CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
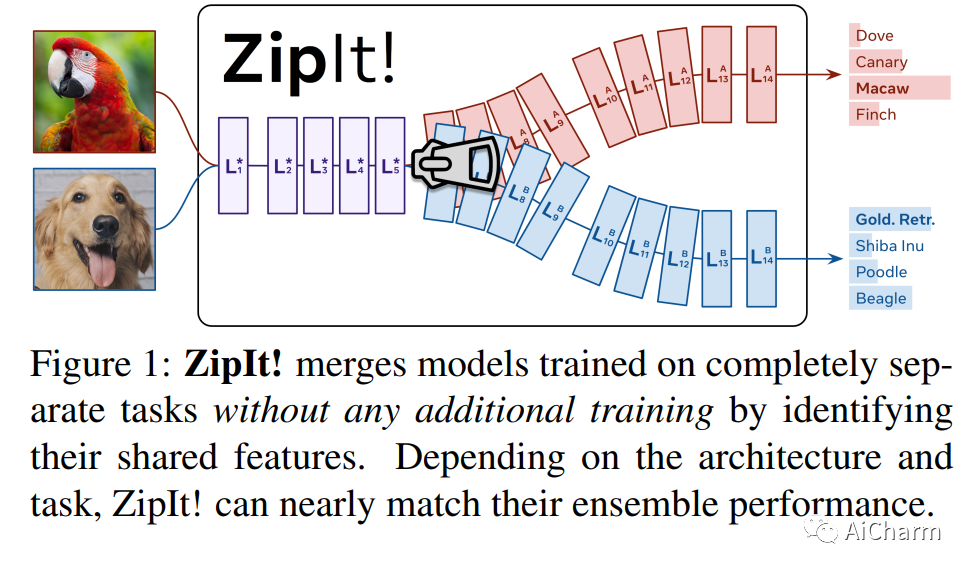
1.ZipIt! Merging Models from Different Tasks without Training

标题:压缩它!无需训练即可合并来自不同任务的模型
作者:George Stoica, Daniel Bolya, Jakob Bjorner, Taylor Hearn, Judy Hoffman
文章链接:https://arxiv.org/abs/2305.03053





摘要:
典型的深度视觉识别模型能够执行他们接受过训练的一项任务。在这篇论文中,我们解决了一个极其困难的问题,即在没有任何额外训练的情况下,将具有不同初始化的完全不同的模型组合成一个多任务模型,每个模型解决一个单独的任务。模型合并的先前工作将一个模型置换到另一个模型的空间,然后将它们加在一起。虽然这适用于在同一任务上训练的模型,但我们发现这无法解释在不相交任务上训练的模型的差异。因此,我们介绍了“ZipIt!”,这是一种合并两个具有相同架构的任意模型的通用方法,它包含两个简单的策略。首先,为了解决模型之间不共享的特征,我们扩展了模型合并问题,通过定义一个通用的“zip”操作,额外允许在每个模型中合并特征。其次,我们添加了对部分压缩模型直到指定层的支持,自然地创建了一个多头模型。我们发现这两个变化相结合,比之前的工作有了惊人的 20-60% 的改进,使得在不相交任务上训练的模型的合并变得可行。
2.Automatic Prompt Optimization with "Gradient Descent" and Beam Search(CVPR 2023)

标题:使用“梯度下降”和波束搜索进行自动提示优化
作者:Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, Michael Zeng
文章链接:https://arxiv.org/abs/2305.03495




摘要:
大型语言模型 (LLM) 作为通用代理已显示出令人印象深刻的性能,但它们的能力仍然高度依赖于通过繁重的试错工作手写的提示。我们针对此问题提出了一个简单且非参数的解决方案,即自动提示优化 (APO),它受数值梯度下降的启发,可以自动改进提示,假设可以访问训练数据和 LLM API。该算法使用小批量数据来形成批评当前提示的自然语言“梯度”。然后通过在梯度的相反语义方向上编辑提示,将梯度“传播”到提示中。这些梯度下降步骤由波束搜索和强盗选择程序引导,可显着提高算法效率。三个基准 NLP 任务和 LLM 越狱检测的新问题的初步结果表明,自动提示优化可以胜过之前的提示编辑技术,并通过使用数据将模糊的任务描述重写为更精确,将初始提示的性能提高多达 31%注释说明。
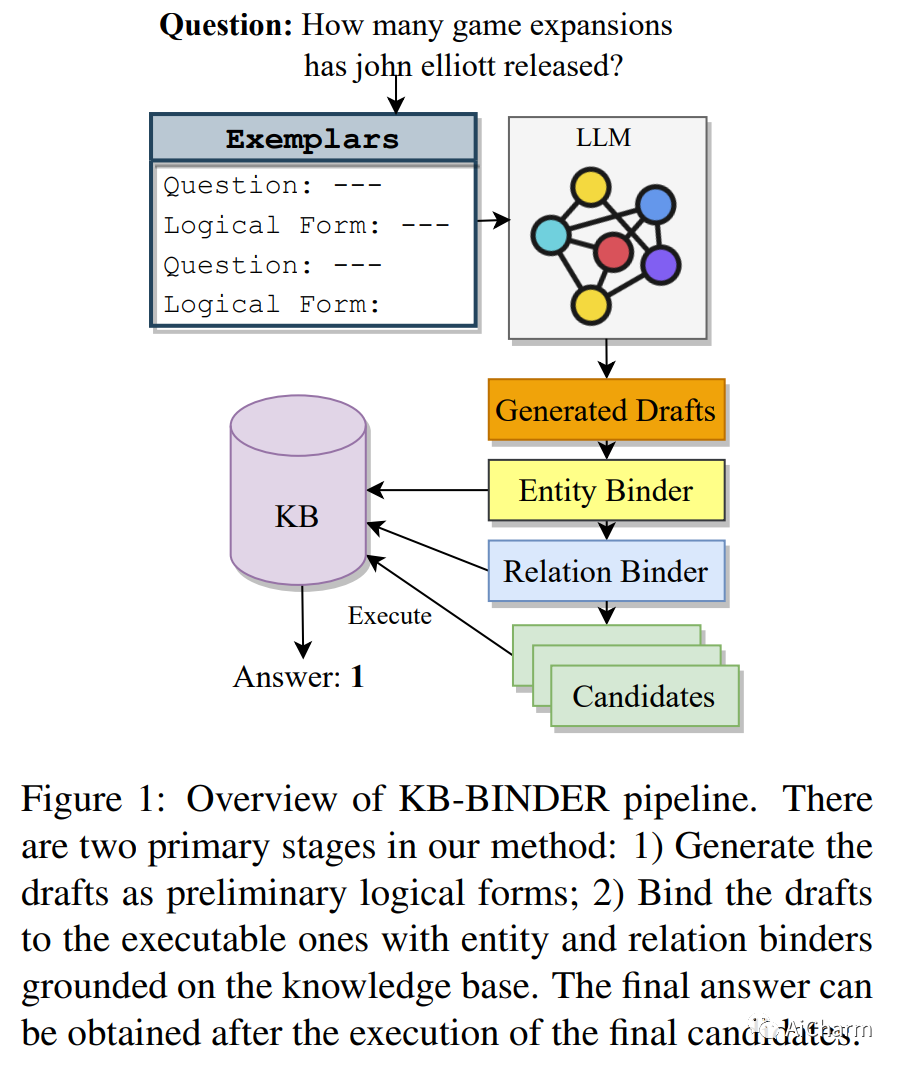
3.Few-shot In-context Learning for Knowledge Base Question Answering (ACL 2023)

标题:用于知识库问答的少样本上下文学习
作者:Tianle Li, Xueguang Ma, Alex Zhuang, Yu Gu, Yu Su, Wenhu Chen
文章链接:https://arxiv.org/abs/2305.01750



摘要:
由于对各种可能的自然语言问题进行概括的挑战,基于知识库的问答被认为是一个难题。此外,不同知识库之间知识库模式项的异质性通常需要对不同知识库问答 (KBQA) 数据集进行专门培训。为了使用统一的免训练框架处理各种 KBQA 数据集的问题,我们提出了 KB-BINDER,它首次实现了对 KBQA 任务的少样本上下文学习。首先,KB-BINDER利用像Codex这样的大型语言模型,通过模仿一些演示,生成逻辑形式作为特定问题的草稿。其次,KB-BINDER以知识库为基础,将生成的草稿与BM25分数匹配的可执行草稿进行绑定。四个公共异构 KBQA 数据集的实验结果表明,KB-BINDER 仅需少量上下文演示即可实现强大的性能。尤其是在 GraphQA 和 3-hop MetaQA 上,KB-BINDER 甚至可以超越最先进的训练模型。在 GrailQA 和 WebQSP 上,我们的模型也与其他经过全面训练的模型不相上下。我们相信 KB-BINDER 可以作为未来研究的重要基线。我们的代码可在此 https URL 上获得。
更多Ai资讯:公主号AiCharm