Improving the Applicability of Knowledge-Enhanced Dialogue Generation Systems by Using Heterogeneous Knowledge from Multiple Sources

文章目录
任务:知识增强对话生成
会议:WSDM 2022
原文:论文地址
源码:项目地址
Abstract
为了应对传统的对话系统容易产生无意义回复的问题,研究者们往往通过融合外部知识来增强对话生成。尽管这类方法取得了显著的成效,但是,由于单源知识的知识覆盖不足,仅使用单源知识往往会使现有的知识增强方法在现实场景中退化为传统模型。
为了提高知识增强方法的适用性,本文提出了两个使用多源异构知识的新颖框架。
- 第一个框架是MHKD-SeqSeq,通过识别抽象级别的知识行为来使用不同的异构知识,同时,使用一个分散-聚合(Diffuse-Aggregate) 机制同时处理多个知识,并产生一个统一的结果;
- 第二个框架是MHKD-ARPLM,使用知识线性化技术结合预训练语言模型的优势。
在实验中,本文收集了以往公开发布的数据集,并构建了一个多源知识对齐的数据集,TriKE-Weibo,该数据集融合了三种知识源:常识(commensense),文本(texts),信息框表格(infobox table)。通过一系列丰富的实验,验证了本文提出的方法的有效性。
1. Introduction
1.1 Motivation
引入外部知识增强对话生成取得了一定效果,但是在现实世界的数据集中,仅有很小一部分对话能够链接到一个单源知识,由于没有可用的知识,这将导致知识增强对话模型的适用性大受限制,因为它们往往会因此退化成传统模型。
下图左边三个展示了单源知识的覆盖范围,最后一个表示连接三个单源知识后的覆盖范围,即至少有一个知识链接到对话时的覆盖范围。


因此,提高知识覆盖范围是提高知识增强对话适用性的关键。一个直觉的方法是直接扩展现有的知识库,但是这是不现实的,因为:
- 现有的知识库比如ConceptNet、Freebase,都是由特定机构发布和维护的,第三方难以扩展它们;
- 知识覆盖范围和知识库容量并不是线性相关的。正如Zip’f定律所揭示的,在许多自然语言场景中,我们总能观察到长尾分布,不能链接到知识库的对话往往涉及低频率的知识,但是,收集低频知识的成本较高。
1.2 Solution
本文提出利用多源异构知识提高知识增强方法的适用性,即知识覆盖范围。其主要优势为:
- 收集更多的知识库比扩展现有知识库更容易;
- 可以结合不同类型知识的独特优势,避免特定类型知识的固有局限性,相比于非结构化知识文本和结构化知识,非结构化知识包含更丰富的语义信息,结构化图中的知识具有更好的组织性;
- 不同的知识源可能有不同的话题分布/偏好,融合多个不同的知识源可以有效地避免长尾分布问题,一个知识源中低频率主题可能在另一个知识源中比较流行,因此,多源知识可以显著提升知识覆盖范围。
因此,本文提出了Multi-source Heterogeneous Knowledge-enhanced Dialogue generation (MHKD),多源异构知识增强的对话生成方法,试图解决使用多源异构知识中的两个主要挑战:
- 由于不同异构知识具有个体特征,如何在不受异构知识差异性影响的前提下利用异构知识?
- 如何灵活有效地将多个来源的知识整合到一个对话系统中?
本文首先提出了非预训练的MHKD-Seq2Seq框架,为了兼容不同的异构知识源,该方法使用Abstract-Level Behavior Modeling在抽象水平建模知识源。为了同时使用多个知识源,本文提出了一个两步的扩散-聚合(Diffuse-Aggregate)机制用于MHKD-Seq2Seq。
除此之外,本文提出了一个预训练的MHKD-APPLM框架,MHKD-APPLM采用知识线性化技术来将不同的知识线性化成一个统一的格式,即纯文本格式。随后,多个线性化的知识文本拼接起来,添加到对话上下文。有了这一范式,就可以在自回归预训练语言模型上(如GPT2)构建多源知识增强的系统。
为了评估多源异构知识增强的对话回复生成的有效性,本文提出了基于上述两个框架的实现,TriKE-Dial和TriKE-DialGPT。本文还收集并构建了TriKE-Weibo,一个多源知识对齐的1M中文对话数据集,包含三种知识源:常识知识图谱(From ConceptNet),文本知识(From Wikipedia),信息框知识(From Wikipedia)。在人工和自动评估中,本文的方法都显著强于Baseline,大量的分析也表明使用来自多个来源的异构知识确实可以提高知识增强对话系统的适用性。
2. MHKD-SEQ2SEQ
该方法可以应用于大多数场景。任务定义为: P ( Y ∣ X , K i ) P(Y|X,K_i) P(Y∣X,Ki), X X X是Query, Y Y Y是Response, K i = { k i , j } ∈ K K_i = \{k_{i,j}\}∈{K} Ki={ ki,j}∈K表示多源知识集合 K {K} K中的第 i i i个知识源,它是一系列item(知识项)的集合。
2.1 Abstract-Level Behavior Modeling
为尽可能减少复杂性,本文提出了在抽象级别建模多源异构知识。首先识别知识在对话系统中可以扮演的角色,然后将其泛化到抽象层面的行为。因此,MHKD-Seq2Seq可以在抽象层次上建模任意类型的知识,而不受具体知识类型的影响。这个方法可以概括为三种抽象行为:
Representing
每个知识 K i K_i Ki首先需要被编码为一个嵌入 K i K_i Ki,定义这个行为: K i = { k i , j } = R e p K i ( K i = { k i , j } ) K_i=\{k_{i,j}\}=Rep_{K_i}(K_i=\{k_{i,j}\}) Ki={ ki,j}=RepKi(Ki={ ki,j}),每个 R e p K i Rep_{K_i} RepKi通过一个编码器实现。
Accessing
知识源的一个重要作用是通过提供相关知识来丰富对对话语境的理解。它可以看作是根据当前语境从编码的知识中收集一个相关的信息,即知识选择。将这种行为 A c c e s s K i Access_{K_i} AccessKi定义为一种注意力函数, A c c e s s K i ( q u e r y , k e y = K i , v a l = K i ) Access_{K_i} (query, key = K_i, val = K_i) AccessKi(query,key=Ki,val=Ki)。query是当前状态,key和value是编码后的知识。
Copying
未登录词和生成无聊回复是对话生成技术当前的两个难点,直接从知识中复制信息词能够有效缓解这两个困难。因此,MHKD-Seq2Seq显式地引入point-then-copy机制,然后将该行为定义为 C o p y K i Copy_{K_i} CopyKi,该行为基于知识 K i K_i Ki,在每个时间步 t t t上的概率分布 P t K i ∈ R ∣ K i ∣ P^{K_i}_t∈R^{|K_i|} PtKi∈R∣Ki∣复制一个知识项 k i , j k_{i,j} ki,j,即 P t K i = C o p y K i ( c o n t e x t d e c o d e r , K i ) P^{K_i}_t=Copy_{K_i} (context_{decoder},K_i) PtKi=CopyKi(contextdecoder,Ki)。
2.2 Diffuse-Aggregate Scheme
另一个挑战是如何同时使用所有知识源。为了最大化灵活性和可扩展性,本文提出了分散-聚合(Diffuse-Aggregate)机制,在每个分散步骤中,对于每个抽象行为,MHKD-Seq2Seq采用多个知识专用处理器并行处理特定知识的数据流。除知识外,所有处理器共享相同的输入并使用相同的输出格式。随后,数据流在聚合步骤中进行聚合。不同知识专用处理器输出的局部结果通过一个聚合处理器/函数进行聚合,可以是Max、Mean、Sum等无参数方法,也可以是可训练网络。
2.3 MHKD-Seq2Seq
Algorithm 1给出了MHKD-Seq2Seq框架的算法流程,其中,
z t z_t zt表示Decoder在 t t t时间步的隐藏状态; H H H表示编码器编码Query得到的表示; K i K_i Ki表示知识编码器编码知识得到的表示; C t C_t Ct表示在 t t t时间步通过注意力计算得到的动态上下文。
- 编码Query得到 H H H,编码每个知识源得到 K i K_i Ki;(line 1-4)
- 通过 H H H的最后一个隐藏状态 h n h_n hn初始化解码器,得到解码器的初始状态 t 0 t_0 t0;(line 5)
- 通过上一时间步的隐藏状态 z t − 1 z_{t-1} zt−1,通过和 H H H还有 K i K_i Ki进行注意力计算,得到上下文向量 c t c_t ct和知识向量 c t K i c_t^{K_i} ctKi,这一部分是behavior Access的Diffuse步骤;(line 6-10)
- 通过一个状态编码器进行聚合,得到状态向量 g t s g_t^s gts;(line 11)
- 更新解码器状态得到 z t z_t zt:根据上一时刻状态、上下文向量、知识向量、上一时刻解码输出token的嵌入、聚合状态向量;(line 12)
- 计算词表上的概率分布、从Query上复制的概率分布、从知识Copy的概率分布;(line 13-17)
- 通过一个状态编码器,得到状态向量 g t m g_t^m gtm,用于最后的聚合;(line 18)
- 通过聚合6中的概率分布进行解码生成。(line 19)

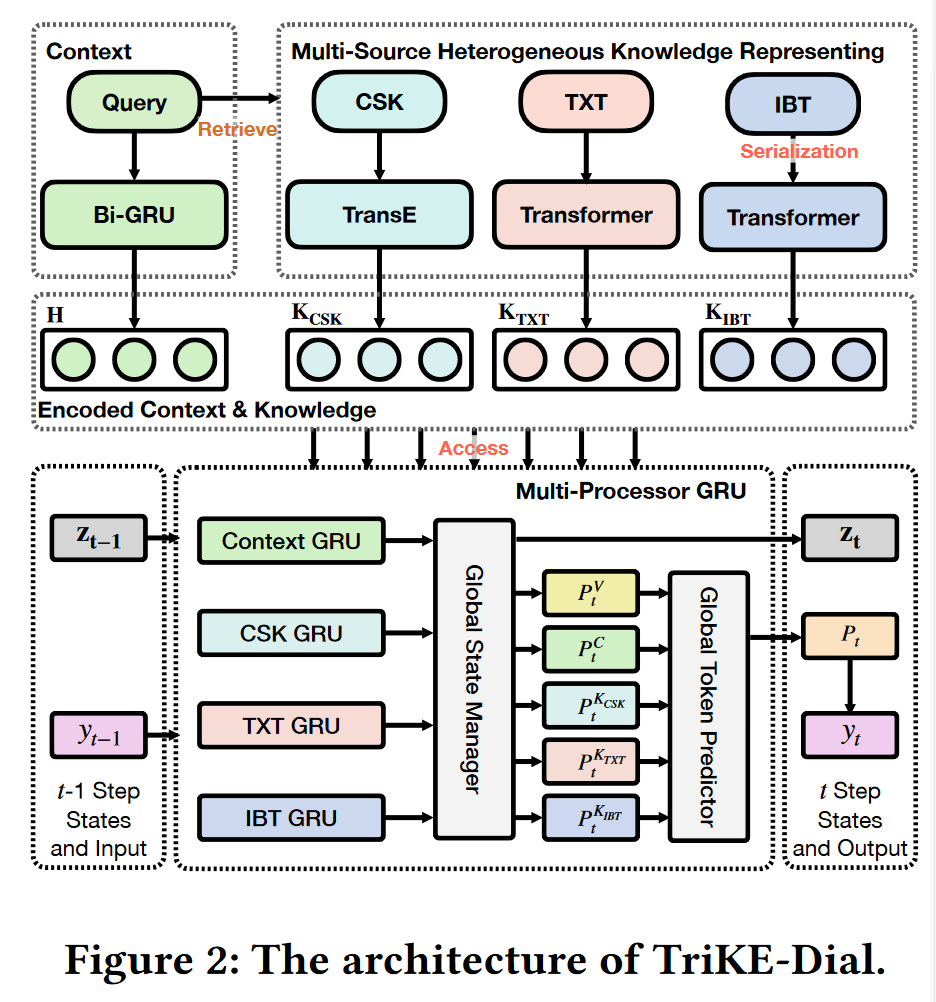
2.4 TriKE-Dial
本文介绍了一个MHKD-Seq2Seq的具体实现:TriKE-Dial。
采用三种知识:
-
常识知识(Commonsense knowledge,CSK)
-
文本知识(Knowledge texts,TXT)
-
信息框表格知识(Infobox table knowledge,IBT)
2.4.1 Representing Stage
使用四个不同的编码器编码Query和不同源的异构知识以更好地捕获语义信息。
- 上下文编码器:Query是短文本,使用Transformer容易过拟合,这里用BiGRU;
- 常识知识编码器:使用TransE编码知识三元组,学习到一个知识嵌入;
- 文本知识编码器:考虑到文本知识输入是一个长序列,使用两层Transformer编码;
- 信息框表格编码器:考虑其知识结构为一系列键值对,Key为一个名字短语,Value是一个短文本,首先将其序列化到一个Key-Word嵌入空间,序列化以后的长度很长,且Key-word对之间不存在很强的序列关系,使用一个两层的Transformer编码Key-word对。
2.4.2 Step-Wise Response Generation
传统解码器只维持一组参数,输出一个状态,难以处理多源异构知识场景。考虑到这个问题,本文提出了一个多处理器GRU(MP-GRU,Muti-Processor GRU unit)作为Decoder,这是一个分层单元,每个处理器都是一个Source-Specific GRU,它们之间不共享参数。
有了这些GRU后,使用一个Golbal State Manager进行聚合,一个Global Token Predictor进行预测下一个词。
MP-GRU Decoder
- 在每个时间步 t t t,进行Diffuse-step for Access,使用每个局部处理器并行计算Query和知识的局部状态 z t c z_t^c ztc和 z t K i z_t^{K_i} ztKi:
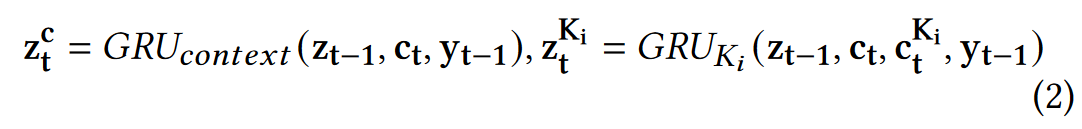
其中, c t c_t ct和 c t K i c_t^{K_i} ctKi是根据注意力网络计算得到注意力表示向量,相当于是当前全局状态 z t − 1 z_{t-1} zt−1作为Query,从上下文还有知识库(Key和Value)中获取到需要的信息:

- 全局状态 z t z_t zt是局部状态(Query和知识)的加权和,其中 f s t a t e f_{state} fstate是一个两层MLP+Softmax,用于Access的聚合,其实就是学习一个控制每个局部状态的权重,用于加权求和:
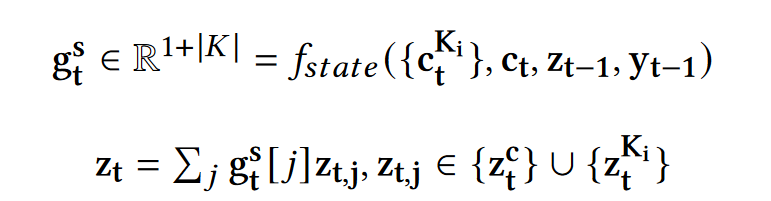
Global Token Predictor
- 词表概率分布,使用一个两层MLP+Softmax,根据全局状态、Query和知识的注意力表示向量、上一时刻输出词的Embedding计算:
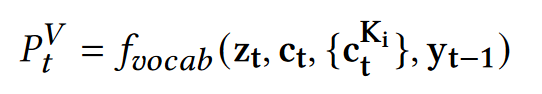
- 基于一个注意力网络 α C α^C αC,根据上下文编码向量(作为Key、Value)和当前全局状态(作为Query),计算从Query(输入的X)中复制一个词的概率分布:
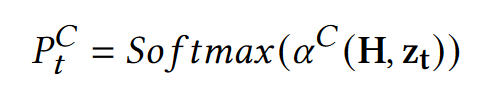
- 基于一个注意力网络 α i K α^K_i αiK,根据知识编码向量和上一刻全局状态(为什么是上一时刻?笔误或者复用了前面的Q-V概率分布,只有t-1时刻),计算从知识中复制一个知识项的概率分布:
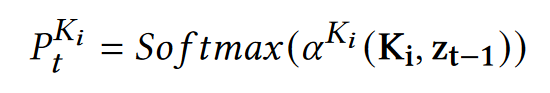
- 对上述概率分布进行聚合, f m o d e f_{mode} fmode是一个两层MLP+Softmax,用于P的聚合,其实就是学习一个权重。最终的概率分布是各预测词概率分布的加权和:
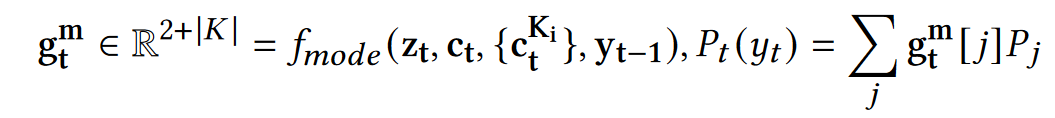
Training
P t ∈ R ∣ V ∣ + ∣ X ∣ + Σ ∣ K i ∣ P_t ∈ R^{|V|+|X|+Σ|K_i|} Pt∈R∣V∣+∣X∣+Σ∣Ki∣
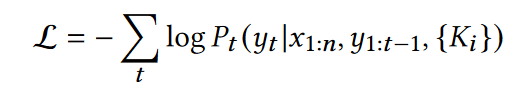
3. MHKD-ARPLM
3.1 TriKE-DialGPT
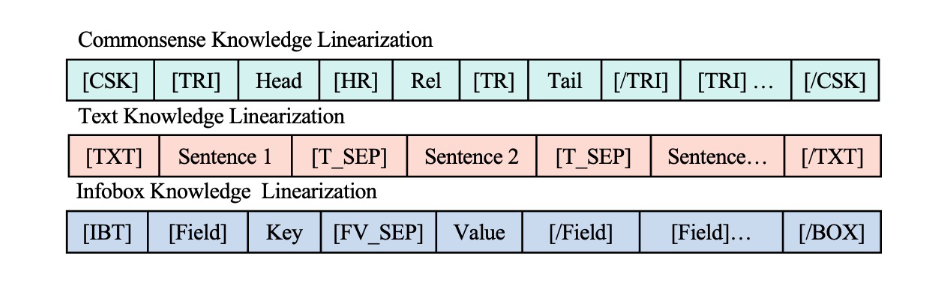
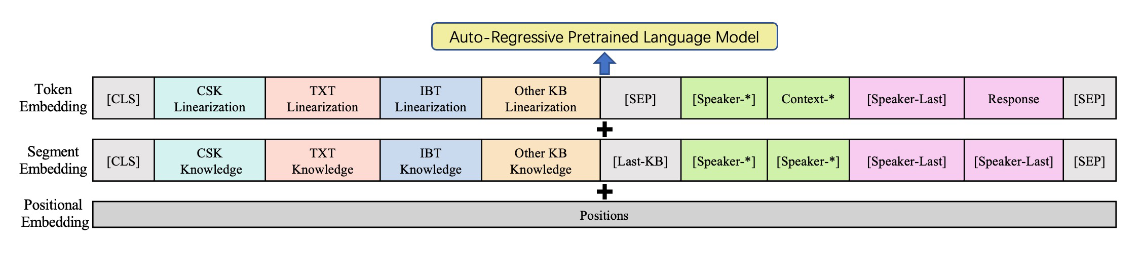
采用知识线性化技术将多源知识线性化为一个token序列,然后将每个线性化后的知识拼接起来。基于对话历史和线性化的知识,微调自回归PLM生成回复。
本文采用CDialGPT作为backbone,采用的线性化机制如下图所示。
3.2 Why do we propose two frameworks?
直觉上来看,开发一个基于MHKD-APPLM的模型相比非预训练模型MHKD-Seq2Seq更加容易,然而,在实际应用中,MHKD-APPLM存在几个限制:
-
预训练模型在预训练阶段消耗大量数据和计算资源,这使得预训练模型在某些场景下不work;
-
不同于MHKDSeq2Seq可以显式地识别和建模知识行为,MHKD-ARPLM以黑盒的方式使用知识。这种方式不容易控制/解释模型如何使用知识;
-
预训练模型通常在文本长度方面有限制(例如,CDialGPT2限制的token上限为512),而线性化知识文本的长度往往很长:
- 知识的丰富信息性往往意味着大量的token;
- 在线性化部分,往往会引入新的特定token来表征知识结构。
虽然存在一些能够处理长文本的预训练模型如Longformer,他们通过省略注意力,将序列长度的二次依赖性降低为线性。但是,这些模型都属于自编码模型,而不是自回归的,不适合做文本生成。
基于此,本文提出了两种框架适用于不同的场景。
4. Evaluation
4.1 Experiment Methodology
Dataset:TriKE-Weibo
首先从三个公开发布的微博数据集中收集3.67M个中文对话Query-Response候选对,使用jieba分词作为分词器。
中文ConceptNet作为常识知识源,从中文维基百科收集1M+文本作为文本知识库,从中文维基百科收集1M+信息框表格作为信息框表格知识库。
值得注意的是,经过对话-知识对齐,在最终的数据中,并不是所有的知识源条目都被使用到。训练/验证/测试集分别为1M/40K/40K个实例。在每个子集中,大约有80%的对话是知识对齐的,剩余的20%的对话用来验证无知识匹配场景的性能。
Models
分为两组模型:非预训练和预训练。非预训练模型方面使用了很多baseline,分为单源知识增强和多源知识增强,预训练模型方面使用了CDialGPT在TriKE-weibo上面微调,最大输入长度限制为256个token。
Metrics
BLEU1-4,ROUGE-L,the embedding-based Embed-A/G/X (Average/Greedy/ Extreme,DIST-A2(所有生成词中distinct 2-grams的数量),DIST-B2(最后一个候选beam中distinct 2-grams的数量),Ent4(4-gram的Entropy),entity score(每句生成的知识词数量)。
4.2 Evaluation Results
非预训练模型方面,TriKE-Dial在相关性指标如BLEU达到了最佳性能,并且在多样性和新颖性指标方面取得了较好的平衡,新颖性指标主要衡量response相比query的新颖性。
预训练模型方面,TriKE-DialGPT性能远超CDial-GPT,验证了本文方法的有效性。
对比TriKE-Dial和TriKE-DialGPT,可以发现TriKE-DialGPT的主要优势是在相关性指标,这个优势可能是其大量的预训练数据带来的。而TriKE-Dial更好地、更细粒度地建模了多源知识来生成对话。因此,即使只有1M训练对话,TriKE-Dial在多样性、新颖性和知识部分和TriKE-DialGPT性能相对持平。
此外,人工评估发现,TriKE-DialGPT性能比CDial-GPT好,而对比本文的两个方法,TriKE-DialGPT的信息性比TriKE-Dial略好,TriKE-Dial的恰当性比TriKE-DialGPT略好。
4.3 Knowledge Ablation Study
消融实验验证了:
- 验证了单源知识的有效性;
- 也验证了本文的多源知识增强模型能更大幅度提升性能;
- 相比于无知识增强方法,单源知识增强取得的性能增益之和约等于多源知识增强取得的性能增益,这验证了本文框架的可扩展性;
- 本文模型+单源知识+Copy的性能相较于其他单源知识增强的baseline取得了相对持平性能;
- 当使用相同的知识源时,本文的模型性能能够超越其SOTA方法,这说明TriKE-Dial的性能提升不仅仅是多源知识的力量,也是本文方法有一定优势。
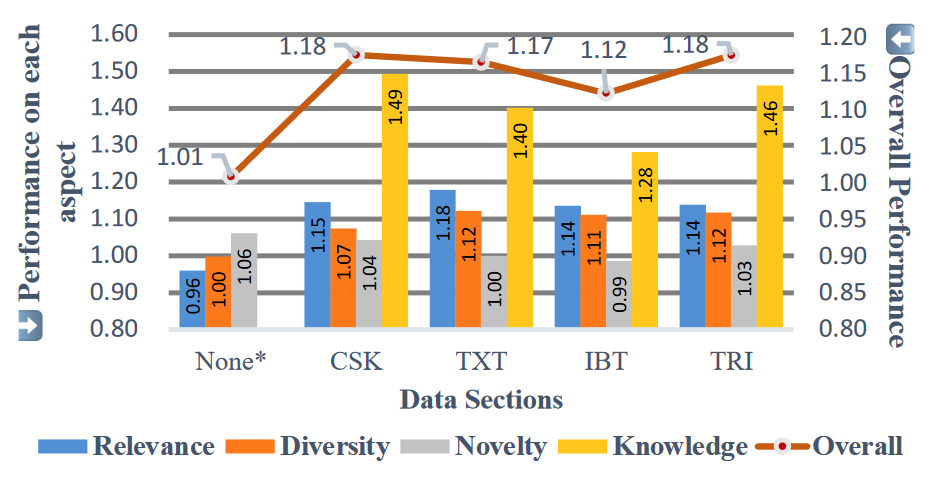
The Necessity of Improving Knowledge Coverage
把测试样例分成了四组:None/CSK/TXT/IBT,下图报告了相对于无知识对齐模型的性能。可以显著观察到知识对齐组性能的增益,而无知识对齐组性能则退化到了无知识增强方法的水平。这表明了提升知识覆盖率的必要性。
4.4 Case Study
样例分析发现,TriKE-DialGPT经常生成有信息量但是重复单词的句子,相比之下,TriKE-Dial生成的句子更加流利。