论文地址:https://arxiv.org/abs/1909.07606v1
项目地址:https://github.com/autoliuweijie/K-BERT
摘要
BERT虽然能够从大规模的语料库中捕获通用的语言表示信息,但是缺少特定领域的知识。针对这一点,论文中的作者提出了融入知识图谱(KGs)的K-BERT模型,作者是通过将三元组注入到句子中作为特定的知识。但如果融入太多的知识可能会使原句子偏离正确的语义,称之为知识噪声(KN)问题。为了解决此问题,作者引入了软位置和可视化矩阵来限制知识对原句子的影响。
引言
当阅读领域的文本时,普通人只能根据上下文来理解,但是专家有能力借助相关的领域知识来进行推断。因此作者打算预训练一个包含特定领域知识的模型。
如果KG可以集成到LR(语言表示)模型中,它将为模型配备领域知识,从而提高模型在特定领域任务上的性能,同时减少大规模的预训练成本。此外,生成的模型具有更大的可解释性,因为注入的知识可以手动编辑。
- 知识注入中遇到的两个挑战:
(1)Heterogeneous Embedding Space(异构嵌入空间) (HES):文本中单词的嵌入向量和KG中的实体的获取向量是分开的,这使得它们的向量空间不一致。
(2)Knowledge Noise(知识噪声) (KN):过多的知识融入会改变原句的语义。
因此作者提出了K-BERT模型,它能够加载预训练的BERT模型,还能够轻松的将领域知识注入到模型中。
- 主要贡献:
(1)K-BERT,与BERT兼容并且在融入领域知识时没有异构嵌入空间问题和知识噪声问题。
(2)精细地融入了知识,使K-BERT模型无论是在开放领域还是特地领域任务中,都比BERT模型取得了更优异的结果。
(3)开源地址:https://github.com/autoliuweijie/K-BERT
模型结构
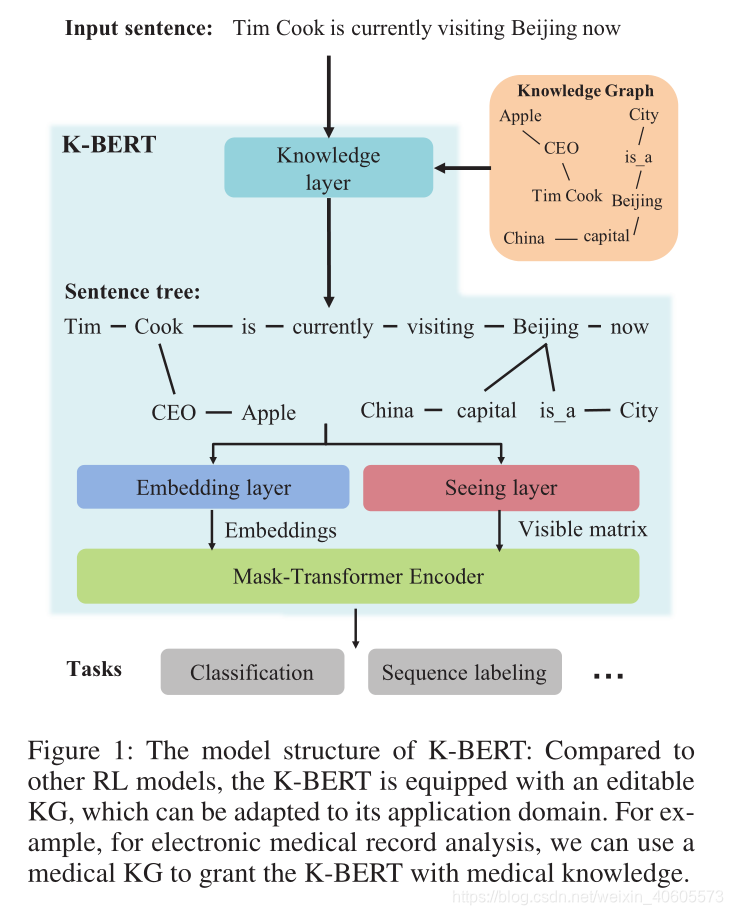
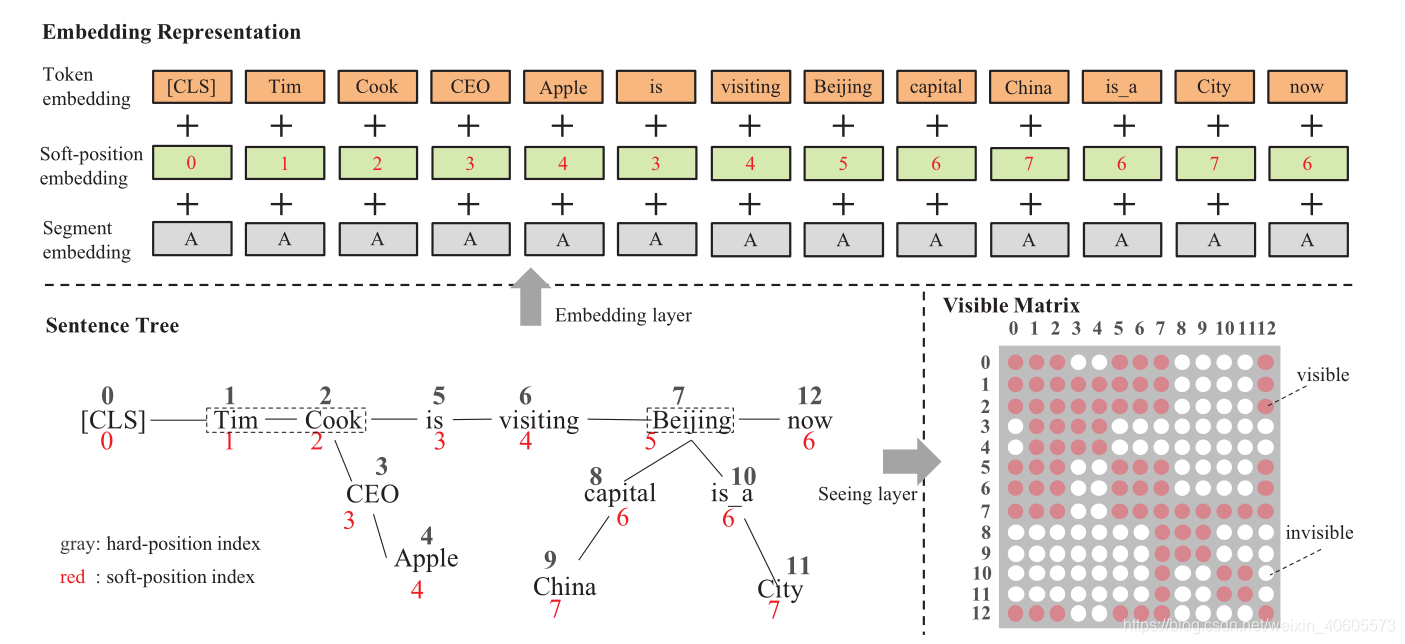
如上图所示,与其他RL模型相比,K-BERT配备了可编辑的KG,可以适应其应用领域。模型包含知识层、嵌入层、可见层、掩盖-转换编码器层。对于输入句子,知识层首先从KG中将相关的三元组注入到句子中,将原始句子转换成具有丰富知识的句子树。然后将句子树同时输入嵌入层和查看层,然后转换为标记级别的嵌入表示和可见矩阵。可见矩阵用于控制每个标记的可见区域,防止由于注入的知识过多而改变原始句子的含义。
知识层
用于将知识注入句子和句子树的转换。给定输入句子:s = [w0,w1,w2, …, wn] 和 一个KG记为K,然后生成句子树t =[w0,w1, …, wi[(ri0,wi0), …,(rik,wik)], …, wn].
首先在KG中查询输入句子中所有实体的三元组E
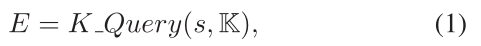
E = [ (wi,ri0,wi0), …,(wi,rik,wik)]
接下来,K-Inject通过将E中的三元组注入到其对应位置,将查询到的E注入到句子s中,并生成句子树t。 t的结构如图3所示。
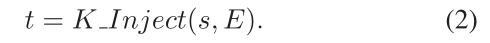
嵌入层
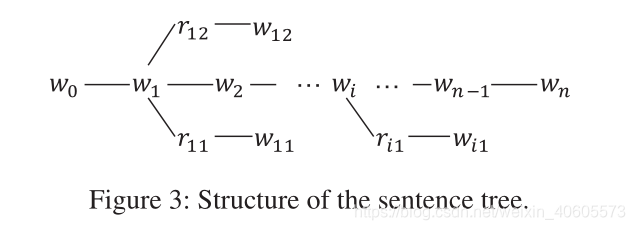
与BERT相似,K-BERT的嵌入表示形式是三个部分的总和:标记嵌入,位置嵌入和段嵌入,但不同之处在于K-BERT的嵌入层的输入是句子树而不是标记序列。因此,如何在保留句子结构信息的同时将句子树转换为序列是K-BERT的关键。
K-BERT和BERT的标记嵌入之间的区别在于,在嵌入操作之前,句子树中的标记需要重新排列。在我们的重新安排策略中,将分支中的标记插入到相应的节点之后,而将后续标记向后移动。如图2所示的示例,句子树被重新排列为“Tim Cook CEO Apple is visiting Beijing capital China is a City now”。尽管此过程很简单,但它使句子不可读并丢失了正确的结构信息。幸运的是,它可以通过软位置和可见矩阵来解决。
软位置嵌入
以图2中的句子树为例,重新排列后,在[Cook]和[is]之间插入了[CEO]和[Apple],但是[is]的主题应该是[Cook],而不是[Apple]。要解决此问题,我们只需将[is]的位置号设置为3而不是5。因此,在计算变压器编码器中的自注意力得分时,[is]会位于[Cook]的下一个位置相等的。但是,出现了另一个问题:[is]和[CEO]的职位号都为3,这使得他们在计算自我注意力时的位置接近,但实际上它们之间没有任何联系。解决此问题的方法是屏蔽自我注意,将在下一部分中介绍。
段嵌入
像BERT一样,当包含多个句子时,K-BERT也使用分段嵌入来标识不同的句子。例如,当输入两个句子[w00,w01,…,w0n]和[w10,w11,…,w1m]时,它们被组合为一个句子[[CLS],w00,w01,… ,w0n,[SEP],w10,w11,…,w1m]和[SEP]。对于组合的句子,它用段标记序列[A,A,A,A,…,A,B,B,…,B]标记。
可见层
可见层是K-BERT和BERT之间的最大区别,也是使此方法如此有效的原因。 K-BERT的输入是一棵句子树,其中的分支是从KG获得的知识。但是,知识带来的风险是它可能导致原始句子含义(即KN问题)的更改。例如,在图2的句子树中,[China]仅修饰[Beijing],而与[Apple]没有关系。因此,[Apple]的表示形式不受[China]的影响。另一方面,用于分类的[CLS]标签不应绕过[Cook]来获取[Apple]的信息,因为这会带来语义变化的风险。为了防止这种情况的发生,K-BERT使用可见矩阵M来限制每个标记的可见区域,以使[Apple]和[China],[CLS]和[Apple]彼此不可见。
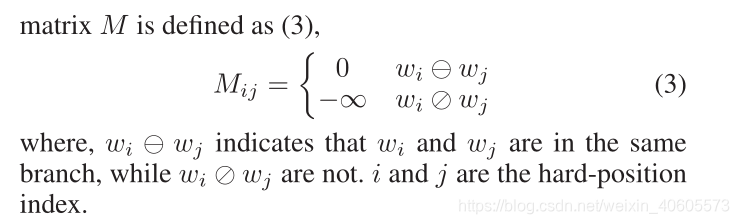
掩码-转换层
在某种程度上,可见矩阵M包含句子树的结构信息。 BERT中的Transformer(V aswani et al.2017)编码器无法接收M作为输入,因此我们需要将其修改为Mask-Transformer,这可以根据M限制自我关注区域.Mask-Transformer是一个堆叠多个mask-self-attention的块。对于BERT,我们将层数(即mask-self-attention块)表示为L,将隐藏大小表示为H,并将mask-self-attention头的数量表示为A.
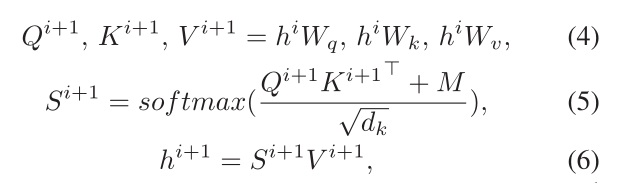
hi是第i个mask-self-attention的隐藏状态,Wq,Wk,Wv是可训练的参数,M是visible matrix,如果对wk来说wj是不可见的,注意力分数Mjk设为0。
以上公式只是对 BERT 里的 self-attention 做简单的修改,多加了一个 M,其余并无差别。如果两个单词之间互相不可见,它们之间的影响系数S[i,j]就会是0,也就使这两个词的隐藏状态之间没有任何影响。这样,就把句子树中的结构信息输入给 BERT 了。
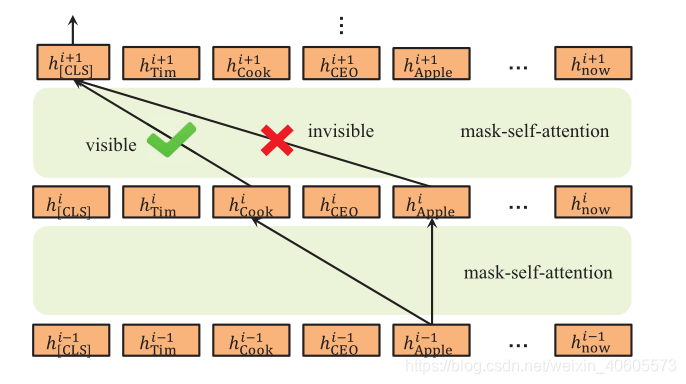
如上图,掩码转换器层是多个掩码自我注意的堆栈。 [Apple]只能通过[Cook]间接作用于[CLS],降低了知识噪声的影响。