论文地址:https://arxiv.org/abs/1905.04748v1
github地址:https://github.com/ShawnDing1994/AOFP
Motivation
这篇文章的提出的剪枝方法是基于最朴素的也是直接的思想,即filter的重要程度取决于其引起的loss的变化程度,loss变得越小,则filter越不重要,这就是oracle。但是如果对每个filter的重要性指标用oracle计算,然后进行排序剪枝,再finetune,这种迭代的方式非常耗时,计算量巨大。基于这个瓶颈,作者提出了基于oracle的思想的剪枝方法。
Method
首先,针对原本oracle的计算是通过比较最后一层的输出loss变化得到,作者提出了改进,即用下一层的输出featuremap的变化程度,而非最终的输出来评估删掉一个filter的影响。这种方法是基于作者认为网络相当于状态机,存在damage isolation的情况,即当前层filter的删除只对下一层的输入产生影响,之后的层是看不到当前层的变化的,变化认为是由其前一层filter的变化造成的。这一方法使得oracle的评估时间大大缩短,否则每个filter都要跑整个网络。重要性指标定义如下:
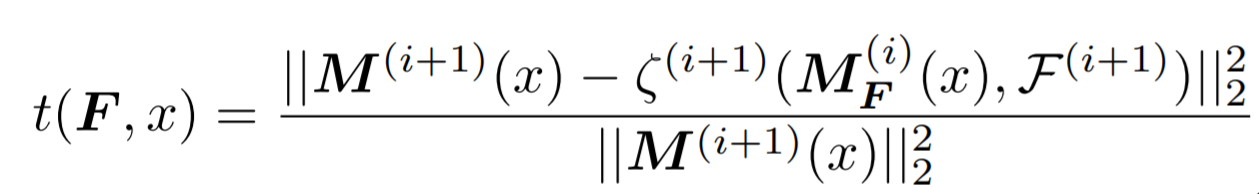
其次,在重要性指标定义方式解决后,作者提出多路径训练剪枝网络来使得剪枝和finetune的过程同时进行。如下图所示。

图中三条路径,左边为反向传播的梯度更新路径,中间为剪枝后的网络,称为base path,其中的 u u u层为mask层,用于标记减剪枝了的filter,右边为scoring path,用于计算每个filter的重要性指标, v v v层为其mask层,用于mask继续待剪枝的filter,来计算其重要性指标。以上图为例,conv1层已经剪枝了两个filter,现尝试剪枝第三个filter,此时把 v v v中的filter mask掉,而在 u u u中保留,这样两条路径在conv2输出的feature map上变化的loss就是删掉该filter的重要性指标,即图中的"compute t for conv1"。因此,在一次前向传播的过程中,base path用于finetune网络,同时产生original output,score path得到filter的重要度,这种并行操作加快了训练和剪枝的过程。
而为了在若干次前向传播后能计算出所有filter的重要性指标,作者提出采用每层随机mask一批filters(数量固定),而不是每次每层只mask一个filter计算重要性。将每次前向传播后计算得到的重要性指标(t值)记录到mask掉的filter中,在经过n个batch的输入后,每个filter中记录了若干个loss,虽然不是自己的,但是期望应等于其他filter的平均loss+自身的loss。因此,该loss的期望能区别出各filter之间的重要性。
对于每次mask的数量的确定,作者提出渐进优化的想法,利用二分的方式随机选取,即每次都从上一个前向传播所得的不重要的一半filter集合中选择一半的filter,并将这一半的集合中loss低于阈值的filter mask为0(即 u u u中mask为0,在下一轮前向传播中剪枝掉)。具体步骤如下:

该过程的终止条件为所选中的待mask的集合中的最大loss值大于等于定义好的阈值且集合中的元素个数为1。
Experiment
数据集:CIFAR-10, ImageNet
模型:AlexNet, ResNet, VGGNet
Results




Thoughts
对于这个方法,我关于batch的个数选取产生疑惑,因为我在之前做实验的过程中发现只有用整个训练集做输入才能准确反映出filter的重要性。这里一方面计算下一层的输出差只是近似最终输出的loss差,另一方面还只是用部分数据集做scoring的计算,重要性应该不是很准确,可能只是通过不断的finetune来提升网络。可能还要细看以下实验过程。