息,作为记忆扩散特征,即:
其中。
由于每个主客体对都有多个谓词映射到它,许多视觉关系具有相似的特征,这意味着它们对应的记忆原型ωp共享多个谓词嵌入。因此,Eq 10的注意操作有助于利用记忆库将知识从数据丰富的类转移到数据贫乏的类,从而使类产生关于
类中缺失的数据贫乏类的补偿信息。将该信息扩散回
,得到均衡嵌入的
,如下图所示:

MDU结构图:

如图4所示,MDU只在训练阶段使用,因为它不是作为一个网络模块来转发,而是作为一个元学习启发的结构元正则器。由于ΩR是直接从PEG嵌入中计算出来的,因此在MDU上的反向传播可以细化计算出的记忆原型,从而实现更好的信息扩散,并从本质上教会PEG如何生成更平衡的嵌入,这些嵌入不会欠拟合到数据贫乏的关系中。这里的λ充当梯度缩放因子。由于最初的PEG嵌入严重偏向于数据丰富的类,如果λ太高,则记忆扩散特征的补偿效果会大大降低。另一方面,如果λ太低,过多的知识从数据丰富的类转移到数据贫乏的类,导致前者的性能较差。
GMM
有兴趣的可以自己去搜了看下,还没细看。